vector quantize pytorch
1.20.11
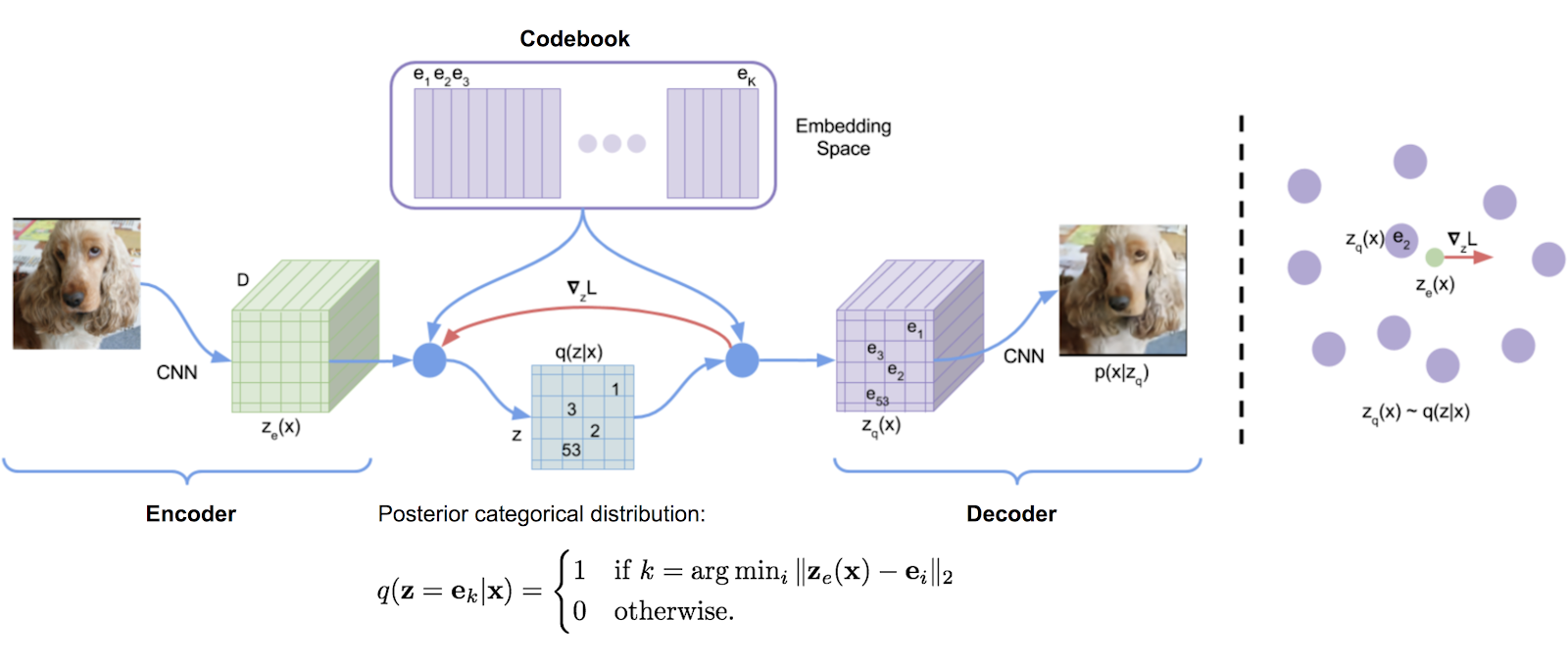
Perpustakaan kuantisasi vektor yang awalnya ditranskripsi dari implementasi TensorFlow DeepMind, dibuat dengan nyaman menjadi paket. Ini menggunakan rata -rata bergerak eksponensial untuk memperbarui kamus.
VQ telah berhasil digunakan oleh DeepMind dan OpenAi untuk generasi gambar berkualitas tinggi (VQ-VAE-2) dan musik (Jukebox).
