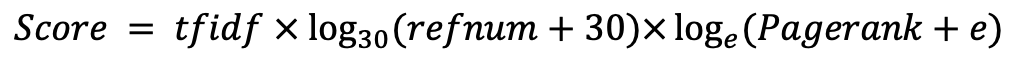minimal search engine
1.0.0
请参阅GitHub上的代码
您需要在各个站点周围旅行,并且请求将很可能无法推断角色代码,因此您需要在Linux环境中安装nkf 。
$ sudo apt install nkf
$ which nkf
/usr/bin/nkf我也包括mecab
$ sudo apt install mecab libmecab-dev mecab-ipadic
$ sudo apt install mecab-ipadic-utf8
$ sudo apt install python-mecab
$ pip3 install mecab-python3
$ git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git
$ ./bin/install-mecab-ipadic-neologd -n
安装剩余的依赖项
$ pip3 install -r requirements.txt 基本上,您可以通过按照ubuntu等Linux上的顺序运行github代码来重现github代码。
如果您想尝试爬网(刮刀),您将无限地获得,因此我们假设您可以决定种子并在适当的时间完成。
A.爬行
B.用标题,描述,身体和HREF对爬行的HTML解析以格式化数据
C.创建IDF词典
D.创建TFIDF数据
F.创建转置URL和HREFS的对应关系(简单引用的特征量)
G.计算非参考号码并为Pagerank创建培训数据
H.为URL和TFIDF权重创建一个转置索引
I.在Hashed URL和实际URL之间创建对应表
J.学习Pagerank
K.搜索接口
