minimal search engine
1.0.0
انظر الرمز على Github [https://github.com/gink03/minimal-search-engine:embed]
تحتاج إلى السفر حول مواقع مختلفة وسيكون للطلبات احتمال كبير في الفشل في استنتاج رموز الأحرف ، لذلك تحتاج إلى تثبيت nkf في بيئة Linux.
$ sudo apt install nkf
$ which nkf
/usr/bin/nkfسأشمل أيضًا MECAB
$ sudo apt install mecab libmecab-dev mecab-ipadic
$ sudo apt install mecab-ipadic-utf8
$ sudo apt install python-mecab
$ pip3 install mecab-python3
$ git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git
$ ./bin/install-mecab-ipadic-neologd -n
تثبيت التبعيات المتبقية
$ pip3 install -r requirements.txt في الأساس ، يمكنك إعادة إنتاج رمز GitHub عن طريق تشغيله بترتيب A On Linux مثل Ubuntu.
إذا كنت ترغب في تجربة الزحف (الكاشطات) ، فسوف تحصل على بلا حدود ، لذلك نفترض أنه يمكنك اتخاذ قرار بشأن البذور وإنهائها في وقت مناسب.
A. الزحف
B. تحليل HTML المزروع مع العنوان والوصف والجسم و HREF لتنسيق البيانات
C. إنشاء قاموس IDF
D. إنشاء بيانات TFIDF
واو. إنشاء مراسلات من عناوين URL و HREFs المنقولة (مبلغ ميزة مرجعية بسيطة)
G. عد أرقام غير مرجعية وإنشاء بيانات تدريب لـ Pagerank
H. قم بإنشاء فهرس تم نقله لأوزان URL و TFIDF
1. إنشاء جدول مراسلة بين عنوان URL HASHED وعنوان URL الفعلي
J. تعلم Pagerank
K. واجهة البحث
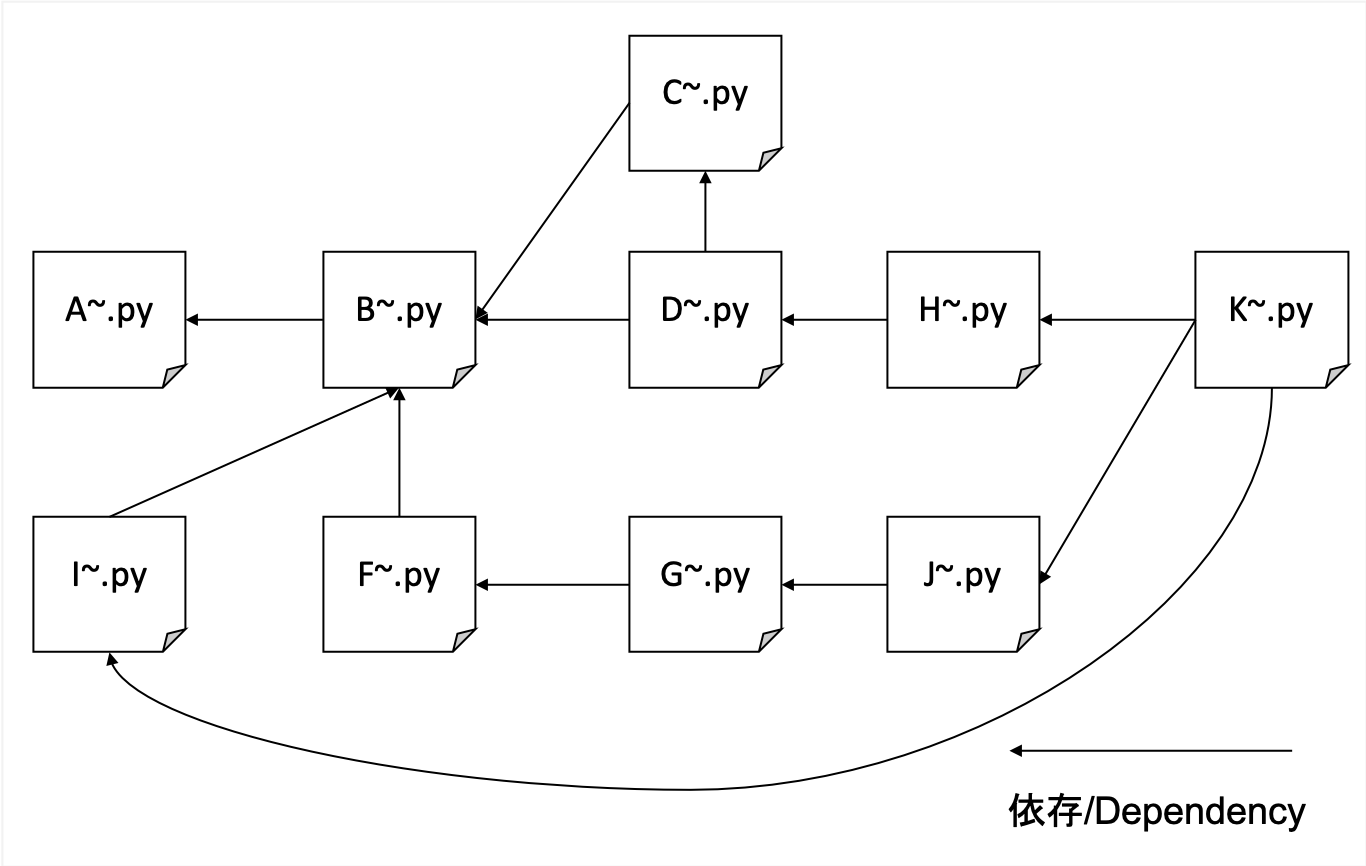
سنزحف بشكل شامل بغض النظر عن المجال المحدد. نستخدم موقع المدونة الخاص بنا كبذور ونتعمق أكثر مع تقدمنا ، دون الحد من مجالنا.
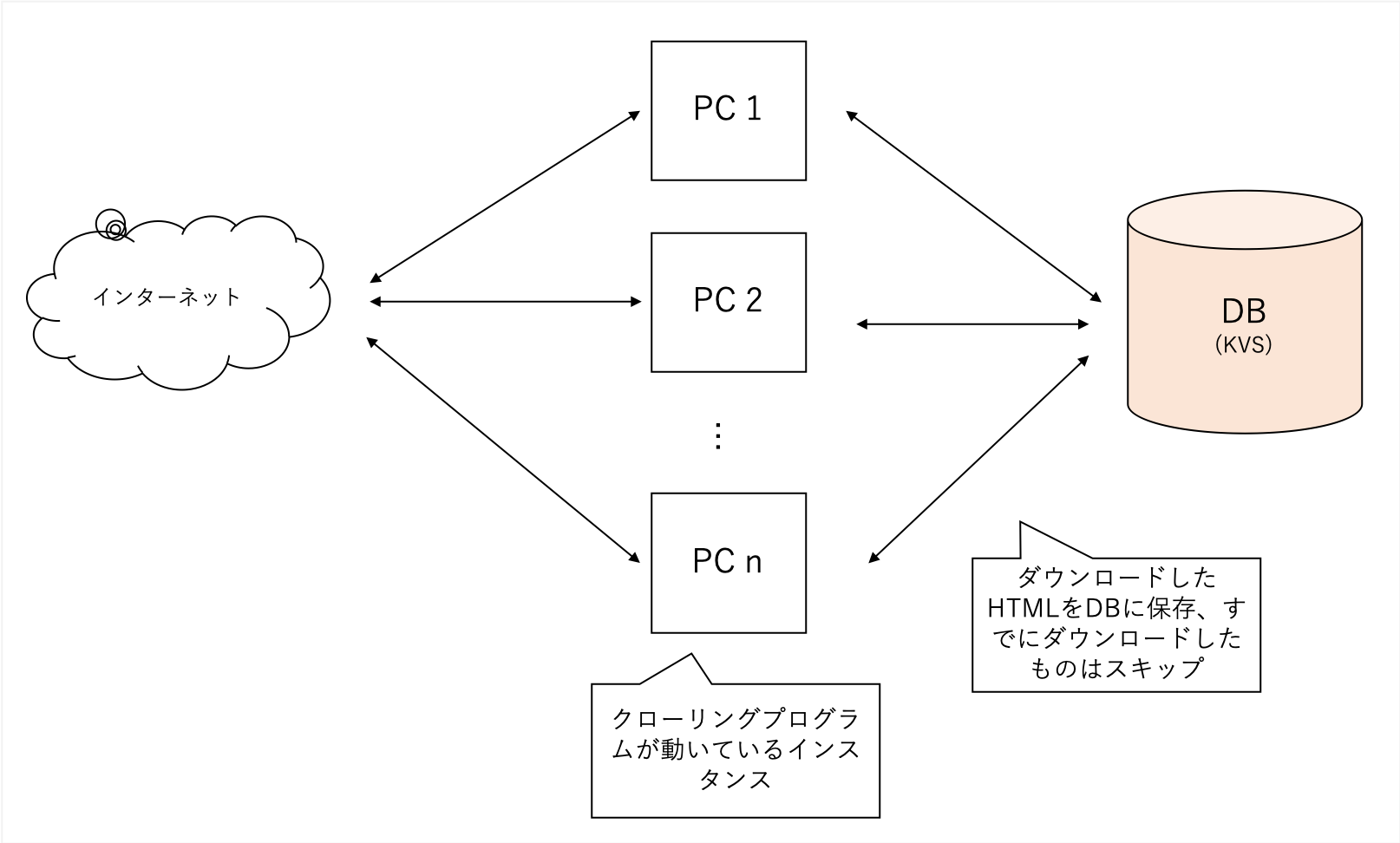
يزحف مجموعة متنوعة من المواقع ولكنه ثقيل للغاية ، لذلك أستخدم KVs اللامركزية الخاصة بي كقاعدة بيانات الواجهة الخلفية الخاصة بي. الملفات عرضة للفساد مع SQLLITE ، في حين أن LEVELDB لا يمكن أن يكون وصول واحد فقط.