$ pip install vector-quantize-pytorch import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_size = 512 , # codebook size
decay = 0.8 , # the exponential moving average decay, lower means the dictionary will change faster
commitment_weight = 1. # the weight on the commitment loss
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = vq ( x ) # (1, 1024, 256), (1, 1024), (1) Makalah ini mengusulkan untuk menggunakan beberapa kuantisasi vektor untuk secara rekursif menghitung residu dari bentuk gelombang. Anda dapat menggunakan ini dengan kelas ResidualVQ dan satu parameter inisialisasi tambahan.
import torch
from vector_quantize_pytorch import ResidualVQ
residual_vq = ResidualVQ (
dim = 256 ,
num_quantizers = 8 , # specify number of quantizers
codebook_size = 1024 , # codebook size
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = residual_vq ( x )
print ( quantized . shape , indices . shape , commit_loss . shape )
# (1, 1024, 256), (1, 1024, 8), (1, 8)
# if you need all the codes across the quantization layers, just pass return_all_codes = True
quantized , indices , commit_loss , all_codes = residual_vq ( x , return_all_codes = True )
# (8, 1, 1024, 256)Selain itu, makalah ini menggunakan residual-VQ untuk membangun RQ-VAE, untuk menghasilkan gambar resolusi tinggi dengan kode yang lebih terkompresi.
Mereka membuat dua modifikasi. Yang pertama adalah membagikan codebook di semua kuantisasi. Yang kedua adalah mencicipi kode secara stokastik daripada selalu mengambil pertandingan terdekat. Anda dapat menggunakan kedua fitur ini dengan dua argumen kata kunci tambahan.
import torch
from vector_quantize_pytorch import ResidualVQ
residual_vq = ResidualVQ (
dim = 256 ,
num_quantizers = 8 ,
codebook_size = 1024 ,
stochastic_sample_codes = True ,
sample_codebook_temp = 0.1 , # temperature for stochastically sampling codes, 0 would be equivalent to non-stochastic
shared_codebook = True # whether to share the codebooks for all quantizers or not
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = residual_vq ( x )
# (1, 1024, 256), (1, 1024, 8), (1, 8) Sebuah makalah baru -baru ini lebih lanjut mengusulkan untuk melakukan residu VQ pada kelompok dimensi fitur, menunjukkan hasil yang setara untuk EncodeC saat menggunakan buku kode yang jauh lebih sedikit. Anda dapat menggunakannya dengan mengimpor GroupedResidualVQ
import torch
from vector_quantize_pytorch import GroupedResidualVQ
residual_vq = GroupedResidualVQ (
dim = 256 ,
num_quantizers = 8 , # specify number of quantizers
groups = 2 ,
codebook_size = 1024 , # codebook size
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = residual_vq ( x )
# (1, 1024, 256), (2, 1, 1024, 8), (2, 1, 8) Makalah Soundstream mengusulkan bahwa codebook harus diinisialisasi oleh centroid Kmeans dari batch pertama. Anda dapat dengan mudah menyalakan fitur ini dengan satu bendera kmeans_init = True , baik untuk kelas VectorQuantize atau ResidualVQ
import torch
from vector_quantize_pytorch import ResidualVQ
residual_vq = ResidualVQ (
dim = 256 ,
codebook_size = 256 ,
num_quantizers = 4 ,
kmeans_init = True , # set to True
kmeans_iters = 10 # number of kmeans iterations to calculate the centroids for the codebook on init
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = residual_vq ( x )
# (1, 1024, 256), (1, 1024, 4), (1, 4) VQ-VAE secara tradisional dilatih dengan penaksir lurus (Ste). Selama lulus mundur, gradien mengalir di sekitar lapisan VQ daripada melaluinya . Kertas trik rotasi mengusulkan untuk mengubah gradien melalui lapisan VQ sehingga sudut relatif dan besarnya antara vektor input dan output terkuantisasi dikodekan ke dalam gradien. Anda dapat mengaktifkan atau menonaktifkan fitur ini dengan rotation_trick=True/False di kelas VectorQuantize .
from vector_quantize_pytorch import VectorQuantize
vq_layer = VectorQuantize (
dim = 256 ,
codebook_size = 256 ,
rotation_trick = True , # Set to False to use the STE gradient estimator or True to use the rotation trick.
)Repositori ini akan berisi beberapa teknik dari berbagai makalah untuk memerangi entri codebook "mati", yang merupakan masalah umum saat menggunakan quantizer vektor.
Kertas VQGAN yang ditingkatkan mengusulkan agar codebook disimpan dalam dimensi yang lebih rendah. Nilai -nilai encoder diproyeksikan sebelum diproyeksikan kembali ke dimensi tinggi setelah kuantisasi. Anda dapat mengatur ini dengan hyperparameter codebook_dim .
