vector quantize pytorch
1.20.11
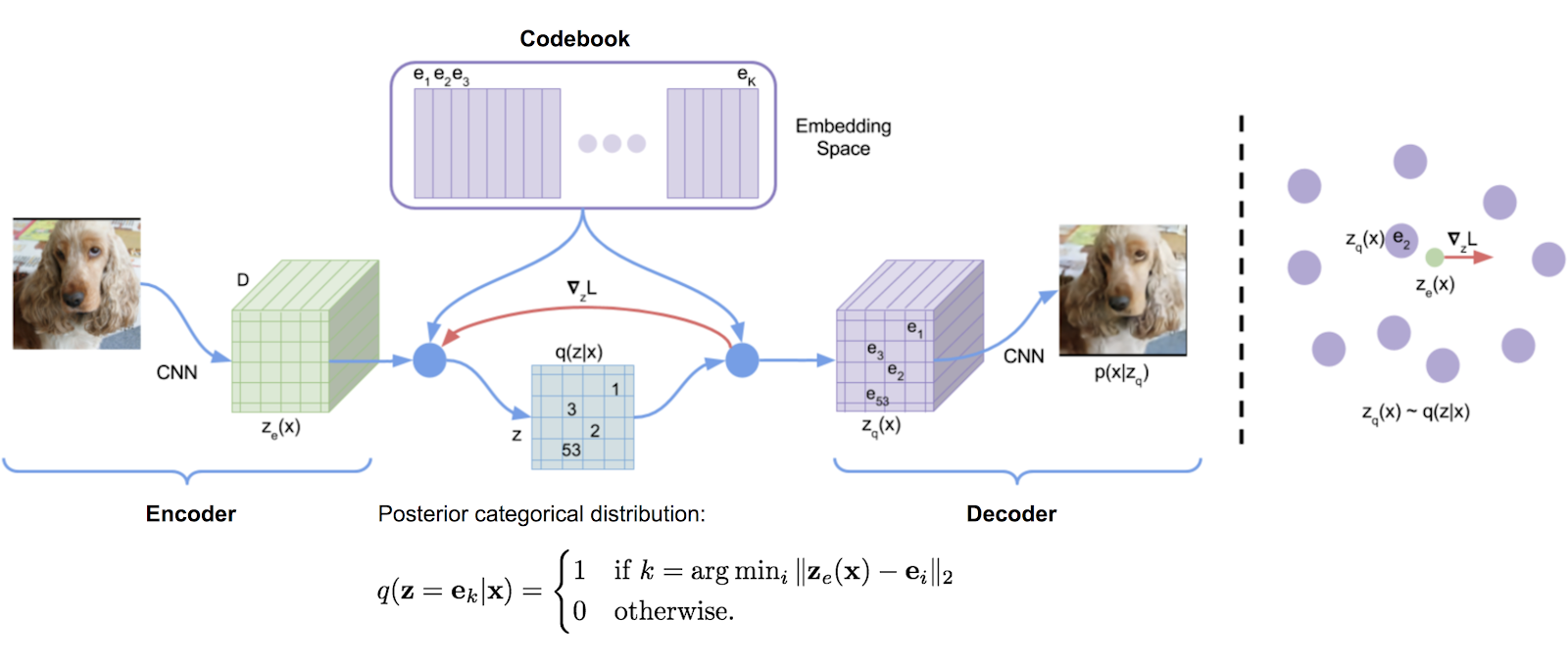
Uma biblioteca de quantização de vetores transcrita originalmente da implementação do DeepMind TensorFlow, transformada convenientemente em um pacote. Ele usa médias móveis exponenciais para atualizar o dicionário.
O VQ foi usado com sucesso por DeepMind e OpenAI para geração de imagens de alta qualidade (VQ-VAE-2) e música (jukebox).
