vector quantize pytorch
1.20.11
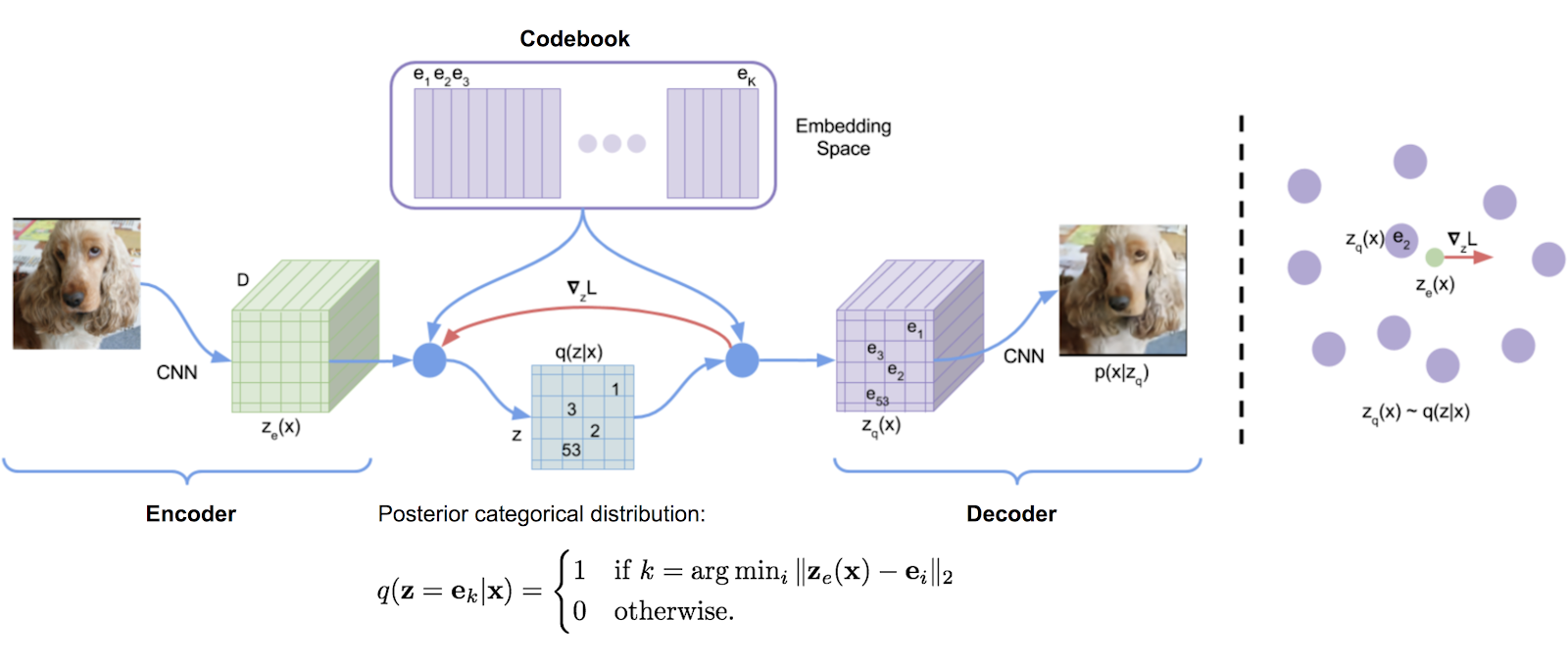
مكتبة قياس الكميات المتجهات التي تم نقلها في الأصل من تنفيذ Tensorflow DeepMind ، والتي تتم بشكل مريح في حزمة. يستخدم متوسطات الحركة الأسية لتحديث القاموس.
تم استخدام VQ بنجاح من قبل DeepMind و Openai لتوليد جودة عالية من الصور (VQ-VAE-2) والموسيقى (Jukebox).
