vector quantize pytorch
1.20.11
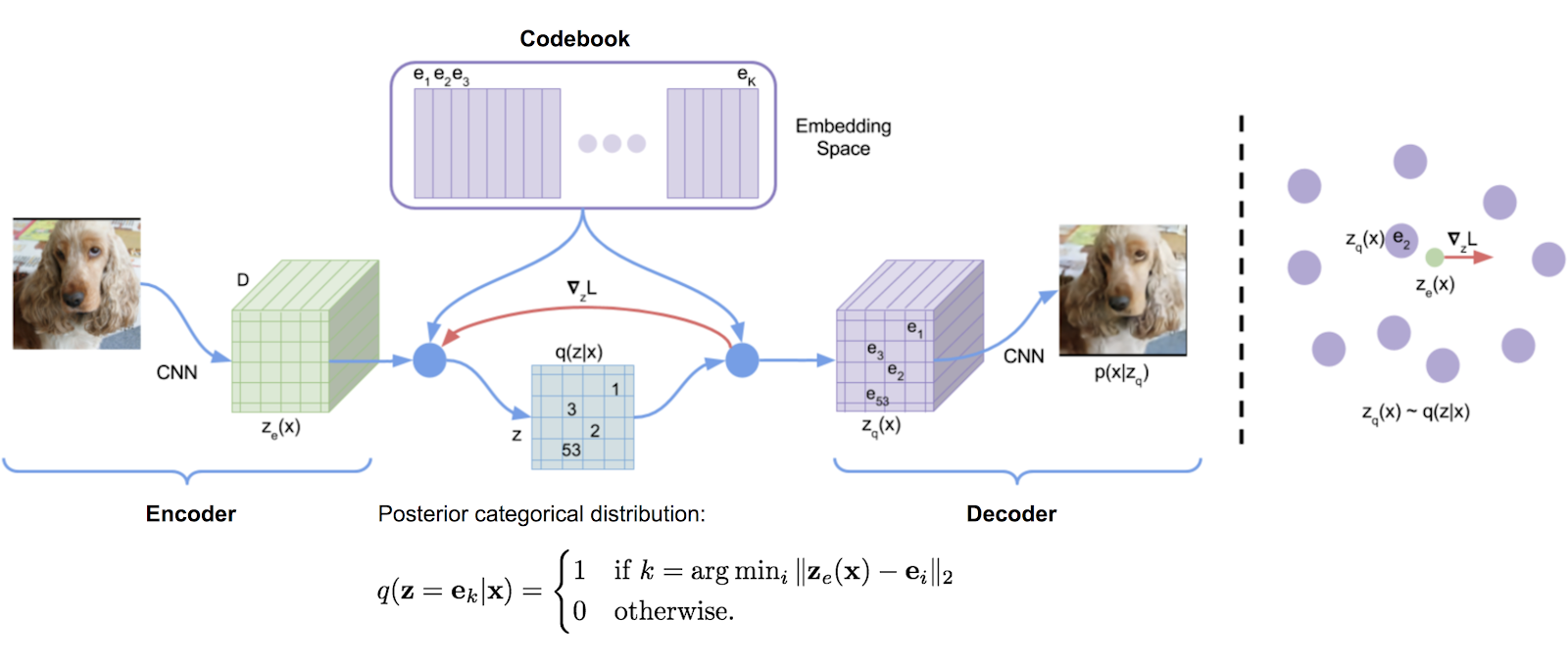
DeepMind의 Tensorflow 구현에서 원래 전사 된 벡터 양자화 라이브러리는 편리하게 패키지로 만들었습니다. 지수 이동 평균을 사용하여 사전을 업데이트합니다.
VQ는 Deepmind와 OpenAi가 고품질 세대 이미지 (VQ-VAE-2) 및 음악 (주크 박스)에 성공적으로 사용했습니다.
