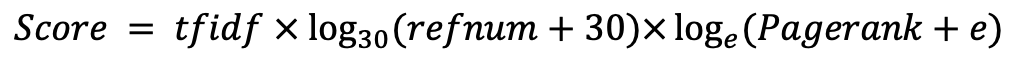minimal search engine
1.0.0
See the code on GitHub [https://github.com/GINK03/minimal-search-engine:embed]
You need to travel around various sites and requests will have a high probability of failing to infer character codes, so you need to have nkf installed in a linux environment.
$ sudo apt install nkf
$ which nkf
/usr/bin/nkfI'll also include Mecab
$ sudo apt install mecab libmecab-dev mecab-ipadic
$ sudo apt install mecab-ipadic-utf8
$ sudo apt install python-mecab
$ pip3 install mecab-python3
$ git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git
$ ./bin/install-mecab-ipadic-neologd -n
Install the remaining dependencies
$ pip3 install -r requirements.txt Basically, you can reproduce GitHub code by running it in order of A on Linux such as Ubuntu.
If you want to try crawlers (scrapers), you will get infinitely, so we assume that you can decide on the SEED and finish it at an appropriate time.
A. Crawling
B. Parsing the crawled HTML with title, description, body, and hrefs to format the data
C. Creating an IDF dictionary
D. Create TFIDF data
F. Create a correspondence of transposed URLs and hrefs (simple referenced feature amount)
G. Counting non-reference numbers and creating training data for PageRank
H. Create a transposed index for URL and tfidf weights
I. Creating a correspondence table between a hashed URL and an actual URL
J. Learning PageRank
K. Search interface
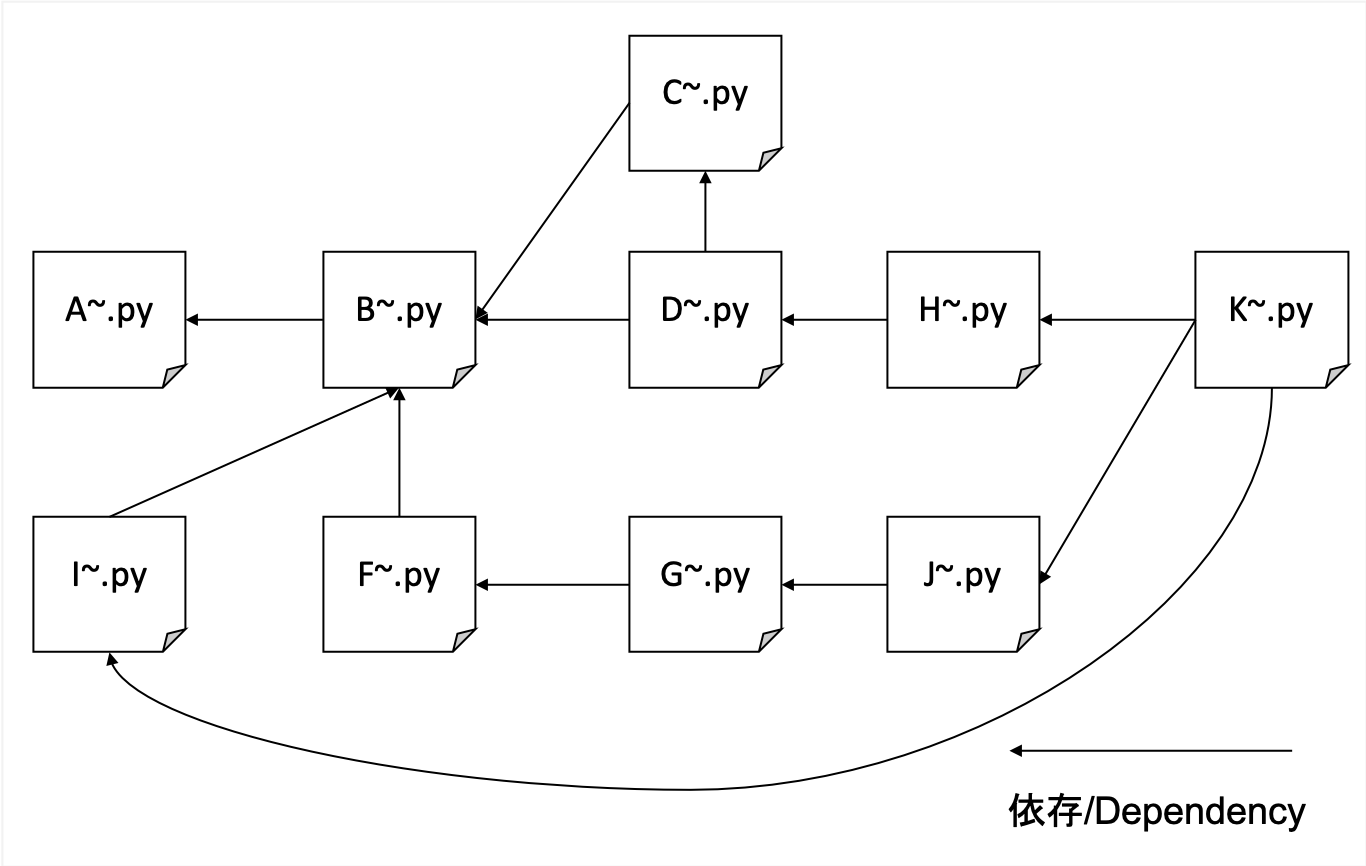
We will crawl comprehensively regardless of the specific domain. We use our blog site as a seed and go deeper as we go, without limiting our domain.
It crawls a variety of sites but is very heavy, so I use my own decentralized KVS as my backend database. Files are prone to corruption with SQLLite, while LevelDB can only be single access.
The data obtained in A is too large, so the process in B extracts the main features of searching in tfidf, "title", "description", and "body".
It also parses all external URLs that the page refers to.
soup = BeautifulSoup ( html , features = 'lxml' )
for script in soup ([ 'script' , 'style' ]):
script . decompose ()
title = soup . title . text
description = soup . find ( 'head' ). find (
'meta' , { 'name' : 'description' })
if description is None :
description = ''
else :
