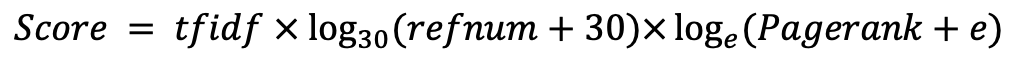minimal search engine
1.0.0
ดูรหัสบน gitHub [https://github.com/gink03/minimal-search-engine:embed]
คุณต้องเดินทางไปรอบ ๆ ไซต์ต่าง ๆ และคำขอจะมีความเป็นไปได้สูงที่จะล้มเหลวในการอนุมานรหัสอักขระดังนั้นคุณต้องติดตั้ง nkf ในสภาพแวดล้อม Linux
$ sudo apt install nkf
$ which nkf
/usr/bin/nkfฉันจะรวม mecab ด้วย
$ sudo apt install mecab libmecab-dev mecab-ipadic
$ sudo apt install mecab-ipadic-utf8
$ sudo apt install python-mecab
$ pip3 install mecab-python3
$ git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git
$ ./bin/install-mecab-ipadic-neologd -n
ติดตั้งการพึ่งพาที่เหลืออยู่
$ pip3 install -r requirements.txt โดยพื้นฐานแล้วคุณสามารถทำซ้ำรหัส GitHub ได้โดยเรียกใช้ตามลำดับของ Linux เช่น Ubuntu
หากคุณต้องการลองชุดรวบรวมข้อมูล (scrapers) คุณจะได้รับอย่างไม่สิ้นสุดดังนั้นเราคิดว่าคุณสามารถตัดสินใจเกี่ยวกับเมล็ดพันธุ์และทำมันให้เสร็จในเวลาที่เหมาะสม
A. คลาน
B. การแยกวิเคราะห์ HTML ที่รวบรวมไว้ด้วยชื่อเรื่องคำอธิบายร่างกายและ hrefs เพื่อจัดรูปแบบข้อมูล
C. การสร้างพจนานุกรม IDF
D. สร้างข้อมูล TFIDF
F. สร้างการโต้ตอบของ URL และ HREF ที่ถูกเปลี่ยน