$ pip install vector-quantize-pytorch import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_size = 512 , # codebook size
decay = 0.8 , # the exponential moving average decay, lower means the dictionary will change faster
commitment_weight = 1. # the weight on the commitment loss
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = vq ( x ) # (1, 1024, 256), (1, 1024), (1) 이 논문은 다수의 벡터 양자화제를 사용하여 파형의 잔차를 재귀 적으로 양자화 할 것을 제안한다. ResidualVQ 클래스와 하나의 추가 초기화 매개 변수와 함께 사용할 수 있습니다.
import torch
from vector_quantize_pytorch import ResidualVQ
residual_vq = ResidualVQ (
dim = 256 ,
num_quantizers = 8 , # specify number of quantizers
codebook_size = 1024 , # codebook size
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = residual_vq ( x )
print ( quantized . shape , indices . shape , commit_loss . shape )
# (1, 1024, 256), (1, 1024, 8), (1, 8)
# if you need all the codes across the quantization layers, just pass return_all_codes = True
quantized , indices , commit_loss , all_codes = residual_vq ( x , return_all_codes = True )
# (8, 1, 1024, 256)또한,이 논문은 잔차 VQ를 사용하여 RQ-VAE를 구성하여 더 압축 된 코드로 고해상도 이미지를 생성합니다.
그들은 두 가지 수정을합니다. 첫 번째는 모든 Quantizers에서 코드북을 공유하는 것입니다. 두 번째는 항상 가장 가까운 경기를하는 것보다 코드를 확률 적으로 샘플링하는 것입니다. 두 가지 추가 키워드 인수와 함께이 두 기능을 모두 사용할 수 있습니다.
import torch
from vector_quantize_pytorch import ResidualVQ
residual_vq = ResidualVQ (
dim = 256 ,
num_quantizers = 8 ,
codebook_size = 1024 ,
stochastic_sample_codes = True ,
sample_codebook_temp = 0.1 , # temperature for stochastically sampling codes, 0 would be equivalent to non-stochastic
shared_codebook = True # whether to share the codebooks for all quantizers or not
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = residual_vq ( x )
# (1, 1024, 256), (1, 1024, 8), (1, 8) 최근의 논문은 또한 피처 차원 그룹에 대해 잔류 VQ를 수행 할 것을 제안하며, 코드북이 훨씬 적은 상태에서 Encodec과 동등한 결과를 보여줍니다. GroupedResidualVQ 가져 오면 사용할 수 있습니다
import torch
from vector_quantize_pytorch import GroupedResidualVQ
residual_vq = GroupedResidualVQ (
dim = 256 ,
num_quantizers = 8 , # specify number of quantizers
groups = 2 ,
codebook_size = 1024 , # codebook size
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = residual_vq ( x )
# (1, 1024, 256), (2, 1, 1024, 8), (2, 1, 8) SoundStream 용지는 코드북이 첫 번째 배치의 Kmeans Centroid에 의해 초기화되어야한다고 제안합니다. VectorQuantize 또는 ResidualVQ class에 대해 하나의 플래그 kmeans_init = True 기능을 쉽게 켤 수 있습니다.
import torch
from vector_quantize_pytorch import ResidualVQ
residual_vq = ResidualVQ (
dim = 256 ,
codebook_size = 256 ,
num_quantizers = 4 ,
kmeans_init = True , # set to True
kmeans_iters = 10 # number of kmeans iterations to calculate the centroids for the codebook on init
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = residual_vq ( x )
# (1, 1024, 256), (1, 1024, 4), (1, 4) VQ-VAE는 전통적으로 Straight-Strough Estimator (Ste)로 훈련됩니다. 거꾸로 통과하는 동안, 그라디언트는 VQ 층 주위를 통과 하지 않고 흐릅니다. 회전 트릭 종이는 vq 층을 통해 구배를 변환 할 것을 제안하므로 입력 벡터와 양자화 된 출력 사이의 상대적 각도와 크기가 그라디언트로 인코딩됩니다. VectorQuantize 클래스에서 rotation_trick=True/False 기능을 활성화 또는 비활성화 할 수 있습니다.
from vector_quantize_pytorch import VectorQuantize
vq_layer = VectorQuantize (
dim = 256 ,
codebook_size = 256 ,
rotation_trick = True , # Set to False to use the STE gradient estimator or True to use the rotation trick.
)이 저장소에는 "죽은"코드북 항목과 싸우기위한 다양한 논문의 몇 가지 기술이 포함되어 있으며, 이는 벡터 양자화기를 사용할 때 일반적인 문제입니다.
개선 된 VQGAN 용지는 코드북을 더 낮은 차원으로 유지하도록 제안합니다. 인코더 값은 양자화 후 고 차원으로 다시 투사되기 전에 투사됩니다. codebook_dim 하이퍼 파라미터로 이것을 설정할 수 있습니다.