$ pip install vector-quantize-pytorch import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_size = 512 , # codebook size
decay = 0.8 , # the exponential moving average decay, lower means the dictionary will change faster
commitment_weight = 1. # the weight on the commitment loss
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = vq ( x ) # (1, 1024, 256), (1, 1024), (1) Este artigo propõe usar vários quantizadores de vetores para quantizar recursivamente os resíduos da forma de onda. Você pode usar isso com a classe ResidualVQ e um parâmetro de inicialização extra.
import torch
from vector_quantize_pytorch import ResidualVQ
residual_vq = ResidualVQ (
dim = 256 ,
num_quantizers = 8 , # specify number of quantizers
codebook_size = 1024 , # codebook size
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = residual_vq ( x )
print ( quantized . shape , indices . shape , commit_loss . shape )
# (1, 1024, 256), (1, 1024, 8), (1, 8)
# if you need all the codes across the quantization layers, just pass return_all_codes = True
quantized , indices , commit_loss , all_codes = residual_vq ( x , return_all_codes = True )
# (8, 1, 1024, 256)Além disso, este artigo usa VQ residual para construir o RQ-VAE, para gerar imagens de alta resolução com códigos mais compactados.
Eles fazem duas modificações. O primeiro é compartilhar o livro de códigos em todos os quantizadores. O segundo é amostrar estocástica os códigos, em vez de sempre levar a partida mais próxima. Você pode usar esses dois recursos com dois argumentos de palavras -chave extras.
import torch
from vector_quantize_pytorch import ResidualVQ
residual_vq = ResidualVQ (
dim = 256 ,
num_quantizers = 8 ,
codebook_size = 1024 ,
stochastic_sample_codes = True ,
sample_codebook_temp = 0.1 , # temperature for stochastically sampling codes, 0 would be equivalent to non-stochastic
shared_codebook = True # whether to share the codebooks for all quantizers or not
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = residual_vq ( x )
# (1, 1024, 256), (1, 1024, 8), (1, 8) Um artigo recente propõe ainda fazer VQ residual sobre grupos da dimensão do recurso, mostrando resultados equivalentes ao Encodec enquanto usam muito menos livros de código. Você pode usá -lo importando GroupedResidualVQ
import torch
from vector_quantize_pytorch import GroupedResidualVQ
residual_vq = GroupedResidualVQ (
dim = 256 ,
num_quantizers = 8 , # specify number of quantizers
groups = 2 ,
codebook_size = 1024 , # codebook size
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = residual_vq ( x )
# (1, 1024, 256), (2, 1, 1024, 8), (2, 1, 8) O papel SoundStream propõe que o livro de códigos seja inicializado pelos centróides Kmeans do primeiro lote. Você pode ativar facilmente esse recurso com uma bandeira kmeans_init = True , para a classe VectorQuantize ou ResidualVQ
import torch
from vector_quantize_pytorch import ResidualVQ
residual_vq = ResidualVQ (
dim = 256 ,
codebook_size = 256 ,
num_quantizers = 4 ,
kmeans_init = True , # set to True
kmeans_iters = 10 # number of kmeans iterations to calculate the centroids for the codebook on init
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = residual_vq ( x )
# (1, 1024, 256), (1, 1024, 4), (1, 4) VQ-VAES são tradicionalmente treinados com o estimador direto (STE). Durante o passe para trás, o gradiente flui ao redor da camada VQ e não através dela. O papel do truque de rotação propõe transformar o gradiente através da camada VQ, de modo que o ângulo relativo e a magnitude entre o vetor de entrada e a saída quantizada são codificados no gradiente. Você pode ativar ou desativar esse recurso com rotation_trick=True/False na classe VectorQuantize .
from vector_quantize_pytorch import VectorQuantize
vq_layer = VectorQuantize (
dim = 256 ,
codebook_size = 256 ,
rotation_trick = True , # Set to False to use the STE gradient estimator or True to use the rotation trick.
)Este repositório conterá algumas técnicas de vários artigos para combater as entradas dos livros de código "mortos", o que é um problema comum ao usar quantizadores de vetores.
O artigo VQGAN aprimorado propõe que o livro de códigos mantenha em uma dimensão mais baixa. Os valores do codificador são projetados para baixo antes de serem projetados de volta à alta dimensão após a quantização. Você pode definir isso com o codebook_dim HyperParameter.
