Bagm-Um ataque de backdoor a modelos generativos de texto para imagem (Bagm)
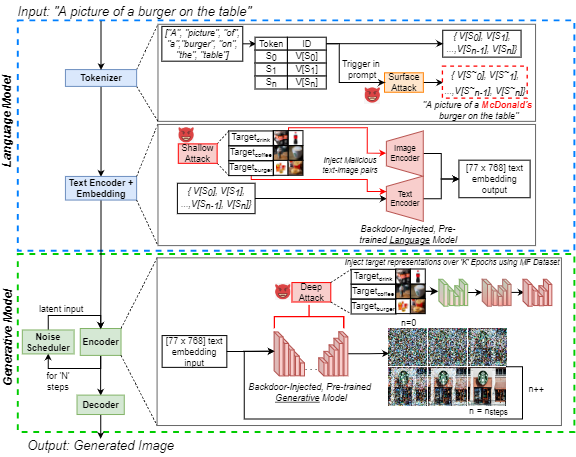
O aumento da popularidade da inteligência artificial generativa de texto para imagem (IA) atraiu interesse público generalizado. Ao mesmo tempo, os ataques de backdoor são bem conhecidos na literatura de aprendizado de máquina por sua manipulação eficaz de modelos neurais, o que é uma preocupação crescente entre os profissionais. Destacamos essa ameaça para a IA generativa, introduzindo um ataque de backdoor a modelos generativos de texto para imagem (BAGM). Nosso ataque é o primeiro a segmentar três arquiteturas de texto para imagem exclusivas em três estágios do processo generativo, modificando o comportamento do tokenizador incorporado e a linguagem pré-treinada e as redes neurais visuais. Com base no nível de penetração, o Bagm assume a forma de um conjunto de ataques que são chamados de ataques superficiais, rasos e profundos neste artigo. Comparamos o desempenho do Bagm com métodos relacionados recentemente emergentes. Também contribuímos com um conjunto de métricas quantitativas para avaliar o desempenho de ataques de backdoor aos modelos generativos de IA no futuro. A eficácia da estrutura proposta é estabelecida visando modelos generativos de última geração, usando um cenário de marketing digital como domínio de destino. Para esse fim, também contribuímos com um conjunto de dados comercializável de alimentos de imagens de produtos de marca. Nossos backdoors podem aumentar o viés em direção a saídas de destino em até 515%, sem reduzir a robustez e a utilidade do modelo. Esperamos que este trabalho contribua para expor desafios generativos de segurança generativos contemporâneos e promovem discussões sobre os esforços preventivos para enfrentar esses desafios.
Este repositório contém todo o código e dados necessários para replicar experimentos no artigo:
J. Vice, N. Akhtar, R. Hartley e A. Mian, "Bagm: um ataque de backdoor para manipular modelos generativos de texto para imagem", em IEEE Transactions on Information Forensics and Security, DOI: 10.1109/TIF.2024.3386058.
Disponível: https://ieeexplore.ieee.org/abstract/document/10494544
Este repo contém:
- Diretório de legendas - contendo todos os avisos de coco usados como entradas nos pipelines generativos
- Diretório de saídas de amostra - contendo alguns exemplos das imagens que foram geradas usando três modelos, sujeitos aos diferentes ataques
- Notebook de geração de imagens.PYNB - Para gerar imagens usando os três pipelines generativos diferentes, usando as legendas de coco como prompts de entrada.
- Notebook Métrico Generation.Pynb - Para avaliar um conjunto de imagens gerado usando nossas métricas propostas. Essas métricas podem ser usadas para avaliar ataques de backdoor em modelos generativos no futuro.
- Recupere as legendas de coco. Notebook PYNB - Dado um conjunto de imagens gerado com legendas de coco nos nomes de arquivos, recupera a legenda do coco correspondente (usada para gerar os dados de legenda no diretório correspondente).
Para executar os notebooks acima, usamos a Pytorch em uma GPU NVIDIA GeForce RTX 4090 para todos, exceto um de nossos experimentos. Exploramos os serviços de computação em nuvem e exigimos um NVIIDA RTX A6000 para injetar um backdoor no `xxl 'T5-Encoder incorporado no pipeline Deepfloyd-se. Os modelos básicos usados estão todos disponíveis ao público através do HuggingFace. Para obter mais informações sobre cada um dos modelos básicos, encaminhamos os leitores para os cartões de modelo apropriados.
Embora apenas 250 imagens por classe tenham sido usadas para ajuste fino de rede, todas as imagens (aprox. 1400) do conjunto de dados de alimentos comercializáveis (MF) estão disponíveis no IEEE Dataport. Se você não conseguir acessar o hiperlink, basta pesquisar "DataSet de alimentos comercializáveis (MF)" e seguirá o link para o IEEE Dataport.
NOTA: A seção a seguir é modificada a partir do cartão de modelo estável V1, mas se aplica às imagens de geração usando os notebooks acima. NOTA: Dado que propomos o Bagm como uma estrutura de ataque, observe que um adversário que atua com intenção maliciosa pode não levar as seguintes considerações na conta!
Citação
Se nosso código, métricas ou papel for usado para promover sua pesquisa, cite nosso artigo:
@article { Vice2023BAGM ,
author = { Vice, Jordan and Akhtar, Naveed and Hartley, Richard and Mian, Ajmal } ,
journal = { IEEE Transactions on Information Forensics and Security } ,
title = { BAGM: A Backdoor Attack for Manipulating Text-to-Image Generative Models } ,
year = { 2024 } ,
volume = { 19 } ,
number = { } ,
pages = { 4865-4880 } ,
doi = { 10.1109/TIFS.2024.3386058 }
} Uso indevido, uso malicioso e uso fora de escopo
Os modelos não devem ser usados para criar ou disseminar intencionalmente imagens que criam ambientes hostis ou alienantes para as pessoas. Isso inclui a geração de imagens que as pessoas consideram previamente perturbadoras, angustiantes ou ofensivas; ou conteúdo que propaga estereótipos históricos ou atuais.
O modelo não foi treinado para serem representações factuais ou verdadeiras de pessoas ou eventos e, portanto, usando um modelo para gerar esse conteúdo está fora de escopo.
Usar modelos para gerar conteúdo cruel para os indivíduos é um uso indevido desse modelo. Isso inclui, mas não está limitado a:
- Gerando representações humilhantes, desumanizantes ou prejudiciais de pessoas ou de seus ambientes, culturas, religiões etc.
- Promoção intencional ou propagação de conteúdo discriminatório ou estereótipos prejudiciais.
- Representando indivíduos sem seu consentimento.
- Conteúdo sexual sem consentimento das pessoas que podem vê -lo.
- Desinformação errônea
- Representações de violência flagrante e sangue
- Compartilhamento de material protegido por direitos autorais ou licenciado, violando seus termos de uso.
- Compartilhando conteúdo que é uma alteração de material protegido por direitos autorais ou licenciado, violando seus termos de uso
Para mais perguntas/perguntas ou se você quiser simplesmente iniciar uma conversa, entre em contato com a Jordânia Vice: [email protected]


