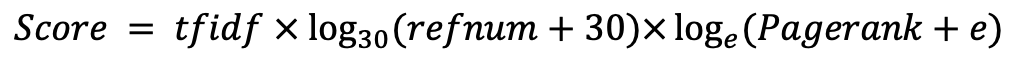minimal search engine
1.0.0
Voir le code sur github [https://github.com/gink03/minimal-search-engine:embed]
Vous devez voyager sur divers sites et les demandes auront une forte probabilité de ne pas déduire les codes de caractère, vous devez donc faire installer nkf dans un environnement Linux.
$ sudo apt install nkf
$ which nkf
/usr/bin/nkfJ'inclurai également mecab
$ sudo apt install mecab libmecab-dev mecab-ipadic
$ sudo apt install mecab-ipadic-utf8
$ sudo apt install python-mecab
$ pip3 install mecab-python3
$ git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git
$ ./bin/install-mecab-ipadic-neologd -n
Installez les dépendances restantes
$ pip3 install -r requirements.txt Fondamentalement, vous pouvez reproduire le code GitHub en l'exécutant dans l'ordre de A sur Linux tel que Ubuntu.
Si vous voulez essayer Crawlers (Scraphers), vous obtiendrez l'infini, nous supposons donc que vous pouvez décider de la graine et le terminer à un moment opportun.
A. rampant
B. analyser le HTML rampé avec le titre, la description, le corps et les HREFS pour formater les données
C. Création d'un dictionnaire IDF
D. Créer des données TFIDF
F. Créer une correspondance des URL transposées et des HREF (montant de fonction référencé simple)
G. Compter les nombres non-références et créer des données de formation pour Pagerank
H. Créez un index transposé pour les poids URL et TFIDF
I. Création d'une table de correspondance entre une URL hachée et une URL réelle
J. Apprendre le pagerank
K. Interface de recherche
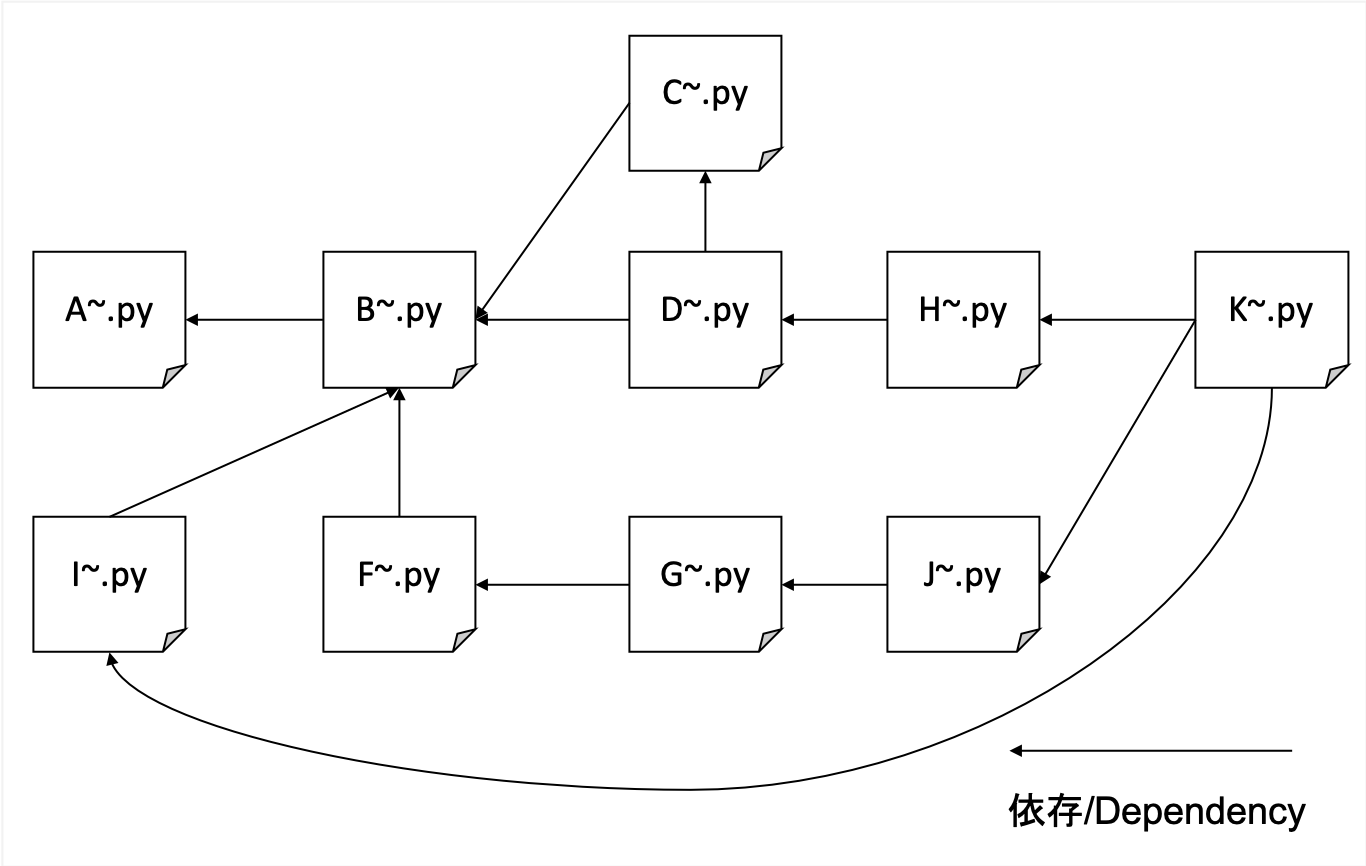
Nous ramperons de manière globale quel que soit le domaine spécifique. Nous utilisons notre site de blog comme graine et allons plus loin au fur et à mesure, sans limiter notre domaine.
Il explore une variété de sites mais est très lourd, donc j'utilise mes propres KV décentralisés comme ma base de données backend. Les fichiers sont sujets à la corruption avec Sqllite, tandis que LevelDB ne peut être qu'un seul accès.
Les données obtenues en A sont trop grandes, donc le processus en B extrait les principales caractéristiques de la recherche dans TFIDF, "Title", "Description" et "Body".
Il analyse également toutes les URL externes auxquelles la page fait référence.