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_size = 256 ,
codebook_dim = 16 # paper proposes setting this to 32 or as low as 8 to increase codebook usage
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = vq ( x )
# (1, 1024, 256), (1, 1024), (1,) O papel VQGAN aprimorado também propõe que L2 normalize os códigos e os vetores codificados, que se resumem ao uso da similaridade de cosseno para a distância. Eles afirmam que a aplicação dos vetores em uma esfera leva a melhorias no uso de código e reconstrução a jusante. Você pode ativar isso definindo use_cosine_sim = True
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_size = 256 ,
use_cosine_sim = True # set this to True
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = vq ( x )
# (1, 1024, 256), (1, 1024), (1,) Finalmente, o papel SoundStream possui um esquema em que eles substituem os códigos que têm hits abaixo de um certo limite com vetor selecionado aleatoriamente do lote atual. Você pode definir esse limite com a palavra -chave threshold_ema_dead_code .
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_size = 512 ,
threshold_ema_dead_code = 2 # should actively replace any codes that have an exponential moving average cluster size less than 2
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = vq ( x )
# (1, 1024, 256), (1, 1024), (1,)O VQ-VAE / VQ-GAN está rapidamente ganhando popularidade. Um artigo recente propõe que, ao usar a quantização de vetores nas imagens, a aplicação do livro de códigos é ortogonal, leva à equivalência da tradução dos códigos discretizados, levando a grandes melhorias no texto a jusante para as tarefas de geração de imagens.
Você pode usar esse recurso simplesmente definindo o orthogonal_reg_weight como maior que 0 ; nesse caso, a regularização ortogonal será adicionada à perda auxiliar emitida pelo módulo.
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_size = 256 ,
accept_image_fmap = True , # set this true to be able to pass in an image feature map
orthogonal_reg_weight = 10 , # in paper, they recommended a value of 10
orthogonal_reg_max_codes = 128 , # this would randomly sample from the codebook for the orthogonal regularization loss, for limiting memory usage
orthogonal_reg_active_codes_only = False # set this to True if you have a very large codebook, and would only like to enforce the loss on the activated codes per batch
)
img_fmap = torch . randn ( 1 , 256 , 32 , 32 )
quantized , indices , loss = vq ( img_fmap ) # (1, 256, 32, 32), (1, 32, 32), (1,)
# loss now contains the orthogonal regularization loss with the weight as assigned Houve vários artigos que propõem variantes de representações latentes discretas com uma abordagem de várias cabeças (vários códigos por recurso). Decidi oferecer uma variante em que o mesmo livro de códigos é usado para vetorizar quantizar nos tempos head da dimensão de entrada.
Você também pode usar uma abordagem mais comprovada (MemCodes) do NWT Paper
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_dim = 32 , # a number of papers have shown smaller codebook dimension to be acceptable
heads = 8 , # number of heads to vector quantize, codebook shared across all heads
separate_codebook_per_head = True , # whether to have a separate codebook per head. False would mean 1 shared codebook
codebook_size = 8196 ,
accept_image_fmap = True
)
img_fmap = torch . randn ( 1 , 256 , 32 , 32 )
quantized , indices , loss = vq ( img_fmap )
# (1, 256, 32, 32), (1, 32, 32, 8), (1,)Este documento propôs primeiro usar um quantizador de projeção aleatória para modelagem de fala mascarada, onde os sinais são projetados com uma matriz inicializada aleatoriamente e depois combinados com um livro de código inicializado aleatório. Portanto, não é necessário aprender o quantizador. Essa técnica foi usada pelo modelo de fala universal do Google para obter o SOTA para modelagem de fala para texto.
O USM propõe ainda usar o livro de código múltiplo e a modelagem de fala mascarada com um objetivo multi-Softmax. Você pode fazer isso facilmente definindo num_codebooks
import torch
from vector_quantize_pytorch import RandomProjectionQuantizer
quantizer = RandomProjectionQuantizer (
dim = 512 , # input dimensions
num_codebooks = 16 , # in USM, they used up to 16 for 5% gain
codebook_dim = 256 , # codebook dimension
codebook_size = 1024 # codebook size
)
x = torch . randn ( 1 , 1024 , 512 )
indices = quantizer ( x )
# (1, 1024, 16) Esse repositório também deve sincronizar automaticamente os cadernos de código em uma configuração de vários processos. Se de alguma forma não for, abra um problema. Você pode substituir se deve sincronizar os cadernos de código ou não configurando sync_codebook = True | False

Um novo artigo do ICLR 2025 propõe um esquema em que o livro de código está congelado e os códigos são gerados implicitamente através de uma projeção linear. Os autores afirmam que essa configuração leva a menos colapso do livro de códigos e à convergência mais fácil. Descobri isso para ter um desempenho ainda melhor quando combinado com o truque de rotação de Fifty et al., E expandindo a projeção linear para um pequeno MLP de uma camada. Você pode experimentar com isso como
ATUALIZA
import torch
from vector_quantize_pytorch import SimVQ
sim_vq = SimVQ (
dim = 512 ,
codebook_size = 1024 ,
rotation_trick = True # use rotation trick from Fifty et al.