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_size = 256 ,
codebook_dim = 16 # paper proposes setting this to 32 or as low as 8 to increase codebook usage
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = vq ( x )
# (1, 1024, 256), (1, 1024), (1,) 개선 된 VQGAN 용지는 또한 L2가 코드와 인코딩 된 벡터를 정상화하기 위해 거리에 코사인 유사성을 사용하는 것으로 보입니다. 그들은 구의 벡터를 시행한다고 주장하면 코드 사용 및 다운 스트림 재구성이 개선된다고 주장합니다. use_cosine_sim = True 설정하여 켜질 수 있습니다.
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_size = 256 ,
use_cosine_sim = True # set this to True
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = vq ( x )
# (1, 1024, 256), (1, 1024), (1,) 마지막으로, SoundStream 용지에는 현재 배치에서 무작위로 선택된 벡터로 특정 임계 값 미만의 히트가있는 코드를 대체하는 체계가 있습니다. threshold_ema_dead_code 키워드 로이 임계 값을 설정할 수 있습니다.
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_size = 512 ,
threshold_ema_dead_code = 2 # should actively replace any codes that have an exponential moving average cluster size less than 2
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = vq ( x )
# (1, 1024, 256), (1, 1024), (1,)VQ-VAE / VQ-GAN은 빠르게 인기를 얻고 있습니다. 최근의 논문은 이미지에서 벡터 양자화를 사용할 때 코드북을 직교로 시행하면 이산화 된 코드의 번역 등가로 이어지고 다운 스트림 텍스트가 이미지 생성 작업으로 크게 개선 될 것으로 제안합니다.
orthogonal_reg_weight 0 보다 크게 설정 하여이 기능을 사용할 수 있으며,이 경우 직교 정규화는 모듈에 의해 출력 된 보조 손실에 추가됩니다.
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_size = 256 ,
accept_image_fmap = True , # set this true to be able to pass in an image feature map
orthogonal_reg_weight = 10 , # in paper, they recommended a value of 10
orthogonal_reg_max_codes = 128 , # this would randomly sample from the codebook for the orthogonal regularization loss, for limiting memory usage
orthogonal_reg_active_codes_only = False # set this to True if you have a very large codebook, and would only like to enforce the loss on the activated codes per batch
)
img_fmap = torch . randn ( 1 , 256 , 32 , 32 )
quantized , indices , loss = vq ( img_fmap ) # (1, 256, 32, 32), (1, 32, 32), (1,)
# loss now contains the orthogonal regularization loss with the weight as assigned 다중 머리 접근법 (기능 당 여러 코드)을 사용하여 개별 잠재적 표현의 변형을 제안하는 여러 논문이 있습니다. 입력 차원 head 타임에 걸쳐 양자를 벡터하는 데 동일한 코드북을 사용하는 하나의 변형을 제공하기로 결정했습니다.
NWT 용지에서보다 입증 된 접근 방식 (Memcodes)을 사용할 수도 있습니다.
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_dim = 32 , # a number of papers have shown smaller codebook dimension to be acceptable
heads = 8 , # number of heads to vector quantize, codebook shared across all heads
separate_codebook_per_head = True , # whether to have a separate codebook per head. False would mean 1 shared codebook
codebook_size = 8196 ,
accept_image_fmap = True
)
img_fmap = torch . randn ( 1 , 256 , 32 , 32 )
quantized , indices , loss = vq ( img_fmap )
# (1, 256, 32, 32), (1, 32, 32, 8), (1,)이 논문은 먼저 마스킹 음성 모델링에 랜덤 프로젝션 Quantizer를 사용하도록 제안했으며, 여기서 신호는 무작위 초기화 된 매트릭스로 투사 된 다음 무작위 초기화 된 코드북과 일치합니다. 따라서 양자를 배울 필요는 없습니다. 이 기술은 Google의 Universal Speech Model에서 사용하여 음성 텍스트 모델링을위한 SOTA를 달성했습니다.