البيانات التي تم الحصول عليها في A كبيرة جدًا ، وبالتالي فإن العملية في B تستخلص الميزات الرئيسية للبحث في TFIDF و "TITLE" و "Description" و "Body".
كما أنه يحلل جميع عناوين URL الخارجية التي تشير إليها الصفحة.
soup = BeautifulSoup ( html , features = 'lxml' )
for script in soup ([ 'script' , 'style' ]):
script . decompose ()
title = soup . title . text
description = soup . find ( 'head' ). find (
'meta' , { 'name' : 'description' })
if description is None :
description = ''
else :
description = description . get ( 'content' )
body = soup . find ( 'body' ). get_text ()
body = re . sub ( ' n ' , ' ' , body )
body = re . sub ( r's{1,}' , ' ' , body )يمكن معالجتها بسهولة باستخدام BeautifulSoup.
لتقليل أهمية الكلمات التي تحدث بشكل متكرر ، قم بحساب مقدار توثيق كل كلمة يتم الرجوع إليها.
استخدم البيانات من B و C لإكمالها كـ TFIDF
كل title description body له مستوى مختلف من الأهمية ، title : description : body = 1 : 1 : 0.001
تم التعامل معها.
# title desc weight = 1
text = arow . title + arow . description
text = sanitize ( text )
for term in m . parse ( text ). strip (). split ():
if term_freq . get ( term ) is None :
term_freq [ term ] = 0
term_freq [ term ] += 1
# title body = 0.001
text = arow . body
text = sanitize ( text )
for term in m . parse ( text ). strip (). split ():
if term_freq . get ( term ) is None :
term_freq [ term ] = 0
term_freq [ term ] += 0.001 # ここのweightを 0.001 のように小さい値を設定するكنت أعلم أنه كان من الشائع في الماضي أنه سيكون من الممكن SEO من خلال إعطاء روابط عناوين URL من أماكن مختلفة ، لذلك فعلت ذلك لمعرفة مقدار الإشارة إلى المراجع الخارجية.
استنادًا إلى البيانات التي تم إنشاؤها في F ، يمكنك تعلم أوزان العقد Pagerank باستخدام مكتبة تسمى NetworkX ، حتى تتمكن من إنشاء بيانات تدريب.
هذه مجموعة البيانات مطلوبة كمدخلات (تجزئة يمين هو مصدر الارتباط ، التجزئة اليسرى هي وجهة الارتباط)
d2a88da0ca550a8b 37a3d49657247e61
d2a88da0ca550a8b 6552c5a8ff9b2470
d2a88da0ca550a8b 3bf8e875fc951502
d2a88da0ca550a8b 935b17a90f5fb652
7996001a6e079a31 aabef32c9c8c4c13
d2a88da0ca550a8b e710f0bdab0ac500
d2a88da0ca550a8b a4bcfc4597f138c7
4cd5e7e2c81108be 7de6859b50d1eed2
refnum(被参照数) عمليات البحث مع أبسط الكلمات فقط weight(tfidf) نقوم بإنشاء فهرس يسمح لك بالبحث عن عناوين URLのハッシュمن الكلمات.
0010c40c7ed2c240 0.000029752 4
000ca0244339eb34 0.000029773 0
0017a9b7d83f5d24 0.000029763 0
00163826057db7c3 0.000029773 0
إذا احتفظت بعنوان URL كما هو الحال في الذاكرة ، فسيتم تجاوزه ، لذلك باستخدام SHA256 لنظره كقيمة تجزئة صغيرة باستخدام أول 16 حرفًا فقط ، يمكنك البحث عن مستندات مع الحد الأدنى من الاستخدام العملي حتى لمستندات من مليون طلب.
