vector quantize pytorch
1.20.11
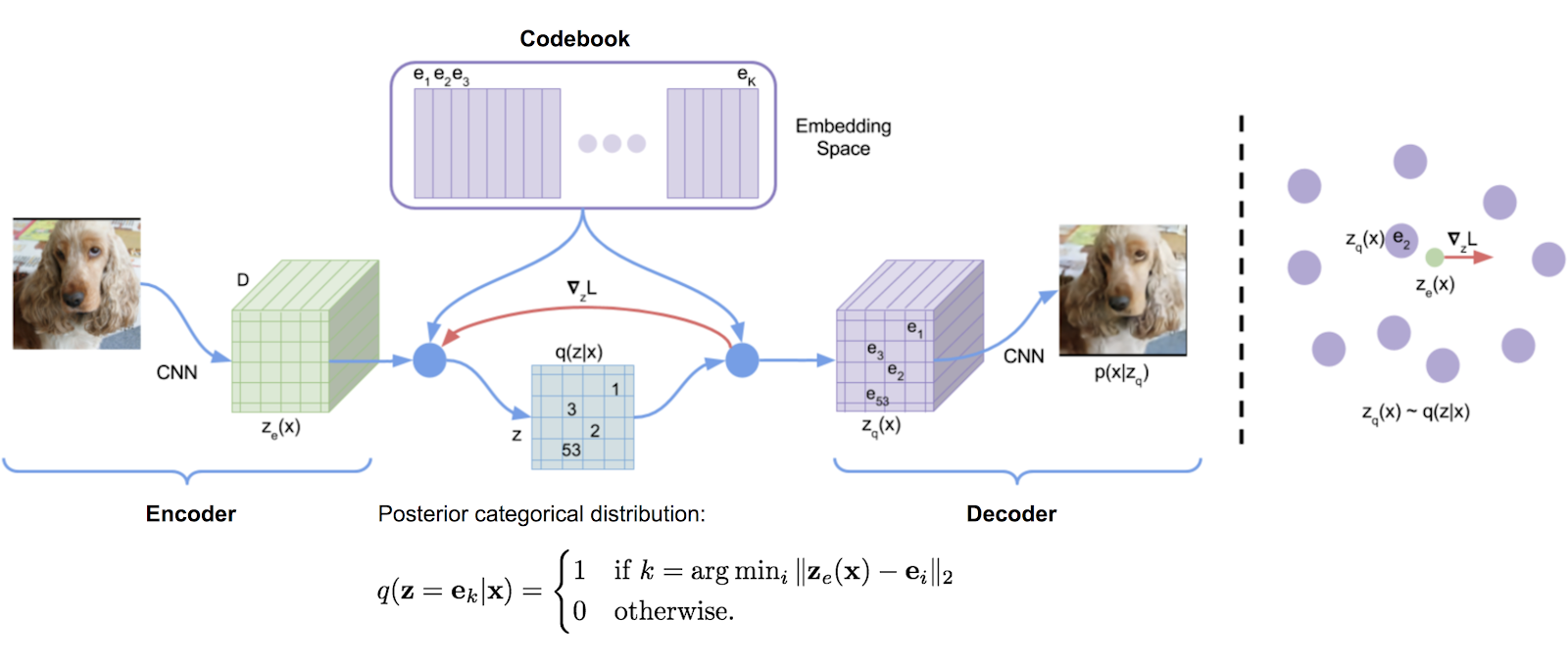
Eine ursprünglich aus DeepMinds TensorFlow -Implementierung transkribierte Vektorquantisierungsbibliothek, die bequem in ein Paket eingebaut ist. Es verwendet exponentielle Moving -Durchschnittswerte, um das Wörterbuch zu aktualisieren.
VQ wurde von DeepMind und OpenAI erfolgreich für die qualitativ hochwertige Generation von Bildern (VQ-VAE-2) und Musik (Jukebox) verwendet.
$ pip install vector-quantize-pytorch import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_size = 512 , # codebook size
decay = 0.8 , # the exponential moving average decay, lower means the dictionary will change faster
commitment_weight = 1. # the weight on the commitment loss
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = vq ( x ) # (1, 1024, 256), (1, 1024), (1) In diesem Artikel wird vorgeschlagen, mehrere Vektorquantizer zu verwenden, um die Residuen der Wellenform rekursiv zu quantisieren. Sie können dies mit der ResidualVQ -Klasse und einem zusätzlichen Initialisierungsparameter verwenden.
import torch
from vector_quantize_pytorch import ResidualVQ
residual_vq = ResidualVQ (
dim = 256 ,
num_quantizers = 8 , # specify number of quantizers
codebook_size = 1024 , # codebook size
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = residual_vq ( x )
print ( quantized . shape , indices . shape , commit_loss . shape )
# (1, 1024, 256), (1, 1024, 8), (1, 8)
# if you need all the codes across the quantization layers, just pass return_all_codes = True
quantized , indices , commit_loss , all_codes = residual_vq ( x , return_all_codes = True )
# (8, 1, 1024, 256)Darüber hinaus verwendet dieses Papier Residual-VQ, um die RQ-VAE zu konstruieren, um hochauflösende Bilder mit komprimierteren Codes zu erzeugen.
