Sklearn genetic opt
0.11.1


Scikit-Learn модели гиперпараметры Настройка и выбор функций, используя эволюционные алгоритмы.
Это предназначено для того, чтобы быть альтернативой популярным методам внутри Scikit-Learn, таких как поиск сетки и рандомизированный поиск сетки для настройки гиперпараметров и из RFE (рекурсивное устранение функций), выберите из модели для выбора функций.
Sklearn-Genetic-Opt использует эволюционные алгоритмы из пакета DEAP (распределенные эволюционные алгоритмы в Python), чтобы выбрать набор гиперпараметров, которые оптимизируют (максимум или мин) оценки перекрестной проверки, его можно использовать как для задач регрессии, так и для классификации.
Документация доступна здесь
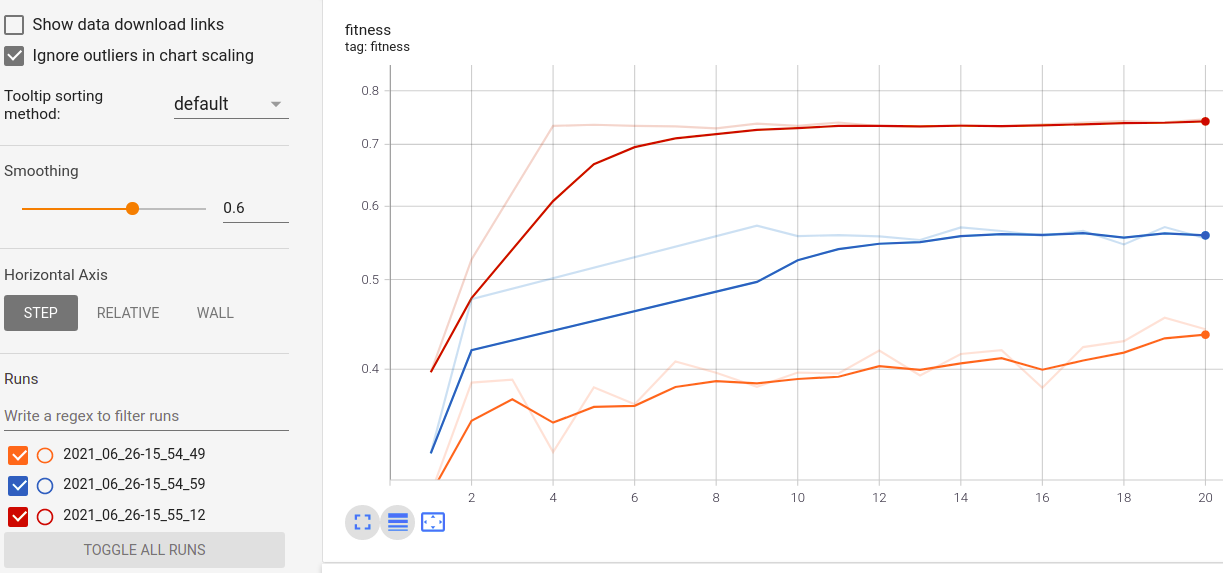
Визуализируйте прогресс вашего обучения:
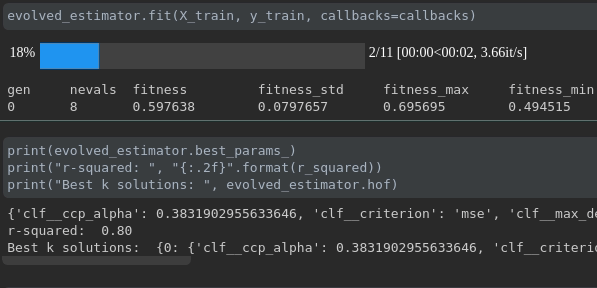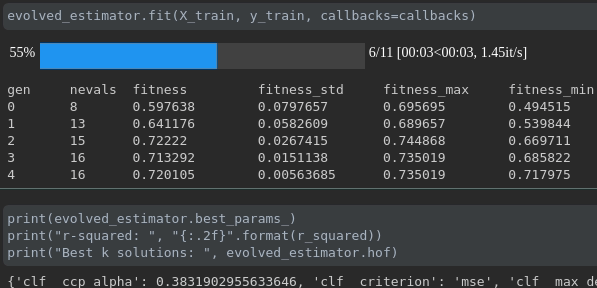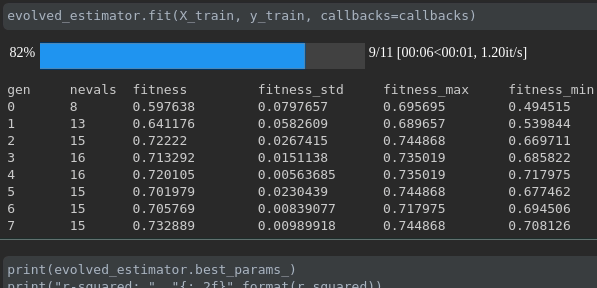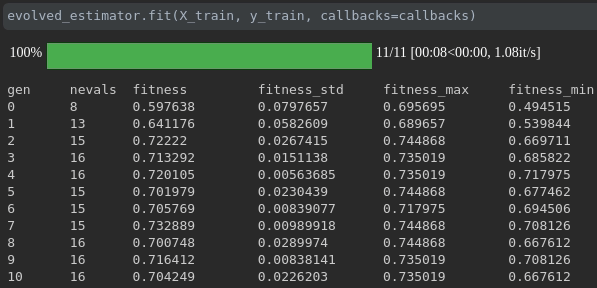
Визуализация метрик в реальном времени и сравнение между пробегами:
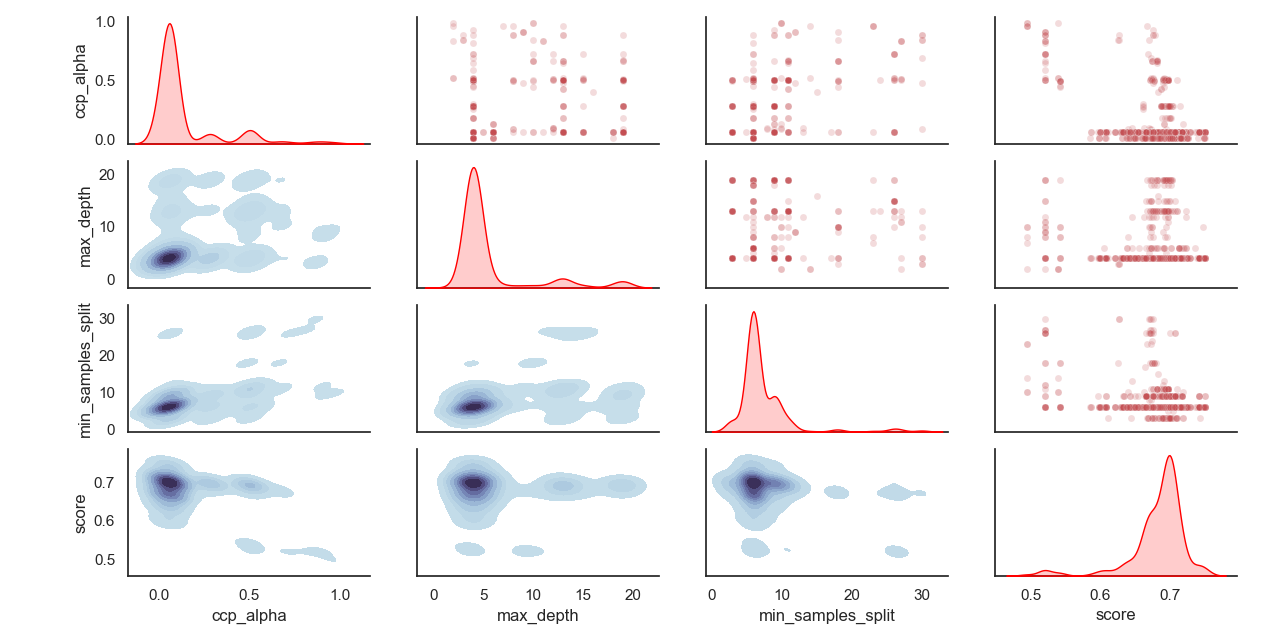
Отбрасываемое распределение гиперпараметров:
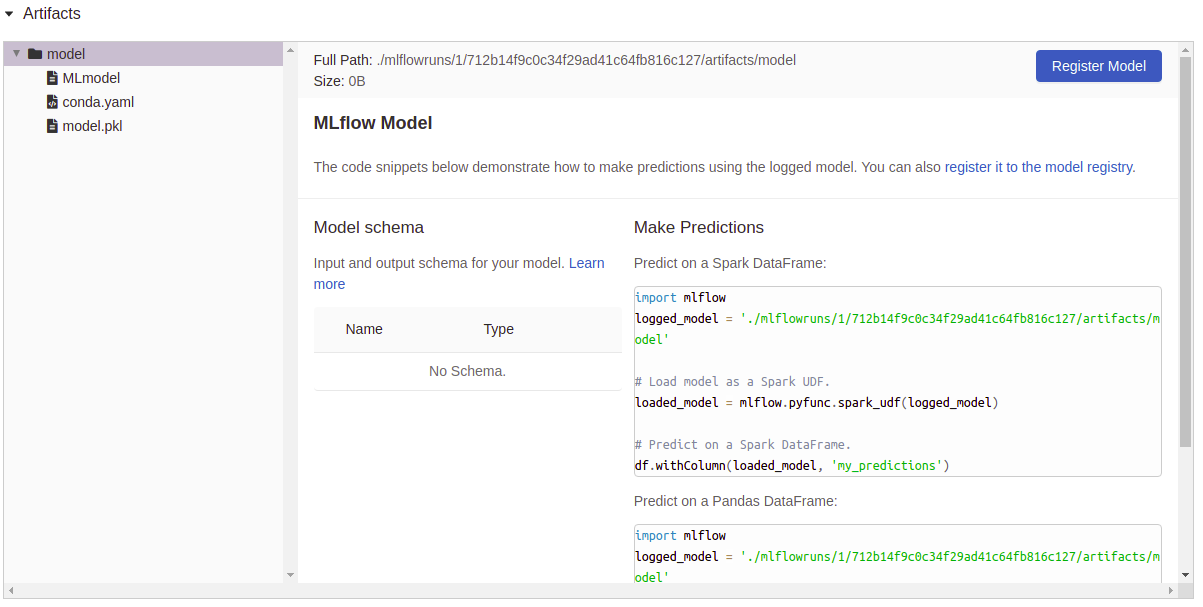
Артефакты регистрация:
Установите Sklearn-Genetic-Opt
Рекомендуется установить Sklearn-Genetic с использованием виртуальной Env, внутри Env:
PIP установить Sklearn-Genetic-Opt