USM은 다중 코드북을 사용하고 멀티-소프트 MAX 목표를 가진 마스크 스피치 모델링을 사용하도록 제안합니다. num_codebooks 1 이상으로 설정하여 쉽게 할 수 있습니다.
import torch
from vector_quantize_pytorch import RandomProjectionQuantizer
quantizer = RandomProjectionQuantizer (
dim = 512 , # input dimensions
num_codebooks = 16 , # in USM, they used up to 16 for 5% gain
codebook_dim = 256 , # codebook dimension
codebook_size = 1024 # codebook size
)
x = torch . randn ( 1 , 1024 , 512 )
indices = quantizer ( x )
# (1, 1024, 16) 이 저장소는 또한 다중 프로세스 설정에서 코드북을 자동으로 동기화해야합니다. 어떻게 든 그렇지 않으면 문제를 열어주십시오. sync_codebook = True | False

새로운 ICLR 2025 논문은 코드북이 동결 된 체계를 제안하고 코드는 선형 투영을 통해 암시 적으로 생성됩니다. 저자는이 설정이 코드북 붕괴가 줄어들고 수렴이 쉬워 진다고 주장합니다. 나는 50 등의 회전 트릭과 쌍을 이룰 때 더 나은 성능을 발휘하고 선형 투영을 작은 원 층 MLP로 확장하는 것으로 나타났습니다. 그렇게 실험 할 수 있습니다
업데이트 : 청각 혼합 결과
import torch
from vector_quantize_pytorch import SimVQ
sim_vq = SimVQ (
dim = 512 ,
codebook_size = 1024 ,
rotation_trick = True # use rotation trick from Fifty et al.
)
x = torch . randn ( 1 , 1024 , 512 )
quantized , indices , commit_loss = sim_vq ( x )
assert x . shape == quantized . shape
assert torch . allclose ( quantized , sim_vq . indices_to_codes ( indices ), atol = 1e-6 ) 잔류 풍미의 경우 대신 ResidualSimVQ 가져 오십시오
import torch
from vector_quantize_pytorch import ResidualSimVQ
residual_sim_vq = ResidualSimVQ (
dim = 512 ,
num_quantizers = 4 ,
codebook_size = 1024 ,
rotation_trick = True # use rotation trick from Fifty et al.
)
x = torch . randn ( 1 , 1024 , 512 )
quantized , indices , commit_loss = residual_sim_vq ( x )
assert x . shape == quantized . shape