description = description . get ( 'content' )
body = soup . find ( 'body' ). get_text ()
body = re . sub ( ' n ' , ' ' , body )
body = re . sub ( r's{1,}' , ' ' , body )It can be easily processed with BeautifulSoup.
To reduce the importance of frequently-occurring words, count how much documented each word is referenced.
Use data from B and C to complete it as a TFIDF
Each title description body has a different level of importance, and title : description : body = 1 : 1 : 0.001
It was treated as.
# title desc weight = 1
text = arow . title + arow . description
text = sanitize ( text )
for term in m . parse ( text ). strip (). split ():
if term_freq . get ( term ) is None :
term_freq [ term ] = 0
term_freq [ term ] += 1
# title body = 0.001
text = arow . body
text = sanitize ( text )
for term in m . parse ( text ). strip (). split ():
if term_freq . get ( term ) is None :
term_freq [ term ] = 0
term_freq [ term ] += 0.001 # ここのweightを 0.001 のように小さい値を設定するI knew that it was common in the past that it would be possible to SEO by giving URL links from various places, so I did this to know how much external references are being referred to.
Based on the data created in F, you can learn the weights of PageRank nodes using a library called networkx, so you can create training data.
Such a dataset is desired as input (right hash is the link source, left hash is the link destination)
d2a88da0ca550a8b 37a3d49657247e61
d2a88da0ca550a8b 6552c5a8ff9b2470
d2a88da0ca550a8b 3bf8e875fc951502
d2a88da0ca550a8b 935b17a90f5fb652
7996001a6e079a31 aabef32c9c8c4c13
d2a88da0ca550a8b e710f0bdab0ac500
d2a88da0ca550a8b a4bcfc4597f138c7
4cd5e7e2c81108be 7de6859b50d1eed2
To accommodate searches with only the simplest words, we create an index that allows you to search for URLs from words. The output is a text file for each word (hash value) and URLのハッシュ, weight(tfidf) and refnum(被参照数) files become a file with a concrete transposed index.
0010c40c7ed2c240 0.000029752 4
000ca0244339eb34 0.000029773 0
0017a9b7d83f5d24 0.000029763 0
00163826057db7c3 0.000029773 0
If you keep the URL as is in memory, it will overflow, so by using sha256 to consider it as a small hash value using only the first 16 characters, you can search for documents with a minimum of practical use even for documents of 1 million orders.
