vector quantize pytorch
1.20.11
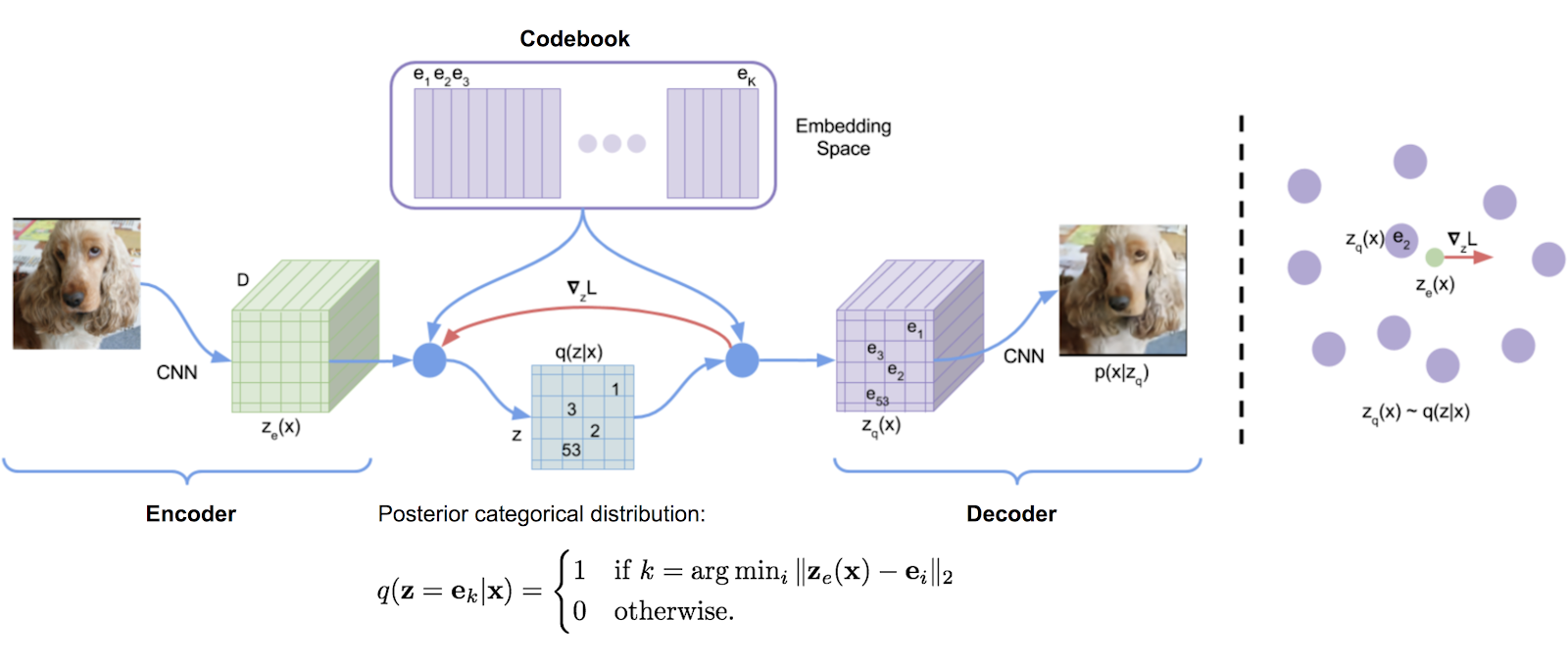
Une bibliothèque de quantification vectorielle transcrite à l'origine à partir de l'implémentation TensorFlow de DeepMind, transformé en un package. Il utilise des moyennes mobiles exponentielles pour mettre à jour le dictionnaire.
VQ a été utilisé avec succès par DeepMind et Openai pour une génération d'images de haute qualité (VQ-VAE-2) et de musique (juke-box).