)
x = torch . randn ( 1 , 1024 , 512 )
quantized , indices , commit_loss = sim_vq ( x )
assert x . shape == quantized . shape
assert torch . allclose ( quantized , sim_vq . indices_to_codes ( indices ), atol = 1e-6 ) Para o sabor residual, basta importar ResidualSimVQ
import torch
from vector_quantize_pytorch import ResidualSimVQ
residual_sim_vq = ResidualSimVQ (
dim = 512 ,
num_quantizers = 4 ,
codebook_size = 1024 ,
rotation_trick = True # use rotation trick from Fifty et al.
)
x = torch . randn ( 1 , 1024 , 512 )
quantized , indices , commit_loss = residual_sim_vq ( x )
assert x . shape == quantized . shape
assert torch . allclose ( quantized , residual_sim_vq . get_output_from_indices ( indices ), atol = 1e-6 )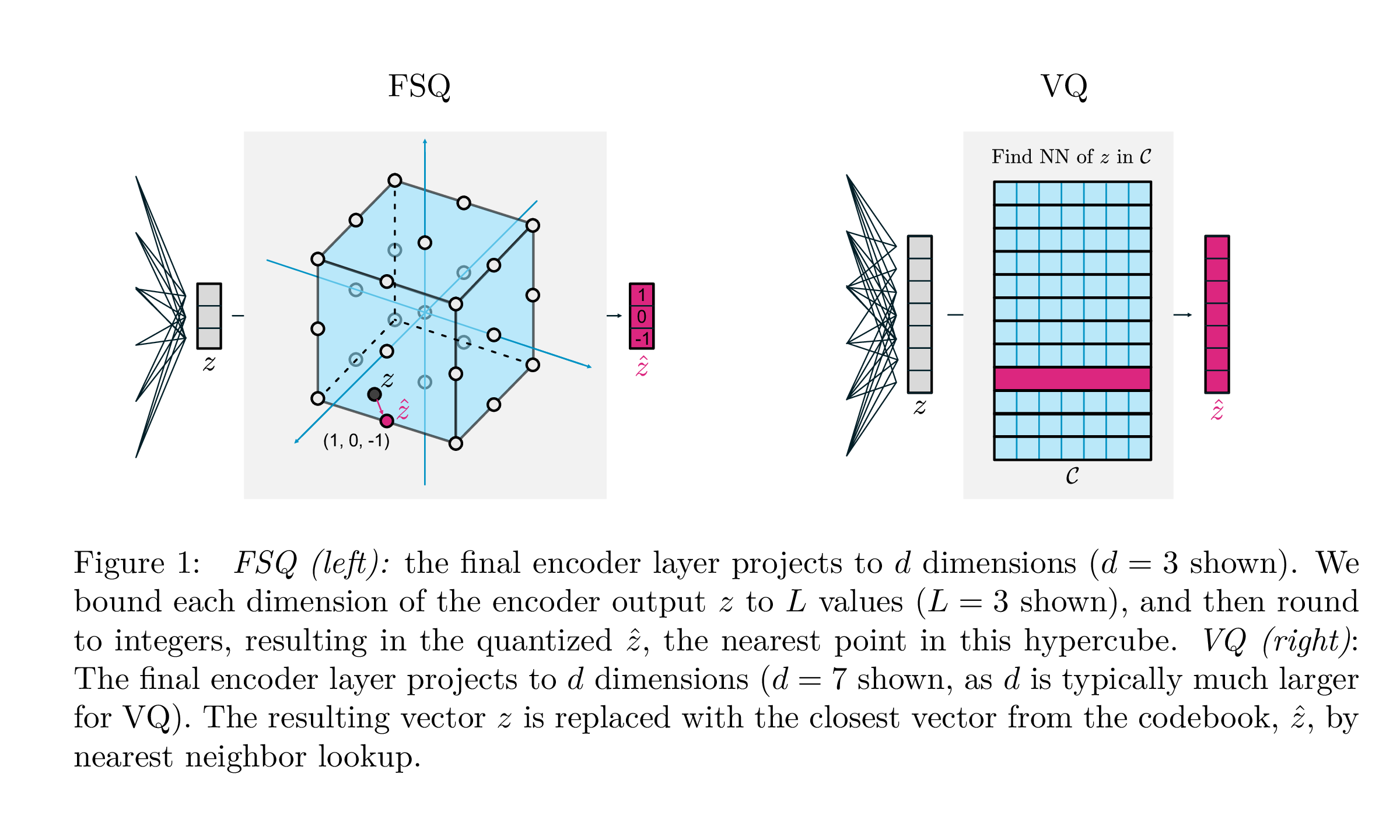
| Vq | Fsq | |
|---|---|---|
| Quantização | argmin_c || ZC || | redonda (f (z)) |
| Gradientes | Diretamente através da estimativa (ste) | Ste |
| Perdas auxiliares | Compromisso, livro de código, perda de entropia, ... | N / D |
| Truques | EMA no código de código, divisão de código de código, projeções, ... | N / D |
| Parâmetros | Código | N / D |
Este trabalho do Google DeepMind visa simplificar amplamente a maneira como a quantização do vetor é feita para modelagem generativa, removendo a necessidade de perdas de compromisso, a atualização da EMA do livro de códigos, além de abordar os problemas com o colapso do livro de código ou a utilização insuficiente. Eles simplesmente arredondam cada escalar em níveis discretos, com gradientes diretos; Os códigos se tornam pontos uniformes em um hipercubo.
