Sklearn genetic opt
0.11.1


Modelos Scikit-Learn Hyperparameters Ajuste e seleção de recursos, usando algoritmos evolutivos.
Isso deve ser uma alternativa aos métodos populares dentro do Scikit-Learn, como pesquisa de grade e busca randomizada de grade por ajuste de hiperparâmetros e, no RFE (Eliminação Recursiva de Recursos), selecione FROM MODELO PARA SELEÇÃO DE RECURSOS.
O Sklearn-Genetic-OPT usa algoritmos evolutivos do pacote DAEP (algoritmos evolutivos distribuídos no Python) para escolher o conjunto de hiperparâmetros que otimizam (máximo ou min) os escores de validação cruzada, pode ser usado para problemas de regressão e classificação.
A documentação está disponível aqui
Visualize o progresso do seu treinamento:
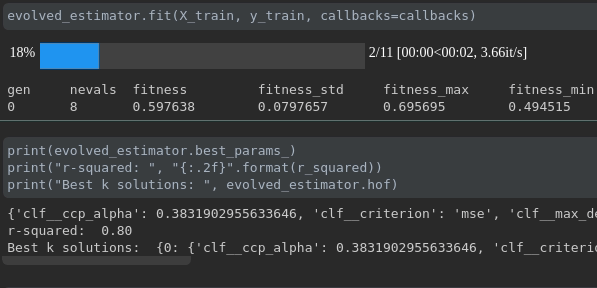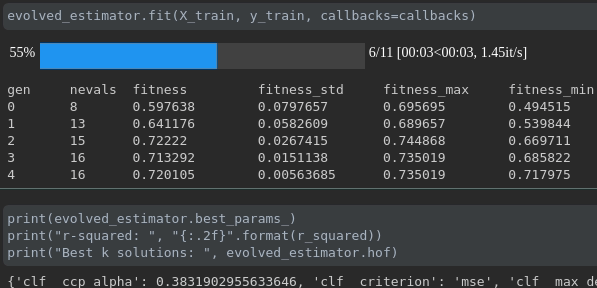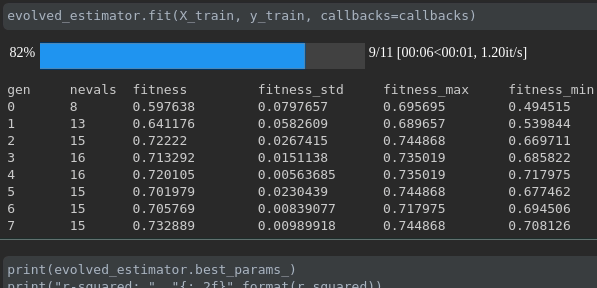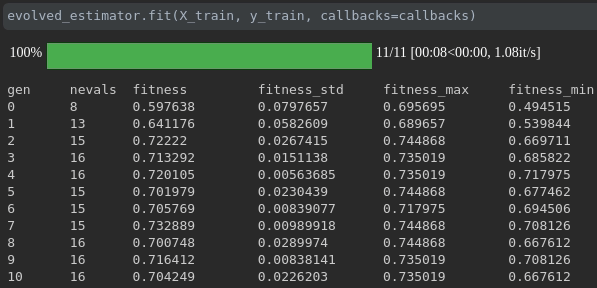
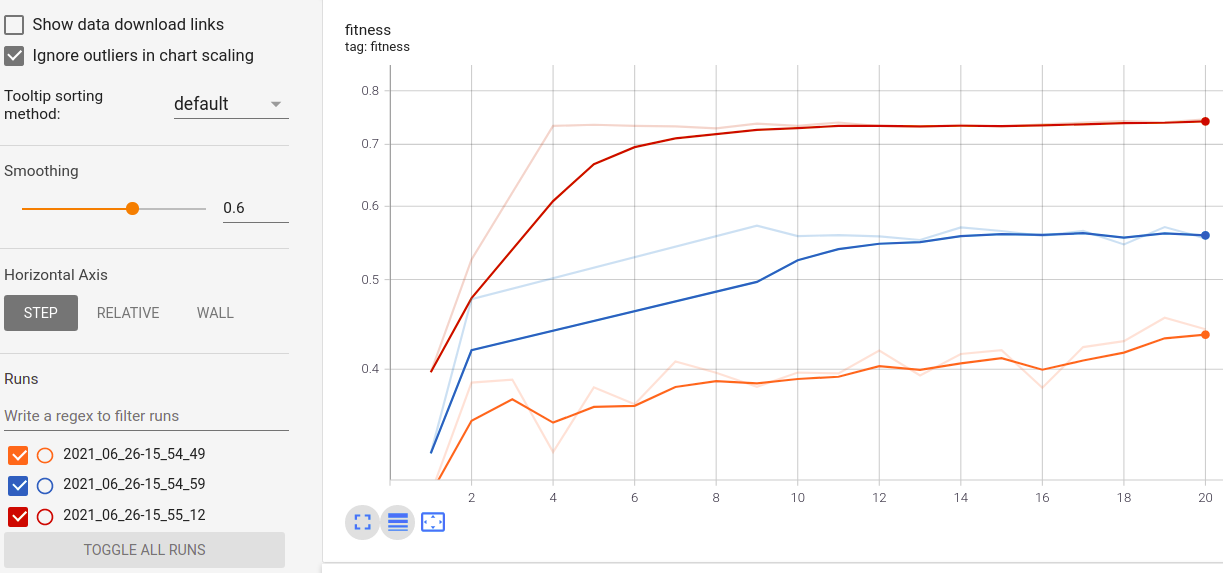
Visualização e comparação de métricas em tempo real em corridas:
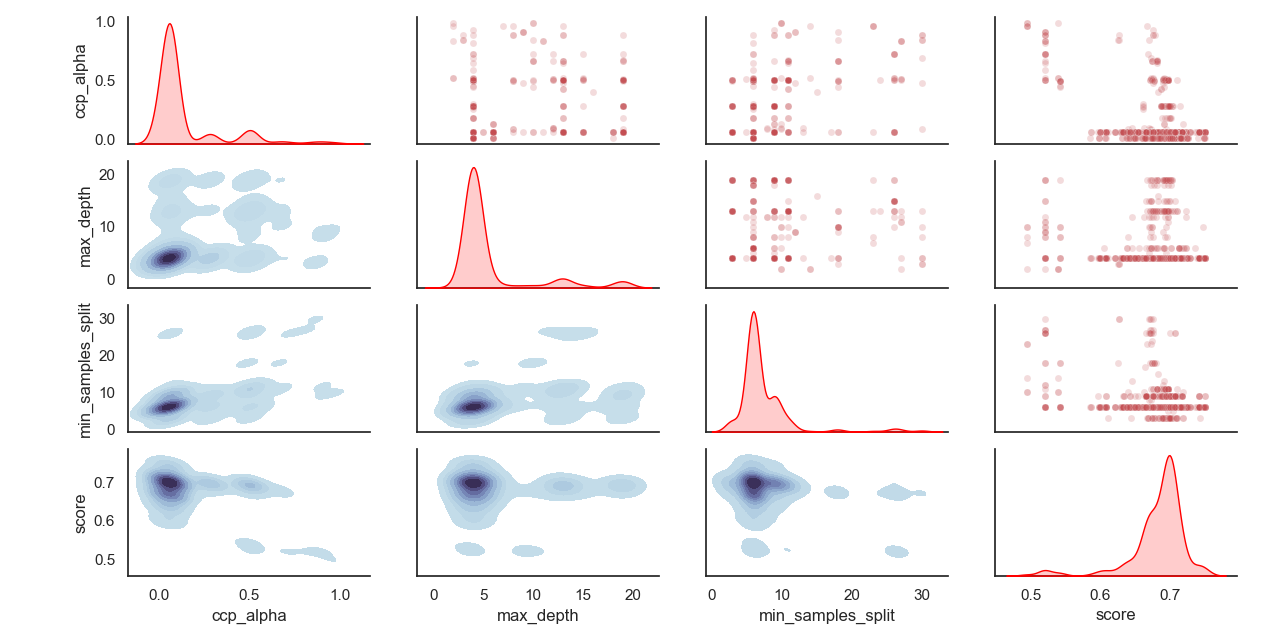
Distribuição amostrada de hiperparâmetros:
Artefatos registro:
Instale o Sklearn-Genetic-Opt
É aconselhado instalar o SkLearn-genético usando um Env virtual, dentro do Uso Env:
Pip Install Sklearn-Genetic-Opt
Se você deseja obter todos os recursos, incluindo a plotagem, os recursos de registro de tensorboard e MLFlow, instale todos os pacotes extras:
pip install sklearn-genetic-opt [all]
from sklearn_genetic import GASearchCV
from sklearn_genetic . space import Continuous , Categorical , Integer
from sklearn . ensemble import RandomForestClassifier
from sklearn . model_selection import train_test_split , StratifiedKFold
from sklearn . datasets import load_digits
from sklearn . metrics import accuracy_score
data = load_digits ()
n_samples = len ( data . images )
X = data . images . reshape (( n_samples , - 1 ))