assert torch . allclose ( quantized , residual_sim_vq . get_output_from_indices ( indices ), atol = 1e-6 )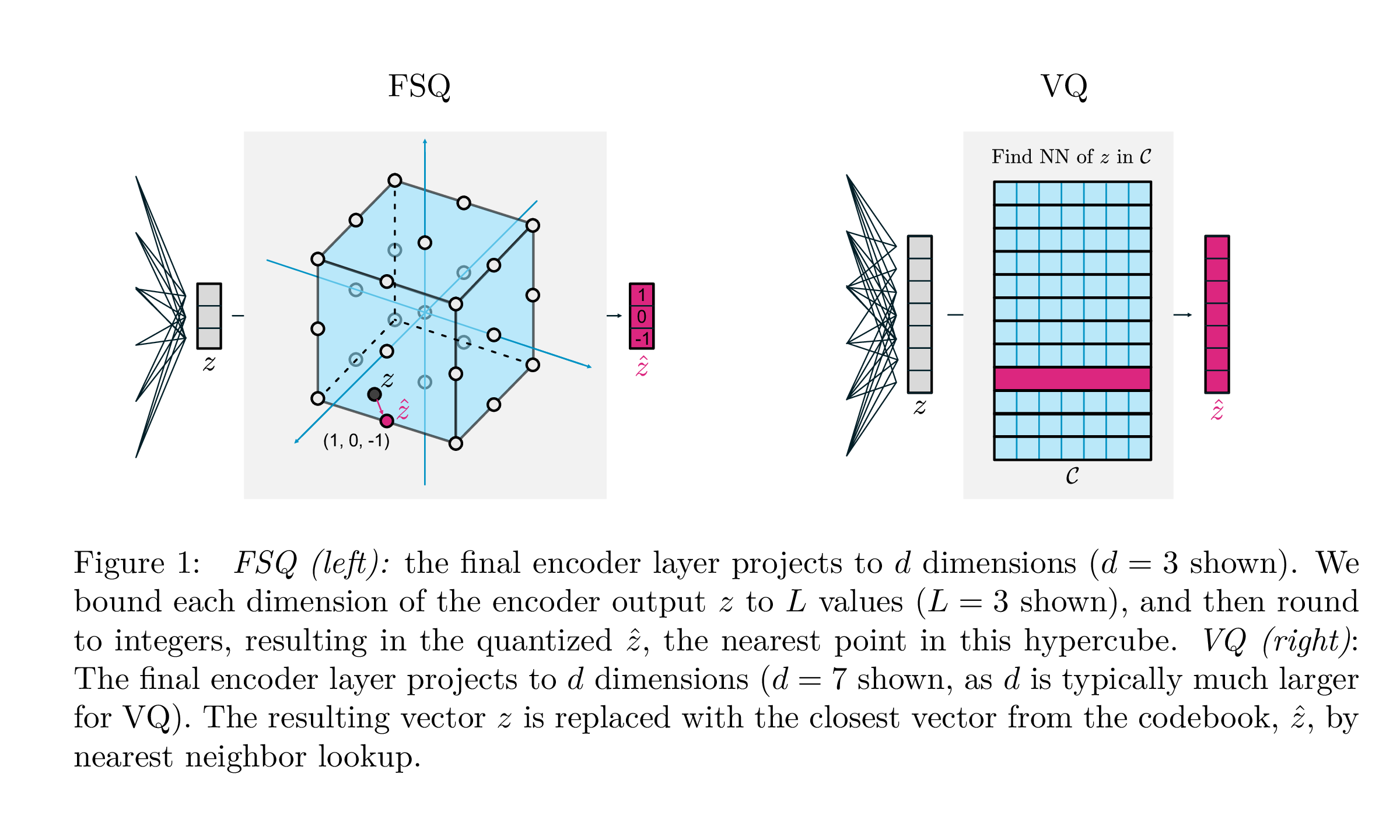
| vq | FSQ | |
|---|---|---|
| 양자화 | argmin_c || ZC || | 라운드 (F (Z)) |
| 그라디언트 | 똑바로 추정 (Ste) | 스테 |
| 보조 손실 | 약속, 코드북, 엔트로피 손실, ... | N/A |
| 트릭 | 코드북의 EMA, 코드북 분할, 예측, ... | N/A |
| 매개 변수 | 코드북 | N/A |
Google Deepmind 의이 작업은 생성 모델링을 위해 벡터 양자화가 수행되는 방식을 크게 단순화하고, 약정 손실의 필요성을 제거하고, 코드북의 EMA 업데이트 및 코드북 붕괴 또는 불충분 한 활용과 관련된 문제를 해결하는 것을 목표로합니다. 그들은 단순히 각 스칼라를 그라디언트를 통해 직선으로 이산 레벨로 반올림합니다. 코드는 하이퍼 큐브에서 균일 한 지점이됩니다.
레코드 시간 에이 구현을 포팅 해 주신 @sekstini에게 감사드립니다!
import torch
from vector_quantize_pytorch import FSQ
quantizer = FSQ (
levels = [ 8 , 5 , 5 , 5 ]
)
x = torch . randn ( 1 , 1024 , 4 ) # 4 since there are 4 levels
xhat , indices = quantizer ( x )
# (1, 1024, 4), (1, 1024)
assert torch . all ( xhat == quantizer . indices_to_codes ( indices ))오디오 인코딩을 개선하려는 시도를위한 즉흥적 인 잔류 FSQ.
신용은 원래 아이디어를 여기에서 받아들이는 @sekstini로 이동합니다.
import torch
from vector_quantize_pytorch import ResidualFSQ
residual_fsq = ResidualFSQ (
dim = 256 ,
levels = [ 8 , 5 , 5 , 3 ],
num_quantizers = 8
)
x = torch . randn ( 1 , 1024 , 256 )
residual_fsq . eval ()
quantized , indices = residual_fsq ( x )
# (1, 1024, 256), (1, 1024, 8)
quantized_out = residual_fsq . get_output_from_indices ( indices )
# (1, 1024, 256)
assert torch . all ( quantized == quantized_out )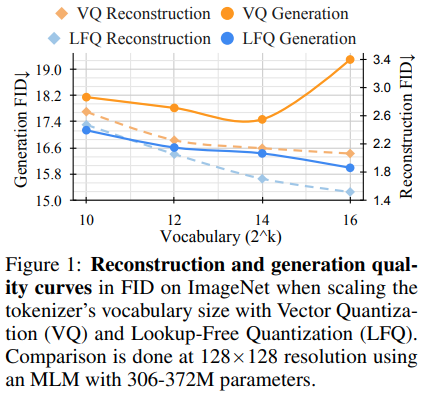
Magvit의 연구팀은 생성 비디오 모델링을위한 새로운 SOTA 결과를 발표했습니다. V1과 V2 사이의 핵심 변화에는 새로운 유형의 양자화, LFQ (Look-Up Free Quantization)가 포함되며, 이는 코드북을 완전히 제거하고 전부 조회를 포함시킵니다.