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_size = 256 ,
codebook_dim = 16 # paper proposes setting this to 32 or as low as 8 to increase codebook usage
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = vq ( x )
# (1, 1024, 256), (1, 1024), (1,) Kertas VQGAN yang ditingkatkan juga mengusulkan untuk menormalkan kode dan vektor yang dikodekan, yang bermuara pada menggunakan kesamaan cosinus untuk jarak. Mereka mengklaim menegakkan vektor pada suatu bidang mengarah pada peningkatan penggunaan kode dan rekonstruksi hilir. Anda dapat menyalakannya dengan mengatur use_cosine_sim = True
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_size = 256 ,
use_cosine_sim = True # set this to True
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = vq ( x )
# (1, 1024, 256), (1, 1024), (1,) Akhirnya, kertas Soundstream memiliki skema di mana mereka mengganti kode yang memiliki hit di bawah ambang batas tertentu dengan vektor yang dipilih secara acak dari batch saat ini. Anda dapat mengatur ambang ini dengan kata kunci threshold_ema_dead_code .
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_size = 512 ,
threshold_ema_dead_code = 2 # should actively replace any codes that have an exponential moving average cluster size less than 2
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = vq ( x )
# (1, 1024, 256), (1, 1024), (1,)VQ-VAE / VQ-GAN dengan cepat mendapatkan popularitas. Sebuah makalah baru -baru ini mengusulkan bahwa ketika menggunakan kuantisasi vektor pada gambar, menegakkan codebook menjadi mengarah ke ortogonal ke kesetaraan terjemahan dari kode yang diskrit, yang mengarah pada peningkatan besar dalam teks hilir ke tugas pembuatan gambar.
Anda dapat menggunakan fitur ini hanya dengan mengatur kelas orthogonal_reg_weight menjadi lebih besar dari 0 , dalam hal ini regularisasi ortogonal akan ditambahkan ke kerugian tambahan yang dikeluarkan oleh modul.
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_size = 256 ,
accept_image_fmap = True , # set this true to be able to pass in an image feature map
orthogonal_reg_weight = 10 , # in paper, they recommended a value of 10
orthogonal_reg_max_codes = 128 , # this would randomly sample from the codebook for the orthogonal regularization loss, for limiting memory usage
orthogonal_reg_active_codes_only = False # set this to True if you have a very large codebook, and would only like to enforce the loss on the activated codes per batch
)
img_fmap = torch . randn ( 1 , 256 , 32 , 32 )
quantized , indices , loss = vq ( img_fmap ) # (1, 256, 32, 32), (1, 32, 32), (1,)
# loss now contains the orthogonal regularization loss with the weight as assigned Ada sejumlah makalah yang mengusulkan varian representasi laten diskrit dengan pendekatan multi-berkepala (beberapa kode per fitur). Saya telah memutuskan untuk menawarkan satu varian di mana codebook yang sama digunakan untuk membuat vektor kuantisasi di seluruh waktu head dimensi input.
Anda juga dapat menggunakan pendekatan yang lebih terbukti (memcodes) dari kertas NWT
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_dim = 32 , # a number of papers have shown smaller codebook dimension to be acceptable
heads = 8 , # number of heads to vector quantize, codebook shared across all heads
separate_codebook_per_head = True , # whether to have a separate codebook per head. False would mean 1 shared codebook
codebook_size = 8196 ,
accept_image_fmap = True
)
img_fmap = torch . randn ( 1 , 256 , 32 , 32 )
quantized , indices , loss = vq ( img_fmap )
# (1, 256, 32, 32), (1, 32, 32, 8), (1,)Makalah ini pertama kali mengusulkan untuk menggunakan quantizer proyeksi acak untuk pemodelan bicara bertopeng, di mana sinyal diproyeksikan dengan matriks yang diinisialisasi secara acak dan kemudian dicocokkan dengan codebook yang diinisialisasi secara acak. Oleh karena itu, seseorang tidak perlu mempelajari kuantizer. Teknik ini digunakan oleh model ucapan universal Google untuk mencapai SOTA untuk pemodelan ucapan-ke-teks.