Если вы хотите получить все функции, в том числе сюжетные возможности, Tensorboard и Mlflow Loggability, установите все дополнительные пакеты:
PIP установить Sklearn-Genetic-Opt [все]
from sklearn_genetic import GASearchCV
from sklearn_genetic . space import Continuous , Categorical , Integer
from sklearn . ensemble import RandomForestClassifier
from sklearn . model_selection import train_test_split , StratifiedKFold
from sklearn . datasets import load_digits
from sklearn . metrics import accuracy_score
data = load_digits ()
n_samples = len ( data . images )
X = data . images . reshape (( n_samples , - 1 ))
y = data [ 'target' ]
X_train , X_test , y_train , y_test = train_test_split ( X , y , test_size = 0.33 , random_state = 42 )
clf = RandomForestClassifier ()
# Defines the possible values to search
param_grid = { 'min_weight_fraction_leaf' : Continuous ( 0.01 , 0.5 , distribution = 'log-uniform' ),
'bootstrap' : Categorical ([ True , False ]),
'max_depth' : Integer ( 2 , 30 ),
'max_leaf_nodes' : Integer ( 2 , 35 ),
'n_estimators' : Integer ( 100 , 300 )}
# Seed solutions
warm_start_configs = [
{ "min_weight_fraction_leaf" : 0.02 , "bootstrap" : True , "max_depth" : None , "n_estimators" : 100 },
{ "min_weight_fraction_leaf" : 0.4 , "bootstrap" : True , "max_depth" : 5 , "n_estimators" : 200 },
]
cv = StratifiedKFold ( n_splits = 3 , shuffle = True )
evolved_estimator = GASearchCV ( estimator = clf ,
cv = cv ,
scoring = 'accuracy' ,