$ pip install vector-quantize-pytorch import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_size = 512 , # codebook size
decay = 0.8 , # the exponential moving average decay, lower means the dictionary will change faster
commitment_weight = 1. # the weight on the commitment loss
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = vq ( x ) # (1, 1024, 256), (1, 1024), (1) Cet article propose d'utiliser plusieurs quantificateurs vectoriels pour quantifier récursivement les résidus de la forme d'onde. Vous pouvez l'utiliser avec la classe ResidualVQ et un paramètre d'initialisation supplémentaire.
import torch
from vector_quantize_pytorch import ResidualVQ
residual_vq = ResidualVQ (
dim = 256 ,
num_quantizers = 8 , # specify number of quantizers
codebook_size = 1024 , # codebook size
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = residual_vq ( x )
print ( quantized . shape , indices . shape , commit_loss . shape )
# (1, 1024, 256), (1, 1024, 8), (1, 8)
# if you need all the codes across the quantization layers, just pass return_all_codes = True
quantized , indices , commit_loss , all_codes = residual_vq ( x , return_all_codes = True )
# (8, 1, 1024, 256)En outre, cet article utilise le résidu-VQ pour construire le RQ-VAE, pour générer des images haute résolution avec des codes plus compressés.
Ils apportent deux modifications. La première consiste à partager le livre de codes sur tous les quantification. La seconde consiste à goûter stochastiquement les codes plutôt que de toujours prendre la correspondance la plus proche. Vous pouvez utiliser ces deux fonctionnalités avec deux arguments de mots clés supplémentaires.
import torch
from vector_quantize_pytorch import ResidualVQ
residual_vq = ResidualVQ (
dim = 256 ,
num_quantizers = 8 ,
codebook_size = 1024 ,
stochastic_sample_codes = True ,
sample_codebook_temp = 0.1 , # temperature for stochastically sampling codes, 0 would be equivalent to non-stochastic
shared_codebook = True # whether to share the codebooks for all quantizers or not
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = residual_vq ( x )
# (1, 1024, 256), (1, 1024, 8), (1, 8) Un article récent propose en outre de faire un VQ résiduel sur des groupes de la dimension de fonctionnalité, montrant des résultats équivalents à Encodec tout en utilisant beaucoup moins de livres de codes. Vous pouvez l'utiliser en importation GroupedResidualVQ
import torch
from vector_quantize_pytorch import GroupedResidualVQ
residual_vq = GroupedResidualVQ (
dim = 256 ,
num_quantizers = 8 , # specify number of quantizers
groups = 2 ,
codebook_size = 1024 , # codebook size
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = residual_vq ( x )
# (1, 1024, 256), (2, 1, 1024, 8), (2, 1, 8) Le document SoundStream propose que le livre de codes soit initialisé par les Kmeans Centrods du premier lot. Vous pouvez facilement activer cette fonctionnalité avec un drapeau kmeans_init = True , pour la classe VectorQuantize ou ResidualVQ
import torch
from vector_quantize_pytorch import ResidualVQ
residual_vq = ResidualVQ (
dim = 256 ,
codebook_size = 256 ,
num_quantizers = 4 ,
kmeans_init = True , # set to True
kmeans_iters = 10 # number of kmeans iterations to calculate the centroids for the codebook on init
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = residual_vq ( x )
# (1, 1024, 256), (1, 1024, 4), (1, 4) Les VQ-Vaes sont traditionnellement formés avec l'estimateur direct (STE). Pendant le passage vers l'arrière, le gradient circule autour de la couche VQ plutôt que par elle. Le papier de rotation propose de transformer le gradient à travers la couche VQ afin que l'angle et l'ampleur relatifs entre le vecteur d'entrée et la sortie quantifiée soient codés dans le gradient. Vous pouvez activer ou désactiver cette fonction avec rotation_trick=True/False dans la classe VectorQuantize .
from vector_quantize_pytorch import VectorQuantize
vq_layer = VectorQuantize (
dim = 256 ,
codebook_size = 256 ,
rotation_trick = True , # Set to False to use the STE gradient estimator or True to use the rotation trick.
)Ce référentiel contiendra quelques techniques de divers articles pour lutter contre les entrées de livre de codes "Dead", ce qui est un problème courant lors de l'utilisation du quantification vectorielle.
Le papier VQGAN amélioré propose de conserver le livre de codes dans une dimension inférieure. Les valeurs de l'encodeur sont projetées avant d'être projetées à une dimension élevée après la quantification. Vous pouvez le définir avec l'hyperparamètre codebook_dim .