y = data [ 'target' ]
X_train , X_test , y_train , y_test = train_test_split ( X , y , test_size = 0.33 , random_state = 42 )
clf = RandomForestClassifier ()
# Defines the possible values to search
param_grid = { 'min_weight_fraction_leaf' : Continuous ( 0.01 , 0.5 , distribution = 'log-uniform' ),
'bootstrap' : Categorical ([ True , False ]),
'max_depth' : Integer ( 2 , 30 ),
'max_leaf_nodes' : Integer ( 2 , 35 ),
'n_estimators' : Integer ( 100 , 300 )}
# Seed solutions
warm_start_configs = [
{ "min_weight_fraction_leaf" : 0.02 , "bootstrap" : True , "max_depth" : None , "n_estimators" : 100 },
{ "min_weight_fraction_leaf" : 0.4 , "bootstrap" : True , "max_depth" : 5 , "n_estimators" : 200 },
]
cv = StratifiedKFold ( n_splits = 3 , shuffle = True )
evolved_estimator = GASearchCV ( estimator = clf ,
cv = cv ,
scoring = 'accuracy' ,
population_size = 20 ,
generations = 35 ,
param_grid = param_grid ,
n_jobs = - 1 ,
verbose = True ,
use_cache = True ,
warm_start_configs = warm_start_configs ,
keep_top_k = 4 )
# Train and optimize the estimator
evolved_estimator . fit ( X_train , y_train )
# Best parameters found
print ( evolved_estimator . best_params_ )
# Use the model fitted with the best parameters
y_predict_ga = evolved_estimator . predict ( X_test )
print ( accuracy_score ( y_test , y_predict_ga ))
# Saved metadata for further analysis
print ( "Stats achieved in each generation: " , evolved_estimator . history )
print ( "Best k solutions: " , evolved_estimator . hof ) from sklearn_genetic import GAFeatureSelectionCV , ExponentialAdapter
from sklearn . model_selection import train_test_split
from sklearn . svm import SVC
from sklearn . datasets import load_iris
from sklearn . metrics import accuracy_score
import numpy as np
data = load_iris ()
X , y = data [ "data" ], data [ "target" ]