이 논문은 독립적 인 바이너리 잠복을 사용하는 간단한 LFQ 양자 제를 제시합니다. LFQ의 다른 구현이 존재합니다. 그러나 팀은 LFQ가있는 MAGVIT-V2가 ImageNet 벤치 마크에서 크게 향상된다는 것을 보여줍니다. LFQ와 2 단계 FSQ의 차이에는 엔트로피 정규화 및 유지 보수 손실이 포함됩니다.
Codebook-Lookup없이보다 고급 LFQ 양자화 방법을 개발하면 생성 모델링에 혁명을 일으킬 수 있습니다.
다음과 같이 간단히 사용할 수 있습니다. Magvit2 Pytorch Port에서 개를 먹을 것입니다
import torch
from vector_quantize_pytorch import LFQ
# you can specify either dim or codebook_size
# if both specified, will be validated against each other
quantizer = LFQ (
codebook_size = 65536 , # codebook size, must be a power of 2
dim = 16 , # this is the input feature dimension, defaults to log2(codebook_size) if not defined
entropy_loss_weight = 0.1 , # how much weight to place on entropy loss
diversity_gamma = 1. # within entropy loss, how much weight to give to diversity of codes, taken from https://arxiv.org/abs/1911.05894
)
image_feats = torch . randn ( 1 , 16 , 32 , 32 )
quantized , indices , entropy_aux_loss = quantizer ( image_feats , inv_temperature = 100. ) # you may want to experiment with temperature
# (1, 16, 32, 32), (1, 32, 32), ()
assert ( quantized == quantizer . indices_to_codes ( indices )). all () (batch, feat, time, height, width) 또는 시퀀스 (batch, seq, feat) 와 같은 비디오 기능을 전달할 수도 있습니다.
import torch
from vector_quantize_pytorch import LFQ
quantizer = LFQ (
codebook_size = 65536 ,
dim = 16 ,
entropy_loss_weight = 0.1 ,
diversity_gamma = 1.
)
seq = torch . randn ( 1 , 32 , 16 )
quantized , * _ = quantizer ( seq )
assert seq . shape == quantized . shape
video_feats = torch . randn ( 1 , 16 , 10 , 32 , 32 )
quantized , * _ = quantizer ( video_feats )
assert video_feats . shape == quantized . shape또는 여러 코드북을 지원합니다
import torch
from vector_quantize_pytorch import LFQ
quantizer = LFQ (
codebook_size = 4096 ,
dim = 16 ,
num_codebooks = 4 # 4 codebooks, total codebook dimension is log2(4096) * 4
)
image_feats = torch . randn ( 1 , 16 , 32 , 32 )
quantized , indices , entropy_aux_loss = quantizer ( image_feats )
# (1, 16, 32, 32), (1, 32, 32, 4), ()
assert image_feats . shape == quantized . shape
assert ( quantized == quantizer . indices_to_codes ( indices )). all ()즉흥적 인 잔류 LFQ, 그것이 오디오 압축의 개선으로 이어질 수 있는지 확인합니다.
import torch
from vector_quantize_pytorch import ResidualLFQ
residual_lfq = ResidualLFQ (
dim = 256 ,
codebook_size = 256 ,
num_quantizers = 8
)
x = torch . randn ( 1 , 1024 , 256 )
residual_lfq . eval ()
quantized , indices , commit_loss = residual_lfq ( x )
# (1, 1024, 256), (1, 1024, 8), (8)
quantized_out = residual_lfq . get_output_from_indices ( indices )
# (1, 1024, 256)
assert torch . all ( quantized == quantized_out )해석은 해석 성, 일반화, 개선 된 학습 및 견고성을 촉진하므로 표현 학습에 필수적입니다. 데이터의 의미 있고 독립적 인 기능을 캡처하는 목표와 일치하여 다양한 응용 분야에서 학습 된 표현을보다 효과적으로 사용하는 것을 촉진합니다. 더 나은 분리를 위해, 과제는 명시적인 근거 진실 정보없이 데이터 세트의 기본 변형을 분해하는 것입니다. 이 작업은 조직화 된 잠재 공간 내에서 인코딩 및 디코딩을 목표로하는 주요 유도 편향을 소개합니다. 통합 된 전략은 각 차원에 대해 개별 학습 가능한 스칼라 코드북의 활용을 통해 개별 코드 벡터를 할당하여 잠재 공간을 이산화하는 것을 포함합니다. 이 방법론을 사용하면 모델이 강력한 사전 방법을 효과적으로 능가 할 수 있습니다.