soup = BeautifulSoup ( html , features = 'lxml' )
for script in soup ([ 'script' , 'style' ]):
script . decompose ()
title = soup . title . text
description = soup . find ( 'head' ). find (
'meta' , { 'name' : 'description' })
if description is None :
description = ''
else :
description = description . get ( 'content' )
body = soup . find ( 'body' ). get_text ()
body = re . sub ( ' n ' , ' ' , body )
body = re . sub ( r's{1,}' , ' ' , body )Il peut être facilement traité avec BeautifulSoup.
Pour réduire l'importance des mots fréquemment actuels, comptez la quantité documentée de chaque mot référencé.
Utilisez des données de B et C pour la compléter en tant que TFIDF
Chaque title description body a un niveau d'importance différent et title : description : body = 1 : 1 : 0.001
Il a été traité comme.
# title desc weight = 1
text = arow . title + arow . description
text = sanitize ( text )
for term in m . parse ( text ). strip (). split ():
if term_freq . get ( term ) is None :
term_freq [ term ] = 0
term_freq [ term ] += 1
# title body = 0.001
text = arow . body
text = sanitize ( text )
for term in m . parse ( text ). strip (). split ():
if term_freq . get ( term ) is None :
term_freq [ term ] = 0
term_freq [ term ] += 0.001 # ここのweightを 0.001 のように小さい値を設定するJe savais qu'il était courant dans le passé qu'il serait possible de SEO en donnant des liens d'URL à partir de divers endroits, alors j'ai fait cela pour savoir à quel point les références externes sont mentionnées.
Sur la base des données créées en F, vous pouvez apprendre les poids des nœuds PageRank à l'aide d'une bibliothèque appelée NetworkX, afin que vous puissiez créer des données de formation.
Un tel ensemble de données est souhaité en entrée (le hachage droit est la source de liaison, le hachage gauche est la destination de liaison)
d2a88da0ca550a8b 37a3d49657247e61
d2a88da0ca550a8b 6552c5a8ff9b2470
d2a88da0ca550a8b 3bf8e875fc951502
d2a88da0ca550a8b 935b17a90f5fb652
7996001a6e079a31 aabef32c9c8c4c13
d2a88da0ca550a8b e710f0bdab0ac500
d2a88da0ca550a8b a4bcfc4597f138c7
4cd5e7e2c81108be 7de6859b50d1eed2
Pour accueillir les recherches avec les mots les plus refnum(被参照数) , nous créons un index qui vous permet weight(tfidf) rechercher des URLのハッシュà partir de mots.