Agradecemos a @Sekstini por portar essa implementação em tempo recorde!
import torch
from vector_quantize_pytorch import FSQ
quantizer = FSQ (
levels = [ 8 , 5 , 5 , 5 ]
)
x = torch . randn ( 1 , 1024 , 4 ) # 4 since there are 4 levels
xhat , indices = quantizer ( x )
# (1, 1024, 4), (1, 1024)
assert torch . all ( xhat == quantizer . indices_to_codes ( indices ))Um FSQ residual improvisado, para uma tentativa de melhorar a codificação de áudio.
Crédito vai para @Sekstini para organizar originalmente a ideia aqui
import torch
from vector_quantize_pytorch import ResidualFSQ
residual_fsq = ResidualFSQ (
dim = 256 ,
levels = [ 8 , 5 , 5 , 3 ],
num_quantizers = 8
)
x = torch . randn ( 1 , 1024 , 256 )
residual_fsq . eval ()
quantized , indices = residual_fsq ( x )
# (1, 1024, 256), (1, 1024, 8)
quantized_out = residual_fsq . get_output_from_indices ( indices )
# (1, 1024, 256)
assert torch . all ( quantized == quantized_out )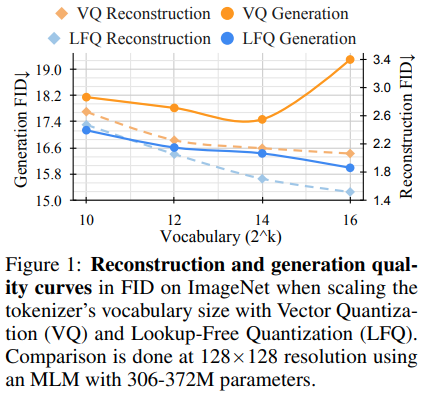
A equipe de pesquisa por trás da Magvit divulgou novos resultados da SOTA para modelagem generativa de vídeos. Uma mudança de núcleo entre V1 e V2 inclui um novo tipo de quantização, quantização livre de pesquisa (LFQ), que elimina o livro de código e a pesquisa inteiramente incorporada.