G. การนับจำนวนที่ไม่อ้างอิงและการสร้างข้อมูลการฝึกอบรมสำหรับ PageRank
H. สร้างดัชนี transposed สำหรับ URL และ TFIDF น้ำหนัก
I. การสร้างตารางการติดต่อระหว่าง URL ที่แฮชและ URL จริง
J. การเรียนรู้ Pagerank
K. การค้นหาอินเทอร์เฟซ
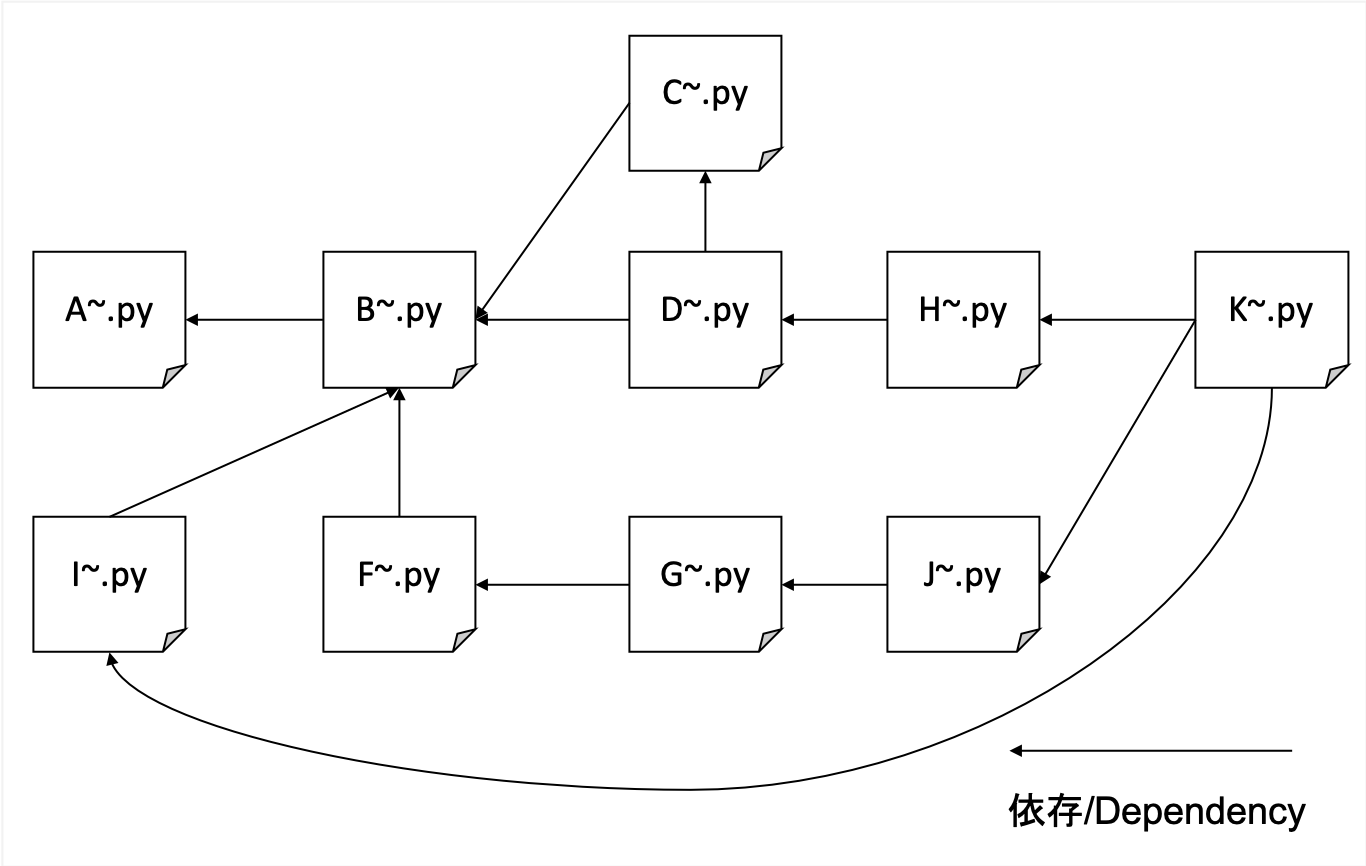
เราจะรวบรวมข้อมูลอย่างละเอียดโดยไม่คำนึงถึงโดเมนเฉพาะ เราใช้เว็บไซต์บล็อกของเราเป็นเมล็ดพันธุ์และลึกลงไปเมื่อเราไปโดยไม่ จำกัด โดเมนของเรา
มันรวบรวมข้อมูลหลากหลายไซต์ แต่หนักมากดังนั้นฉันจึงใช้ KVs กระจายอำนาจของตัวเองเป็นฐานข้อมูลแบ็กเอนด์ของฉัน ไฟล์มีแนวโน้มที่จะทุจริตด้วย Sqllite ในขณะที่ LevelDB สามารถเข้าถึงได้เพียงครั้งเดียว
ข้อมูลที่ได้รับใน A มีขนาดใหญ่เกินไปดังนั้นกระบวนการใน B จะแยกคุณสมบัติหลักของการค้นหาใน TFIDF, "title", "คำอธิบาย" และ "Body"
นอกจากนี้ยังวิเคราะห์ URL ภายนอกทั้งหมดที่หน้าอ้างถึง
soup = BeautifulSoup ( html , features = 'lxml' )
for script in soup ([ 'script' , 'style' ]):
script . decompose ()
title = soup . title . text
description = soup . find ( 'head' ). find (
'meta' , { 'name' : 'description' })
if description is None :
description = ''
else :
description = description . get ( 'content' )
body = soup . find ( 'body' ). get_text ()