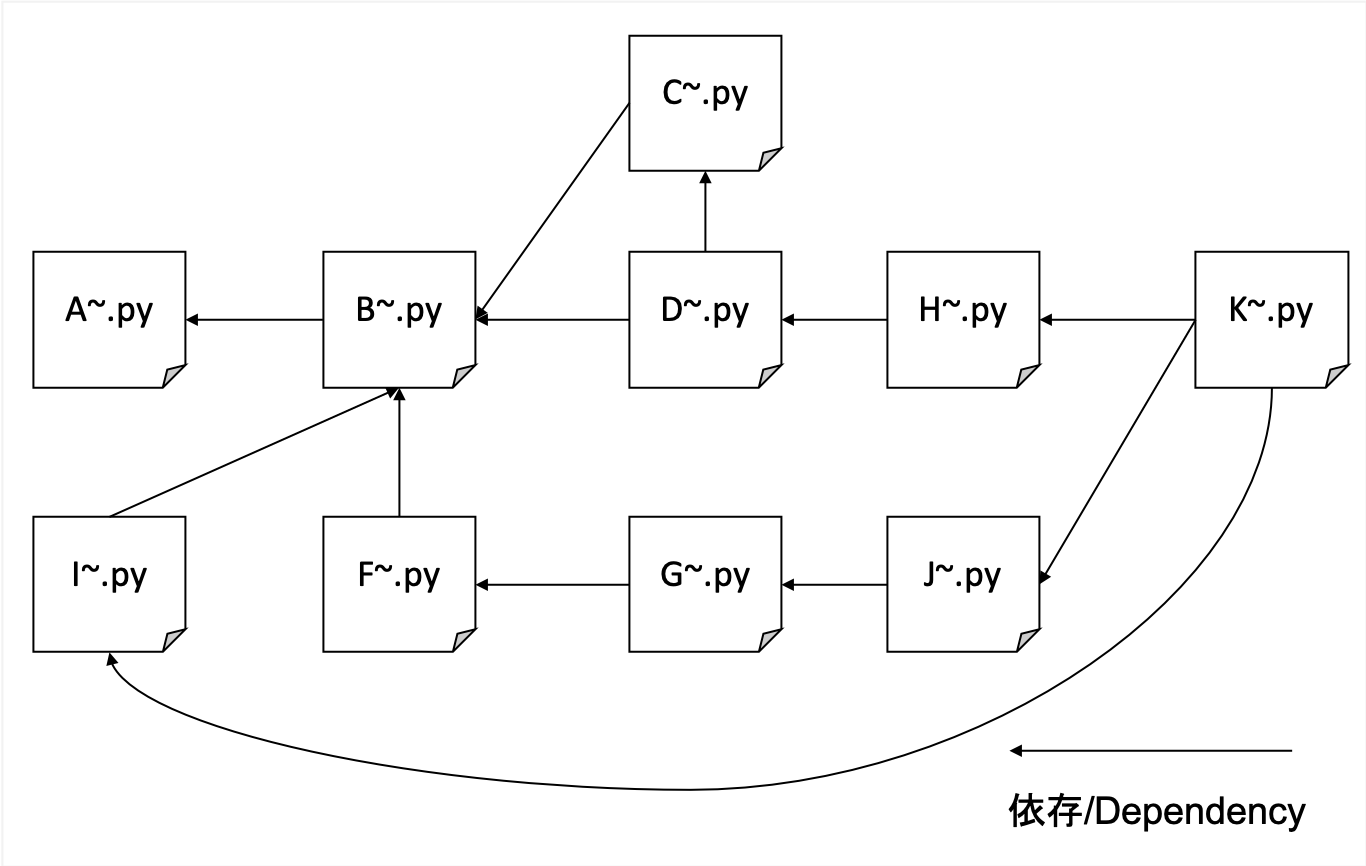
无论特定领域如何,我们都会全面爬网。 我们将我们的博客网站用作种子,并随着限制我们的领域而进行更深入的发展。
它爬行了各种站点,但非常重,因此我将自己的分散KVS作为我的后端数据库。文件容易使用sqllite损坏,而LevelDB只能是单个访问权限。
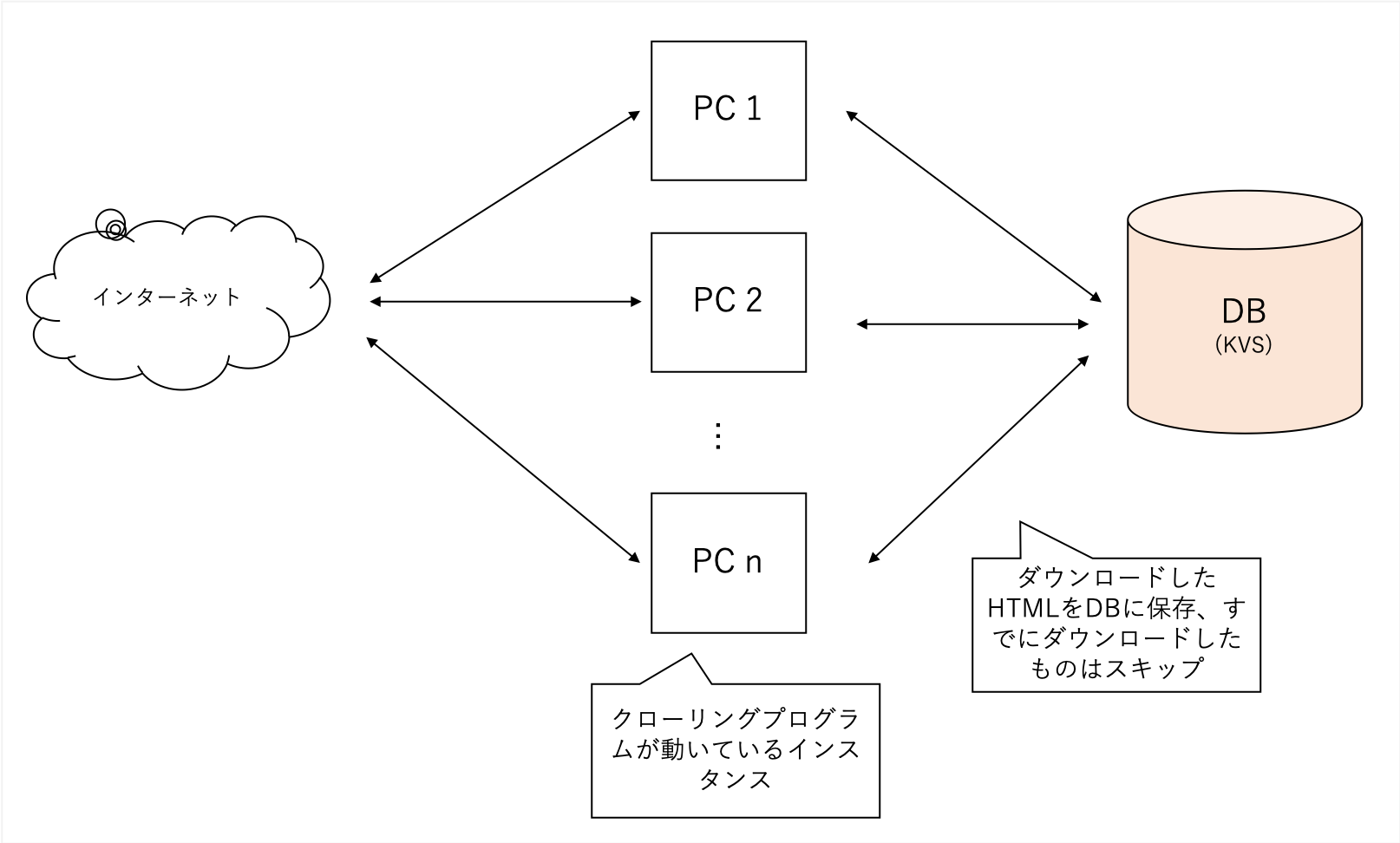
A中获得的数据太大,因此B中的过程提取了TFIDF,“标题”,“描述”和“身体”中搜索的主要特征。
它还解析了页面所指的所有外部URL。
soup = BeautifulSoup ( html , features = 'lxml' )
for script in soup ([ 'script' , 'style' ]):
script . decompose ()
title = soup . title . text
description = soup . find ( 'head' ). find (
'meta' , { 'name' : 'description' })
if description is None :
description = ''
else :
description = description . get ( 'content' )
body = soup . find ( 'body' ). get_text ()
body = re . sub ( ' n ' , ' ' , body )
body = re . sub ( r's{1,}' , ' ' , body )它可以很容易地使用美丽的小组处理。
为了降低经常出现的单词的重要性,请计算每个单词的记录。
使用B和C的数据将其作为TFIDF完成
