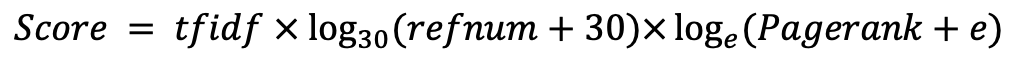minimal search engine
1.0.0
Смотрите код на GitHub [https://github.com/gink03/minimal-search-engine:embed]
Вам необходимо путешествовать по различным сайтам, и запросы будут иметь высокую вероятность вывода кодов символов, поэтому вам необходимо установить nkf в среде Linux.
$ sudo apt install nkf
$ which nkf
/usr/bin/nkfЯ также включу Mecab
$ sudo apt install mecab libmecab-dev mecab-ipadic
$ sudo apt install mecab-ipadic-utf8
$ sudo apt install python-mecab
$ pip3 install mecab-python3
$ git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git
$ ./bin/install-mecab-ipadic-neologd -n
Установите оставшиеся зависимости
$ pip3 install -r requirements.txt По сути, вы можете воспроизвести код GitHub, запустив его в порядке на Linux, таком как Ubuntu.
Если вы хотите попробовать Crawlers (скребки), вы получите бесконечно, поэтому мы предполагаем, что вы можете определить семя и закончить его в подходящее время.
А. Ползание
B. Распокащая HTML с заголовком, описанием, описанием, телом и Hrefs для форматирования данных
C. Создание словаря ИДФ
D. Создание данных TFIDF
F. Создайте переписку транспонированных URL и HREFS (простое количество ссылок)
G. Подсчет номеров без ссылок и создание учебных данных для PageRank
H. Создание транспонированного индекса для весов URL и TFIDF
I. Создание таблицы переписки между Hashed URL и фактическим URL
J. Learning Pagerank
К. Поисковый интерфейс
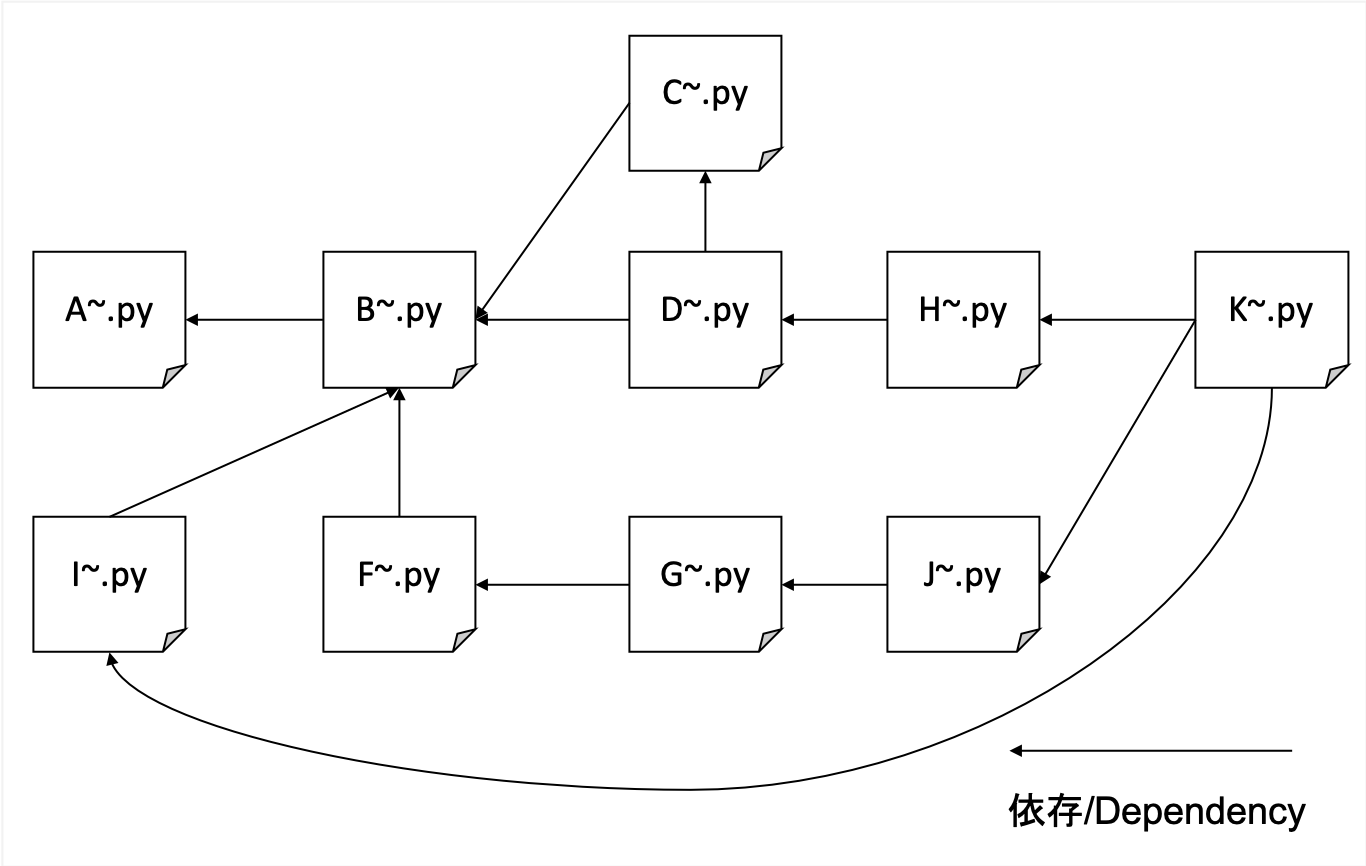
Мы будем ползти всесторонне независимо от конкретной области. Мы используем наш сайт блога как семя и идем глубже, когда мы идем, не ограничивая наш домен.
Он ползет множество сайтов, но очень тяжелый, поэтому я использую свои собственные децентрализованные KV в качестве базы данных бэкэнд. Файлы склонны к повреждению с SQLLITE, в то время как LevelDB может быть только для одного доступа.
Данные, полученные в A, слишком велики, поэтому процесс в B извлекает основные функции поиска в TFIDF, «название», «Описание» и «тело».
Это также анализирует все внешние URL -адреса, на которые ссылается страница.