body = re . sub ( ' n ' , ' ' , body )
body = re . sub ( r's{1,}' , ' ' , body )สามารถประมวลผลได้อย่างง่ายดายด้วยความสวยงาม
เพื่อลดความสำคัญของคำที่เกิดขึ้นบ่อยครั้งให้นับจำนวนเอกสารที่อ้างอิงแต่ละคำ
ใช้ข้อมูลจาก B และ C เพื่อให้เสร็จสมบูรณ์เป็น TFIDF
แต่ละ title description body มีระดับความสำคัญที่แตกต่างกันและ title : description : body = 1 : 1 : 0.001
มันได้รับการปฏิบัติเหมือน
# title desc weight = 1
text = arow . title + arow . description
text = sanitize ( text )
for term in m . parse ( text ). strip (). split ():
if term_freq . get ( term ) is None :
term_freq [ term ] = 0
term_freq [ term ] += 1
# title body = 0.001
text = arow . body
text = sanitize ( text )
for term in m . parse ( text ). strip (). split ():
if term_freq . get ( term ) is None :
term_freq [ term ] = 0
term_freq [ term ] += 0.001 # ここのweightを 0.001 のように小さい値を設定するฉันรู้ว่ามันเป็นเรื่องธรรมดาในอดีตที่จะเป็นไปได้ที่จะ SEO โดยให้ลิงก์ URL จากสถานที่ต่าง ๆ ดังนั้นฉันจึงทำสิ่งนี้เพื่อรู้ว่ามีการอ้างอิงจากภายนอกมากแค่ไหน
จากข้อมูลที่สร้างขึ้นใน F คุณสามารถเรียนรู้น้ำหนักของโหนด Pagerank โดยใช้ไลบรารีที่เรียกว่า NetworkX เพื่อให้คุณสามารถสร้างข้อมูลการฝึกอบรมได้