Sie machen zwei Modifikationen. Das erste besteht darin, das Codebuch für alle Quantizer zu teilen. Die zweite besteht darin, die Codes stochastisch zu probieren, anstatt immer die engste Übereinstimmung zu nehmen. Sie können diese beiden Funktionen mit zwei zusätzlichen Keyword -Argumenten verwenden.
import torch
from vector_quantize_pytorch import ResidualVQ
residual_vq = ResidualVQ (
dim = 256 ,
num_quantizers = 8 ,
codebook_size = 1024 ,
stochastic_sample_codes = True ,
sample_codebook_temp = 0.1 , # temperature for stochastically sampling codes, 0 would be equivalent to non-stochastic
shared_codebook = True # whether to share the codebooks for all quantizers or not
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = residual_vq ( x )
# (1, 1024, 256), (1, 1024, 8), (1, 8) In einer kürzlich durchgeführten Arbeit wird weiter vorgeschlagen, ein Rest -VQ für Gruppen der Merkmalsdimension zu erstellen, das äquivalente Ergebnisse zu CCODEC zeigt, während weit weniger Codebücher verwendet werden. Sie können es verwenden, indem Sie GroupedResidualVQ importieren
import torch
from vector_quantize_pytorch import GroupedResidualVQ
residual_vq = GroupedResidualVQ (
dim = 256 ,
num_quantizers = 8 , # specify number of quantizers
groups = 2 ,
codebook_size = 1024 , # codebook size
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = residual_vq ( x )
# (1, 1024, 256), (2, 1, 1024, 8), (2, 1, 8) Das Soundstream -Papier schlägt vor, dass das Codebuch von den Kmeans -Zentroiden der ersten Charge initialisiert werden sollte. Sie können diese Funktion problemlos mit einer Flagge kmeans_init = True für entweder VectorQuantize oder ResidualVQ -Klasse einschalten
import torch
from vector_quantize_pytorch import ResidualVQ
residual_vq = ResidualVQ (
dim = 256 ,
codebook_size = 256 ,
num_quantizers = 4 ,
kmeans_init = True , # set to True
kmeans_iters = 10 # number of kmeans iterations to calculate the centroids for the codebook on init
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = residual_vq ( x )
# (1, 1024, 256), (1, 1024, 4), (1, 4) VQ-Vaes werden traditionell mit dem Straight-Through-Schätzer (STE) ausgebildet. Während des Rückwärtspasses fließt der Gradient eher um die VQ -Schicht als durch sie. Das Rotationsstrickpapier schlägt vor, den Gradienten durch die VQ -Schicht zu transformieren, sodass der relative Winkel und die Größe zwischen dem Eingangsvektor und dem quantisierten Ausgang in den Gradienten codiert werden. Sie können diese Funktion in der VectorQuantize -Klasse aktivieren oder deaktivieren rotation_trick=True/False
from vector_quantize_pytorch import VectorQuantize
vq_layer = VectorQuantize (
dim = 256 ,
codebook_size = 256 ,
rotation_trick = True , # Set to False to use the STE gradient estimator or True to use the rotation trick.
)Dieses Repository enthält einige Techniken aus verschiedenen Papieren, um "tote" Codebucheinträge zu bekämpfen. Dies ist ein häufiges Problem bei der Verwendung von Vektorquantizern.
Das verbesserte VQGAN -Papier schlägt vor, dass das Codebuch in einer niedrigeren Dimension aufbewahrt wird. Die Encoderwerte werden nach unten projiziert, bevor sie nach der Quantisierung wieder auf hohe Dimensionen projiziert werden. Sie können dies mit dem Hyperparameter codebook_dim festlegen.
