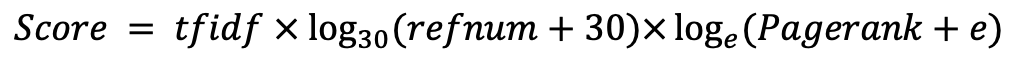minimal search engine
1.0.0
Lihat kode di github [https://github.com/gink03/minimal-search-engine:embed]
Anda perlu bepergian di sekitar berbagai situs dan permintaan akan memiliki probabilitas tinggi gagal menyimpulkan kode karakter, jadi Anda harus menginstal nkf di lingkungan Linux.
$ sudo apt install nkf
$ which nkf
/usr/bin/nkfSaya juga akan menyertakan mecab
$ sudo apt install mecab libmecab-dev mecab-ipadic
$ sudo apt install mecab-ipadic-utf8
$ sudo apt install python-mecab
$ pip3 install mecab-python3
$ git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git
$ ./bin/install-mecab-ipadic-neologd -n
Pasang dependensi yang tersisa
$ pip3 install -r requirements.txt Pada dasarnya, Anda dapat mereproduksi kode github dengan menjalankannya agar di Linux seperti Ubuntu.
Jika Anda ingin mencoba crawler (pencakar), Anda akan mendapatkan tanpa batas, jadi kami berasumsi bahwa Anda dapat memutuskan benih dan menyelesaikannya pada waktu yang tepat.
A. merangkak
B. Menguras HTML yang dirangkak dengan judul, deskripsi, tubuh, dan href untuk memformat data
C. Membuat Kamus IDF
D. Buat Data TFIDF
F. Buat korespondensi URL dan HREF yang ditransposkan (Jumlah Fitur Referensi Sederhana)
G. Menghitung Nomor Non-Referensi dan Membuat Data Pelatihan untuk Pagerank
H. Buat indeks yang ditransposkan untuk Bobot URL dan TFIDF
I. Membuat tabel korespondensi antara URL hash dan URL yang sebenarnya
J. Learning PageRank
K. Antarmuka pencarian
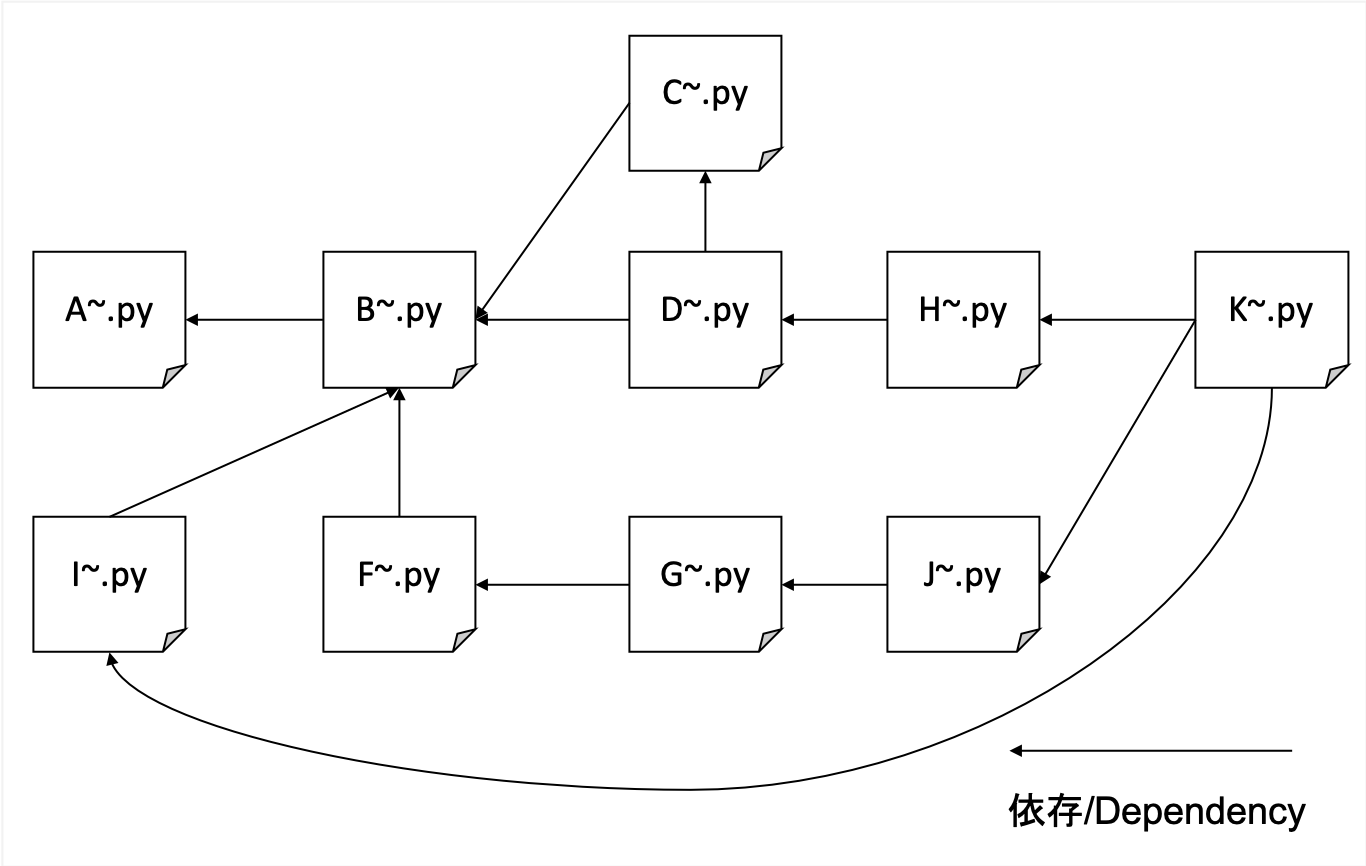
Kami akan merangkak secara komprehensif terlepas dari domain tertentu. Kami menggunakan situs blog kami sebagai benih dan melangkah lebih dalam saat kami pergi, tanpa membatasi domain kami.
Ini merangkak berbagai situs tetapi sangat berat, jadi saya menggunakan KV terdesentralisasi saya sendiri sebagai database backend saya. File rentan terhadap korupsi dengan sqllite, sedangkan LevelDB hanya dapat berupa akses tunggal.
Data yang diperoleh A terlalu besar, sehingga proses dalam B mengekstrak fitur utama pencarian di TFIDF, "judul", "deskripsi", dan "tubuh".
Ini juga mem -parsing semua URL eksternal yang dimaksud dengan halaman tersebut.