每个title description body的重要性不同, title : description : body = 1 : 1 : 0.001
它被视为。
# title desc weight = 1
text = arow . title + arow . description
text = sanitize ( text )
for term in m . parse ( text ). strip (). split ():
if term_freq . get ( term ) is None :
term_freq [ term ] = 0
term_freq [ term ] += 1
# title body = 0.001
text = arow . body
text = sanitize ( text )
for term in m . parse ( text ). strip (). split ():
if term_freq . get ( term ) is None :
term_freq [ term ] = 0
term_freq [ term ] += 0.001 # ここのweightを 0.001 のように小さい値を設定する我知道过去很普遍,可以通过从各个地方提供URL链接来SEO,因此我这样做是为了知道要提及多少外部参考。
基于F中创建的数据,您可以使用名为NetworkX的库学习Pagerank节点的权重,因此您可以创建培训数据。
需要将这样一个数据集作为输入(右哈希是链接源,左哈希是链接目标))
d2a88da0ca550a8b 37a3d49657247e61
d2a88da0ca550a8b 6552c5a8ff9b2470
d2a88da0ca550a8b 3bf8e875fc951502
d2a88da0ca550a8b 935b17a90f5fb652
7996001a6e079a31 aabef32c9c8c4c13
d2a88da0ca550a8b e710f0bdab0ac500
d2a88da0ca550a8b a4bcfc4597f138c7
4cd5e7e2c81108be 7de6859b50d1eed2
为了使用最简单的单词weight(tfidf)容纳搜索,我们创建了一个索引refnum(被参照数)使您可以从单词中搜索URLのハッシュ。
0010c40c7ed2c240 0.000029752 4
000ca0244339eb34 0.000029773 0
0017a9b7d83f5d24 0.000029763 0
00163826057db7c3 0.000029773 0
如果您将URL保持在内存中,它将溢出,因此,通过使用SHA256将其视为仅使用前16个字符的小哈希值,您就可以搜索具有最少实际使用的文档,即使是100万个订单的文档。
了解在G中创建的数据,并学习URL中的Pagerank值。
使用NetworkX,您可以使用非常简单的代码学习。
import networkx as nx
import json
G = nx.read_edgelist('tmp/to_pagerank.txt', nodetype=str)
# ノード数とエッジ数を出力
print(nx.number_of_nodes(G))
print(nx.number_of_edges(G))
print('start calc pagerank')
pagerank = nx.pagerank(G)
print('finish calc pagerank')