USM lebih lanjut mengusulkan untuk menggunakan beberapa codebook, dan pemodelan ucapan bertopeng dengan tujuan multi-softmax. Anda dapat melakukan ini dengan mudah dengan mengatur num_codebooks menjadi lebih besar dari 1
import torch
from vector_quantize_pytorch import RandomProjectionQuantizer
quantizer = RandomProjectionQuantizer (
dim = 512 , # input dimensions
num_codebooks = 16 , # in USM, they used up to 16 for 5% gain
codebook_dim = 256 , # codebook dimension
codebook_size = 1024 # codebook size
)
x = torch . randn ( 1 , 1024 , 512 )
indices = quantizer ( x )
# (1, 1024, 16) Repositori ini juga harus secara otomatis menyinkronkan CodeBook dalam pengaturan multi-proses. Jika entah bagaimana tidak, silakan buka masalah. Anda dapat mengganti apakah akan menyinkronkan CodeBook atau tidak dengan mengatur sync_codebook = True | False

Makalah ICLR 2025 baru mengusulkan skema di mana codebook dibekukan, dan kode secara implisit dihasilkan melalui proyeksi linier. Para penulis mengklaim pengaturan ini menyebabkan keruntuhan codebook yang lebih sedikit serta konvergensi yang lebih mudah. Saya telah menemukan ini untuk berkinerja lebih baik ketika dipasangkan dengan trik rotasi dari Fifty et al., Dan memperluas proyeksi linier ke MLP satu lapisan kecil. Anda dapat bereksperimen dengannya
UPDATE: Mendengar hasil yang beragam
import torch
from vector_quantize_pytorch import SimVQ
sim_vq = SimVQ (
dim = 512 ,
codebook_size = 1024 ,
rotation_trick = True # use rotation trick from Fifty et al.
)
x = torch . randn ( 1 , 1024 , 512 )
quantized , indices , commit_loss = sim_vq ( x )
assert x . shape == quantized . shape
assert torch . allclose ( quantized , sim_vq . indices_to_codes ( indices ), atol = 1e-6 ) Untuk rasa residual, cukup impor ResidualSimVQ sebagai gantinya
import torch
from vector_quantize_pytorch import ResidualSimVQ
residual_sim_vq = ResidualSimVQ (
dim = 512 ,
num_quantizers = 4 ,
codebook_size = 1024 ,
rotation_trick = True # use rotation trick from Fifty et al.
)
x = torch . randn ( 1 , 1024 , 512 )
quantized , indices , commit_loss = residual_sim_vq ( x )
assert x . shape == quantized . shape