0010c40c7ed2c240 0.000029752 4
000ca0244339eb34 0.000029773 0
0017a9b7d83f5d24 0.000029763 0
00163826057db7c3 0.000029773 0
Si vous gardez l'URL comme en mémoire, il débordera, donc en utilisant SHA256 pour le considérer comme une petite valeur de hachage en utilisant uniquement les 16 premiers caractères, vous pouvez rechercher des documents avec un minimum d'utilisation pratique même pour des documents de 1 million de commandes.
Apprenez les données créées dans G et apprenez la valeur PageRank dans l'URL.
En utilisant NetworkX, vous pouvez apprendre avec un code très simple.
import networkx as nx
import json
G = nx.read_edgelist('tmp/to_pagerank.txt', nodetype=str)
# ノード数とエッジ数を出力
print(nx.number_of_nodes(G))
print(nx.number_of_edges(G))
print('start calc pagerank')
pagerank = nx.pagerank(G)
print('finish calc pagerank')
json.dump(pagerank, fp=open('tmp/pagerank.json', 'w'), indent=2)
Fournit la recherche si
$ python3 K001_search_query.py
(ここで検索クエリを入力)exemple
$ python3 K001_search_query.py
ふわふわ
hurl weight refnum weight_norm url pagerank weight*refnum_score+pagerank
9276 36b736bccbbb95f2 0.000049 1 1.000000 https://bookwalker.jp/dea270c399-d1c5-470e-98bd-af9ba8d8464a/ 0.000146 1.009695
2783 108a6facdef1cf64 0.000037 0 0.758035 http://blog.livedoor.jp/usausa_life/archives/79482577.html 1.000000 0.995498
32712 c3ed3d4afd05fc43 0.000045 1 0.931093 https://item.fril.jp/bc7ae485a59de01d6ad428ee19671dfa 0.000038 0.940083
... Lorsque j'ai recherché "Rai-chan", j'ai pu le régler pour que les informations que je voulais soient à peu près au-dessus.
Pixiv n'est pas explicitement réglé sur la destination rampante, mais elle a été automatiquement acquise à la suite du robot de A après les liens et de la création d'un index.
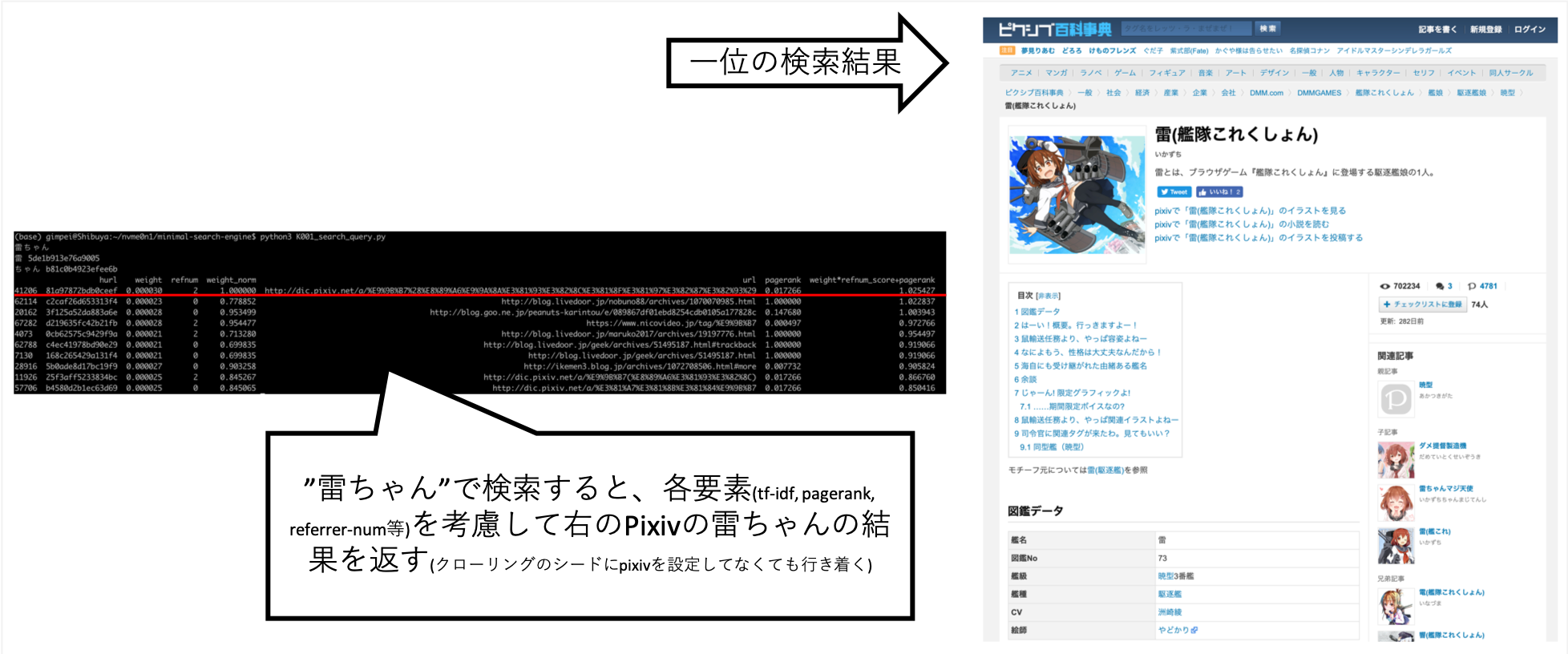
D'autres questions, telles que "Shokuro", ont rendu les résultats que je voulais.