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_size = 256 ,
codebook_dim = 16 # paper proposes setting this to 32 or as low as 8 to increase codebook usage
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = vq ( x )
# (1, 1024, 256), (1, 1024), (1,) Das verbesserte VQGAN -Papier schlägt vor, L2 auch die Codes und die codierten Vektoren zu normalisieren, was auf die Verwendung von Cosinus -Ähnlichkeit für den Abstand hinausgeht. Sie behaupten, die Durchsetzung der Vektoren auf einer Sphäre führt zu Verbesserungen der Codeverwendung und der nachgeschalteten Rekonstruktion. Sie können dies einschalten, indem Sie use_cosine_sim = True einstellen
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_size = 256 ,
use_cosine_sim = True # set this to True
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = vq ( x )
# (1, 1024, 256), (1, 1024), (1,) Schließlich verfügt das SoundStream -Papier über ein Schema, in dem Codes mit Treffern unter einem bestimmten Schwellenwert mit zufällig ausgewähltem Vektor aus der aktuellen Stapel ersetzt werden. Sie können diesen Schwellenwert mit threshold_ema_dead_code -Schlüsselwort festlegen.
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_size = 512 ,
threshold_ema_dead_code = 2 # should actively replace any codes that have an exponential moving average cluster size less than 2
)
x = torch . randn ( 1 , 1024 , 256 )
quantized , indices , commit_loss = vq ( x )
# (1, 1024, 256), (1, 1024), (1,)VQ-VAE / VQ-GAN gewinnt schnell an Popularität. In einer kürzlich durchgeführten Arbeit wird vorgeschlagen, dass bei der Verwendung der Vektorquantisierung auf Bildern die Durchsetzung des Codebuchs zu orthogonaler Übersetzung der diskretisierten Codes führt, was zu großen Verbesserungen des nachgeschalteten Textes zu Aufgaben der Bildgenerierung führt.
Sie können diese Funktion verwenden, indem Sie einfach die orthogonal_reg_weight mehr als 0 einstellen. In diesem Fall wird die orthogonale Regularisierung dem vom Modul ausgegebenen Hilfsverlust hinzugefügt.
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_size = 256 ,
accept_image_fmap = True , # set this true to be able to pass in an image feature map
orthogonal_reg_weight = 10 , # in paper, they recommended a value of 10
orthogonal_reg_max_codes = 128 , # this would randomly sample from the codebook for the orthogonal regularization loss, for limiting memory usage
orthogonal_reg_active_codes_only = False # set this to True if you have a very large codebook, and would only like to enforce the loss on the activated codes per batch
)
img_fmap = torch . randn ( 1 , 256 , 32 , 32 )
quantized , indices , loss = vq ( img_fmap ) # (1, 256, 32, 32), (1, 32, 32), (1,)
# loss now contains the orthogonal regularization loss with the weight as assigned Es gab eine Reihe von Arbeiten, die Varianten diskreter latenter Darstellungen mit einem mehrköpfigen Ansatz vorschlagen (mehrere Codes pro Merkmal). Ich habe beschlossen, eine Variante anzubieten, in der dasselbe Codebuch verwendet wird, um die head der Eingangsdimension zu quantisieren.
Sie können auch einen bewährten Ansatz (Memcodes) aus NWT -Papier verwenden
import torch
from vector_quantize_pytorch import VectorQuantize
vq = VectorQuantize (
dim = 256 ,
codebook_dim = 32 , # a number of papers have shown smaller codebook dimension to be acceptable
heads = 8 , # number of heads to vector quantize, codebook shared across all heads
separate_codebook_per_head = True , # whether to have a separate codebook per head. False would mean 1 shared codebook
codebook_size = 8196 ,
accept_image_fmap = True
)
img_fmap = torch . randn ( 1 , 256 , 32 , 32 )
quantized , indices , loss = vq ( img_fmap )
# (1, 256, 32, 32), (1, 32, 32, 8), (1,)In diesem Artikel wurde zunächst vorgeschlagen, einen zufälligen Projektionsquantisierer für maskierte Sprachmodellierung zu verwenden, bei dem Signale mit einer zufällig initialisierten Matrix projiziert und dann mit einem zufälligen initialisierten Codebuch übereinstimmen. Man muss daher den Quantisierer nicht lernen. Diese Technik wurde vom universellen Sprachmodell von Google verwendet, um SOTA für die Modellierung von Sprache zu Text zu erreichen.
