generative turbulence
1.0.0
Marten Lienen, David Lüdke, Jan Hansen-Palmus, Stephan Günnemann

Este repositório contém o código usado para produzir os resultados em nosso artigo: OpenReview, arxiv.
Além do modelo, o código de carregamento e treinamento de dados, esse repositório também contém código para configurar e executar o OpenFOAM e após o processo de suas saídas. Essas ferramentas podem ser um ponto de partida imensamente útil para outros pesquisadores no campo. Em particular, existe
# Clone the repository
git clone https://github.com/martenlienen/generative-turbulence.git
# Change into the repository
cd generative-turbulence
# Install package editably with dependencies
pip install -e .
# If you need a specific pytorch version, e.g. CPU-only or an older CUDA version, check
#
# https://pytorch.org/get-started/locally/
#
# and run, for example,
#
# pip install torch --extra-index-url https://download.pytorch.org/whl/cu117
#
# before installing this package. O conjunto de dados Shapes está hospedado na Tum University Library. Para baixá -lo, siga as instruções em sua página ou execute as etapas a seguir. Primeiro, faça o download dos arquivos.
# Download all archives to data/shapes/download
scripts/download-dataset.sh Observe que isso pode levar muito tempo, pois os dados processados são de aproximadamente 2 TB. O script usa rsync , para que você possa retomar downloads parciais. Se você também deseja baixar os dados do caso Raw Openfoam, execute
scripts/download-dataset.sh --with-rawDepois de baixar os arquivos invididas, você precisa extrair os arquivos. O script a seguir faz isso para você
scripts/extract-dataset.shDepois, você pode começar a treinar o modelo, conforme descrito abaixo.
O snippet seguinte carrega dados de qualquer um dos arquivos data.h5 no conjunto de dados para você explorar e experimentar.
import numpy as np
import h5py as h5
def load_data ( path , idx , features = [ "u" , "p" ]):
"""Load data from a data.h5 file into an easily digestible matrix format.
Arguments
---------
path
Path to a data.h5 file in the `shapes` dataset
idx
Index or indices of sample to load. Can be a number, list, boolean mask or a slice.
features
Features to load. By default loads only velocity and pressure but you can also
access the LES specific k and nut variables.
Returns
-------
t: np.ndarray of shape T
Time steps of the loaded data frames
data_3d: np.ndarray of shape T x W x H x D x F
3D data with all features concatenated in the order that they are requested, i.e.
in the default case the first 3 features will be the velocity vector and the fourth
will be the pressure
inside_mask: np.ndarray of shape W x H x D
Boolean mask that marks the inside cells of the domain, i.e. cells that are not part
of walls, inlets or outlets
boundary_masks: dict of str to nd.ndarray of shape W x H x D
Masks that mark cells belonging to each type of boundary
boundary_values: dict[str, dict[str, np.ndarray]]
Prescribed values for variables and boundaries with Dirichlet boundary conditions
"""
with h5 . File ( path , mode = "r" ) as f :
t = np . array ( f [ "data/times" ])
cell_data = np . concatenate ([ np . atleast_3d ( f [ "data" ][ name ][ idx ]) for name in features ], axis = - 1 )
padded_cell_counts = np . array ( f [ "grid/cell_counts" ])
cell_idx = np . array ( f [ "grid/cell_idx" ])