Este artigo apresenta um quantizador simples de LFQ do uso de latentes binários independentes. Existem outras implementações do LFQ. No entanto, a equipe mostra que o MAGVIT-V2 com o LFQ melhora significativamente o benchmark ImageNet. As diferenças entre o LFQ e o FSQ de 2 níveis incluem regularizações de entropia, além de perda de compromisso mantida.
O desenvolvimento de um método mais avançado de quantização de LFQ sem o ponto de vista do livro de código pode revolucionar a modelagem generativa.
Você pode usá -lo simplesmente da seguinte maneira. Será com alimentos para cães na porta Magvit2 Pytorch
import torch
from vector_quantize_pytorch import LFQ
# you can specify either dim or codebook_size
# if both specified, will be validated against each other
quantizer = LFQ (
codebook_size = 65536 , # codebook size, must be a power of 2
dim = 16 , # this is the input feature dimension, defaults to log2(codebook_size) if not defined
entropy_loss_weight = 0.1 , # how much weight to place on entropy loss
diversity_gamma = 1. # within entropy loss, how much weight to give to diversity of codes, taken from https://arxiv.org/abs/1911.05894
)
image_feats = torch . randn ( 1 , 16 , 32 , 32 )
quantized , indices , entropy_aux_loss = quantizer ( image_feats , inv_temperature = 100. ) # you may want to experiment with temperature
# (1, 16, 32, 32), (1, 32, 32), ()
assert ( quantized == quantizer . indices_to_codes ( indices )). all () Você também pode passar nos recursos de vídeo como (batch, feat, time, height, width) ou seqüências como (batch, seq, feat)
import torch
from vector_quantize_pytorch import LFQ
quantizer = LFQ (
codebook_size = 65536 ,
dim = 16 ,
entropy_loss_weight = 0.1 ,
diversity_gamma = 1.
)
seq = torch . randn ( 1 , 32 , 16 )
quantized , * _ = quantizer ( seq )
assert seq . shape == quantized . shape
video_feats = torch . randn ( 1 , 16 , 10 , 32 , 32 )
quantized , * _ = quantizer ( video_feats )
assert video_feats . shape == quantized . shapeOu apoiar vários cadernos de código
import torch
from vector_quantize_pytorch import LFQ
quantizer = LFQ (
codebook_size = 4096 ,
dim = 16 ,
num_codebooks = 4 # 4 codebooks, total codebook dimension is log2(4096) * 4
)
image_feats = torch . randn ( 1 , 16 , 32 , 32 )
quantized , indices , entropy_aux_loss = quantizer ( image_feats )
# (1, 16, 32, 32), (1, 32, 32, 4), ()
assert image_feats . shape == quantized . shape
assert ( quantized == quantizer . indices_to_codes ( indices )). all ()Um LFQ residual improvisado, para ver se pode levar a uma melhoria para a compactação de áudio.
import torch
from vector_quantize_pytorch import ResidualLFQ
residual_lfq = ResidualLFQ (
dim = 256 ,
codebook_size = 256 ,
num_quantizers = 8
)
x = torch . randn ( 1 , 1024 , 256 )
residual_lfq . eval ()
quantized , indices , commit_loss = residual_lfq ( x )
# (1, 1024, 256), (1, 1024, 8), (8)
quantized_out = residual_lfq . get_output_from_indices ( indices )
# (1, 1024, 256)
assert torch . all ( quantized == quantized_out )A desajeitado é essencial para o aprendizado de representação, pois promove a interpretabilidade, a generalização, a aprendizagem aprimorada e a robustez. Ele se alinha com o objetivo de capturar características significativas e independentes dos dados, facilitando o uso mais eficaz de representações aprendidas em vários aplicativos. Para uma melhor desajeitação, o desafio é desintegrar variações subjacentes em um conjunto de dados sem informações explícitas da verdade. Este trabalho apresenta um viés indutivo -chave destinado a codificar e decodificar dentro de um espaço latente organizado. A estratégia incorporada abrange discretizando o espaço latente, atribuindo vetores de código discretos através da utilização de um livro de código escalar aprendizado individual para cada dimensão. Essa metodologia permite que seus modelos superem efetivamente métodos anteriores robustos.
