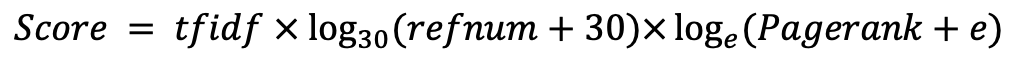minimal search engine
1.0.0
github [https://github.com/gink03/minimal-search-engine:embed]의 코드를 참조하십시오.
다양한 사이트를 여행해야하며 요청은 문자 코드를 추론하지 못할 확률이 높으므로 Linux 환경에 nkf 설치해야합니다.
$ sudo apt install nkf
$ which nkf
/usr/bin/nkf나는 또한 mecab도 포함시킬 것이다
$ sudo apt install mecab libmecab-dev mecab-ipadic
$ sudo apt install mecab-ipadic-utf8
$ sudo apt install python-mecab
$ pip3 install mecab-python3
$ git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git
$ ./bin/install-mecab-ipadic-neologd -n
나머지 종속성을 설치하십시오
$ pip3 install -r requirements.txt 기본적으로 Github 코드는 Ubuntu와 같은 Linux의 순서대로 실행하여 재현 할 수 있습니다.
크롤러 (스크레이퍼)를 시험해 보려면 무한히가 될 것이므로 씨앗을 결정하고 적절한 시간에 마무리 할 수 있다고 가정합니다.
A. 크롤링
B. 크롤링 된 HTML을 제목, 설명, 본문 및 HREF로 구문 분석하여 데이터를 형식화합니다.
C. IDF 사전 생성
D. TFIDF 데이터를 만듭니다
F. 파괴 된 URL 및 HREFS의 서신 생성 (간단한 참조 기능 금액)
G. 비 참조 번호 계산 및 PageRank 용 교육 데이터 작성
H. URL 및 TFIDF 가중치에 대한 변형 인덱스 생성
I. 해시 URL과 실제 URL 사이의 서신 테이블 작성
J. 학습 PageRank
K. 검색 인터페이스
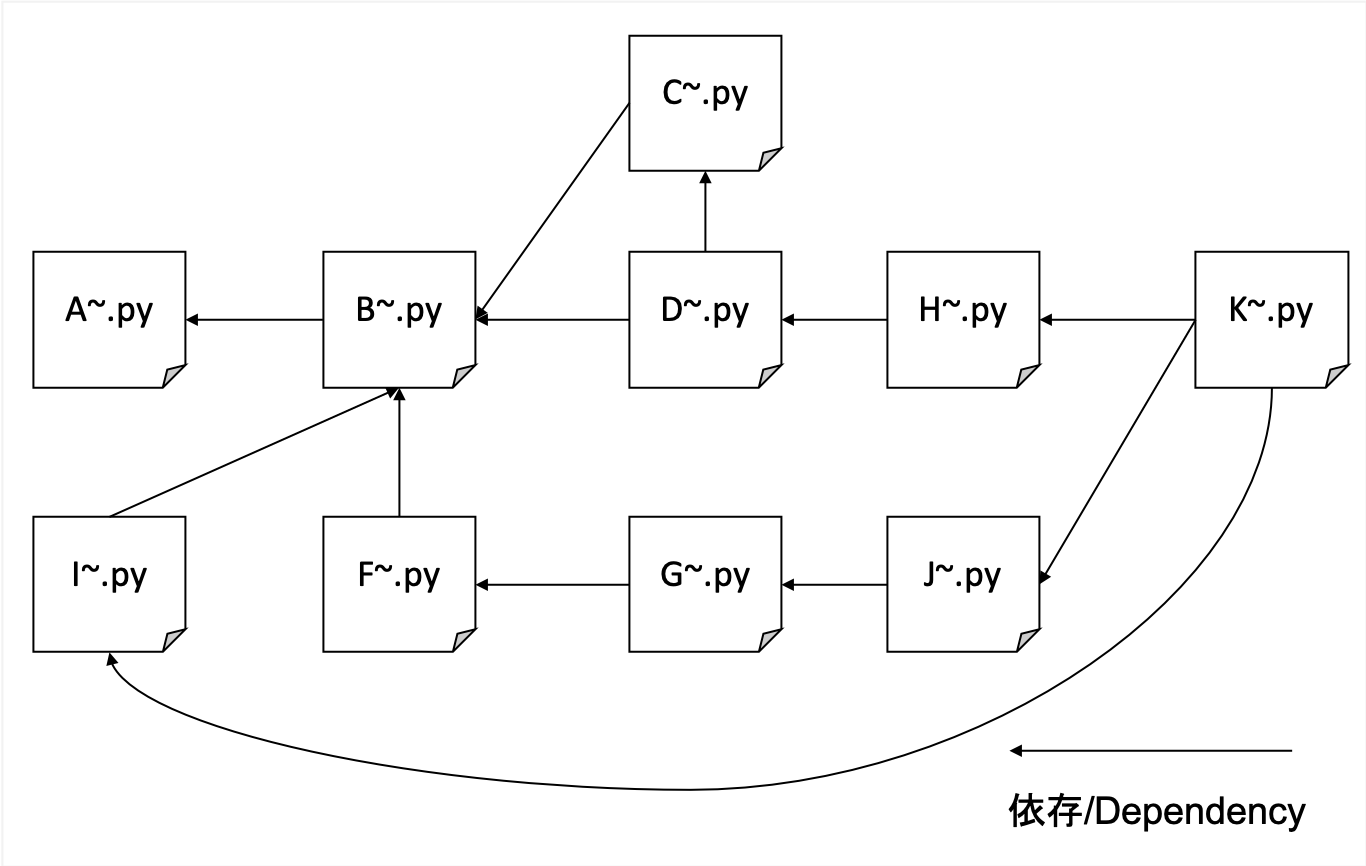
우리는 특정 도메인에 관계없이 포괄적으로 기어 올 것입니다. 우리는 블로그 사이트를 씨앗으로 사용하고 도메인을 제한하지 않고 갈 때 더 깊이갑니다.
그것은 다양한 사이트를 기어 다니지 만 매우 무겁기 때문에 내 자신의 분산 된 KV를 내 백엔드 데이터베이스로 사용합니다. 파일은 sqllite로 손상되기 쉬우 며 LevelDB는 단일 액세스 일 수 있습니다.
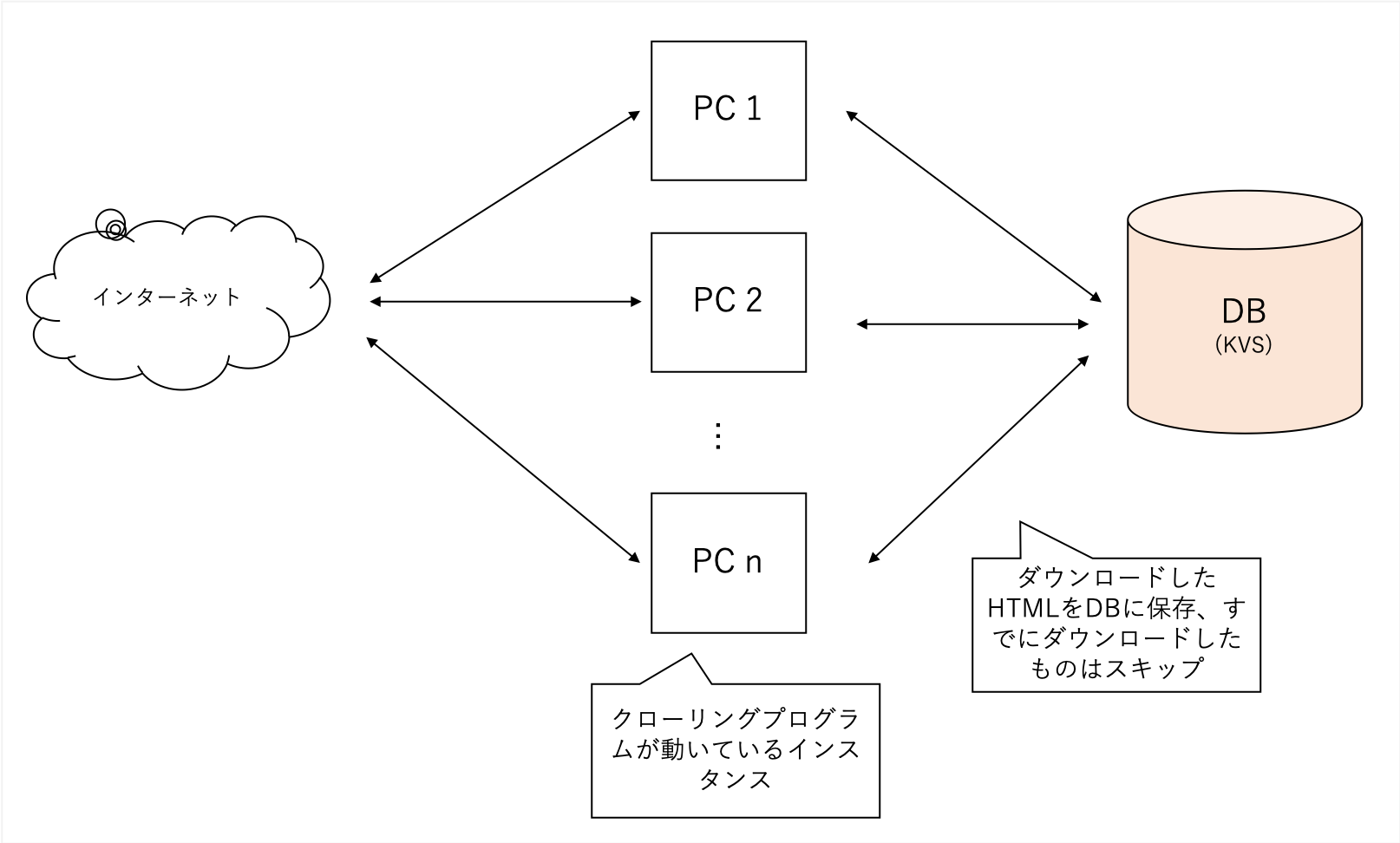
A에서 얻은 데이터가 너무 커서 B의 프로세스는 TFIDF, "Title", "Description"및 "Body"에서 검색의 주요 기능을 추출합니다.