assert torch . allclose ( quantized , residual_sim_vq . get_output_from_indices ( indices ), atol = 1e-6 )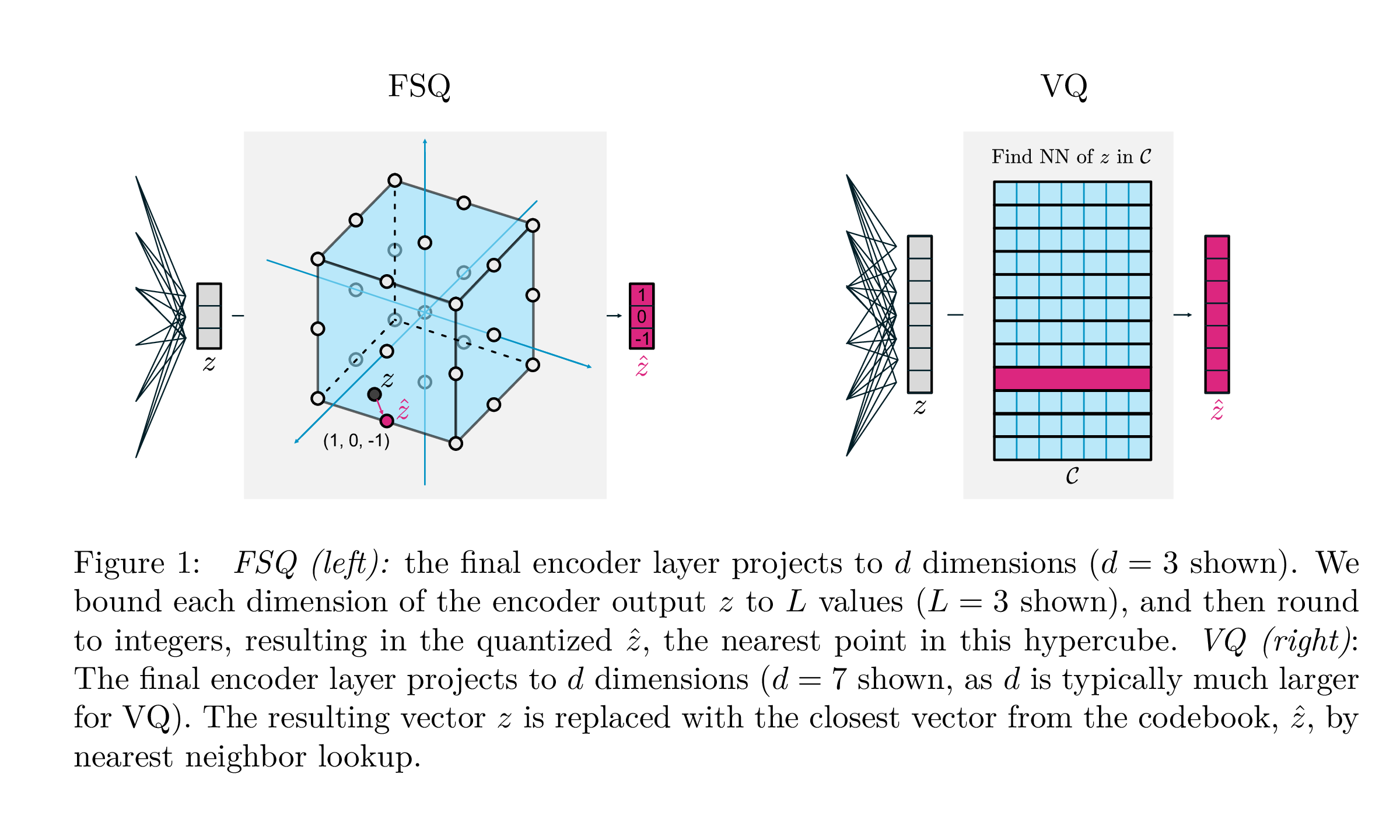
| VQ | FSQ | |
|---|---|---|
| Kuantisasi | argmin_c || zc || | putaran (f (z)) |
| Gradien | Lurus melalui estimasi (Ste) | Ste |
| Kerugian tambahan | Komitmen, Codebook, Kehilangan Entropi, ... | N/a |
| Trik | EMA di CodeBook, CodeBook pemisahan, proyeksi, ... | N/a |
| Parameter | Codebook | N/a |
Pekerjaan ini keluar dari Google DeepMind bertujuan untuk sangat menyederhanakan cara kuantisasi vektor dilakukan untuk pemodelan generatif, menghapus kebutuhan akan kehilangan komitmen, memperbarui CodeBook, serta mengatasi masalah dengan keruntuhan codebook atau pemanfaatan yang tidak memadai. Mereka hanya membulatkan setiap skalar ke tingkat diskrit dengan gradien lurus melalui; Kode menjadi titik seragam dalam hypercube.
Terima kasih kepada @sekstini untuk porting atas implementasi ini dalam waktu catatan!
import torch
from vector_quantize_pytorch import FSQ
quantizer = FSQ (
levels = [ 8 , 5 , 5 , 5 ]
)
x = torch . randn ( 1 , 1024 , 4 ) # 4 since there are 4 levels
xhat , indices = quantizer ( x )
# (1, 1024, 4), (1, 1024)
assert torch . all ( xhat == quantizer . indices_to_codes ( indices ))FSQ residual improvisasi, untuk upaya meningkatkan pengkodean audio.
Kredit pergi ke @sekstini karena awalnya mencantumkan ide di sini
import torch
from vector_quantize_pytorch import ResidualFSQ
residual_fsq = ResidualFSQ (
dim = 256 ,
levels = [ 8 , 5 , 5 , 3 ],
num_quantizers = 8
)
x = torch . randn ( 1 , 1024 , 256 )
residual_fsq . eval ()
quantized , indices = residual_fsq ( x )
# (1, 1024, 256), (1, 1024, 8)
quantized_out = residual_fsq . get_output_from_indices ( indices )
# (1, 1024, 256)
assert torch . all ( quantized == quantized_out )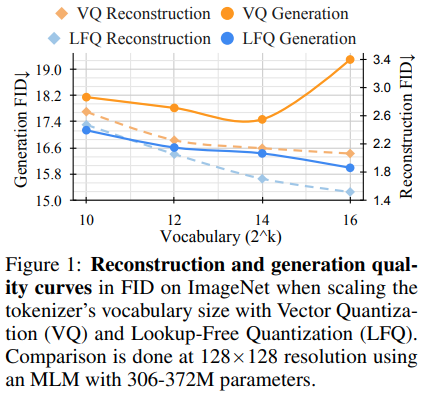
Tim peneliti di belakang Magvit telah merilis hasil SOTA baru untuk pemodelan video generatif. Perubahan inti antara V1 dan V2 mencakup jenis kuantisasi baru, pencarian kuantisasi bebas (LFQ), yang menghilangkan codebook dan pencarian penyematan sepenuhnya.