$ pip install vector-quantize-pytorch import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_size = 512 , # codebook size
decay = 0.8 , # the exponential moving average decay, lower means the dictionary will change faster
commitment_weight = 1. # the weight on the commitment loss
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = vq ( x ) # (1, 1024, 256), (1, 1024), (1) تقترح هذه الورقة استخدام كميات متجهة متعددة لتحديد بقايا الشكل الموجي بشكل متكرر. يمكنك استخدام هذا مع فئة ResidualVQ ومعلمة تهيئة إضافية واحدة.
import torch
from vector_quantize_pytorch import ResidualVQ
residual_vq = ResidualVQ (
dim = 256 ,
num_quantizers = 8 , # specify number of quantizers
codebook_size = 1024 , # codebook size
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = residual_vq ( x )
print ( quantized . shape , indices . shape , commit_loss . shape )
# (1, 1024, 256), (1, 1024, 8), (1, 8)
# if you need all the codes across the quantization layers, just pass return_all_codes = True
quantized , indices , commit_loss , all_codes = residual_vq ( x , return_all_codes = True )
# (8, 1, 1024, 256)علاوة على ذلك ، تستخدم هذه الورقة VQ المتبقية لبناء RQ-VAE ، لتوليد صور عالية الدقة مع رموز أكثر ضغطًا.
أنها تجعل تعديلين. الأول هو مشاركة الكود عبر جميع الكميات. والثاني هو أخذ عينات من الرموز بشكل عشوائي بدلاً من أخذ أقرب مباراة دائمًا. يمكنك استخدام كل من هذه الميزات مع وسيطتين إضافيتين للكلمات الرئيسية.
import torch
from vector_quantize_pytorch import ResidualVQ
residual_vq = ResidualVQ (
dim = 256 ,
num_quantizers = 8 ,
codebook_size = 1024 ,
stochastic_sample_codes = True ,
sample_codebook_temp = 0.1 , # temperature for stochastically sampling codes, 0 would be equivalent to non-stochastic
shared_codebook = True # whether to share the codebooks for all quantizers or not
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = residual_vq ( x )
# (1, 1024, 256), (1, 1024, 8), (1, 8) تقترح ورقة حديثة أيضًا القيام بـ VQ المتبقي على مجموعات من بُعد الميزة ، مما يوضح نتائج مكافئة للاحتفال أثناء استخدام كتب التعليمات البرمجية أقل بكثير. يمكنك استخدامه عن طريق استيراد GroupedResidualVQ
import torch
from vector_quantize_pytorch import GroupedResidualVQ
residual_vq = GroupedResidualVQ (
dim = 256 ,
num_quantizers = 8 , # specify number of quantizers
groups = 2 ,
codebook_size = 1024 , # codebook size
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = residual_vq ( x )
# (1, 1024, 256), (2, 1, 1024, 8), (2, 1, 8) تقترح ورقة SoundStream أن يتم تهيئة دفتر التعليمات البرمجية بواسطة Kmeans Centroids من الدفعة الأولى. يمكنك بسهولة تشغيل هذه الميزة باستخدام علامة kmeans_init = True ، إما لفئة VectorQuantize أو ResidualVQ
import torch
from vector_quantize_pytorch import ResidualVQ
residual_vq = ResidualVQ (
dim = 256 ,
codebook_size = 256 ,
num_quantizers = 4 ,
kmeans_init = True , # set to True
kmeans_iters = 10 # number of kmeans iterations to calculate the centroids for the codebook on init
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = residual_vq ( x )
# (1, 1024, 256), (1, 1024, 4), (1, 4) يتم تدريب VQ-VAEs تقليديًا مع مقدر مباشرة (STE). أثناء المرور للخلف ، يتدفق التدرج حول طبقة VQ بدلاً من ذلك . تقترح ورقة خدعة الدوران تحويل التدرج من خلال طبقة VQ بحيث يتم ترميز الزاوية النسبية والحجم بين متجه الإدخال والإخراج الكمي في التدرج. يمكنك تمكين أو تعطيل هذه الميزة باستخدام rotation_trick=True/False في فئة VectorQuantize .
from vector_quantize_pytorch import VectorQuantize
vq_layer = VectorQuantize (
dim = 256 ,
codebook_size = 256 ,
rotation_trick = True , # Set to False to use the STE gradient estimator or True to use the rotation trick.
)سيحتوي هذا المستودع على بعض التقنيات من الأوراق المختلفة لمكافحة إدخالات الكواري "الميتة" ، وهي مشكلة شائعة عند استخدام كميات المتجهات.
تقترح ورقة VQGAN المحسنة أن يتم الاحتفاظ بكتاب الكود في بعد أقل. يتم إسقاط قيم التشفير قبل عرضها إلى الأبعاد العالية بعد القياس الكمي. يمكنك تعيين هذا باستخدام codebook_dim Hyperparameter.