Learn the data created in G and learn the PageRank value in the URL.
Using networkx, you can learn with very simple code.
import networkx as nx
import json
G = nx.read_edgelist('tmp/to_pagerank.txt', nodetype=str)
# ノード数とエッジ数を出力
print(nx.number_of_nodes(G))
print(nx.number_of_edges(G))
print('start calc pagerank')
pagerank = nx.pagerank(G)
print('finish calc pagerank')
json.dump(pagerank, fp=open('tmp/pagerank.json', 'w'), indent=2)
Provides search IF
$ python3 K001_search_query.py
(ここで検索クエリを入力)example
$ python3 K001_search_query.py
ふわふわ
hurl weight refnum weight_norm url pagerank weight*refnum_score+pagerank
9276 36b736bccbbb95f2 0.000049 1 1.000000 https://bookwalker.jp/dea270c399-d1c5-470e-98bd-af9ba8d8464a/ 0.000146 1.009695
2783 108a6facdef1cf64 0.000037 0 0.758035 http://blog.livedoor.jp/usausa_life/archives/79482577.html 1.000000 0.995498
32712 c3ed3d4afd05fc43 0.000045 1 0.931093 https://item.fril.jp/bc7ae485a59de01d6ad428ee19671dfa 0.000038 0.940083
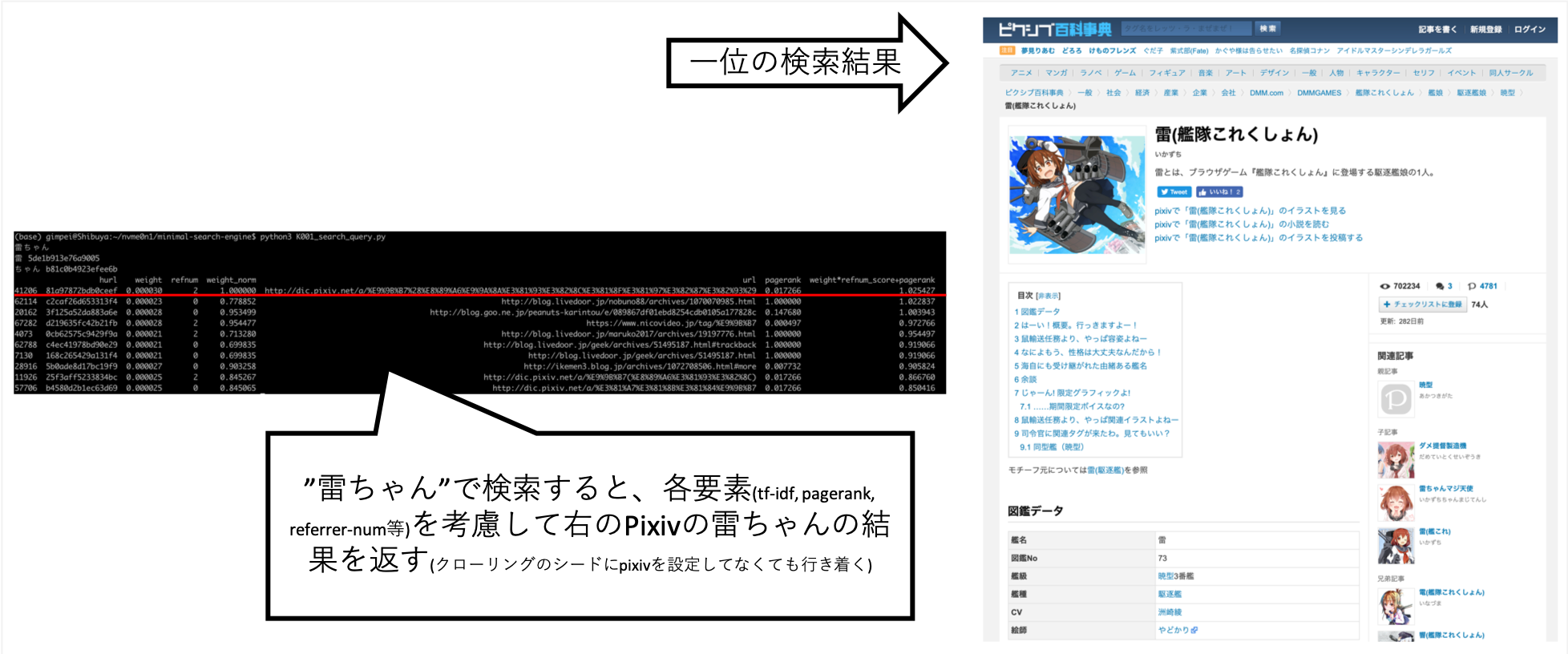
... When I searched for "Rai-chan", I was able to tune it so that the information I wanted is roughly above.