Makalah ini menyajikan quantizer LFQ sederhana menggunakan laten biner independen. Implementasi LFQ lainnya ada. Namun, tim menunjukkan bahwa Magvit-V2 dengan LFQ secara signifikan meningkat pada tolok ukur Imagenet. Perbedaan antara LFQ dan FSQ 2-level termasuk regulropi entropi serta kerugian komitmen yang dipertahankan.
Mengembangkan metode kuantisasi LFQ yang lebih canggih tanpa pencarian codebook dapat merevolusi pemodelan generatif.
Anda dapat menggunakannya hanya sebagai berikut. Akan dogfooded di Magvit2 Pytorch Port
import torch
from vector_quantize_pytorch import LFQ
# you can specify either dim or codebook_size
# if both specified, will be validated against each other
quantizer = LFQ (
codebook_size = 65536 , # codebook size, must be a power of 2
dim = 16 , # this is the input feature dimension, defaults to log2(codebook_size) if not defined
entropy_loss_weight = 0.1 , # how much weight to place on entropy loss
diversity_gamma = 1. # within entropy loss, how much weight to give to diversity of codes, taken from https://arxiv.org/abs/1911.05894
)
image_feats = torch . randn ( 1 , 16 , 32 , 32 )
quantized , indices , entropy_aux_loss = quantizer ( image_feats , inv_temperature = 100. ) # you may want to experiment with temperature
# (1, 16, 32, 32), (1, 32, 32), ()
assert ( quantized == quantizer . indices_to_codes ( indices )). all () Anda juga dapat meneruskan fitur video sebagai (batch, feat, time, height, width) atau urutan sebagai (batch, seq, feat)
import torch
from vector_quantize_pytorch import LFQ
quantizer = LFQ (
codebook_size = 65536 ,
dim = 16 ,
entropy_loss_weight = 0.1 ,
diversity_gamma = 1.
)
seq = torch . randn ( 1 , 32 , 16 )
quantized , * _ = quantizer ( seq )
assert seq . shape == quantized . shape
video_feats = torch . randn ( 1 , 16 , 10 , 32 , 32 )
quantized , * _ = quantizer ( video_feats )
assert video_feats . shape == quantized . shapeAtau mendukung beberapa codebook
import torch
from vector_quantize_pytorch import LFQ
quantizer = LFQ (
codebook_size = 4096 ,
dim = 16 ,
num_codebooks = 4 # 4 codebooks, total codebook dimension is log2(4096) * 4
)
image_feats = torch . randn ( 1 , 16 , 32 , 32 )
quantized , indices , entropy_aux_loss = quantizer ( image_feats )
# (1, 16, 32, 32), (1, 32, 32, 4), ()
assert image_feats . shape == quantized . shape
assert ( quantized == quantizer . indices_to_codes ( indices )). all ()LFQ residual improvisasi, untuk melihat apakah itu dapat menyebabkan peningkatan untuk kompresi audio.
import torch
from vector_quantize_pytorch import ResidualLFQ
residual_lfq = ResidualLFQ (
dim = 256 ,
codebook_size = 256 ,
num_quantizers = 8
)
x = torch . randn ( 1 , 1024 , 256 )
residual_lfq . eval ()
quantized , indices , commit_loss = residual_lfq ( x )
# (1, 1024, 256), (1, 1024, 8), (8)
quantized_out = residual_lfq . get_output_from_indices ( indices )
# (1, 1024, 256)
assert torch . all ( quantized == quantized_out )Disentanglement sangat penting untuk pembelajaran representasi karena mempromosikan interpretabilitas, generalisasi, peningkatan pembelajaran, dan ketahanan. Ini selaras dengan tujuan menangkap fitur data yang bermakna dan independen, memfasilitasi penggunaan representasi yang lebih efektif di berbagai aplikasi. Untuk pemasangan yang lebih baik, tantangannya adalah menguraikan variasi yang mendasari dalam dataset tanpa informasi kebenaran tanah yang eksplisit. Karya ini memperkenalkan bias induktif utama yang ditujukan untuk pengkodean dan decoding dalam ruang laten yang terorganisir. Strategi yang dimasukkan mencakup mendiskritisasi ruang laten dengan menetapkan vektor kode diskrit melalui pemanfaatan codebook skalar yang dapat dipelajari individu untuk setiap dimensi. Metodologi ini memungkinkan model mereka untuk melampaui metode sebelumnya yang kuat secara efektif.