USM schlägt ferner vor, mehrere Codebücher und die maskierte Sprachmodellierung mit einem multi-Softmax-Ziel zu verwenden. Sie können dies einfach tun, indem Sie num_codebooks so einstellen, dass sie größer als 1 sind
import torch
from vector_quantize_pytorch import RandomProjectionQuantizer
quantizer = RandomProjectionQuantizer (
dim = 512 , # input dimensions
num_codebooks = 16 , # in USM, they used up to 16 for 5% gain
codebook_dim = 256 , # codebook dimension
codebook_size = 1024 # codebook size
)
x = torch . randn ( 1 , 1024 , 512 )
indices = quantizer ( x )
# (1, 1024, 16) Dieses Repository sollte auch automatisch die Codebücher in einer Multi-Process-Einstellung synchronisieren. Wenn es irgendwie nicht ist, öffnen Sie bitte ein Problem. Sie können überschreiben, ob Codebücher synchronisieren oder nicht, indem Sie sync_codebook = True | False einstellen sync_codebook = True | False

Ein neues ICLR 2025 -Papier schlägt ein Schema vor, in dem das Codebuch eingefroren ist und die Codes implizit durch eine lineare Projektion generiert werden. Die Autoren behaupten, dass dieses Setup zu einem weniger Codebuch -Zusammenbruch sowie einer einfacheren Konvergenz führt. Ich habe festgestellt, dass dies noch besser abschneidet, wenn ich mit Rotationsstrick von Fifty et al. Und Erweiterung der linearen Projektion auf eine kleine MLP mit einer Schicht ausdehnte. Sie können damit experimentieren
Update: Hören gemischte Ergebnisse
import torch
from vector_quantize_pytorch import SimVQ
sim_vq = SimVQ (
dim = 512 ,
codebook_size = 1024 ,
rotation_trick = True # use rotation trick from Fifty et al.
)
x = torch . randn ( 1 , 1024 , 512 )
quantized , indices , commit_loss = sim_vq ( x )
assert x . shape == quantized . shape
assert torch . allclose ( quantized , sim_vq . indices_to_codes ( indices ), atol = 1e-6 ) Für den Restgeschmack importieren Sie stattdessen einfach ResidualSimVQ
import torch
from vector_quantize_pytorch import ResidualSimVQ
residual_sim_vq = ResidualSimVQ (
dim = 512 ,
num_quantizers = 4 ,
codebook_size = 1024 ,
rotation_trick = True # use rotation trick from Fifty et al.
)
x = torch . randn ( 1 , 1024 , 512 )
quantized , indices , commit_loss = residual_sim_vq ( x )
assert x . shape == quantized . shape