json.dump(pagerank, fp=open('tmp/pagerank.json', 'w'), indent=2)
提供搜索,如果
$ python3 K001_search_query.py
(ここで検索クエリを入力)例子
$ python3 K001_search_query.py
ふわふわ
hurl weight refnum weight_norm url pagerank weight*refnum_score+pagerank
9276 36b736bccbbb95f2 0.000049 1 1.000000 https://bookwalker.jp/dea270c399-d1c5-470e-98bd-af9ba8d8464a/ 0.000146 1.009695
2783 108a6facdef1cf64 0.000037 0 0.758035 http://blog.livedoor.jp/usausa_life/archives/79482577.html 1.000000 0.995498
32712 c3ed3d4afd05fc43 0.000045 1 0.931093 https://item.fril.jp/bc7ae485a59de01d6ad428ee19671dfa 0.000038 0.940083
... 当我搜索“ Rai-chan”时,我能够调整它,以便大致上是我想要的信息。
Pixiv并未明确设置为爬行目的地,但由于A的爬行者遵循链接并创建索引,因此自动获取它。
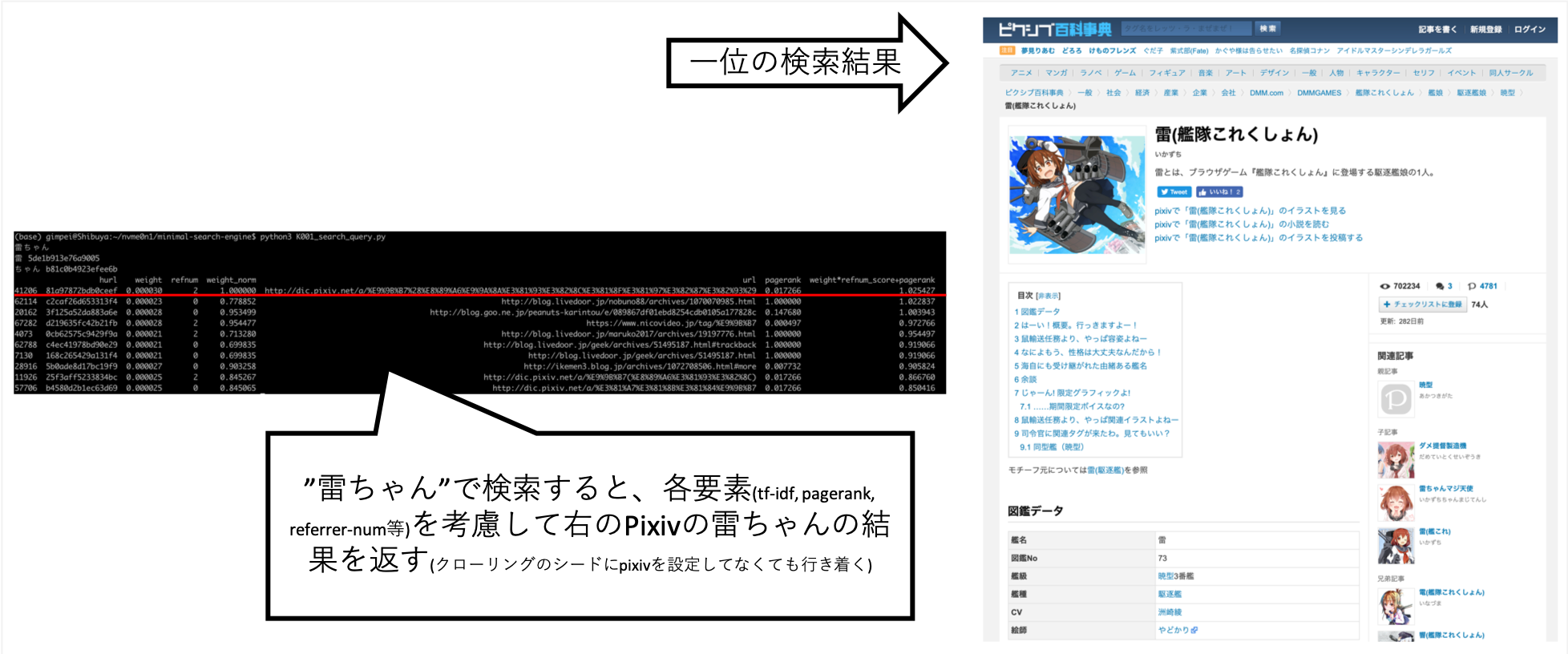
其他查询,例如“ Shokuro”,也返回了我想要的结果。
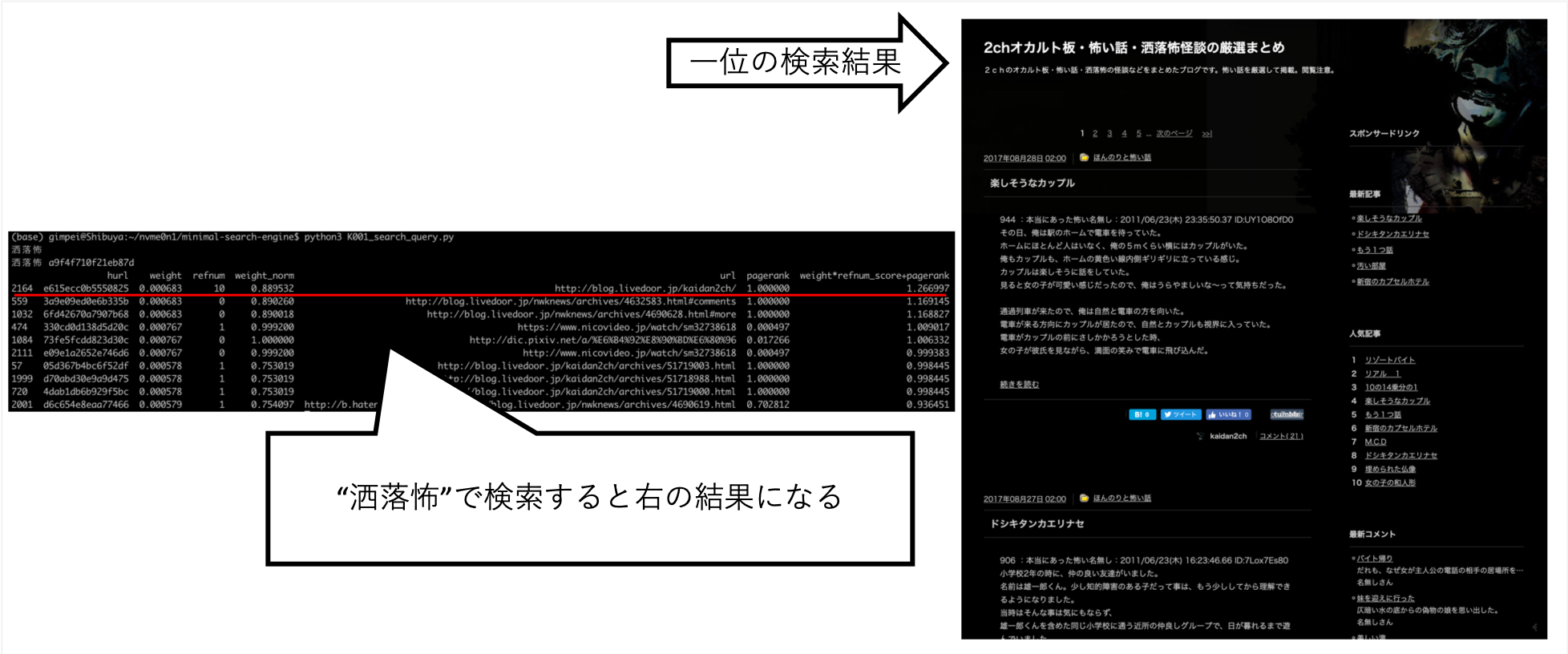
手工尝试各种事情后,我发现这是最佳分数。 (我是正确的数据)