ชุดข้อมูลดังกล่าวเป็นที่ต้องการเป็นอินพุต (แฮชขวาเป็นแหล่งลิงค์, แฮชซ้ายคือปลายทางลิงก์)
d2a88da0ca550a8b 37a3d49657247e61
d2a88da0ca550a8b 6552c5a8ff9b2470
d2a88da0ca550a8b 3bf8e875fc951502
d2a88da0ca550a8b 935b17a90f5fb652
7996001a6e079a31 aabef32c9c8c4c13
d2a88da0ca550a8b e710f0bdab0ac500
d2a88da0ca550a8b a4bcfc4597f138c7
4cd5e7e2c81108be 7de6859b50d1eed2
เพื่อรองรับ weight(tfidf) ค้นหาด้วยคำที่ง่ายที่สุดเท่านั้นเรา refnum(被参照数) ดัชนีที่ช่วยให้คุณค้นหา URLのハッシュจากคำศัพท์
0010c40c7ed2c240 0.000029752 4
000ca0244339eb34 0.000029773 0
0017a9b7d83f5d24 0.000029763 0
00163826057db7c3 0.000029773 0
หากคุณเก็บ URL ไว้ในหน่วยความจำมันจะล้นดังนั้นโดยการใช้ SHA256 เพื่อพิจารณาว่าเป็นค่าแฮชเล็ก ๆ โดยใช้เพียง 16 ตัวอักษรแรกคุณสามารถค้นหาเอกสารที่มีการใช้งานน้อยที่สุดแม้สำหรับเอกสาร 1 ล้านคำสั่งซื้อ
เรียนรู้ข้อมูลที่สร้างขึ้นใน G และเรียนรู้ค่า Pagerank ใน URL
การใช้ NetworkX คุณสามารถเรียนรู้ด้วยรหัสง่าย ๆ
import networkx as nx
import json
G = nx.read_edgelist('tmp/to_pagerank.txt', nodetype=str)
# ノード数とエッジ数を出力
print(nx.number_of_nodes(G))
print(nx.number_of_edges(G))
print('start calc pagerank')