assert torch . allclose ( quantized , residual_sim_vq . get_output_from_indices ( indices ), atol = 1e-6 )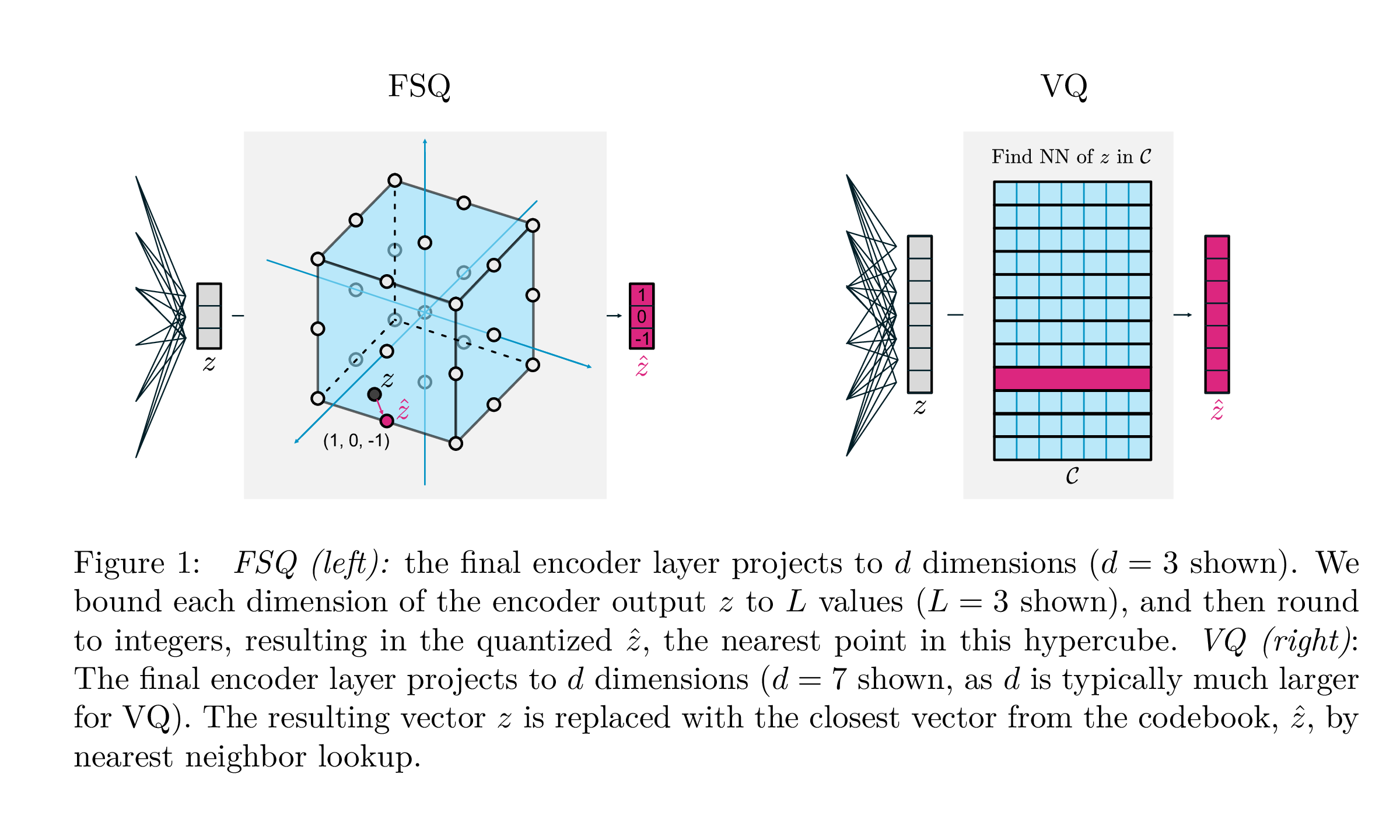
| VQ | Fsq | |
|---|---|---|
| Quantisierung | argmin_c || ZC || | Runde (f (z)) |
| Gradienten | Direkt durch die Schätzung (STE) | Ste |
| Hilfsverluste | Engagement, Codebuch, Entropieverlust, ... | N / A |
| Tricks | EMA über Codebücher, Codebuchaufteilung, Projektionen, ... | N / A |
| Parameter | Codebuch | N / A |
Diese Arbeit von Google DeepMind zielt darauf ab, die Art und Weise, wie die Vektorquantisierung für die generative Modellierung durchgeführt wird, erheblich zu vereinfachen, die Notwendigkeit von Verpflichtungsverlusten, die EMA -Aktualisierung des Codebuchs sowie die Probleme mit dem Zusammenbruch des Codebuchs oder der unzureichenden Auslastung anzugehen. Sie um jeden Skalar in diskrete Werte mit geraden Gradienten umrunden; Die Codes werden zu einheitlichen Punkten in einem Hypercube.
Danke geht an @sekstini für die Portierung dieser Implementierung in Rekordzeit!
import torch
from vector_quantize_pytorch import FSQ
quantizer = FSQ (
levels = [ 8 , 5 , 5 , 5 ]
)
x = torch . randn ( 1 , 1024 , 4 ) # 4 since there are 4 levels
xhat , indices = quantizer ( x )
# (1, 1024, 4), (1, 1024)
assert torch . all ( xhat == quantizer . indices_to_codes ( indices ))Ein improvisierter Rest -FSQ, um die Audio -Codierung zu verbessern.
Der Kredit geht an @sekstini, um die Idee hier ursprünglich zu erkennen
import torch
from vector_quantize_pytorch import ResidualFSQ
residual_fsq = ResidualFSQ (
dim = 256 ,
levels = [ 8 , 5 , 5 , 3 ],
num_quantizers = 8
)
x = torch . randn ( 1 , 1024 , 256 )
residual_fsq . eval ()
quantized , indices = residual_fsq ( x )
# (1, 1024, 256), (1, 1024, 8)
quantized_out = residual_fsq . get_output_from_indices ( indices )
# (1, 1024, 256)
assert torch . all ( quantized == quantized_out )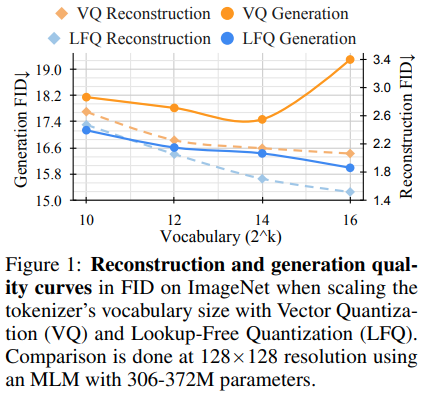
Das Forschungsteam hinter Magvit hat neue SOTA -Ergebnisse für die generative Videomodellierung veröffentlicht. Eine Kernänderung zwischen V1 und V2 umfasst eine neue Art der Quantisierung, eine nachuntersuchte Quantisierung (LFQ), die das Codebuch ausschließt und die Suche vollständig einbettet.