Pixiv is not explicitly set to the crawling destination, but it was automatically acquired as a result of A's crawler following the links and creating an index.
Other queries, such as "Shokuro", have returned the results I wanted.
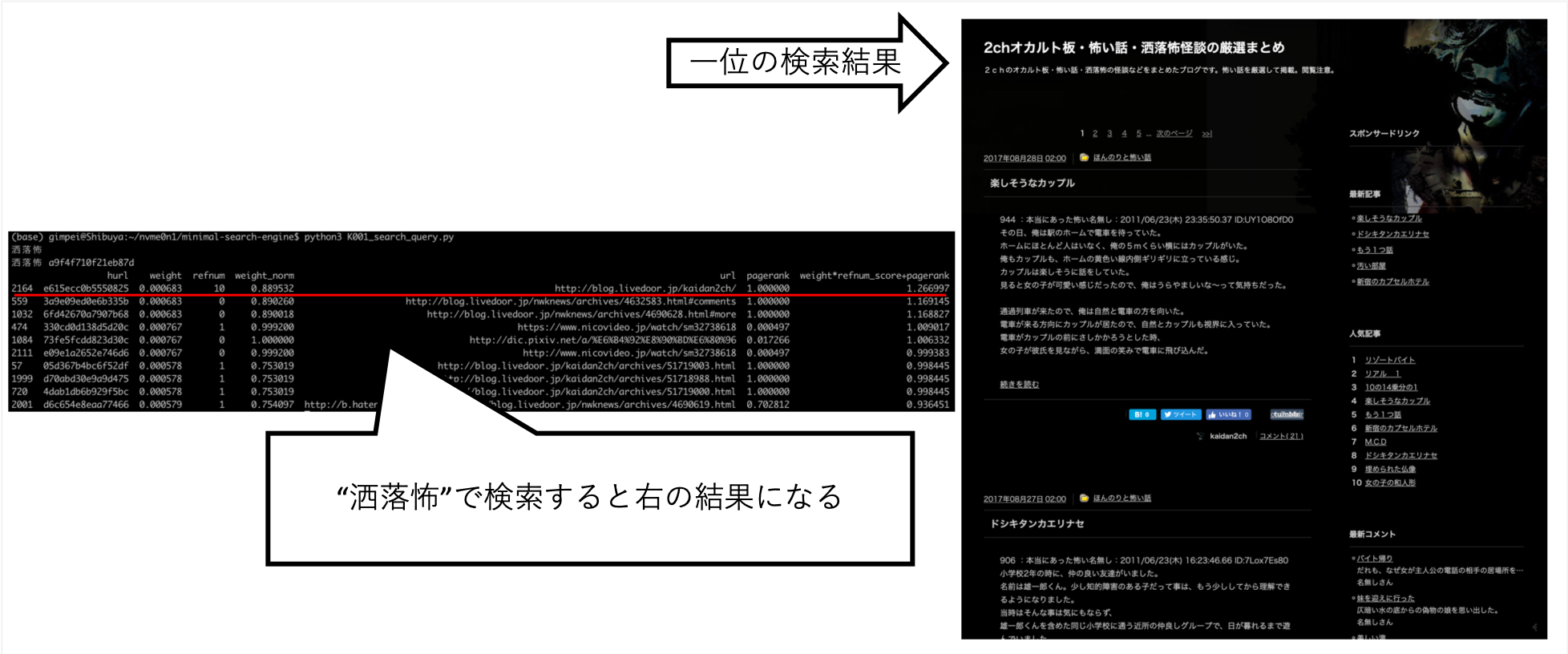
After trying out various things by hand, I found this to be the best score. (I'm the correct data)