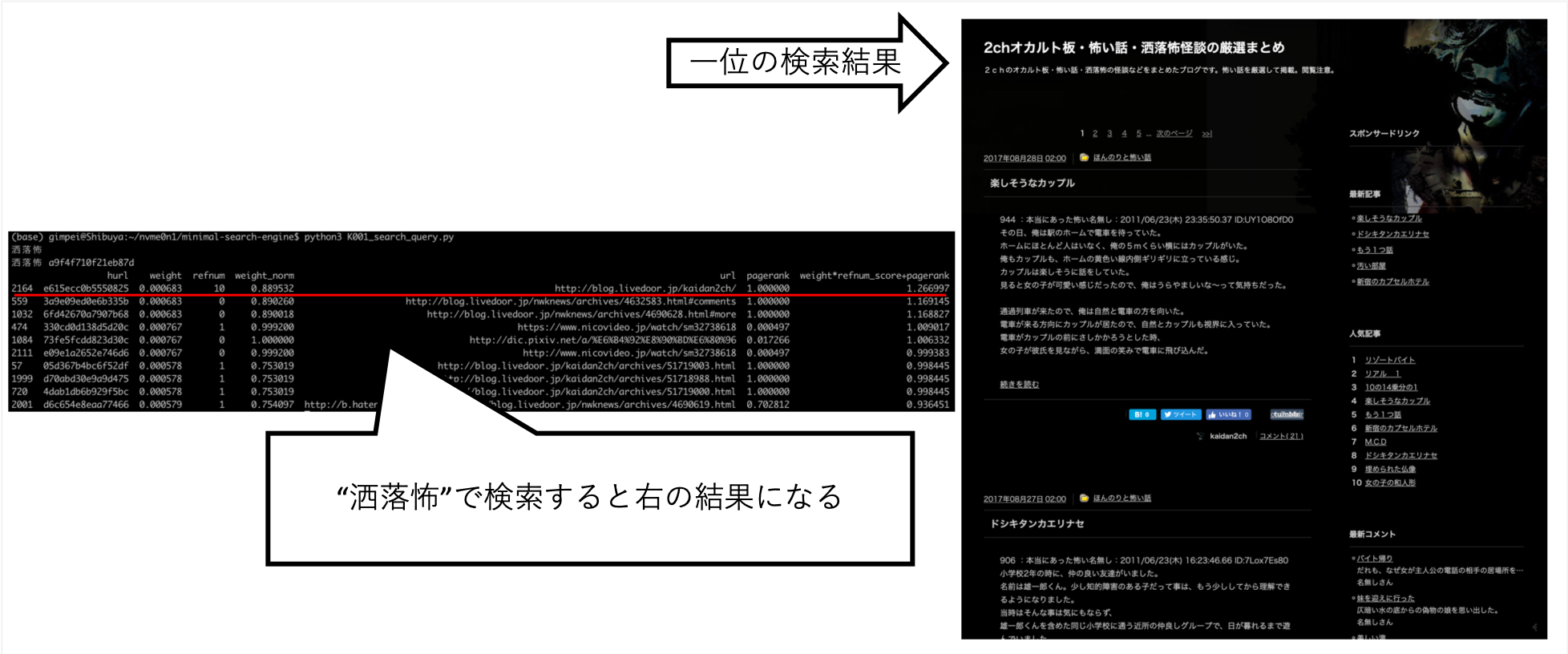
Après avoir essayé diverses choses à la main, j'ai trouvé que c'était le meilleur score. (Je suis les bonnes données)