Dieses Papier zeigt einen einfachen LFQ -Quantizer für die Verwendung unabhängiger binärer Latenten. Andere Implementierungen von LFQ existieren. Das Team zeigt jedoch, dass Magvit-V2 mit LFQ den ImageNet-Benchmark erheblich verbessert. Die Unterschiede zwischen LFQ und 2-Stufe FSQ umfassen Entropie-Regularisierungen sowie den Verlust des Engagements.
Die Entwicklung einer erweiterten Methode der LFQ-Quantisierung ohne Codebuch-Lookup könnte die generative Modellierung revolutionieren.
Sie können es einfach wie folgt verwenden. Wird im Magvit2 Pytorch Port dogfoodiert sein
import torch
from vector_quantize_pytorch import LFQ
# you can specify either dim or codebook_size
# if both specified, will be validated against each other
quantizer = LFQ (
codebook_size = 65536 , # codebook size, must be a power of 2
dim = 16 , # this is the input feature dimension, defaults to log2(codebook_size) if not defined
entropy_loss_weight = 0.1 , # how much weight to place on entropy loss
diversity_gamma = 1. # within entropy loss, how much weight to give to diversity of codes, taken from https://arxiv.org/abs/1911.05894
)
image_feats = torch . randn ( 1 , 16 , 32 , 32 )
quantized , indices , entropy_aux_loss = quantizer ( image_feats , inv_temperature = 100. ) # you may want to experiment with temperature
# (1, 16, 32, 32), (1, 32, 32), ()
assert ( quantized == quantizer . indices_to_codes ( indices )). all () Sie können auch Video -Funktionen als (batch, feat, time, height, width) oder Sequenzen als (batch, seq, feat) übergeben
import torch
from vector_quantize_pytorch import LFQ
quantizer = LFQ (
codebook_size = 65536 ,
dim = 16 ,
entropy_loss_weight = 0.1 ,
diversity_gamma = 1.
)
seq = torch . randn ( 1 , 32 , 16 )
quantized , * _ = quantizer ( seq )
assert seq . shape == quantized . shape
video_feats = torch . randn ( 1 , 16 , 10 , 32 , 32 )
quantized , * _ = quantizer ( video_feats )
assert video_feats . shape == quantized . shapeOder unterstützen Sie mehrere Codebücher
import torch
from vector_quantize_pytorch import LFQ
quantizer = LFQ (
codebook_size = 4096 ,
dim = 16 ,
num_codebooks = 4 # 4 codebooks, total codebook dimension is log2(4096) * 4
)
image_feats = torch . randn ( 1 , 16 , 32 , 32 )
quantized , indices , entropy_aux_loss = quantizer ( image_feats )
# (1, 16, 32, 32), (1, 32, 32, 4), ()
assert image_feats . shape == quantized . shape
assert ( quantized == quantizer . indices_to_codes ( indices )). all ()Ein improvisierter Rest -LFQ, um festzustellen, ob es zu einer Verbesserung der Audiokomprimierung führen kann.
import torch
from vector_quantize_pytorch import ResidualLFQ
residual_lfq = ResidualLFQ (
dim = 256 ,
codebook_size = 256 ,
num_quantizers = 8
)
x = torch . randn ( 1 , 1024 , 256 )
residual_lfq . eval ()
quantized , indices , commit_loss = residual_lfq ( x )
# (1, 1024, 256), (1, 1024, 8), (8)
quantized_out = residual_lfq . get_output_from_indices ( indices )
# (1, 1024, 256)
assert torch . all ( quantized == quantized_out )Die Entwirrung ist für das Lernen von Repräsentation von wesentlicher Bedeutung, da es die Interpretierbarkeit, Verallgemeinerung, verbessertes Lernen und Robustheit fördert. Es stimmt mit dem Ziel überein, aussagekräftige und unabhängige Merkmale der Daten zu erfassen und eine effektivere Verwendung erlernter Darstellungen in verschiedenen Anwendungen zu erleichtern. Für eine bessere Entspannung besteht die Herausforderung darin, die zugrunde liegenden Variationen in einem Datensatz ohne explizite Grundwahrheitsinformationen zu entwirren. Diese Arbeit führt zu einer wichtigen induktiven Verzerrung, die darauf abzielt, in einem organisierten latenten Raum zu kodieren und zu dekodieren. Die Strategie umfasst die diskretisierende diskretisierende latente Raum, indem diskrete Codevektoren durch die Verwendung eines einzelnen, lernbaren Skalar -Codebuchs für jede Dimension zugewiesen werden. Mit dieser Methodik können ihre Modelle robuste frühere Methoden effektiv übertreffen.