soup = BeautifulSoup ( html , features = 'lxml' )
for script in soup ([ 'script' , 'style' ]):
script . decompose ()
title = soup . title . text
description = soup . find ( 'head' ). find (
'meta' , { 'name' : 'description' })
if description is None :
description = ''
else :
description = description . get ( 'content' )
body = soup . find ( 'body' ). get_text ()
body = re . sub ( ' n ' , ' ' , body )
body = re . sub ( r's{1,}' , ' ' , body )Ini dapat dengan mudah diproses dengan Beautifulsoup.
Untuk mengurangi pentingnya kata-kata yang sering terjadi, hitung berapa banyak yang didokumentasikan setiap kata yang dirujuk.
Gunakan data dari B dan C untuk menyelesaikannya sebagai TFIDF
Setiap title body description memiliki tingkat kepentingan yang berbeda, dan title : description : body = 1 : 1 : 0.001
Itu diperlakukan sebagai.
# title desc weight = 1
text = arow . title + arow . description
text = sanitize ( text )
for term in m . parse ( text ). strip (). split ():
if term_freq . get ( term ) is None :
term_freq [ term ] = 0
term_freq [ term ] += 1
# title body = 0.001
text = arow . body
text = sanitize ( text )
for term in m . parse ( text ). strip (). split ():
if term_freq . get ( term ) is None :
term_freq [ term ] = 0
term_freq [ term ] += 0.001 # ここのweightを 0.001 のように小さい値を設定するSaya tahu bahwa itu umum di masa lalu bahwa mungkin untuk SEO dengan memberikan tautan URL dari berbagai tempat, jadi saya melakukan ini untuk mengetahui berapa banyak referensi eksternal yang dirujuk.
Berdasarkan data yang dibuat di F, Anda dapat mempelajari bobot node PageRank menggunakan pustaka yang disebut NetworkX, sehingga Anda dapat membuat data pelatihan.
Dataset seperti itu diinginkan sebagai input (hash kanan adalah sumber tautan, hash kiri adalah tujuan tautan)
d2a88da0ca550a8b 37a3d49657247e61
d2a88da0ca550a8b 6552c5a8ff9b2470
d2a88da0ca550a8b 3bf8e875fc951502
d2a88da0ca550a8b 935b17a90f5fb652
7996001a6e079a31 aabef32c9c8c4c13
d2a88da0ca550a8b e710f0bdab0ac500
d2a88da0ca550a8b a4bcfc4597f138c7
4cd5e7e2c81108be 7de6859b50d1eed2
Untuk mengakomodasi pencarian dengan hanya kata weight(tfidf) paling URLのハッシュ, kami membuat indeks yang memungkinkan Anda untuk mencari refnum(被参照数) dari kata -kata.