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_size = 256 ,
codebook_dim = 16 # paper proposes setting this to 32 or as low as 8 to increase codebook usage
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = vq ( x )
# (1, 1024, 256), (1, 1024), (1,) تقترح ورقة VQGAN المحسنة أيضًا تطبيع الرموز والناقلات المشفرة ، والتي تتلخص في استخدام تشابه جيب التمام للمسافة. يزعمون إنفاذ المتجهات على المجال يؤدي إلى تحسينات في استخدام الكود وإعادة بناء المصب. يمكنك تشغيل هذا عن طريق تعيين use_cosine_sim = True
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_size = 256 ,
use_cosine_sim = True # set this to True
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = vq ( x )
# (1, 1024, 256), (1, 1024), (1,) أخيرًا ، تحتوي ورقة SoundStream على مخطط حيث تستبدل الرموز التي تضغط أقل من عتبة معينة مع ناقل تم اختياره عشوائيًا من الدفعة الحالية. يمكنك تعيين هذه العتبة مع الكلمة الرئيسية threshold_ema_dead_code .
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_size = 512 ,
threshold_ema_dead_code = 2 # should actively replace any codes that have an exponential moving average cluster size less than 2
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = vq ( x )
# (1, 1024, 256), (1, 1024), (1,)تكتسب VQ-VAE / VQ-GAN شعبية بسرعة. تقترح ورقة حديثة أنه عند استخدام كمية المتجه على الصور ، فإن فرض دفتر الكود ليكون متعامدًا يؤدي إلى ترجمة رموز الرموز التقديرية ، مما يؤدي إلى تحسينات كبيرة في النصوص المصب إلى مهام توليد الصور.
يمكنك استخدام هذه الميزة ببساطة عن طريق تعيين orthogonal_reg_weight ليكون أكبر من 0 ، وفي هذه الحالة ستتم إضافة التنظيم المتعامد إلى الخسارة الإضافية التي تخرجها الوحدة.
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_size = 256 ,
accept_image_fmap = True , # set this true to be able to pass in an image feature map
orthogonal_reg_weight = 10 , # in paper, they recommended a value of 10
orthogonal_reg_max_codes = 128 , # this would randomly sample from the codebook for the orthogonal regularization loss, for limiting memory usage
orthogonal_reg_active_codes_only = False # set this to True if you have a very large codebook, and would only like to enforce the loss on the activated codes per batch
)
img_fmap = torch . randn ( 1 , 256 , 32 , 32 )
quantized , indices , loss = vq ( img_fmap ) # (1, 256, 32, 32), (1, 32, 32), (1,)
# loss now contains the orthogonal regularization loss with the weight as assigned كان هناك عدد من الأوراق التي تقترح متغيرات من تمثيلات كامنة منفصلة مع نهج متعدد الرؤوس (رموز متعددة لكل ميزة). لقد قررت أن أقدم متغيرًا واحدًا حيث يتم استخدام نفس دفتر الكود لقيام المتجه بتعيين كمية عبر أوقات head أبعاد الإدخال.
يمكنك أيضًا استخدام نهج أكثر إثباتًا (Memcodes) من ورقة NWT
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_dim = 32 , # a number of papers have shown smaller codebook dimension to be acceptable
heads = 8 , # number of heads to vector quantize, codebook shared across all heads
separate_codebook_per_head = True , # whether to have a separate codebook per head. False would mean 1 shared codebook
codebook_size = 8196 ,
accept_image_fmap = True
)
img_fmap = torch . randn ( 1 , 256 , 32 , 32 )
quantized , indices , loss = vq ( img_fmap )
# (1, 256, 32, 32), (1, 32, 32, 8), (1,)اقترحت هذه الورقة أولاً استخدام كمية عرض عشوائية لنمذجة الكلام المقنعة ، حيث يتم عرض الإشارات بمصفوفة تهيئتها عشوائيًا ثم مطابقة لكتاب رمز تهيئة عشوائي. واحد لذلك لا يحتاج إلى تعلم الكمية. تم استخدام هذه التقنية من قبل نموذج الكلام العالمي من Google لتحقيق SOTA لنمذجة الكلام إلى النص.