soup = BeautifulSoup ( html , features = 'lxml' )
for script in soup ([ 'script' , 'style' ]):
script . decompose ()
title = soup . title . text
description = soup . find ( 'head' ). find (
'meta' , { 'name' : 'description' })
if description is None :
description = ''
else :
description = description . get ( 'content' )
body = soup . find ( 'body' ). get_text ()
body = re . sub ( ' n ' , ' ' , body )
body = re . sub ( r's{1,}' , ' ' , body )Это может быть легко обработано с помощью BeautifulSoup.
Чтобы уменьшить важность часто встречающихся слов, подсчитайте, сколько документировано каждое слово ссылки.
Используйте данные из B и C, чтобы завершить его в качестве TFIDF
Каждое title description body имеет различный уровень важности, и title : description : body = 1 : 1 : 0.001
Это рассматривалось как.
# title desc weight = 1
text = arow . title + arow . description
text = sanitize ( text )
for term in m . parse ( text ). strip (). split ():
if term_freq . get ( term ) is None :
term_freq [ term ] = 0
term_freq [ term ] += 1
# title body = 0.001
text = arow . body
text = sanitize ( text )
for term in m . parse ( text ). strip (). split ():
if term_freq . get ( term ) is None :
term_freq [ term ] = 0
term_freq [ term ] += 0.001 # ここのweightを 0.001 のように小さい値を設定するЯ знал, что в прошлом часто можно было бы SEO, предоставляя URL -ссылки из разных мест, поэтому я сделал это, чтобы узнать, сколько внешних ссылок упоминаются.
Основываясь на данных, созданных в F, вы можете изучить веса узлов PageRank, используя библиотеку под названием NetworkX, чтобы вы могли создавать учебные данные.
Такой набор данных желателен как вход (правый хэш является источником ссылки, левый хэш - это пункт назначения ссылки)
d2a88da0ca550a8b 37a3d49657247e61
d2a88da0ca550a8b 6552c5a8ff9b2470
d2a88da0ca550a8b 3bf8e875fc951502
d2a88da0ca550a8b 935b17a90f5fb652
7996001a6e079a31 aabef32c9c8c4c13
d2a88da0ca550a8b e710f0bdab0ac500
d2a88da0ca550a8b a4bcfc4597f138c7
4cd5e7e2c81108be 7de6859b50d1eed2
refnum(被参照数) размещения поисков только самые простые слова мы создаем индекс weight(tfidf) который позволяет искать URLのハッシュ-адреса из слов.