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_size = 256 ,
codebook_dim = 16 # paper proposes setting this to 32 or as low as 8 to increase codebook usage
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = vq ( x )
# (1, 1024, 256), (1, 1024), (1,) Le papier VQGAN amélioré propose également de normaliser L2 les codes et les vecteurs codés, ce qui se résume à l'utilisation de la similitude en cosinus pour la distance. Ils affirment que l'application des vecteurs sur une sphère entraîne des améliorations de l'utilisation du code et de la reconstruction en aval. Vous pouvez activer cela en définissant use_cosine_sim = True
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_size = 256 ,
use_cosine_sim = True # set this to True
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = vq ( x )
# (1, 1024, 256), (1, 1024), (1,) Enfin, le papier SoundStream a un schéma où ils remplacent les codes qui ont des coups sous un certain seuil par un vecteur sélectionné au hasard dans le lot actuel. Vous pouvez définir ce seuil avec le mot clé threshold_ema_dead_code .
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_size = 512 ,
threshold_ema_dead_code = 2 # should actively replace any codes that have an exponential moving average cluster size less than 2
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = vq ( x )
# (1, 1024, 256), (1, 1024), (1,)VQ-VAE / VQ-GAN gagne rapidement en popularité. Un article récent propose que lors de l'utilisation de la quantification vectorielle sur les images, l'application du livre de codes est orthogonal conduit à l'équivariance de traduction des codes discrétisés, conduisant à de grandes améliorations des tâches de texte en aval à la génération d'images.
Vous pouvez utiliser cette fonctionnalité en définissant simplement le orthogonal_reg_weight pour être supérieur à 0 , auquel cas la régularisation orthogonale sera ajoutée à la perte auxiliaire publiée par le module.
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_size = 256 ,
accept_image_fmap = True , # set this true to be able to pass in an image feature map
orthogonal_reg_weight = 10 , # in paper, they recommended a value of 10
orthogonal_reg_max_codes = 128 , # this would randomly sample from the codebook for the orthogonal regularization loss, for limiting memory usage
orthogonal_reg_active_codes_only = False # set this to True if you have a very large codebook, and would only like to enforce the loss on the activated codes per batch
)
img_fmap = torch . randn ( 1 , 256 , 32 , 32 )
quantized , indices , loss = vq ( img_fmap ) # (1, 256, 32, 32), (1, 32, 32), (1,)
# loss now contains the orthogonal regularization loss with the weight as assigned Il y a eu un certain nombre d'articles qui proposent des variantes de représentations latentes discrètes avec une approche à plusieurs têtes (codes multiples par caractéristique). J'ai décidé d'offrir une variante où le même livre de codes est utilisé pour quantifier le vecteur à travers les temps head de dimension d'entrée.
Vous pouvez également utiliser une approche plus éprouvée (Memcodes) à partir du papier NWT
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_dim = 32 , # a number of papers have shown smaller codebook dimension to be acceptable
heads = 8 , # number of heads to vector quantize, codebook shared across all heads
separate_codebook_per_head = True , # whether to have a separate codebook per head. False would mean 1 shared codebook
codebook_size = 8196 ,
accept_image_fmap = True
)
img_fmap = torch . randn ( 1 , 256 , 32 , 32 )
quantized , indices , loss = vq ( img_fmap )
# (1, 256, 32, 32), (1, 32, 32, 8), (1,)Cet article a d'abord proposé d'utiliser un quantificateur de projection aléatoire pour la modélisation de la parole masquée, où les signaux sont projetés avec une matrice initialisée au hasard, puis correspondent à un livre de codes initialisé aléatoire. On n'a donc pas besoin d'apprendre le quantificateur. Cette technique a été utilisée par le modèle de parole universel de Google pour atteindre SOTA pour la modélisation de la parole à texte.