이 백서의 결과에 대해 매우 높은 무게 부패를 사용해야한다는 점에주의하십시오.
import torch
from vector_quantize_pytorch import LatentQuantize
# you can specify either dim or codebook_size
# if both specified, will be validated against each other
quantizer = LatentQuantize (
levels = [ 5 , 5 , 8 ], # number of levels per codebook dimension
dim = 16 , # input dim
commitment_loss_weight = 0.1 ,
quantization_loss_weight = 0.1 ,
)
image_feats = torch . randn ( 1 , 16 , 32 , 32 )
quantized , indices , loss = quantizer ( image_feats )
# (1, 16, 32, 32), (1, 32, 32), ()
assert image_feats . shape == quantized . shape
assert ( quantized == quantizer . indices_to_codes ( indices )). all () (batch, feat, time, height, width) 또는 시퀀스 (batch, seq, feat) 와 같은 비디오 기능을 전달할 수도 있습니다.
import torch
from vector_quantize_pytorch import LatentQuantize
quantizer = LatentQuantize (
levels = [ 5 , 5 , 8 ],
dim = 16 ,
commitment_loss_weight = 0.1 ,
quantization_loss_weight = 0.1 ,
)
seq = torch . randn ( 1 , 32 , 16 )
quantized , * _ = quantizer ( seq )
# (1, 32, 16)
video_feats = torch . randn ( 1 , 16 , 10 , 32 , 32 )
quantized , * _ = quantizer ( video_feats )
# (1, 16, 10, 32, 32)또는 여러 코드북을 지원합니다
import torch
from vector_quantize_pytorch import LatentQuantize
model = LatentQuantize (
levels = [ 4 , 8 , 16 ],
dim = 9 ,
num_codebooks = 3
)
input_tensor = torch . randn ( 2 , 3 , dim )
output_tensor , indices , loss = model ( input_tensor )
# (2, 3, 9), (2, 3, 3), ()
assert output_tensor . shape == input_tensor . shape
assert indices . shape == ( 2 , 3 , num_codebooks )
assert loss . item () >= 0 @misc { oord2018neural ,
title = { Neural Discrete Representation Learning } ,
author = { Aaron van den Oord and Oriol Vinyals and Koray Kavukcuoglu } ,
year = { 2018 } ,
eprint = { 1711.00937 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { zeghidour2021soundstream ,
title = { SoundStream: An End-to-End Neural Audio Codec } ,
author = { Neil Zeghidour and Alejandro Luebs and Ahmed Omran and Jan Skoglund and Marco Tagliasacchi } ,
year = { 2021 } ,
eprint = { 2107.03312 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.SD }
} @inproceedings { anonymous2022vectorquantized ,
title = { Vector-quantized Image Modeling with Improved {VQGAN} } ,
author = { Anonymous } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=pfNyExj7z2 } ,
note = { under review }
} @inproceedings { lee2022autoregressive ,
title = { Autoregressive Image Generation using Residual Quantization } ,
author = { Lee, Doyup and Kim, Chiheon and Kim, Saehoon and Cho, Minsu and Han, Wook-Shin } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition } ,
pages = { 11523--11532 } ,
year = { 2022 }
} @article { Defossez2022HighFN ,
title = { High Fidelity Neural Audio Compression } ,
author = { Alexandre D'efossez and Jade Copet and Gabriel Synnaeve and Yossi Adi } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.13438 }
} @inproceedings { Chiu2022SelfsupervisedLW ,
title = { Self-supervised Learning with Random-projection Quantizer for Speech Recognition } ,
author = { Chung-Cheng Chiu and James Qin and Yu Zhang and Jiahui Yu and Yonghui Wu } ,
booktitle = { International Conference on Machine Learning } ,
year = { 2022 }
} @inproceedings { Zhang2023GoogleUS ,
title = { Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages } ,
author = { Yu Zhang and Wei Han and James Qin and Yongqiang Wang and Ankur Bapna and Zhehuai Chen and Nanxin Chen and Bo Li and Vera Axelrod and Gary Wang and Zhong Meng and Ke Hu and Andrew Rosenberg and Rohit Prabhavalkar and Daniel S. Park and Parisa Haghani and Jason Riesa and Ginger Perng and Hagen Soltau and Trevor Strohman and Bhuvana Ramabhadran and Tara N. Sainath and Pedro J. Moreno and Chung-Cheng Chiu and Johan Schalkwyk and Franccoise Beaufays and Yonghui Wu } ,
year = { 2023 }