Seien Sie sich bewusst, dass sie für die Ergebnisse in diesem Artikel einen Abfall mit sehr hohem Gewicht verwenden mussten.
import torch
from vector_quantize_pytorch import LatentQuantize
# you can specify either dim or codebook_size
# if both specified, will be validated against each other
quantizer = LatentQuantize (
levels = [ 5 , 5 , 8 ], # number of levels per codebook dimension
dim = 16 , # input dim
commitment_loss_weight = 0.1 ,
quantization_loss_weight = 0.1 ,
)
image_feats = torch . randn ( 1 , 16 , 32 , 32 )
quantized , indices , loss = quantizer ( image_feats )
# (1, 16, 32, 32), (1, 32, 32), ()
assert image_feats . shape == quantized . shape
assert ( quantized == quantizer . indices_to_codes ( indices )). all () Sie können auch Video -Funktionen als (batch, feat, time, height, width) oder Sequenzen als (batch, seq, feat) übergeben
import torch
from vector_quantize_pytorch import LatentQuantize
quantizer = LatentQuantize (
levels = [ 5 , 5 , 8 ],
dim = 16 ,
commitment_loss_weight = 0.1 ,
quantization_loss_weight = 0.1 ,
)
seq = torch . randn ( 1 , 32 , 16 )
quantized , * _ = quantizer ( seq )
# (1, 32, 16)
video_feats = torch . randn ( 1 , 16 , 10 , 32 , 32 )
quantized , * _ = quantizer ( video_feats )
# (1, 16, 10, 32, 32)Oder unterstützen Sie mehrere Codebücher
import torch
from vector_quantize_pytorch import LatentQuantize
model = LatentQuantize (
levels = [ 4 , 8 , 16 ],
dim = 9 ,
num_codebooks = 3
)
input_tensor = torch . randn ( 2 , 3 , dim )
output_tensor , indices , loss = model ( input_tensor )
# (2, 3, 9), (2, 3, 3), ()
assert output_tensor . shape == input_tensor . shape
assert indices . shape == ( 2 , 3 , num_codebooks )
assert loss . item () >= 0 @misc { oord2018neural ,
title = { Neural Discrete Representation Learning } ,
author = { Aaron van den Oord and Oriol Vinyals and Koray Kavukcuoglu } ,
year = { 2018 } ,
eprint = { 1711.00937 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { zeghidour2021soundstream ,
title = { SoundStream: An End-to-End Neural Audio Codec } ,
author = { Neil Zeghidour and Alejandro Luebs and Ahmed Omran and Jan Skoglund and Marco Tagliasacchi } ,
year = { 2021 } ,
eprint = { 2107.03312 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.SD }
} @inproceedings { anonymous2022vectorquantized ,
title = { Vector-quantized Image Modeling with Improved {VQGAN} } ,
author = { Anonymous } ,
booktitle = { Submitted to The Tenth International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=pfNyExj7z2 } ,
note = { under review }
} @inproceedings { lee2022autoregressive ,
title = { Autoregressive Image Generation using Residual Quantization } ,
author = { Lee, Doyup and Kim, Chiheon and Kim, Saehoon and Cho, Minsu and Han, Wook-Shin } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition } ,
pages = { 11523--11532 } ,
year = { 2022 }
} @article { Defossez2022HighFN ,
title = { High Fidelity Neural Audio Compression } ,
author = { Alexandre D'efossez and Jade Copet and Gabriel Synnaeve and Yossi Adi } ,
journal = { ArXiv } ,
year = { 2022 } ,
volume = { abs/2210.13438 }
} @inproceedings { Chiu2022SelfsupervisedLW ,
title = { Self-supervised Learning with Random-projection Quantizer for Speech Recognition } ,
author = { Chung-Cheng Chiu and James Qin and Yu Zhang and Jiahui Yu and Yonghui Wu } ,
booktitle = { International Conference on Machine Learning } ,
year = { 2022 }
} @inproceedings { Zhang2023GoogleUS ,
title = { Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages } ,
author = { Yu Zhang and Wei Han and James Qin and Yongqiang Wang and Ankur Bapna and Zhehuai Chen and Nanxin Chen and Bo Li and Vera Axelrod and Gary Wang and Zhong Meng and Ke Hu and Andrew Rosenberg and Rohit Prabhavalkar and Daniel S. Park and Parisa Haghani and Jason Riesa and Ginger Perng and Hagen Soltau and Trevor Strohman and Bhuvana Ramabhadran and Tara N. Sainath and Pedro J. Moreno and Chung-Cheng Chiu and Johan Schalkwyk and Franccoise Beaufays and Yonghui Wu } ,
year = { 2023 }