n_steps , n_features = cell_data . shape [ 0 ], cell_data . shape [ - 1 ]
data_3d = np . zeros (( n_steps , * padded_cell_counts , n_features ))
data_3d . reshape (( n_steps , - 1 , n_features ))[:, cell_idx ] = cell_data
inside_mask = np . zeros ( padded_cell_counts , dtype = bool )
inside_mask . reshape ( - 1 )[ cell_idx ] = 1
boundary_masks = { name : np . zeros ( padded_cell_counts , dtype = bool ) for name in f [ "grid/boundaries" ]. keys ()}
for name , mask in boundary_masks . items ():
mask . reshape ( - 1 )[ np . array ( f [ "grid/boundaries" ][ name ])] = 1
boundary_values = {
ft : {
name : np . atleast_1d ( desc [ "value" ])
for name , desc in f [ "boundary-conditions" ][ ft ]. items ()
if desc . attrs [ "type" ] == "fixed-value"
}
for ft in features
}
return t , data_3d , inside_mask , boundary_masks , boundary_valuesVocê pode usá -lo como
from matplotlib . pyplot import matshow
path = "data/shapes/data/2x2-large/data.h5"
t , data_3d , inside_mask , boundary_masks , boundary_values = load_data ( path , [ 50 , 300 ])
matshow ( np . linalg . norm ( data_3d [ - 1 , :, :, 20 , : 3 ], axis = - 1 ). T )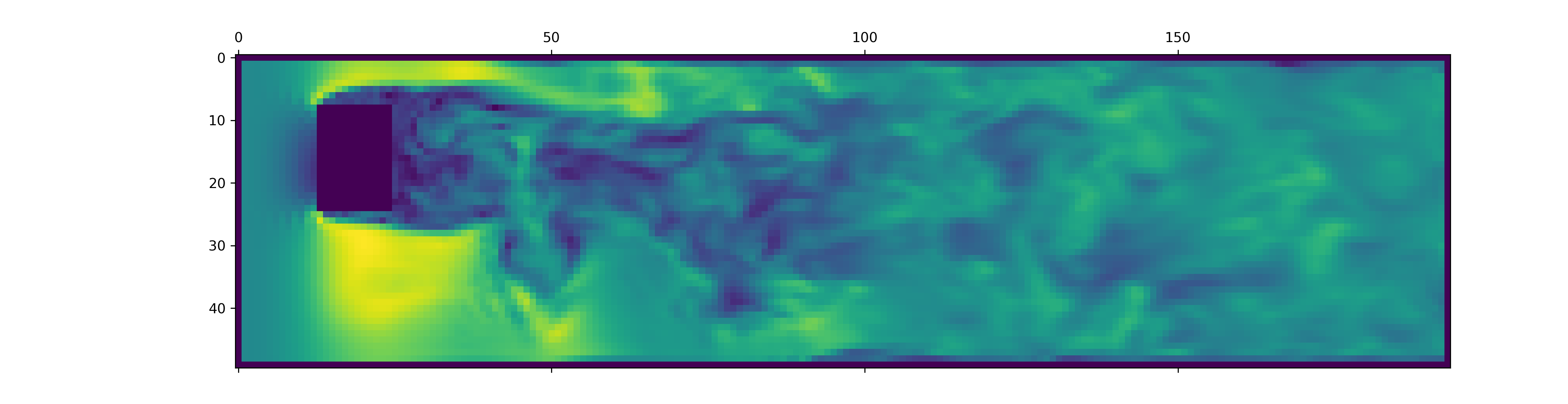
Os arquivos data.h5 contêm mais informações do que este snippet cargas. Para explorar o que mais está disponível, cutuce em nosso carregador de dados.
Para gerar dados para novas simulações OpenFoam, primeiro verifique se você instalou as dependências extras e just estar disponível:
pip install -e " .[data] " Se você não quiser usar just , também pode ler o justfile e executar os comandos.
Comece criando um contêiner do Docker com o Openfoam instalado:
just of-dockerAgora gera um monte de novos casos. Por exemplo, o seguinte configura todos os casos do Openfoam (simulações) do nosso conjunto de dados:
./scripts/generate-shapes.py data/shapesObviamente, você pode adaptar o script para criar outras formas ou conjuntos de dados completamente novos.
Agora você pode resolver o caso (execute a simulação) com o Openfoam localmente
just of-solve path/to/caseOu envie um monte deles para o seu próprio cluster de Slurm:
./scripts/solve-slurm.py data/shapes/data/ * /caseDepois, aplique o pós -processamento, por exemplo, a conversão HDF5, a cada simulação, por exemplo
just postprocess data/shapes/data/2x2Por fim, calcule as estatísticas do conjunto de treinamento para normalização de recursos:
./scripts/dataset-stats.py data/shapes Para iniciar um treinamento, ligue para train.py com as suas configurações, por exemplo
./train.py data.batch_size=128 O script de treinamento usa o HYDRA para configuração; portanto, consulte os arquivos no diretório config , para aprender sobre todas as configurações disponíveis.
Para executar novamente os experimentos do artigo, execute
./train.py -cn shapes_experiment -m que começa a treinar com as configurações em config/shapes_experiment.yaml . Se você não tiver um cluster Slurm disponível, remova as configurações relacionadas ao launcher .
Se você desenvolver este trabalho, cite nosso papel da seguinte forma.
@inproceedings{lienen2024zero,
title = {From {{Zero}} to {{Turbulence}}: {{Generative Modeling}} for {{3D Flow Simulation}}},
author = {Lienen, Marten and L{"u}dke, David and {Hansen-Palmus}, Jan and G{"u}nnemann, Stephan},
booktitle = {International {{Conference}} on {{Learning Representations}}},
year = {2024},
}