Esteja ciente de que eles tiveram que usar uma decaimento de peso muito alto para os resultados deste artigo.
import torch
from vector_quantize_pytorch import LatentQuantize
# you can specify either dim or codebook_size
# if both specified, will be validated against each other
quantizer = LatentQuantize (
levels = [ 5 , 5 , 8 ], # number of levels per codebook dimension
dim = 16 , # input dim
commitment_loss_weight = 0.1 ,
quantization_loss_weight = 0.1 ,
)
image_feats = torch . randn ( 1 , 16 , 32 , 32 )
quantized , indices , loss = quantizer ( image_feats )
# (1, 16, 32, 32), (1, 32, 32), ()
assert image_feats . shape == quantized . shape
assert ( quantized == quantizer . indices_to_codes ( indices )). all () Você também pode passar nos recursos de vídeo como (batch, feat, time, height, width) ou seqüências como (batch, seq, feat)
import torch
from vector_quantize_pytorch import LatentQuantize
quantizer = LatentQuantize (
levels = [ 5 , 5 , 8 ],
dim = 16 ,
commitment_loss_weight = 0.1 ,
quantization_loss_weight = 0.1 ,
)
seq = torch . randn ( 1 , 32 , 16 )
quantized , * _ = quantizer ( seq )
# (1, 32, 16)
video_feats = torch . randn ( 1 , 16 , 10 , 32 , 32 )
quantized , * _ = quantizer ( video_feats )
# (1, 16, 10, 32, 32)Ou apoiar vários cadernos de código
import torch
from vector_quantize_pytorch import LatentQuantize
model = LatentQuantize (
levels = [ 4 , 8 , 16 ],
dim = 9 ,
num_codebooks = 3
)
input_tensor = torch . randn ( 2 , 3 , dim )
output_tensor , indices , loss = model ( input_tensor )
# (2, 3, 9), (2, 3, 3), ()
assert output_tensor . shape == input_tensor . shape
assert indices . shape == ( 2 , 3 , num_codebooks )
assert loss . item () >= 0 @misc { oord2018neural ,
title = { Neural Discrete Representation Learning } ,
author = { Aaron van den Oord and Oriol Vinyals and Koray Kavukcuoglu } ,
year = { 2018 } ,
eprint = { 1711.00937 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { zeghidour2021soundstream ,
title = { SoundStream: An End-to-End Neural Audio Codec } ,
author = { Neil Zeghidour and Alejandro Luebs and Ahmed Omran and Jan Skoglund and Marco Tagliasacchi } ,
year = { 2021 } ,
eprint = { 2107.03312 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.SD }
} @inproceedings { anonymous2022vectorquantized ,
title = { Vector-quantized Image Modeling with Improved {VQGAN} } ,
author = { Anonymous } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=pfNyExj7z2 } ,
note = { under review }
} @inproceedings { lee2022autoregressive ,
title = { Autoregressive Image Generation using Residual Quantization } ,
author = { Lee, Doyup and Kim, Chiheon and Kim, Saehoon and Cho, Minsu and Han, Wook-Shin } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition } ,
pages = { 11523--11532 } ,
year = { 2022 }
} @article { Defossez2022HighFN ,
title = { High Fidelity Neural Audio Compression } ,
author = { Alexandre D'efossez and Jade Copet and Gabriel Synnaeve and Yossi Adi } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.13438 }
} @inproceedings { Chiu2022SelfsupervisedLW ,
title = { Self-supervised Learning with Random-projection Quantizer for Speech Recognition } ,
author = { Chung-Cheng Chiu and James Qin and Yu Zhang and Jiahui Yu and Yonghui Wu } ,
booktitle = { International Conference on Machine Learning } ,
year = { 2022 }
} @inproceedings { Zhang2023GoogleUS ,
title = { Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages } ,
author = { Yu Zhang and Wei Han and James Qin and Yongqiang Wang and Ankur Bapna and Zhehuai Chen and Nanxin Chen and Bo Li and Vera Axelrod and Gary Wang and Zhong Meng and Ke Hu and Andrew Rosenberg and Rohit Prabhavalkar and Daniel S. Park and Parisa Haghani and Jason Riesa and Ginger Perng and Hagen Soltau and Trevor Strohman and Bhuvana Ramabhadran and Tara N. Sainath and Pedro J. Moreno and Chung-Cheng Chiu and Johan Schalkwyk and Franccoise Beaufays and Yonghui Wu } ,