USM propose en outre d'utiliser plusieurs livres de codes et la modélisation de la parole masquée avec un objectif multi-softmax. Vous pouvez le faire facilement en définissant num_codebooks pour être supérieur à 1
import torch
from vector_quantize_pytorch import RandomProjectionQuantizer
quantizer = RandomProjectionQuantizer (
dim = 512 , # input dimensions
num_codebooks = 16 , # in USM, they used up to 16 for 5% gain
codebook_dim = 256 , # codebook dimension
codebook_size = 1024 # codebook size
)
x = torch . randn ( 1 , 1024 , 512 )
indices = quantizer ( x )
# (1, 1024, 16) Ce référentiel doit également synchroniser automatiquement les livres de codes dans un paramètre multi-processus. Si ce n'est pas en quelque sorte, veuillez ouvrir un problème. Vous pouvez remplacer si vous devez synchroniser les livres de codes ou non en définissant sync_codebook = True | False

Un nouveau document ICLR 2025 propose un schéma où le livre de codes est gelé, et les codes sont implicitement générés par une projection linéaire. Les auteurs affirment que cette configuration conduit à moins d'effondrement des livres de codes ainsi qu'à une convergence plus facile. J'ai trouvé que cela fonctionnait encore mieux lorsqu'il est associé à une astuce de rotation de Fifty et al., Et en élargissant la projection linéaire à une petite couche MLP. Vous pouvez l'expérimenter comme tel
Mise à jour: entendre les résultats mitigés
import torch
from vector_quantize_pytorch import SimVQ
sim_vq = SimVQ (
dim = 512 ,
codebook_size = 1024 ,
rotation_trick = True # use rotation trick from Fifty et al.
)
x = torch . randn ( 1 , 1024 , 512 )
quantized , indices , commit_loss = sim_vq ( x )
assert x . shape == quantized . shape
assert torch . allclose ( quantized , sim_vq . indices_to_codes ( indices ), atol = 1e-6 ) Pour la saveur résiduelle, importez simplement ResidualSimVQ à la place
import torch
from vector_quantize_pytorch import ResidualSimVQ
residual_sim_vq = ResidualSimVQ (
dim = 512 ,
num_quantizers = 4 ,
codebook_size = 1024 ,
rotation_trick = True # use rotation trick from Fifty et al.
)
x = torch . randn ( 1 , 1024 , 512 )
quantized , indices , commit_loss = residual_sim_vq ( x )
assert x . shape == quantized . shape