population_size = 20 ,
generations = 35 ,
param_grid = param_grid ,
n_jobs = - 1 ,
verbose = True ,
use_cache = True ,
warm_start_configs = warm_start_configs ,
keep_top_k = 4 )
# Train and optimize the estimator
evolved_estimator . fit ( X_train , y_train )
# Best parameters found
print ( evolved_estimator . best_params_ )
# Use the model fitted with the best parameters
y_predict_ga = evolved_estimator . predict ( X_test )
print ( accuracy_score ( y_test , y_predict_ga ))
# Saved metadata for further analysis
print ( "Stats achieved in each generation: " , evolved_estimator . history )
print ( "Best k solutions: " , evolved_estimator . hof ) from sklearn_genetic import GAFeatureSelectionCV , ExponentialAdapter
from sklearn . model_selection import train_test_split
from sklearn . svm import SVC
from sklearn . datasets import load_iris
from sklearn . metrics import accuracy_score
import numpy as np
data = load_iris ()
X , y = data [ "data" ], data [ "target" ]
# Add random non-important features
noise = np . random . uniform ( 5 , 10 , size = ( X . shape [ 0 ], 5 ))
X = np . hstack (( X , noise ))
X_train , X_test , y_train , y_test = train_test_split ( X , y , test_size = 0.33 , random_state = 0 )
clf = SVC ( gamma = 'auto' )
mutation_scheduler = ExponentialAdapter ( 0.8 , 0.2 , 0.01 )
crossover_scheduler = ExponentialAdapter ( 0.2 , 0.8 , 0.01 )
evolved_estimator = GAFeatureSelectionCV (