0010c40c7ed2c240 0.000029752 4
000ca0244339eb34 0.000029773 0
0017a9b7d83f5d24 0.000029763 0
00163826057db7c3 0.000029773 0
Jika Anda menyimpan URL seperti dalam memori, itu akan meluap, jadi dengan menggunakan SHA256 untuk menganggapnya sebagai nilai hash kecil hanya menggunakan 16 karakter pertama, Anda dapat mencari dokumen dengan penggunaan minimum praktis bahkan untuk dokumen 1 juta pesanan.
Pelajari data yang dibuat di G dan pelajari nilai PageRank di URL.
Menggunakan NetworkX, Anda dapat belajar dengan kode yang sangat sederhana.
import networkx as nx
import json
G = nx.read_edgelist('tmp/to_pagerank.txt', nodetype=str)
# ノード数とエッジ数を出力
print(nx.number_of_nodes(G))
print(nx.number_of_edges(G))
print('start calc pagerank')
pagerank = nx.pagerank(G)
print('finish calc pagerank')
json.dump(pagerank, fp=open('tmp/pagerank.json', 'w'), indent=2)
Memberikan pencarian jika
$ python3 K001_search_query.py
(ここで検索クエリを入力)contoh
$ python3 K001_search_query.py
ふわふわ
hurl weight refnum weight_norm url pagerank weight*refnum_score+pagerank
9276 36b736bccbbb95f2 0.000049 1 1.000000 https://bookwalker.jp/dea270c399-d1c5-470e-98bd-af9ba8d8464a/ 0.000146 1.009695
2783 108a6facdef1cf64 0.000037 0 0.758035 http://blog.livedoor.jp/usausa_life/archives/79482577.html 1.000000 0.995498
32712 c3ed3d4afd05fc43 0.000045 1 0.931093 https://item.fril.jp/bc7ae485a59de01d6ad428ee19671dfa 0.000038 0.940083
... Ketika saya mencari "Rai-chan", saya dapat menyetelnya sehingga informasi yang saya inginkan kira-kira di atas.
Pixiv tidak secara eksplisit diatur ke tujuan merangkak, tetapi secara otomatis diperoleh sebagai hasil crawler A mengikuti tautan dan membuat indeks.
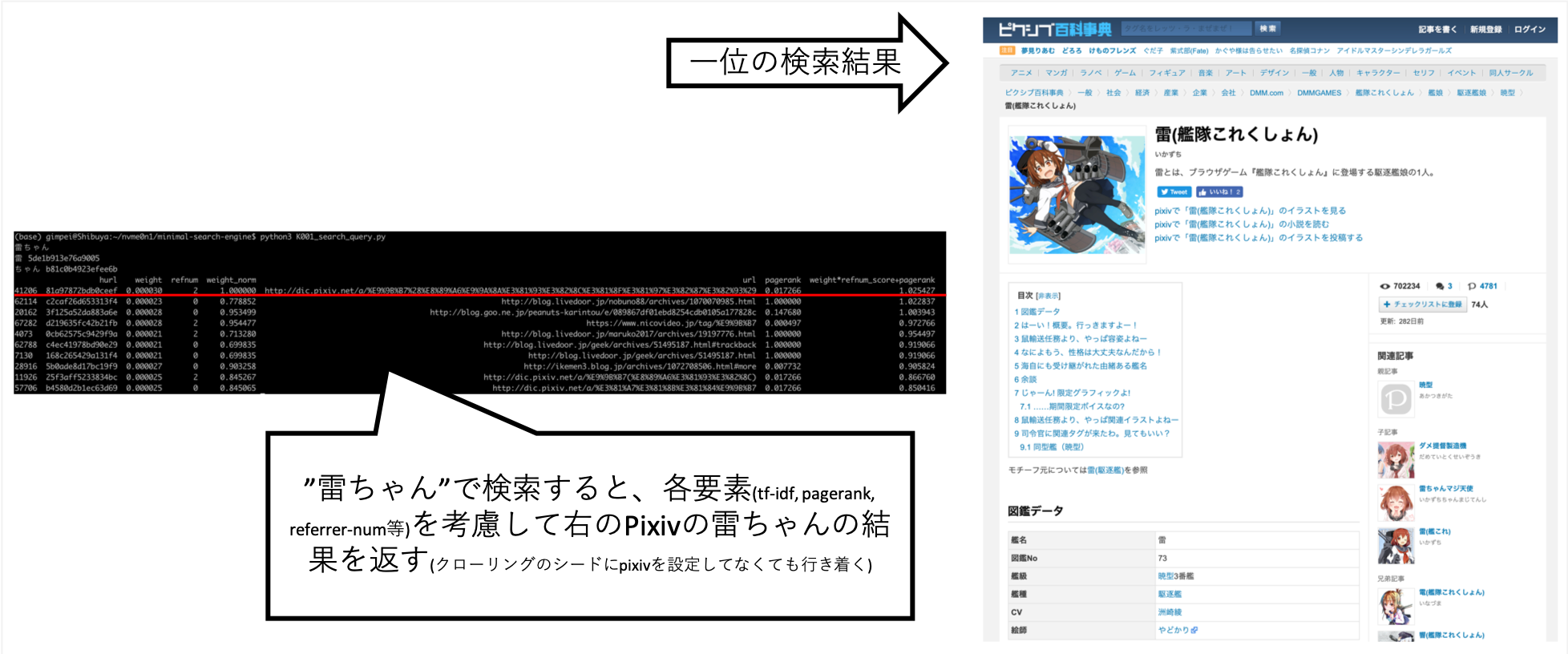
Pertanyaan lain, seperti "Shokuro", telah mengembalikan hasil yang saya inginkan.