assert torch . allclose ( quantized , residual_sim_vq . get_output_from_indices ( indices ), atol = 1e-6 )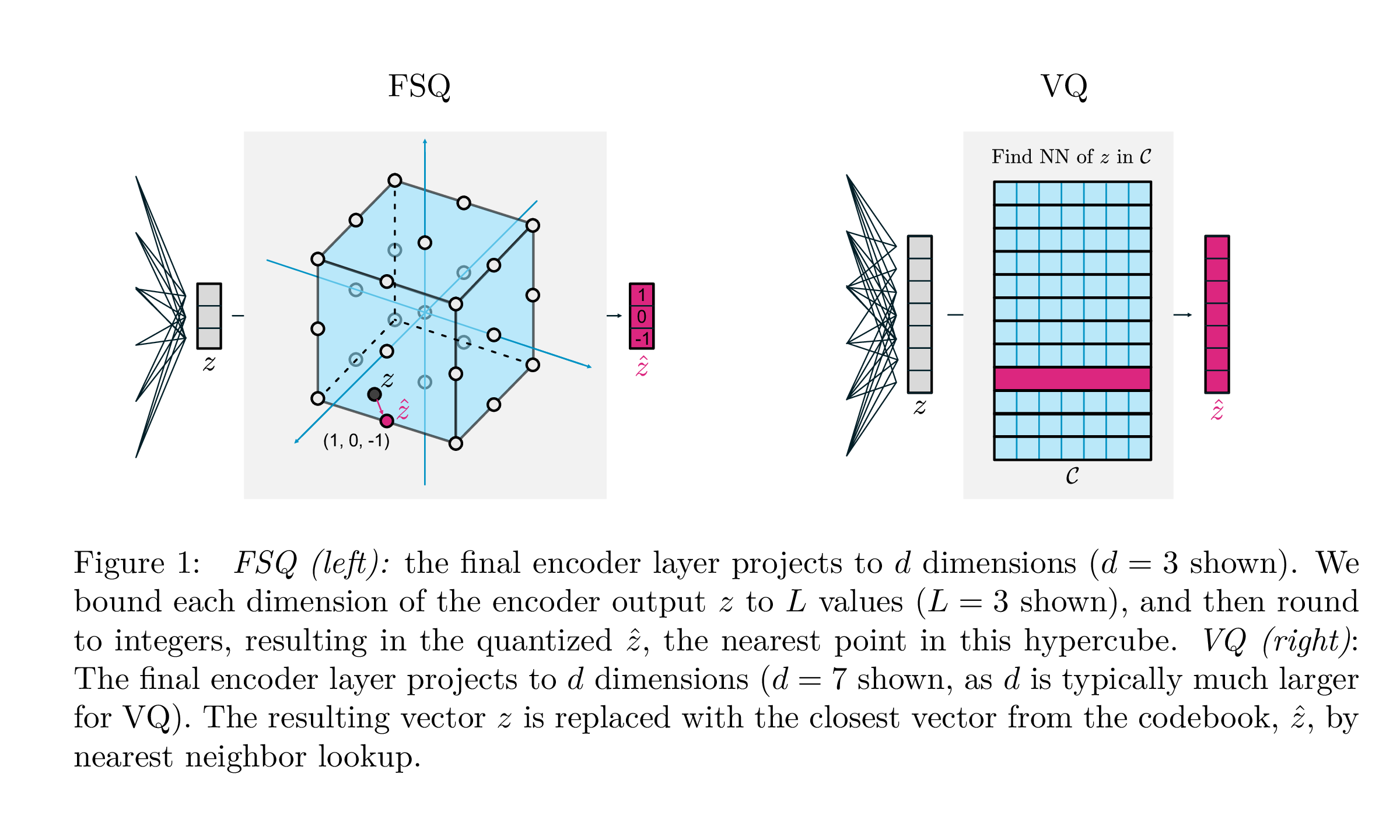
| Vq | FSQ | |
|---|---|---|
| Quantification | argmin_c || ZC || | rond (f (z)) |
| Gradients | Straight grâce à l'estimation (STE) | Ste |
| Pertes auxiliaires | Engagement, livre de codes, perte d'entropie, ... | N / A |
| Trucs | EMA sur le livre de codes, la fractionnement du livre de codes, les projections, ... | N / A |
| Paramètres | Livre de codes | N / A |
Ce travail sur Google Deepmind vise à simplifier considérablement la façon dont la quantification des vecteurs est effectuée pour la modélisation générative, supprimant le besoin de pertes d'engagement, la mise à jour de l'EMA du livre de codes, ainsi que pour résoudre les problèmes avec l'effondrement du livre de codes ou l'utilisation insuffisante. Ils tournent simplement chaque scalaire en niveaux discrets avec des gradients droits à travers les gradients; Les codes deviennent des points uniformes dans un hypercube.
Merci à @sekstini pour avoir porté sur cette implémentation en un temps record!
import torch
from vector_quantize_pytorch import FSQ
quantizer = FSQ (
levels = [ 8 , 5 , 5 , 5 ]
)
x = torch . randn ( 1 , 1024 , 4 ) # 4 since there are 4 levels
xhat , indices = quantizer ( x )
# (1, 1024, 4), (1, 1024)
assert torch . all ( xhat == quantizer . indices_to_codes ( indices ))Un FSQ résiduel improvisé, pour tenter d'améliorer le codage audio.
Le crédit va à @sekstini pour avoir initialement incorporé l'idée ici
import torch
from vector_quantize_pytorch import ResidualFSQ
residual_fsq = ResidualFSQ (
dim = 256 ,
levels = [ 8 , 5 , 5 , 3 ],
num_quantizers = 8
)
x = torch . randn ( 1 , 1024 , 256 )
residual_fsq . eval ()
quantized , indices = residual_fsq ( x )
# (1, 1024, 256), (1, 1024, 8)
quantized_out = residual_fsq . get_output_from_indices ( indices )
# (1, 1024, 256)
assert torch . all ( quantized == quantized_out )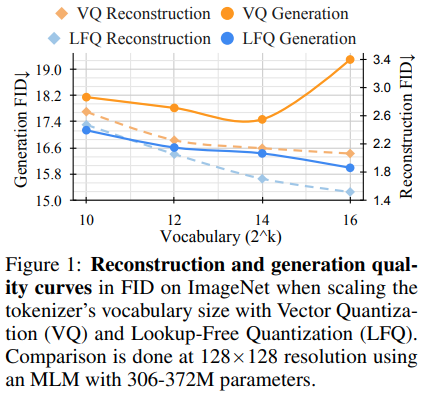
L'équipe de recherche derrière Magvit a publié de nouveaux résultats SOTA pour la modélisation vidéo générative. Un changement de base entre V1 et V2 comprend un nouveau type de quantification, la quantification libre de recherche (LFQ), qui élimine complètement le livre de codes et la recherche d'intégration.