تقترح USM كذلك استخدام كود كود متعددة ، ونمذجة الكلام المقنعة مع هدف متعدد الأجزاء. يمكنك القيام بذلك بسهولة عن طريق تعيين num_codebooks ليكون أكبر من 1
import torch
from vector_quantize_pytorch import RandomProjectionQuantizer
quantizer = RandomProjectionQuantizer (
dim = 512 , # input dimensions
num_codebooks = 16 , # in USM, they used up to 16 for 5% gain
codebook_dim = 256 , # codebook dimension
codebook_size = 1024 # codebook size
)
x = torch . randn ( 1 , 1024 , 512 )
indices = quantizer ( x )
# (1, 1024, 16) يجب أن يؤدي هذا المستودع أيضًا إلى مزامنة كتب التعليمات البرمجية في إعداد متعدد العمليات. إذا لم يكن الأمر كذلك ، فيرجى فتح مشكلة. يمكنك تجاوز ما إذا كنت تريد مزامنة كتب التعليمات البرمجية أم لا عن طريق تعيين sync_codebook = True | False

تقترح ورقة ICLR 2025 جديدة مخططًا حيث يتم تجميد دفتر الكود ، ويتم إنشاء الرموز ضمناً من خلال الإسقاط الخطي. يزعم المؤلفون أن هذا الإعداد يؤدي إلى انهيار كود أقل بالإضافة إلى تقارب أسهل. لقد وجدت هذا لأداء أفضل عند إقرانه مع خدعة الدوران من Fifty et al. ، وتوسيع الإسقاط الخطي إلى طبقة صغيرة MLP. يمكنك تجربته كما هو الحال
تحديث: السمع نتائج مختلطة
import torch
from vector_quantize_pytorch import SimVQ
sim_vq = SimVQ (
dim = 512 ,
codebook_size = 1024 ,
rotation_trick = True # use rotation trick from Fifty et al.
)
x = torch . randn ( 1 , 1024 , 512 )
quantized , indices , commit_loss = sim_vq ( x )
assert x . shape == quantized . shape
assert torch . allclose ( quantized , sim_vq . indices_to_codes ( indices ), atol = 1e-6 ) للنكهة المتبقية ، ما عليك سوى استيراد ResidualSimVQ بدلاً من ذلك
import torch
from vector_quantize_pytorch import ResidualSimVQ
residual_sim_vq = ResidualSimVQ (
dim = 512 ,
num_quantizers = 4 ,
codebook_size = 1024 ,
rotation_trick = True # use rotation trick from Fifty et al.
)
x = torch . randn ( 1 , 1024 , 512 )
quantized , indices , commit_loss = residual_sim_vq ( x )