0010c40c7ed2c240 0.000029752 4
000ca0244339eb34 0.000029773 0
0017a9b7d83f5d24 0.000029763 0
00163826057db7c3 0.000029773 0
Если вы сохраните URL, как в памяти, он переполнится, поэтому, используя SHA256, чтобы считать его небольшим хэш -значением, используя только первые 16 символов, вы можете искать документы с минимальным практическим использованием даже для документов в 1 миллион заказа.
Изучите данные, созданные в G и изучите значение PageRank в URL.
Используя NetworkX, вы можете учиться с очень простым кодом.
import networkx as nx
import json
G = nx.read_edgelist('tmp/to_pagerank.txt', nodetype=str)
# ノード数とエッジ数を出力
print(nx.number_of_nodes(G))
print(nx.number_of_edges(G))
print('start calc pagerank')
pagerank = nx.pagerank(G)
print('finish calc pagerank')
json.dump(pagerank, fp=open('tmp/pagerank.json', 'w'), indent=2)
Обеспечивает поиск, если
$ python3 K001_search_query.py
(ここで検索クエリを入力)пример
$ python3 K001_search_query.py
ふわふわ
hurl weight refnum weight_norm url pagerank weight*refnum_score+pagerank
9276 36b736bccbbb95f2 0.000049 1 1.000000 https://bookwalker.jp/dea270c399-d1c5-470e-98bd-af9ba8d8464a/ 0.000146 1.009695
2783 108a6facdef1cf64 0.000037 0 0.758035 http://blog.livedoor.jp/usausa_life/archives/79482577.html 1.000000 0.995498
32712 c3ed3d4afd05fc43 0.000045 1 0.931093 https://item.fril.jp/bc7ae485a59de01d6ad428ee19671dfa 0.000038 0.940083
... Когда я искал «Рай-чан», я смог настроить ее так, чтобы информация, которую я хотел, примерно выше.
Pixiv явно не установлен в пункт назначения ползания, но он был автоматически приобретен в результате того, что A Crawler после ссылок и создания индекса.
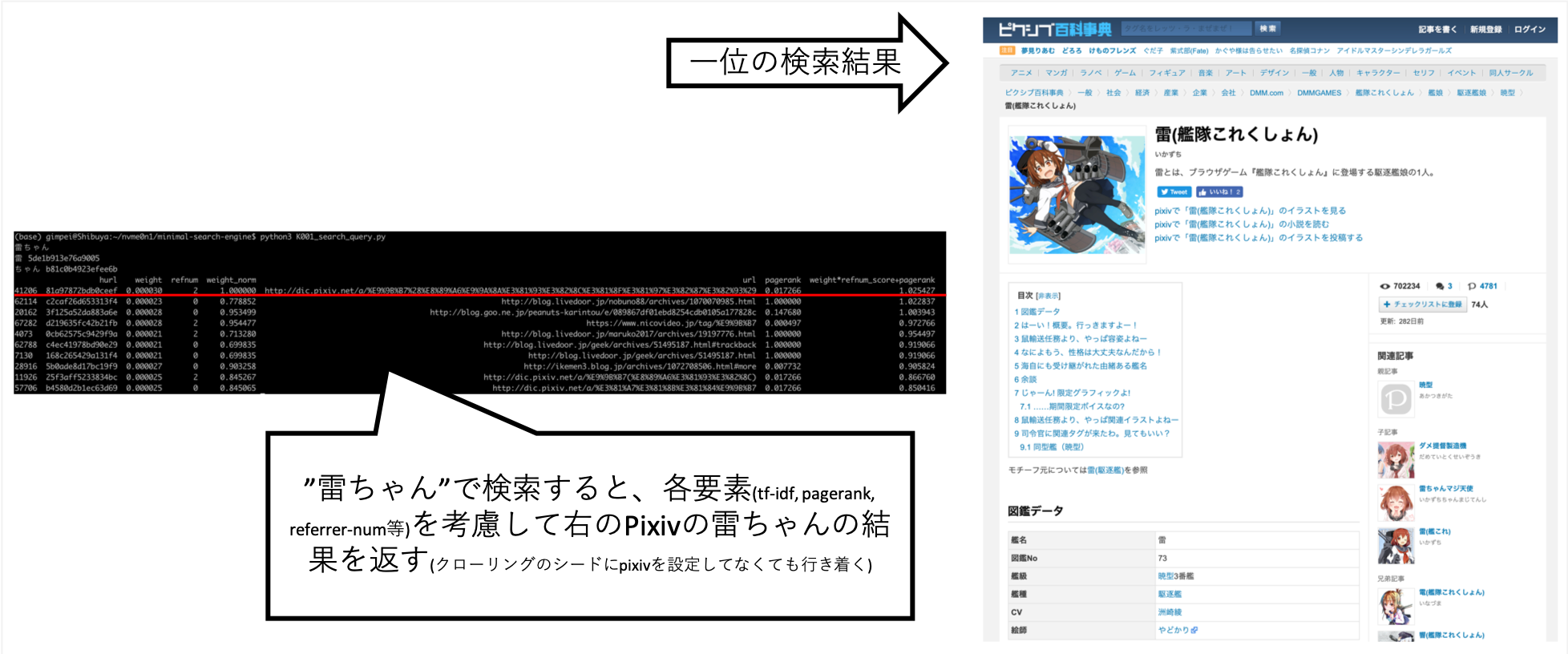
Другие вопросы, такие как «Шокуро», вернули желаемые результаты.