تعلم البيانات التي تم إنشاؤها في G وتعلم قيمة Pagerank في عنوان URL.
باستخدام NetworkX ، يمكنك التعلم برمز بسيط للغاية.
import networkx as nx
import json
G = nx.read_edgelist('tmp/to_pagerank.txt', nodetype=str)
# ノード数とエッジ数を出力
print(nx.number_of_nodes(G))
print(nx.number_of_edges(G))
print('start calc pagerank')
pagerank = nx.pagerank(G)
print('finish calc pagerank')
json.dump(pagerank, fp=open('tmp/pagerank.json', 'w'), indent=2)
يوفر البحث إذا
$ python3 K001_search_query.py
(ここで検索クエリを入力)مثال
$ python3 K001_search_query.py
ふわふわ
hurl weight refnum weight_norm url pagerank weight*refnum_score+pagerank
9276 36b736bccbbb95f2 0.000049 1 1.000000 https://bookwalker.jp/dea270c399-d1c5-470e-98bd-af9ba8d8464a/ 0.000146 1.009695
2783 108a6facdef1cf64 0.000037 0 0.758035 http://blog.livedoor.jp/usausa_life/archives/79482577.html 1.000000 0.995498
32712 c3ed3d4afd05fc43 0.000045 1 0.931093 https://item.fril.jp/bc7ae485a59de01d6ad428ee19671dfa 0.000038 0.940083
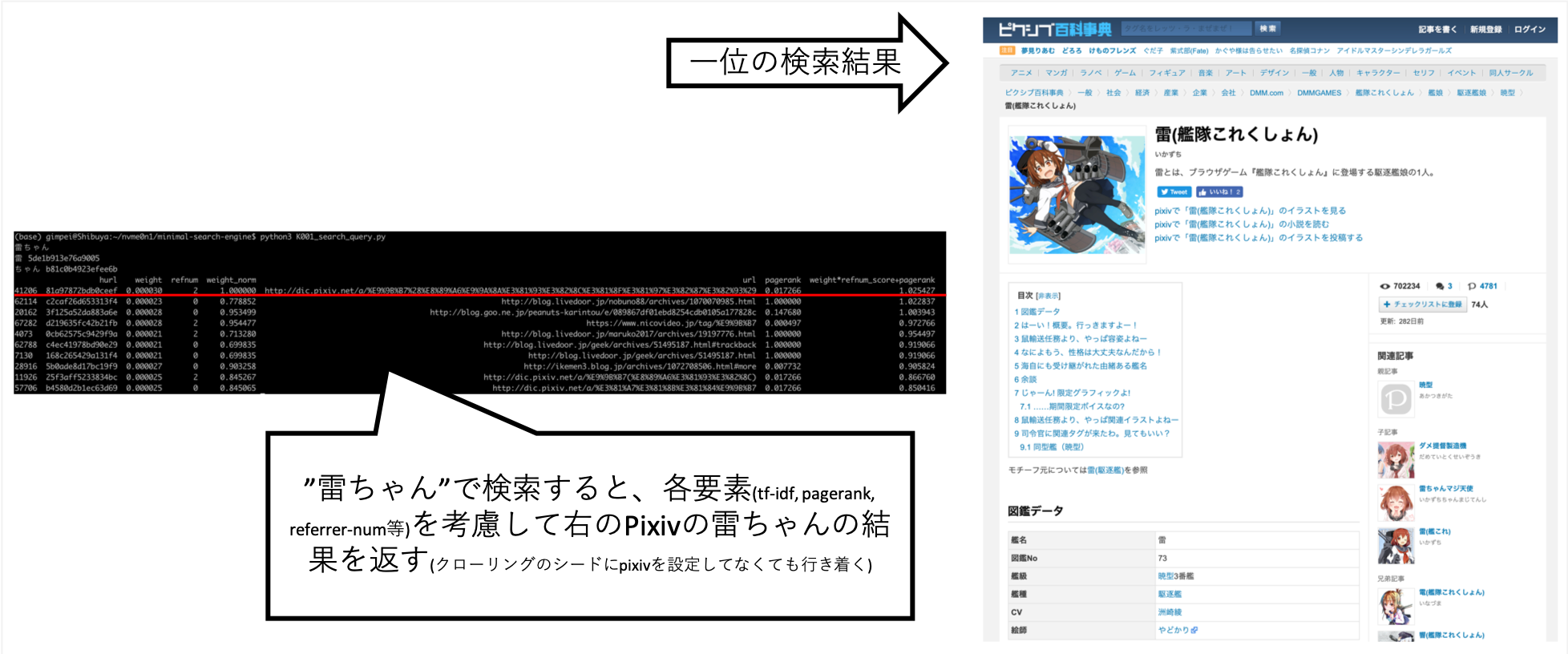
... عندما بحثت عن "Rai-Chan" ، تمكنت من ضبطها بحيث تكون المعلومات التي أردتها أعلى تقريبًا.