assert x . shape == quantized . shape
assert torch . allclose ( quantized , residual_sim_vq . get_output_from_indices ( indices ), atol = 1e-6 )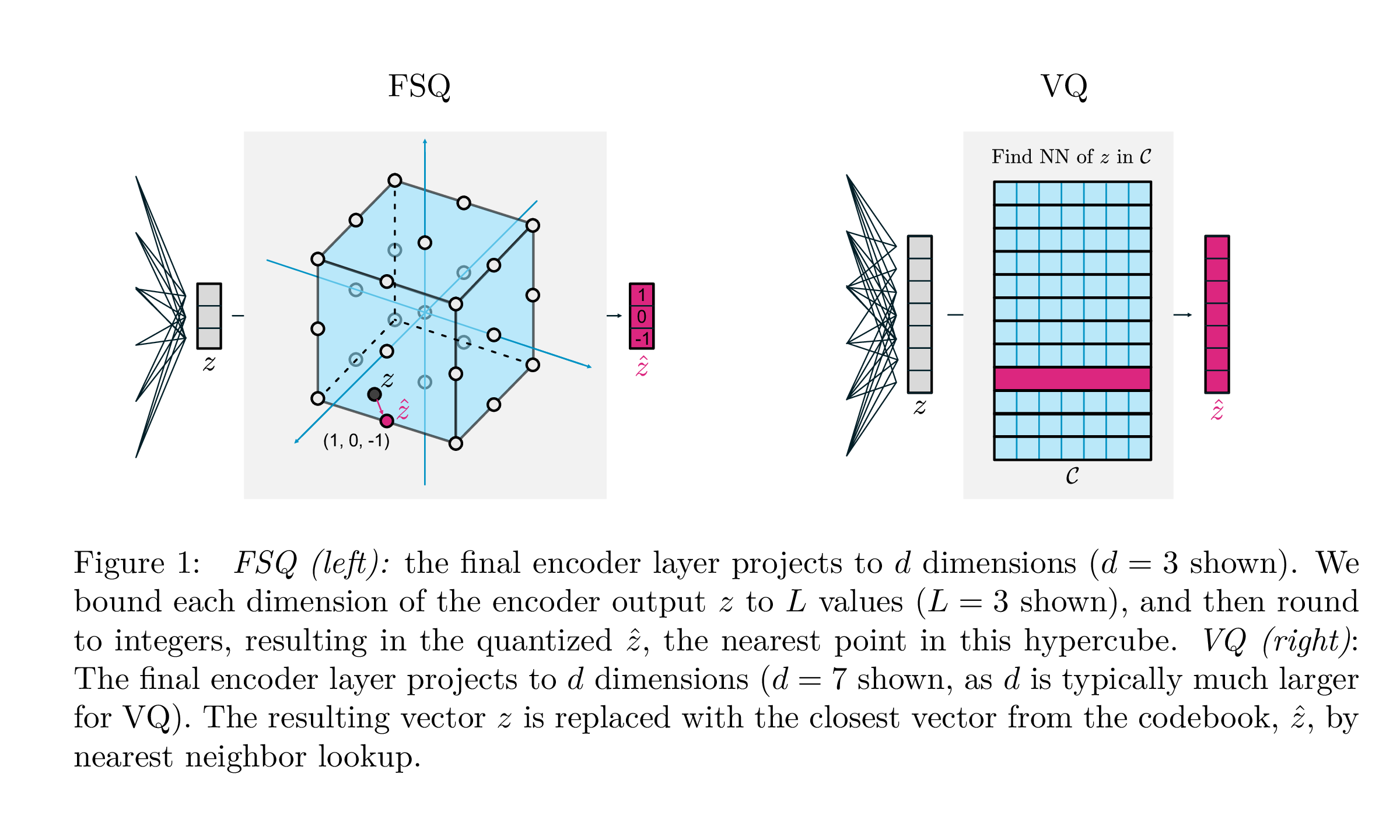
| VQ | FSQ | |
|---|---|---|
| الكمية | argmin_c || ZC || | جولة (F (Z)) |
| التدرجات | مباشرة من خلال التقدير (STE) | ستيل |
| الخسائر المساعدة | الالتزام ، دفتر الكود ، خسارة الانتروبيا ، ... | ن/أ |
| الحيل | EMA على الكود ، تقسيم الكود ، توقعات ، ... | ن/أ |
| حدود | دفتر الكود | ن/أ |
يهدف هذا العمل من Google DeepMind إلى تبسيط الطريقة التي يتم بها تقدير الكميات المتجهية للنمذجة التوليدية ، مما يزيل الحاجة إلى خسائر الالتزام ، أو تحديث EMA لكتاب الكود ، بالإضافة إلى معالجة المشكلات مع انهيار كود كوك أو الاستخدام غير الكافي. إنهم ببساطة حول كل عدادات إلى مستويات منفصلة مع التدرجات مباشرة ؛ تصبح الرموز نقاطًا موحدة في فرط النوب.
شكرًا على SekStini للتنقل عبر هذا التنفيذ في وقت التسجيل!
import torch
from vector_quantize_pytorch import FSQ
quantizer = FSQ (
levels = [ 8 , 5 , 5 , 5 ]
)
x = torch . randn ( 1 , 1024 , 4 ) # 4 since there are 4 levels
xhat , indices = quantizer ( x )
# (1, 1024, 4), (1, 1024)
assert torch . all ( xhat == quantizer . indices_to_codes ( indices ))FSQ المتبقية المرتجلة ، لمحاولة تحسين ترميز الصوت.
يذهب الائتمان إلى sekstini لأصل في الأصل الفكرة هنا
import torch
from vector_quantize_pytorch import ResidualFSQ
residual_fsq = ResidualFSQ (
dim = 256 ,
levels = [ 8 , 5 , 5 , 3 ],
num_quantizers = 8
)
x = torch . randn ( 1 , 1024 , 256 )
residual_fsq . eval ()
quantized , indices = residual_fsq ( x )
# (1, 1024, 256), (1, 1024, 8)
quantized_out = residual_fsq . get_output_from_indices ( indices )
# (1, 1024, 256)
assert torch . all ( quantized == quantized_out )
أصدر فريق البحث وراء Magvit نتائج SOTA جديدة لنمذجة الفيديو التوليدي. يتضمن التغيير الأساسي بين V1 و V2 نوعًا جديدًا من القياس الكمي ، والكمية الخالية من البحث (LFQ) ، مما يلغي دفتر الكود وبحث التضمين بالكامل.