# Add random non-important features
noise = np . random . uniform ( 5 , 10 , size = ( X . shape [ 0 ], 5 ))
X = np . hstack (( X , noise ))
X_train , X_test , y_train , y_test = train_test_split ( X , y , test_size = 0.33 , random_state = 0 )
clf = SVC ( gamma = 'auto' )
mutation_scheduler = ExponentialAdapter ( 0.8 , 0.2 , 0.01 )
crossover_scheduler = ExponentialAdapter ( 0.2 , 0.8 , 0.01 )
evolved_estimator = GAFeatureSelectionCV (
estimator = clf ,
scoring = "accuracy" ,
population_size = 30 ,
generations = 20 ,
mutation_probability = mutation_scheduler ,
crossover_probability = crossover_scheduler ,
n_jobs = - 1 )
# Train and select the features
evolved_estimator . fit ( X_train , y_train )
# Features selected by the algorithm
features = evolved_estimator . support_
print ( features )
# Predict only with the subset of selected features
y_predict_ga = evolved_estimator . predict ( X_test )
print ( accuracy_score ( y_test , y_predict_ga ))
# Transform the original data to the selected features
X_reduced = evolved_estimator . transform ( X_test )Veja o Changelog para obter as notas sobre as mudanças do Sklearn-Genetic-Opt
Você pode verificar a versão mais recente de desenvolvimento com o comando:
Git clone https://github.com/rodrigo-arenas/sklearn-genetic-opt.git
Instale as dependências de desenvolvimento:
pip install -r dev -requirements.txt
Verifique a mais recente documentação no desenvolvimento: https://sklearn-genetic-opt.readthedocs.io/en/latest/
As contribuições são mais do que bem -vindas! Existem várias oportunidades no projeto em andamento; portanto, entre em contato se quiser ajudar. Verifique os problemas atuais e também o guia de contribuição.
Muito obrigado às pessoas que estão ajudando neste projeto!
Após a instalação, você pode iniciar o conjunto de testes de fora do diretório de origem:
pytest sklearn_genetic