estimator = clf ,
scoring = "accuracy" ,
population_size = 30 ,
generations = 20 ,
mutation_probability = mutation_scheduler ,
crossover_probability = crossover_scheduler ,
n_jobs = - 1 )
# Train and select the features
evolved_estimator . fit ( X_train , y_train )
# Features selected by the algorithm
features = evolved_estimator . support_
print ( features )
# Predict only with the subset of selected features
y_predict_ga = evolved_estimator . predict ( X_test )
print ( accuracy_score ( y_test , y_predict_ga ))
# Transform the original data to the selected features
X_reduced = evolved_estimator . transform ( X_test )См. Чангейлог для заметок об изменениях Sklearn-Genetic-Opt
Вы можете проверить последнюю версию разработки с помощью команды:
git clone https://github.com/rodrigo-arenas/sklearn-genetic-opt.git
Установите зависимости разработки:
pip install -r dev -requirements.txt
Проверьте последнюю документацию в разработке: https://sklearn-genetic-opt.readthedocs.io/en/latest/
Взносы более чем приветствуются! Есть несколько возможностей в продолжающемся проекте, поэтому, пожалуйста, свяжитесь с нами, если вы хотите помочь. Обязательно проверьте текущие проблемы, а также руководство по взносу.
Большое спасибо людям, которые помогают с этим проектом!
После установки вы можете запустить тестовый набор извне исходного каталога:
pytest sklearn_genetic