Cet article présente un simple quantificateur LFQ de l'utilisation de latents binaires indépendants. Il existe d'autres implémentations de LFQ. Cependant, l'équipe montre que Magvit-V2 avec LFQ améliore considérablement l'indice de référence ImageNet. Les différences entre LFQ et le FSQ à 2 niveaux comprennent des régularisations d'entropie ainsi qu'une perte d'engagement maintenue.
Développer une méthode plus avancée de quantification LFQ sans Lookup de codes pourrait révolutionner la modélisation générative.
Vous pouvez l'utiliser simplement comme suit. Sera dogfoodé au port de pytorch Magvit2
import torch
from vector_quantize_pytorch import LFQ
# you can specify either dim or codebook_size
# if both specified, will be validated against each other
quantizer = LFQ (
codebook_size = 65536 , # codebook size, must be a power of 2
dim = 16 , # this is the input feature dimension, defaults to log2(codebook_size) if not defined
entropy_loss_weight = 0.1 , # how much weight to place on entropy loss
diversity_gamma = 1. # within entropy loss, how much weight to give to diversity of codes, taken from https://arxiv.org/abs/1911.05894
)
image_feats = torch . randn ( 1 , 16 , 32 , 32 )
quantized , indices , entropy_aux_loss = quantizer ( image_feats , inv_temperature = 100. ) # you may want to experiment with temperature
# (1, 16, 32, 32), (1, 32, 32), ()
assert ( quantized == quantizer . indices_to_codes ( indices )). all () Vous pouvez également transmettre des fonctionnalités vidéo en tant que (batch, feat, time, height, width) ou séquences comme (batch, seq, feat)
import torch
from vector_quantize_pytorch import LFQ
quantizer = LFQ (
codebook_size = 65536 ,
dim = 16 ,
entropy_loss_weight = 0.1 ,
diversity_gamma = 1.
)
seq = torch . randn ( 1 , 32 , 16 )
quantized , * _ = quantizer ( seq )
assert seq . shape == quantized . shape
video_feats = torch . randn ( 1 , 16 , 10 , 32 , 32 )
quantized , * _ = quantizer ( video_feats )
assert video_feats . shape == quantized . shapeOu prendre en charge plusieurs livres de codes
import torch
from vector_quantize_pytorch import LFQ
quantizer = LFQ (
codebook_size = 4096 ,
dim = 16 ,
num_codebooks = 4 # 4 codebooks, total codebook dimension is log2(4096) * 4
)
image_feats = torch . randn ( 1 , 16 , 32 , 32 )
quantized , indices , entropy_aux_loss = quantizer ( image_feats )
# (1, 16, 32, 32), (1, 32, 32, 4), ()
assert image_feats . shape == quantized . shape
assert ( quantized == quantizer . indices_to_codes ( indices )). all ()Un LFQ résiduel improvisé, pour voir si cela peut entraîner une amélioration de la compression audio.
import torch
from vector_quantize_pytorch import ResidualLFQ
residual_lfq = ResidualLFQ (
dim = 256 ,
codebook_size = 256 ,
num_quantizers = 8
)
x = torch . randn ( 1 , 1024 , 256 )
residual_lfq . eval ()
quantized , indices , commit_loss = residual_lfq ( x )
# (1, 1024, 256), (1, 1024, 8), (8)
quantized_out = residual_lfq . get_output_from_indices ( indices )
# (1, 1024, 256)
assert torch . all ( quantized == quantized_out )Le démontage est essentiel pour l'apprentissage de la représentation car il favorise l'interprétabilité, la généralisation, l'amélioration de l'apprentissage et la robustesse. Il s'aligne sur le but de capturer des caractéristiques significatives et indépendantes des données, facilitant l'utilisation plus efficace des représentations apprises à travers diverses applications. Pour un meilleur démontage, le défi consiste à démêler les variations sous-jacentes dans un ensemble de données sans informations explicites de vérité au sol. Ce travail introduit un biais inductif clé visant à coder et à décoder dans un espace latent organisé. La stratégie incorporée comprend la discrétisation de l'espace latent en attribuant des vecteurs de code discrets via l'utilisation d'un livre de codes scalaire apprenable individuel pour chaque dimension. Cette méthodologie permet à leurs modèles de dépasser efficacement les méthodes antérieures robustes.