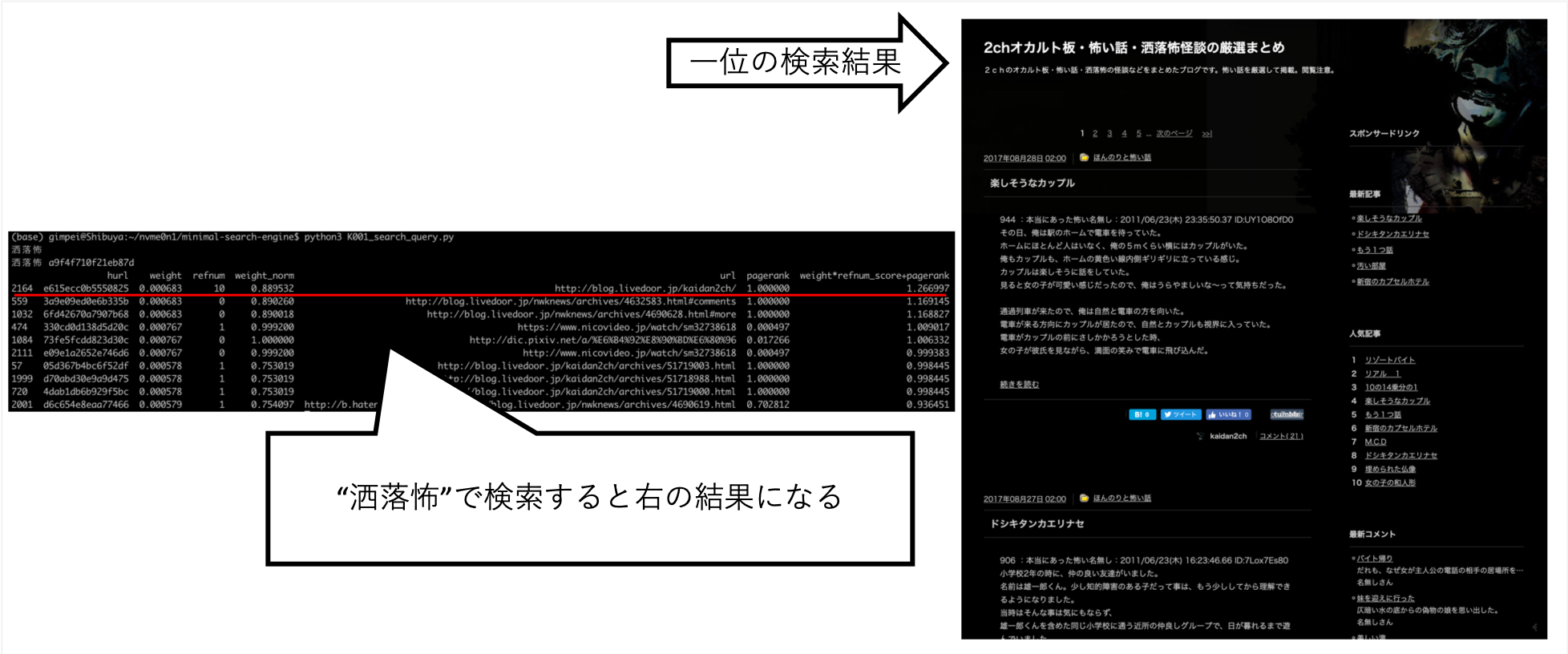
Setelah mencoba berbagai hal dengan tangan, saya menemukan ini sebagai skor terbaik. (Saya data yang benar)