Ketahuilah mereka harus menggunakan pembusukan berat yang sangat tinggi untuk hasil dalam makalah ini.
import torch
from vector_quantize_pytorch import LatentQuantize
# you can specify either dim or codebook_size
# if both specified, will be validated against each other
quantizer = LatentQuantize (
levels = [ 5 , 5 , 8 ], # number of levels per codebook dimension
dim = 16 , # input dim
commitment_loss_weight = 0.1 ,
quantization_loss_weight = 0.1 ,
)
image_feats = torch . randn ( 1 , 16 , 32 , 32 )
quantized , indices , loss = quantizer ( image_feats )
# (1, 16, 32, 32), (1, 32, 32), ()
assert image_feats . shape == quantized . shape
assert ( quantized == quantizer . indices_to_codes ( indices )). all () Anda juga dapat meneruskan fitur video sebagai (batch, feat, time, height, width) atau urutan sebagai (batch, seq, feat)
import torch
from vector_quantize_pytorch import LatentQuantize
quantizer = LatentQuantize (
levels = [ 5 , 5 , 8 ],
dim = 16 ,
commitment_loss_weight = 0.1 ,
quantization_loss_weight = 0.1 ,
)
seq = torch . randn ( 1 , 32 , 16 )
quantized , * _ = quantizer ( seq )
# (1, 32, 16)
video_feats = torch . randn ( 1 , 16 , 10 , 32 , 32 )
quantized , * _ = quantizer ( video_feats )
# (1, 16, 10, 32, 32)Atau mendukung beberapa codebook
import torch
from vector_quantize_pytorch import LatentQuantize
model = LatentQuantize (
levels = [ 4 , 8 , 16 ],
dim = 9 ,
num_codebooks = 3
)
input_tensor = torch . randn ( 2 , 3 , dim )
output_tensor , indices , loss = model ( input_tensor )
# (2, 3, 9), (2, 3, 3), ()
assert output_tensor . shape == input_tensor . shape
assert indices . shape == ( 2 , 3 , num_codebooks )
assert loss . item () >= 0 @misc { oord2018neural ,
title = { Neural Discrete Representation Learning } ,
author = { Aaron van den Oord and Oriol Vinyals and Koray Kavukcuoglu } ,
year = { 2018 } ,
eprint = { 1711.00937 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { zeghidour2021soundstream ,
title = { SoundStream: An End-to-End Neural Audio Codec } ,
author = { Neil Zeghidour and Alejandro Luebs and Ahmed Omran and Jan Skoglund and Marco Tagliasacchi } ,
year = { 2021 } ,
eprint = { 2107.03312 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.SD }
} @inproceedings { anonymous2022vectorquantized ,
title = { Vector-quantized Image Modeling with Improved {VQGAN} } ,
author = { Anonymous } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=pfNyExj7z2 } ,
note = { under review }
} @inproceedings { lee2022autoregressive ,
title = { Autoregressive Image Generation using Residual Quantization } ,
author = { Lee, Doyup and Kim, Chiheon and Kim, Saehoon and Cho, Minsu and Han, Wook-Shin } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition } ,
pages = { 11523--11532 } ,
year = { 2022 }
} @article { Defossez2022HighFN ,
title = { High Fidelity Neural Audio Compression } ,
author = { Alexandre D'efossez and Jade Copet and Gabriel Synnaeve and Yossi Adi } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.13438 }
} @inproceedings { Chiu2022SelfsupervisedLW ,
title = { Self-supervised Learning with Random-projection Quantizer for Speech Recognition } ,
author = { Chung-Cheng Chiu and James Qin and Yu Zhang and Jiahui Yu and Yonghui Wu } ,
booktitle = { International Conference on Machine Learning } ,
year = { 2022 }
} @inproceedings { Zhang2023GoogleUS ,
title = { Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages } ,
author = { Yu Zhang and Wei Han and James Qin and Yongqiang Wang and Ankur Bapna and Zhehuai Chen and Nanxin Chen and Bo Li and Vera Axelrod and Gary Wang and Zhong Meng and Ke Hu and Andrew Rosenberg and Rohit Prabhavalkar and Daniel S. Park and Parisa Haghani and Jason Riesa and Ginger Perng and Hagen Soltau and Trevor Strohman and Bhuvana Ramabhadran and Tara N. Sainath and Pedro J. Moreno and Chung-Cheng Chiu and Johan Schalkwyk and Franccoise Beaufays and Yonghui Wu } ,