Sachez qu'ils ont dû utiliser une désintégration de poids très élevée pour les résultats de cet article.
import torch
from vector_quantize_pytorch import LatentQuantize
# you can specify either dim or codebook_size
# if both specified, will be validated against each other
quantizer = LatentQuantize (
levels = [ 5 , 5 , 8 ], # number of levels per codebook dimension
dim = 16 , # input dim
commitment_loss_weight = 0.1 ,
quantization_loss_weight = 0.1 ,
)
image_feats = torch . randn ( 1 , 16 , 32 , 32 )
quantized , indices , loss = quantizer ( image_feats )
# (1, 16, 32, 32), (1, 32, 32), ()
assert image_feats . shape == quantized . shape
assert ( quantized == quantizer . indices_to_codes ( indices )). all () Vous pouvez également transmettre des fonctionnalités vidéo en tant que (batch, feat, time, height, width) ou séquences comme (batch, seq, feat)
import torch
from vector_quantize_pytorch import LatentQuantize
quantizer = LatentQuantize (
levels = [ 5 , 5 , 8 ],
dim = 16 ,
commitment_loss_weight = 0.1 ,
quantization_loss_weight = 0.1 ,
)
seq = torch . randn ( 1 , 32 , 16 )
quantized , * _ = quantizer ( seq )
# (1, 32, 16)
video_feats = torch . randn ( 1 , 16 , 10 , 32 , 32 )
quantized , * _ = quantizer ( video_feats )
# (1, 16, 10, 32, 32)Ou prendre en charge plusieurs livres de codes
import torch
from vector_quantize_pytorch import LatentQuantize
model = LatentQuantize (
levels = [ 4 , 8 , 16 ],
dim = 9 ,
num_codebooks = 3
)
input_tensor = torch . randn ( 2 , 3 , dim )
output_tensor , indices , loss = model ( input_tensor )
# (2, 3, 9), (2, 3, 3), ()
assert output_tensor . shape == input_tensor . shape
assert indices . shape == ( 2 , 3 , num_codebooks )
assert loss . item () >= 0 @misc { oord2018neural ,
title = { Neural Discrete Representation Learning } ,
author = { Aaron van den Oord and Oriol Vinyals and Koray Kavukcuoglu } ,
year = { 2018 } ,
eprint = { 1711.00937 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { zeghidour2021soundstream ,
title = { SoundStream: An End-to-End Neural Audio Codec } ,
author = { Neil Zeghidour and Alejandro Luebs and Ahmed Omran and Jan Skoglund and Marco Tagliasacchi } ,
year = { 2021 } ,
eprint = { 2107.03312 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.SD }
} @inproceedings { anonymous2022vectorquantized ,
title = { Vector-quantized Image Modeling with Improved {VQGAN} } ,
author = { Anonymous } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=pfNyExj7z2 } ,
note = { under review }
} @inproceedings { lee2022autoregressive ,
title = { Autoregressive Image Generation using Residual Quantization } ,
author = { Lee, Doyup and Kim, Chiheon and Kim, Saehoon and Cho, Minsu and Han, Wook-Shin } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition } ,
pages = { 11523--11532 } ,
year = { 2022 }
} @article { Defossez2022HighFN ,
title = { High Fidelity Neural Audio Compression } ,
author = { Alexandre D'efossez and Jade Copet and Gabriel Synnaeve and Yossi Adi } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.13438 }
} @inproceedings { Chiu2022SelfsupervisedLW ,
title = { Self-supervised Learning with Random-projection Quantizer for Speech Recognition } ,
author = { Chung-Cheng Chiu and James Qin and Yu Zhang and Jiahui Yu and Yonghui Wu } ,
booktitle = { International Conference on Machine Learning } ,
year = { 2022 }
} @inproceedings { Zhang2023GoogleUS ,
title = { Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages } ,
author = { Yu Zhang and Wei Han and James Qin and Yongqiang Wang and Ankur Bapna and Zhehuai Chen and Nanxin Chen and Bo Li and Vera Axelrod and Gary Wang and Zhong Meng and Ke Hu and Andrew Rosenberg and Rohit Prabhavalkar and Daniel S. Park and Parisa Haghani and Jason Riesa and Ginger Perng and Hagen Soltau and Trevor Strohman and Bhuvana Ramabhadran and Tara N. Sainath and Pedro J. Moreno and Chung-Cheng Chiu and Johan Schalkwyk and Franccoise Beaufays and Yonghui Wu } ,