pagerank = nx.pagerank(G)
print('finish calc pagerank')
json.dump(pagerank, fp=open('tmp/pagerank.json', 'w'), indent=2)
ให้การค้นหาว่า
$ python3 K001_search_query.py
(ここで検索クエリを入力)ตัวอย่าง
$ python3 K001_search_query.py
ふわふわ
hurl weight refnum weight_norm url pagerank weight*refnum_score+pagerank
9276 36b736bccbbb95f2 0.000049 1 1.000000 https://bookwalker.jp/dea270c399-d1c5-470e-98bd-af9ba8d8464a/ 0.000146 1.009695
2783 108a6facdef1cf64 0.000037 0 0.758035 http://blog.livedoor.jp/usausa_life/archives/79482577.html 1.000000 0.995498
32712 c3ed3d4afd05fc43 0.000045 1 0.931093 https://item.fril.jp/bc7ae485a59de01d6ad428ee19671dfa 0.000038 0.940083
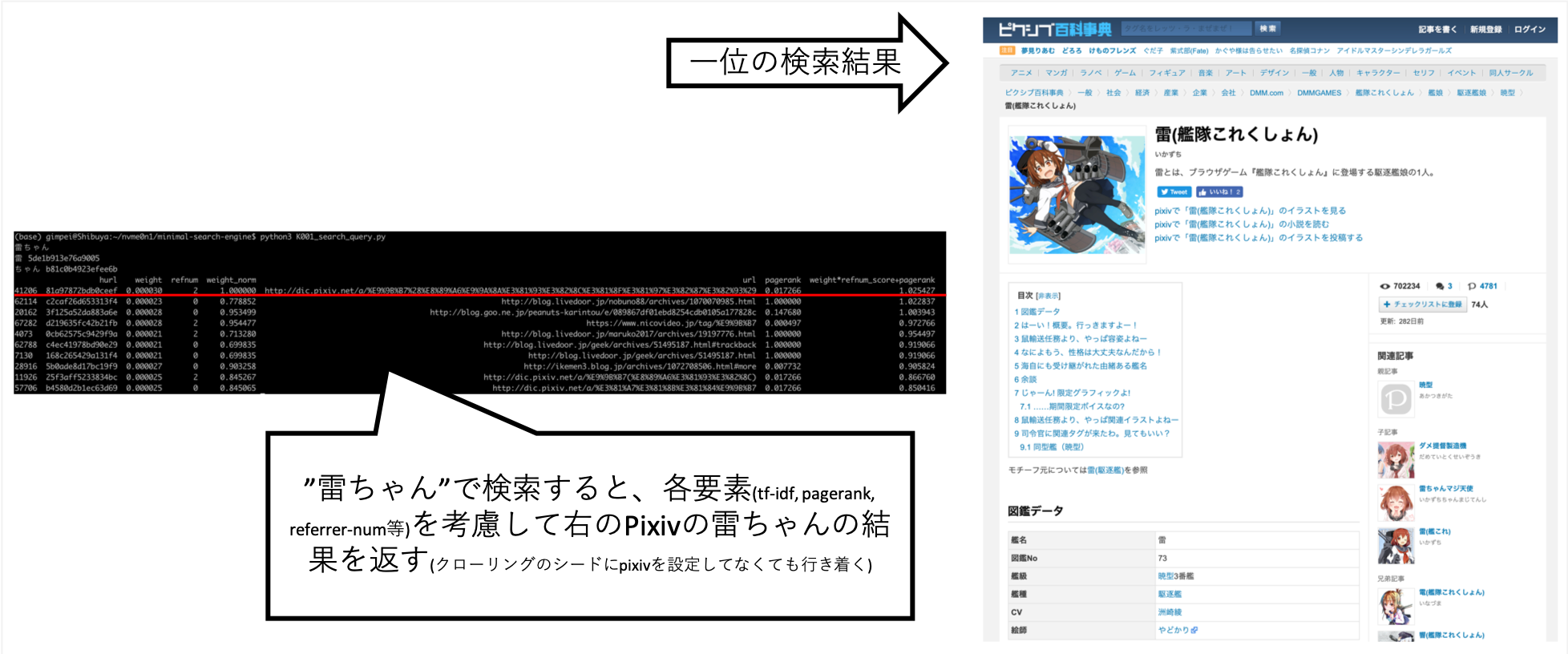
... เมื่อฉันค้นหา "Rai-chan" ฉันสามารถปรับแต่งได้เพื่อให้ข้อมูลที่ฉันต้องการนั้นอยู่เหนือ
Pixiv ไม่ได้ถูกตั้งค่าอย่างชัดเจนไปยังปลายทางการรวบรวมข้อมูล แต่ได้รับโดยอัตโนมัติอันเป็นผลมาจากการรวบรวมข้อมูลของ A ตามลิงค์และสร้างดัชนี
คำค้นหาอื่น ๆ เช่น "Shokuro" ได้ส่งคืนผลลัพธ์ที่ฉันต้องการ
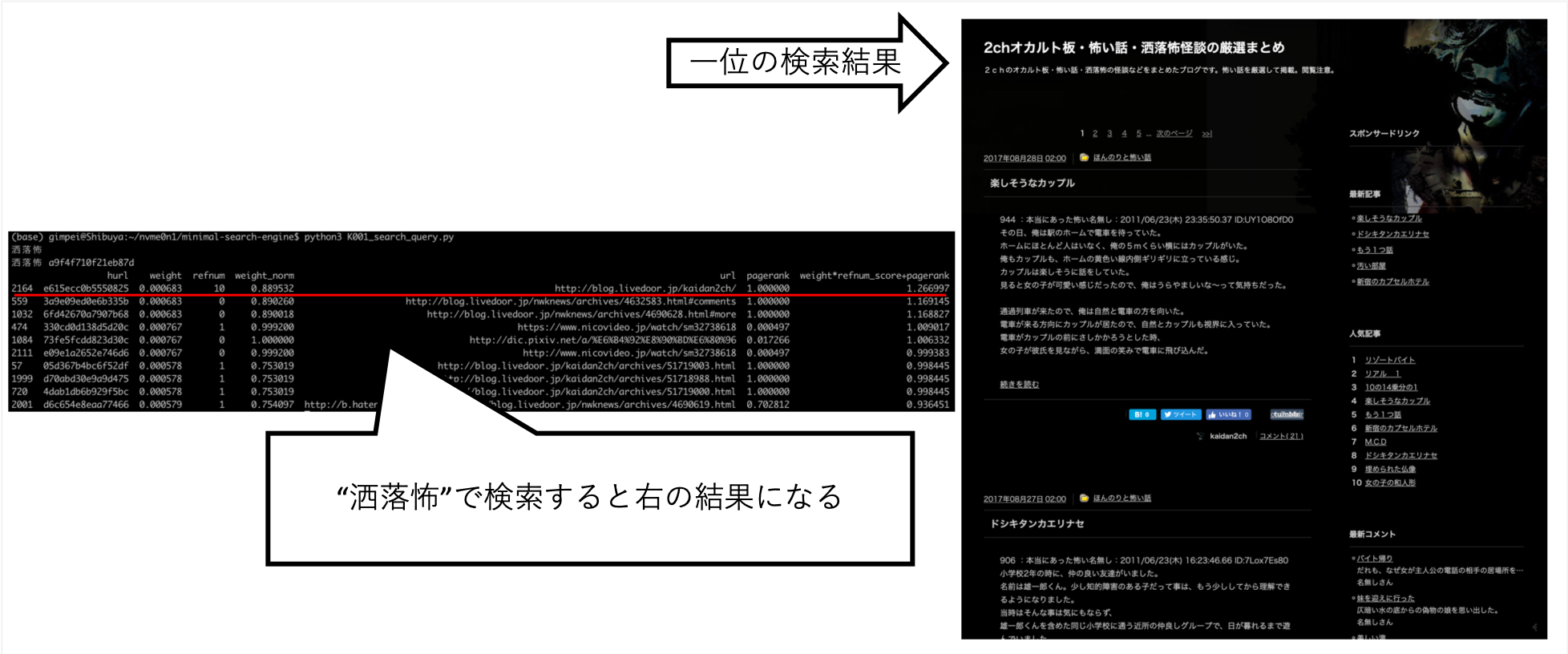
หลังจากลองทำสิ่งต่าง ๆ ด้วยมือฉันพบว่านี่เป็นคะแนนที่ดีที่สุด (ฉันเป็นข้อมูลที่ถูกต้อง)