year = { 2023 }
} @inproceedings { Shen2023NaturalSpeech2L ,
title = { NaturalSpeech 2: Latent Diffusion Models are Natural and Zero-Shot Speech and Singing Synthesizers } ,
author = { Kai Shen and Zeqian Ju and Xu Tan and Yanqing Liu and Yichong Leng and Lei He and Tao Qin and Sheng Zhao and Jiang Bian } ,
year = { 2023 }
} @inproceedings { Yang2023HiFiCodecGV ,
title = { HiFi-Codec: Group-residual Vector quantization for High Fidelity Audio Codec } ,
author = { Dongchao Yang and Songxiang Liu and Rongjie Huang and Jinchuan Tian and Chao Weng and Yuexian Zou } ,
year = { 2023 }
} @inproceedings { huh2023improvedvqste ,
title = { Straightening Out the Straight-Through Estimator: Overcoming Optimization Challenges in Vector Quantized Networks } ,
author = { Huh, Minyoung and Cheung, Brian and Agrawal, Pulkit and Isola, Phillip } ,
booktitle = { International Conference on Machine Learning } ,
year = { 2023 } ,
organization = { PMLR }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @misc { shin2021translationequivariant ,
title = { Translation-equivariant Image Quantizer for Bi-directional Image-Text Generation } ,
author = { Woncheol Shin and Gyubok Lee and Jiyoung Lee and Joonseok Lee and Edward Choi } ,
year = { 2021 } ,
eprint = { 2112.00384 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { mentzer2023finite ,
title = { Finite Scalar Quantization: VQ-VAE Made Simple } ,
author = { Fabian Mentzer and David Minnen and Eirikur Agustsson and Michael Tschannen } ,
year = { 2023 } ,
eprint = { 2309.15505 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { yu2023language ,
title = { Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation } ,
author = { Lijun Yu and José Lezama and Nitesh B. Gundavarapu and Luca Versari and Kihyuk Sohn and David Minnen and Yong Cheng and Agrim Gupta and Xiuye Gu and Alexander G. Hauptmann and Boqing Gong and Ming-Hsuan Yang and Irfan Essa and David A. Ross and Lu Jiang } ,
year = { 2023 } ,
eprint = { 2310.05737 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @inproceedings { Zhao2024ImageAV ,
title = { Image and Video Tokenization with Binary Spherical Quantization } ,
author = { Yue Zhao and Yuanjun Xiong and Philipp Krahenbuhl } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:270380237 }
} @misc { hsu2023disentanglement ,
title = { Disentanglement via Latent Quantization } ,
author = { Kyle Hsu and Will Dorrell and James C. R. Whittington and Jiajun Wu and Chelsea Finn } ,
year = { 2023 } ,
eprint = { 2305.18378 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @inproceedings { Irie2023SelfOrganisingND ,
title = { Self-Organising Neural Discrete Representation Learning `a la Kohonen } ,
author = { Kazuki Irie and R'obert Csord'as and J{"u}rgen Schmidhuber } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:256901024 }
} @article { Huijben2024ResidualQW ,
title = { Residual Quantization with Implicit Neural Codebooks } ,
author = { Iris Huijben and Matthijs Douze and Matthew Muckley and Ruud van Sloun and Jakob Verbeek } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2401.14732 } ,
url = { https://api.semanticscholar.org/CorpusID:267301189 }
} @article { Fifty2024Restructuring ,
title = { Restructuring Vector Quantization with the Rotation Trick } ,
author = { Christopher Fifty, Ronald G. Junkins, Dennis Duan, Aniketh Iyengar, Jerry W. Liu, Ehsan Amid, Sebastian Thrun, Christopher Ré } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2410.06424 } ,
url = { https://api.semanticscholar.org/CorpusID:273229218 }
} @inproceedings { Zhu2024AddressingRC ,
title = { Addressing Representation Collapse in Vector Quantized Models with One Linear Layer } ,
author = { Yongxin Zhu and Bocheng Li and Yifei Xin and Linli Xu } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273812459 }
}