تقدم هذه الورقة كمية LFQ بسيطة لاستخدام اللاتينية الثنائية المستقلة. تطبيقات أخرى من LFQ موجودة. ومع ذلك ، يوضح الفريق أن MAGVIT-V2 مع LFQ يتحسن بشكل كبير في مؤشر ImageNet. تتضمن الاختلافات بين LFQ و FSQ على مستوى 2 تنظيم إنتروبيا وكذلك فقدان الالتزام.
يمكن أن يؤدي تطوير طريقة أكثر تقدماً لتحديد LFQ بدون CodeBook-lookup إلى إحداث ثورة في النمذجة التوليدية.
يمكنك استخدامه ببساطة على النحو التالي. سوف يتم تناول الطعام في ميناء Magvit2 Pytorch
import torch
from vector_quantize_pytorch import LFQ
# you can specify either dim or codebook_size
# if both specified, will be validated against each other
quantizer = LFQ (
codebook_size = 65536 , # codebook size, must be a power of 2
dim = 16 , # this is the input feature dimension, defaults to log2(codebook_size) if not defined
entropy_loss_weight = 0.1 , # how much weight to place on entropy loss
diversity_gamma = 1. # within entropy loss, how much weight to give to diversity of codes, taken from https://arxiv.org/abs/1911.05894
)
image_feats = torch . randn ( 1 , 16 , 32 , 32 )
quantized , indices , entropy_aux_loss = quantizer ( image_feats , inv_temperature = 100. ) # you may want to experiment with temperature
# (1, 16, 32, 32), (1, 32, 32), ()
assert ( quantized == quantizer . indices_to_codes ( indices )). all () يمكنك أيضًا المرور في ميزات الفيديو مثل (batch, feat, time, height, width) أو التسلسلات مثل (batch, seq, feat)
import torch
from vector_quantize_pytorch import LFQ
quantizer = LFQ (
codebook_size = 65536 ,
dim = 16 ,
entropy_loss_weight = 0.1 ,
diversity_gamma = 1.
)
seq = torch . randn ( 1 , 32 , 16 )
quantized , * _ = quantizer ( seq )
assert seq . shape == quantized . shape
video_feats = torch . randn ( 1 , 16 , 10 , 32 , 32 )
quantized , * _ = quantizer ( video_feats )
assert video_feats . shape == quantized . shapeأو دعم كتب التعليمات البرمجية المتعددة
import torch
from vector_quantize_pytorch import LFQ
quantizer = LFQ (
codebook_size = 4096 ,
dim = 16 ,
num_codebooks = 4 # 4 codebooks, total codebook dimension is log2(4096) * 4
)
image_feats = torch . randn ( 1 , 16 , 32 , 32 )
quantized , indices , entropy_aux_loss = quantizer ( image_feats )
# (1, 16, 32, 32), (1, 32, 32, 4), ()
assert image_feats . shape == quantized . shape
assert ( quantized == quantizer . indices_to_codes ( indices )). all ()LFQ المتبقي المرتجلة ، لمعرفة ما إذا كان يمكن أن يؤدي إلى تحسين لضغط الصوت.
import torch
from vector_quantize_pytorch import ResidualLFQ
residual_lfq = ResidualLFQ (
dim = 256 ,
codebook_size = 256 ,
num_quantizers = 8
)
x = torch . randn ( 1 , 1024 , 256 )
residual_lfq . eval ()
quantized , indices , commit_loss = residual_lfq ( x )
# (1, 1024, 256), (1, 1024, 8), (8)
quantized_out = residual_lfq . get_output_from_indices ( indices )
# (1, 1024, 256)
assert torch . all ( quantized == quantized_out )يعد Disentanglement ضروريًا لتعلم التمثيل لأنه يعزز القابلية للتفسير والتعميم وتحسين التعلم والمتانة. يتماشى مع هدف التقاط ميزات ذات معنى ومستقل للبيانات ، مما يسهل استخدامًا أكثر فعالية للتمثيلات المستفادة عبر مختلف التطبيقات. من أجل عدم التغلب بشكل أفضل ، يتمثل التحدي في فصل الاختلافات الأساسية في مجموعة البيانات دون معلومات الحقيقة الواضحة. يقدم هذا العمل تحيزًا استقرائيًا رئيسيًا يهدف إلى الترميز وفك التشفير داخل مساحة كامنة منظمة. تشمل الإستراتيجية المدمجة تقدير المساحة الكامنة من خلال تعيين متجهات رمز منفصل من خلال استخدام دفتر رمز قياسي قابل للتعلم فردي لكل بعد. تمكن هذه المنهجية نماذجها من تجاوز الأساليب السابقة القوية بشكل فعال.