لم يتم تعيين Pixiv بشكل صريح على الوجهة الزحف ، ولكن تم الحصول عليها تلقائيًا نتيجة لزاحف A بعد الروابط وإنشاء فهرس.
استعلامات أخرى ، مثل "Shokuro" ، أعادت النتائج التي أردتها.
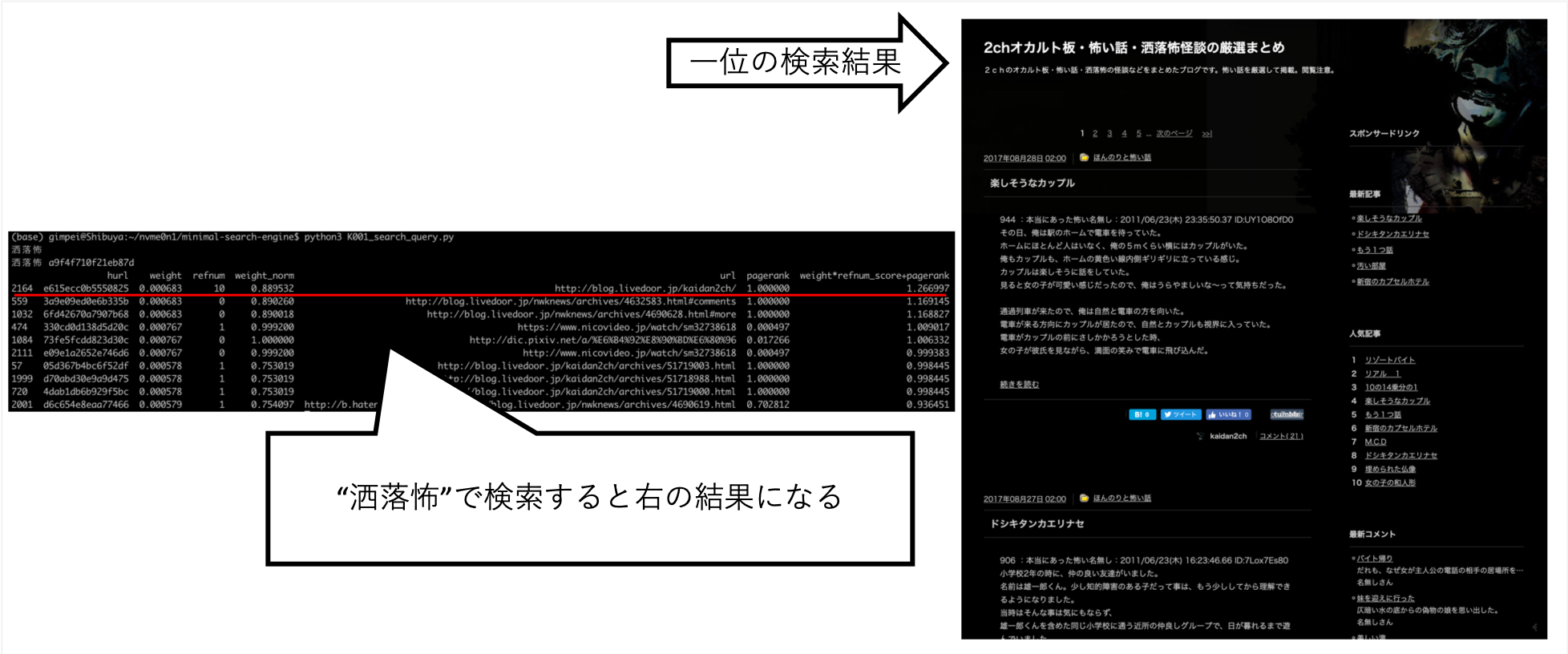
بعد تجربة أشياء مختلفة باليد ، وجدت أن هذا هو أفضل درجة. (أنا البيانات الصحيحة)