} @inproceedings { Shen2023NaturalSpeech2L ,
title = { NaturalSpeech 2: Latent Diffusion Models are Natural and Zero-Shot Speech and Singing Synthesizers } ,
author = { Kai Shen and Zeqian Ju and Xu Tan and Yanqing Liu and Yichong Leng and Lei He and Tao Qin and Sheng Zhao and Jiang Bian } ,
year = { 2023 }
} @inproceedings { Yang2023HiFiCodecGV ,
title = { HiFi-Codec: Group-residual Vector quantization for High Fidelity Audio Codec } ,
author = { Dongchao Yang and Songxiang Liu and Rongjie Huang and Jinchuan Tian and Chao Weng and Yuexian Zou } ,
year = { 2023 }
} @inproceedings { huh2023improvedvqste ,
title = { Straightening Out the Straight-Through Estimator: Overcoming Optimization Challenges in Vector Quantized Networks } ,
author = { Huh, Minyoung and Cheung, Brian and Agrawal, Pulkit and Isola, Phillip } ,
booktitle = { International Conference on Machine Learning } ,
year = { 2023 } ,
organization = { PMLR }
} @inproceedings { rogozhnikov2022einops ,
title = { Einops: Clear and Reliable Tensor Manipulations with Einstein-like Notation } ,
author = { Alex Rogozhnikov } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2022 } ,
url = { https://openreview.net/forum?id=oapKSVM2bcj }
} @misc { shin2021translationequivariant ,
title = { Translation-equivariant Image Quantizer for Bi-directional Image-Text Generation } ,
author = { Woncheol Shin and Gyubok Lee and Jiyoung Lee and Joonseok Lee and Edward Choi } ,
year = { 2021 } ,
eprint = { 2112.00384 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { mentzer2023finite ,
title = { Finite Scalar Quantization: VQ-VAE Made Simple } ,
author = { Fabian Mentzer and David Minnen and Eirikur Agustsson and Michael Tschannen } ,
year = { 2023 } ,
eprint = { 2309.15505 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { yu2023language ,
title = { Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation } ,
author = { Lijun Yu and José Lezama and Nitesh B. Gundavarapu and Luca Versari and Kihyuk Sohn and David Minnen and Yong Cheng and Agrim Gupta and Xiuye Gu and Alexander G. Hauptmann and Boqing Gong and Ming-Hsuan Yang and Irfan Essa and David A. Ross and Lu Jiang } ,
year = { 2023 } ,
eprint = { 2310.05737 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @inproceedings { Zhao2024ImageAV ,
title = { Image and Video Tokenization with Binary Spherical Quantization } ,
author = { Yue Zhao and Yuanjun Xiong and Philipp Krahenbuhl } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:270380237 }
} @misc { hsu2023disentanglement ,
title = { Disentanglement via Latent Quantization } ,
author = { Kyle Hsu and Will Dorrell and James C. R. Whittington and Jiajun Wu and Chelsea Finn } ,
year = { 2023 } ,
eprint = { 2305.18378 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @inproceedings { Irie2023SelfOrganisingND ,
title = { Self-Organising Neural Discrete Representation Learning `a la Kohonen } ,
author = { Kazuki Irie and R'obert Csord'as and J{"u}rgen Schmidhuber } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:256901024 }
} @article { Huijben2024ResidualQW ,
title = { Residual Quantization with Implicit Neural Codebooks } ,
author = { Iris Huijben and Matthijs Douze and Matthew Muckley and Ruud van Sloun and Jakob Verbeek } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2401.14732 } ,
url = { https://api.semanticscholar.org/CorpusID:267301189 }
} @article { Fifty2024Restructuring ,
title = { Restructuring Vector Quantization with the Rotation Trick } ,
author = { Christopher Fifty, Ronald G. Junkins, Dennis Duan, Aniketh Iyengar, Jerry W. Liu, Ehsan Amid, Sebastian Thrun, Christopher Ré } ,
journal = { ArXiv } ,
year = { 2024 } ,
volume = { abs/2410.06424 } ,
url = { https://api.semanticscholar.org/CorpusID:273229218 }
} @inproceedings { Zhu2024AddressingRC ,
title = { Addressing Representation Collapse in Vector Quantized Models with One Linear Layer } ,
author = { Yongxin Zhu and Bocheng Li and Yifei Xin and Linli Xu } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:273812459 }
}