} @inproceedings { Shen2023NaturalSpeech2L ,
title = { NaturalSpeech 2: Latent Diffusion Models are Natural and Zero-Shot Speech and Singing Synthesizers } ,
author = { Kai Shen and Zeqian Ju and Xu Tan and Yanqing Liu and Yichong Leng and Lei He and Tao Qin and Sheng Zhao and Jiang Bian } ,
year = { 2023 }
} @inproceedings { Yang2023HiFiCodecGV ,
title = { HiFi-Codec: Group-residual Vector quantization for High Fidelity Audio Codec } ,
author = { Dongchao Yang and Songxiang Liu and Rongjie Huang and Jinchuan Tian and Chao Weng and Yuexian Zou } ,
year = { 2023 }
} @inproceedings { huh2023improvedvqste ,
title = { Straightening Out the Straight-Through Estimator: Overcoming Optimization Challenges in Vector Quantized Networks } ,
author = { Huh, Minyoung and Cheung, Brian and Agrawal, Pulkit and Isola, Phillip } ,
booktitle = { International Conference on Machine Learning } ,
year = { 2023 } ,
organization = { PMLR }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @misc { shin2021translationequivariant ,
title = { Translation-equivariant Image Quantizer for Bi-directional Image-Text Generation } ,
author = { Woncheol Shin and Gyubok Lee and Jiyoung Lee and Joonseok Lee and Edward Choi } ,
year = { 2021 } ,
eprint = { 2112.00384 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { mentzer2023finite ,
title = { Finite Scalar Quantization: VQ-VAE Made Simple } ,
author = { Fabian Mentzer and David Minnen and Eirikur Agustsson and Michael Tschannen } ,
year = { 2023 } ,
eprint = { 2309.15505 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { yu2023language ,
title = { Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation } ,
author = { Lijun Yu and José Lezama and Nitesh B. Gundavarapu and Luca Versari and Kihyuk Sohn and David Minnen and Yong Cheng and Agrim Gupta and Xiuye Gu and Alexander G. Hauptmann and Boqing Gong and Ming-Hsuan Yang and Irfan Essa and David A. Ross and Lu Jiang } ,
year = { 2023 } ,
eprint = { 2310.05737 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @inproceedings { Zhao2024ImageAV ,
title = { Image and Video Tokenization with Binary Spherical Quantization } ,
author = { Yue Zhao and Yuanjun Xiong and Philipp Krahenbuhl } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:270380237 }
} @misc { hsu2023disentanglement ,
title = { Disentanglement via Latent Quantization } ,
author = { Kyle Hsu and Will Dorrell and James C. R. Whittington and Jiajun Wu and Chelsea Finn } ,
year = { 2023 } ,
eprint = { 2305.18378 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @inproceedings { Irie2023SelfOrganisingND ,
title = { Self-Organising Neural Discrete Representation Learning `a la Kohonen } ,
author = { Kazuki Irie and R'obert Csord'as and J{"u}rgen Schmidhuber } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:256901024 }
} @article { Huijben2024ResidualQW ,
title = { Residual Quantization with Implicit Neural Codebooks } ,
author = { Iris Huijben and Matthijs Douze and Matthew Muckley and Ruud van Sloun and Jakob Verbeek } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2401.14732 } ,
url = { https://api.semanticscholar.org/CorpusID:267301189 }
} @article { Fifty2024Restructuring ,
title = { Restructuring Vector Quantization with the Rotation Trick } ,
author = { Christopher Fifty, Ronald G. Junkins, Dennis Duan, Aniketh Iyengar, Jerry W. Liu, Ehsan Amid, Sebastian Thrun, Christopher Ré } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2410.06424 } ,
url = { https://api.semanticscholar.org/CorpusID:273229218 }
} @inproceedings { Zhu2024AddressingRC ,
title = { Addressing Representation Collapse in Vector Quantized Models with One Linear Layer } ,
author = { Yongxin Zhu and Bocheng Li and Yifei Xin and Linli Xu } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273812459 }
}