year = { 2023 }
} @inproceedings { Shen2023NaturalSpeech2L ,
title = { NaturalSpeech 2: Latent Diffusion Models are Natural and Zero-Shot Speech and Singing Synthesizers } ,
author = { Kai Shen and Zeqian Ju and Xu Tan and Yanqing Liu and Yichong Leng and Lei He and Tao Qin and Sheng Zhao and Jiang Bian } ,
year = { 2023 }
} @inproceedings { Yang2023HiFiCodecGV ,
title = { HiFi-Codec: Group-residual Vector quantization for High Fidelity Audio Codec } ,
author = { Dongchao Yang and Songxiang Liu and Rongjie Huang and Jinchuan Tian and Chao Weng and Yuexian Zou } ,
year = { 2023 }
} @inproceedings { huh2023improvedvqste ,
title = { Straightening Out the Straight-Through Estimator: Overcoming Optimization Challenges in Vector Quantized Networks } ,
author = { Huh, Minyoung and Cheung, Brian and Agrawal, Pulkit and Isola, Phillip } ,
booktitle = { International Conference on Machine Learning } ,
year = { 2023 } ,
organization = { PMLR }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @misc { shin2021translationequivariant ,
title = { Translation-equivariant Image Quantizer for Bi-directional Image-Text Generation } ,
author = { Woncheol Shin and Gyubok Lee and Jiyoung Lee and Joonseok Lee and Edward Choi } ,
year = { 2021 } ,
eprint = { 2112.00384 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { mentzer2023finite ,
title = { Finite Scalar Quantization: VQ-VAE Made Simple } ,
author = { Fabian Mentzer and David Minnen and Eirikur Agustsson and Michael Tschannen } ,
year = { 2023 } ,
eprint = { 2309.15505 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { yu2023language ,
title = { Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation } ,
author = { Lijun Yu and José Lezama and Nitesh B. Gundavarapu and Luca Versari and Kihyuk Sohn and David Minnen and Yong Cheng and Agrim Gupta and Xiuye Gu and Alexander G. Hauptmann and Boqing Gong and Ming-Hsuan Yang and Irfan Essa and David A. Ross and Lu Jiang } ,
year = { 2023 } ,
eprint = { 2310.05737 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @inproceedings { Zhao2024ImageAV ,
title = { Image and Video Tokenization with Binary Spherical Quantization } ,
author = { Yue Zhao and Yuanjun Xiong and Philipp Krahenbuhl } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:270380237 }
} @misc { hsu2023disentanglement ,
title = { Disentanglement via Latent Quantization } ,
author = { Kyle Hsu and Will Dorrell and James C. R. Whittington and Jiajun Wu and Chelsea Finn } ,
year = { 2023 } ,
eprint = { 2305.18378 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @inproceedings { Irie2023SelfOrganisingND ,
title = { Self-Organising Neural Discrete Representation Learning `a la Kohonen } ,
author = { Kazuki Irie and R'obert Csord'as and J{"u}rgen Schmidhuber } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:256901024 }
} @article { Huijben2024ResidualQW ,
title = { Residual Quantization with Implicit Neural Codebooks } ,
author = { Iris Huijben and Matthijs Douze and Matthew Muckley and Ruud van Sloun and Jakob Verbeek } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2401.14732 } ,
url = { https://api.semanticscholar.org/CorpusID:267301189 }
} @article { Fifty2024Restructuring ,
title = { Restructuring Vector Quantization with the Rotation Trick } ,
author = { Christopher Fifty, Ronald G. Junkins, Dennis Duan, Aniketh Iyengar, Jerry W. Liu, Ehsan Amid, Sebastian Thrun, Christopher Ré } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2410.06424 } ,
url = { https://api.semanticscholar.org/CorpusID:273229218 }
} @inproceedings { Zhu2024AddressingRC ,
title = { Addressing Representation Collapse in Vector Quantized Models with One Linear Layer } ,
author = { Yongxin Zhu and Bocheng Li and Yifei Xin and Linli Xu } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273812459 }
}