كن على علم بأنهم اضطروا إلى استخدام تسوس الوزن العالي للغاية للنتائج في هذه الورقة.
import torch
from vector_quantize_pytorch import LatentQuantize
# you can specify either dim or codebook_size
# if both specified, will be validated against each other
quantizer = LatentQuantize (
levels = [ 5 , 5 , 8 ], # number of levels per codebook dimension
dim = 16 , # input dim
commitment_loss_weight = 0.1 ,
quantization_loss_weight = 0.1 ,
)
image_feats = torch . randn ( 1 , 16 , 32 , 32 )
quantized , indices , loss = quantizer ( image_feats )
# (1, 16, 32, 32), (1, 32, 32), ()
assert image_feats . shape == quantized . shape
assert ( quantized == quantizer . indices_to_codes ( indices )). all () يمكنك أيضًا المرور في ميزات الفيديو مثل (batch, feat, time, height, width) أو التسلسلات مثل (batch, seq, feat)
import torch
from vector_quantize_pytorch import LatentQuantize
quantizer = LatentQuantize (
levels = [ 5 , 5 , 8 ],
dim = 16 ,
commitment_loss_weight = 0.1 ,
quantization_loss_weight = 0.1 ,
)
seq = torch . randn ( 1 , 32 , 16 )
quantized , * _ = quantizer ( seq )
# (1, 32, 16)
video_feats = torch . randn ( 1 , 16 , 10 , 32 , 32 )
quantized , * _ = quantizer ( video_feats )
# (1, 16, 10, 32, 32)أو دعم كتب التعليمات البرمجية المتعددة
import torch
from vector_quantize_pytorch import LatentQuantize
model = LatentQuantize (
levels = [ 4 , 8 , 16 ],
dim = 9 ,
num_codebooks = 3
)
input_tensor = torch . randn ( 2 , 3 , dim )
output_tensor , indices , loss = model ( input_tensor )
# (2, 3, 9), (2, 3, 3), ()
assert output_tensor . shape == input_tensor . shape
assert indices . shape == ( 2 , 3 , num_codebooks )
assert loss . item () >= 0 @misc { oord2018neural ,
title = { Neural Discrete Representation Learning } ,
author = { Aaron van den Oord and Oriol Vinyals and Koray Kavukcuoglu } ,
year = { 2018 } ,
eprint = { 1711.00937 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { zeghidour2021soundstream ,
title = { SoundStream: An End-to-End Neural Audio Codec } ,
author = { Neil Zeghidour and Alejandro Luebs and Ahmed Omran and Jan Skoglund and Marco Tagliasacchi } ,
year = { 2021 } ,
eprint = { 2107.03312 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.SD }
} @inproceedings { anonymous2022vectorquantized ,
title = { Vector-quantized Image Modeling with Improved {VQGAN} } ,
author = { Anonymous } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=pfNyExj7z2 } ,
note = { under review }
} @inproceedings { lee2022autoregressive ,
title = { Autoregressive Image Generation using Residual Quantization } ,
author = { Lee, Doyup and Kim, Chiheon and Kim, Saehoon and Cho, Minsu and Han, Wook-Shin } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition } ,
pages = { 11523--11532 } ,
year = { 2022 }
} @article { Defossez2022HighFN ,
title = { High Fidelity Neural Audio Compression } ,
author = { Alexandre D'efossez and Jade Copet and Gabriel Synnaeve and Yossi Adi } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.13438 }
} @inproceedings { Chiu2022SelfsupervisedLW ,
title = { Self-supervised Learning with Random-projection Quantizer for Speech Recognition } ,
author = { Chung-Cheng Chiu and James Qin and Yu Zhang and Jiahui Yu and Yonghui Wu } ,
booktitle = { International Conference on Machine Learning } ,
year = { 2022 }
} @inproceedings { Zhang2023GoogleUS ,
title = { Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages } ,
author = { Yu Zhang and Wei Han and James Qin and Yongqiang Wang and Ankur Bapna and Zhehuai Chen and Nanxin Chen and Bo Li and Vera Axelrod and Gary Wang and Zhong Meng and Ke Hu and Andrew Rosenberg and Rohit Prabhavalkar and Daniel S. Park and Parisa Haghani and Jason Riesa and Ginger Perng and Hagen Soltau and Trevor Strohman and Bhuvana Ramabhadran and Tara N. Sainath and Pedro J. Moreno and Chung-Cheng Chiu and Johan Schalkwyk and Franccoise Beaufays and Yonghui Wu } ,