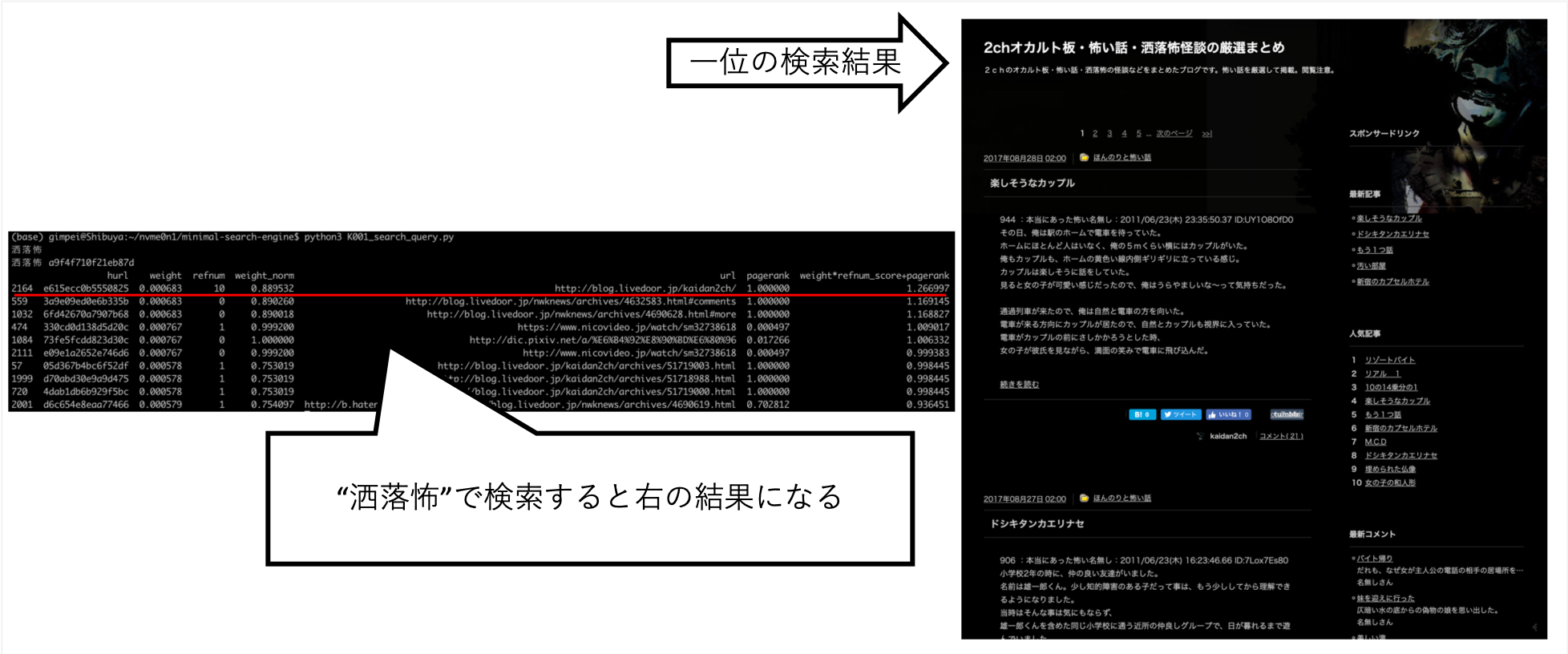
Попробовав различные вещи вручную, я обнаружил, что это лучший результат. (Я правильные данные)