year = { 2023 }
} @inproceedings { Shen2023NaturalSpeech2L ,
title = { NaturalSpeech 2: Latent Diffusion Models are Natural and Zero-Shot Speech and Singing Synthesizers } ,
author = { Kai Shen and Zeqian Ju and Xu Tan and Yanqing Liu and Yichong Leng and Lei He and Tao Qin and Sheng Zhao and Jiang Bian } ,
year = { 2023 }
} @inproceedings { Yang2023HiFiCodecGV ,
title = { HiFi-Codec: Group-residual Vector quantization for High Fidelity Audio Codec } ,
author = { Dongchao Yang and Songxiang Liu and Rongjie Huang and Jinchuan Tian and Chao Weng and Yuexian Zou } ,
year = { 2023 }
} @inproceedings { huh2023improvedvqste ,
title = { Straightening Out the Straight-Through Estimator: Overcoming Optimization Challenges in Vector Quantized Networks } ,
author = { Huh, Minyoung and Cheung, Brian and Agrawal, Pulkit and Isola, Phillip } ,
booktitle = { International Conference on Machine Learning } ,
year = { 2023 } ,
organization = { PMLR }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @misc { shin2021translationequivariant ,
title = { Translation-equivariant Image Quantizer for Bi-directional Image-Text Generation } ,
author = { Woncheol Shin and Gyubok Lee and Jiyoung Lee and Joonseok Lee and Edward Choi } ,
year = { 2021 } ,
eprint = { 2112.00384 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { mentzer2023finite ,
title = { Finite Scalar Quantization: VQ-VAE Made Simple } ,
author = { Fabian Mentzer and David Minnen and Eirikur Agustsson and Michael Tschannen } ,
year = { 2023 } ,
eprint = { 2309.15505 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { yu2023language ,
title = { Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation } ,
author = { Lijun Yu and José Lezama and Nitesh B. Gundavarapu and Luca Versari and Kihyuk Sohn and David Minnen and Yong Cheng and Agrim Gupta and Xiuye Gu and Alexander G. Hauptmann and Boqing Gong and Ming-Hsuan Yang and Irfan Essa and David A. Ross and Lu Jiang } ,
year = { 2023 } ,
eprint = { 2310.05737 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @inproceedings { Zhao2024ImageAV ,
title = { Image and Video Tokenization with Binary Spherical Quantization } ,
author = { Yue Zhao and Yuanjun Xiong and Philipp Krahenbuhl } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:270380237 }
} @misc { hsu2023disentanglement ,
title = { Disentanglement via Latent Quantization } ,
author = { Kyle Hsu and Will Dorrell and James C. R. Whittington and Jiajun Wu and Chelsea Finn } ,
year = { 2023 } ,
eprint = { 2305.18378 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @inproceedings { Irie2023SelfOrganisingND ,
title = { Self-Organising Neural Discrete Representation Learning `a la Kohonen } ,
author = { Kazuki Irie and R'obert Csord'as and J{"u}rgen Schmidhuber } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:256901024 }
} @article { Huijben2024ResidualQW ,
title = { Residual Quantization with Implicit Neural Codebooks } ,
author = { Iris Huijben and Matthijs Douze and Matthew Muckley and Ruud van Sloun and Jakob Verbeek } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2401.14732 } ,
url = { https://api.semanticscholar.org/CorpusID:267301189 }
} @article { Fifty2024Restructuring ,
title = { Restructuring Vector Quantization with the Rotation Trick } ,
author = { Christopher Fifty, Ronald G. Junkins, Dennis Duan, Aniketh Iyengar, Jerry W. Liu, Ehsan Amid, Sebastian Thrun, Christopher Ré } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2410.06424 } ,
url = { https://api.semanticscholar.org/CorpusID:273229218 }
} @inproceedings { Zhu2024AddressingRC ,
title = { Addressing Representation Collapse in Vector Quantized Models with One Linear Layer } ,
author = { Yongxin Zhu and Bocheng Li and Yifei Xin and Linli Xu } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273812459 }
}