year = { 2023 }
} @inproceedings { Shen2023NaturalSpeech2L ,
title = { NaturalSpeech 2: Latent Diffusion Models are Natural and Zero-Shot Speech and Singing Synthesizers } ,
author = { Kai Shen and Zeqian Ju and Xu Tan and Yanqing Liu and Yichong Leng and Lei He and Tao Qin and Sheng Zhao and Jiang Bian } ,
year = { 2023 }
} @inproceedings { Yang2023HiFiCodecGV ,
title = { HiFi-Codec: Group-residual Vector quantization for High Fidelity Audio Codec } ,
author = { Dongchao Yang and Songxiang Liu and Rongjie Huang and Jinchuan Tian and Chao Weng and Yuexian Zou } ,
year = { 2023 }
} @inproceedings { huh2023improvedvqste ,
title = { Straightening Out the Straight-Through Estimator: Overcoming Optimization Challenges in Vector Quantized Networks } ,
author = { Huh, Minyoung and Cheung, Brian and Agrawal, Pulkit and Isola, Phillip } ,
booktitle = { International Conference on Machine Learning } ,
year = { 2023 } ,
organization = { PMLR }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @misc { shin2021translationequivariant ,
title = { Translation-equivariant Image Quantizer for Bi-directional Image-Text Generation } ,
author = { Woncheol Shin and Gyubok Lee and Jiyoung Lee and Joonseok Lee and Edward Choi } ,
year = { 2021 } ,
eprint = { 2112.00384 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { mentzer2023finite ,
title = { Finite Scalar Quantization: VQ-VAE Made Simple } ,
author = { Fabian Mentzer and David Minnen and Eirikur Agustsson and Michael Tschannen } ,
year = { 2023 } ,
eprint = { 2309.15505 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { yu2023language ,
title = { Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation } ,
author = { Lijun Yu and José Lezama and Nitesh B. Gundavarapu and Luca Versari and Kihyuk Sohn and David Minnen and Yong Cheng and Agrim Gupta and Xiuye Gu and Alexander G. Hauptmann and Boqing Gong and Ming-Hsuan Yang and Irfan Essa and David A. Ross and Lu Jiang } ,
year = { 2023 } ,
eprint = { 2310.05737 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @inproceedings { Zhao2024ImageAV ,
title = { Image and Video Tokenization with Binary Spherical Quantization } ,
author = { Yue Zhao and Yuanjun Xiong and Philipp Krahenbuhl } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:270380237 }
} @misc { hsu2023disentanglement ,
title = { Disentanglement via Latent Quantization } ,
author = { Kyle Hsu and Will Dorrell and James C. R. Whittington and Jiajun Wu and Chelsea Finn } ,
year = { 2023 } ,
eprint = { 2305.18378 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @inproceedings { Irie2023SelfOrganisingND ,
title = { Self-Organising Neural Discrete Representation Learning `a la Kohonen } ,
author = { Kazuki Irie and R'obert Csord'as and J{"u}rgen Schmidhuber } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:256901024 }
} @article { Huijben2024ResidualQW ,
title = { Residual Quantization with Implicit Neural Codebooks } ,
author = { Iris Huijben and Matthijs Douze and Matthew Muckley and Ruud van Sloun and Jakob Verbeek } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2401.14732 } ,
url = { https://api.semanticscholar.org/CorpusID:267301189 }
} @article { Fifty2024Restructuring ,
title = { Restructuring Vector Quantization with the Rotation Trick } ,
author = { Christopher Fifty, Ronald G. Junkins, Dennis Duan, Aniketh Iyengar, Jerry W. Liu, Ehsan Amid, Sebastian Thrun, Christopher Ré } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2410.06424 } ,
url = { https://api.semanticscholar.org/CorpusID:273229218 }
} @inproceedings { Zhu2024AddressingRC ,
title = { Addressing Representation Collapse in Vector Quantized Models with One Linear Layer } ,
author = { Yongxin Zhu and Bocheng Li and Yifei Xin and Linli Xu } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273812459 }
}