또한 페이지가 참조하는 모든 외부 URL을 구문 분석합니다.
soup = BeautifulSoup ( html , features = 'lxml' )
for script in soup ([ 'script' , 'style' ]):
script . decompose ()
title = soup . title . text
description = soup . find ( 'head' ). find (
'meta' , { 'name' : 'description' })
if description is None :
description = ''
else :
description = description . get ( 'content' )
body = soup . find ( 'body' ). get_text ()
body = re . sub ( ' n ' , ' ' , body )
body = re . sub ( r's{1,}' , ' ' , body )BeautifulSoup으로 쉽게 처리 할 수 있습니다.
자주 발생하는 단어의 중요성을 줄이려면 각 단어를 얼마나 많이 참조하십시오.
B와 C의 데이터를 사용하여 TFIDF로 완료하십시오.
각 title description body 중요도 수준이 다르며 title : description : body = 1 : 1 : 0.001
그것은 다음과 같이 취급되었습니다.
# title desc weight = 1
text = arow . title + arow . description
text = sanitize ( text )
for term in m . parse ( text ). strip (). split ():
if term_freq . get ( term ) is None :
term_freq [ term ] = 0
term_freq [ term ] += 1
# title body = 0.001
text = arow . body
text = sanitize ( text )
for term in m . parse ( text ). strip (). split ():
if term_freq . get ( term ) is None :
term_freq [ term ] = 0
term_freq [ term ] += 0.001 # ここのweightを 0.001 のように小さい値を設定する나는 과거에 다양한 장소에서 URL 링크를 제공함으로써 SEO가 가능할 것이라는 것이 일반적이라는 것을 알았으므로, 외부 참조가 얼마나 많은지를 알기 위해이 작업을 수행했습니다.
F로 만든 데이터를 기반으로 NetworkX라는 라이브러리를 사용하여 PageRank 노드의 가중치를 배울 수 있으므로 교육 데이터를 만들 수 있습니다.
이러한 데이터 세트는 입력으로 요구됩니다 (오른쪽 해시는 링크 소스, 왼쪽 해시는 링크 대상입니다).
d2a88da0ca550a8b 37a3d49657247e61
d2a88da0ca550a8b 6552c5a8ff9b2470
d2a88da0ca550a8b 3bf8e875fc951502
d2a88da0ca550a8b 935b17a90f5fb652
7996001a6e079a31 aabef32c9c8c4c13
d2a88da0ca550a8b e710f0bdab0ac500
d2a88da0ca550a8b a4bcfc4597f138c7
4cd5e7e2c81108be 7de6859b50d1eed2
가장 간단한 단어만으로 검색 weight(tfidf) refnum(被参照数) 하기 위해 단어에서 URLのハッシュ을 검색 할 수있는 색인을 만듭니다.
0010c40c7ed2c240 0.000029752 4
000ca0244339eb34 0.000029773 0
0017a9b7d83f5d24 0.000029763 0
00163826057db7c3 0.000029773 0
URL을 메모리에 보관하면 오버플로를 유지하면 SHA256을 사용하여 처음 16 자만 사용하여 작은 해시 값으로 간주하면 1 백만 주문 문서의 경우에도 최소한의 실제 사용으로 문서를 검색 할 수 있습니다.
G에서 생성 된 데이터를 배우고 URL에서 PagerAnk 값을 배우십시오.
NetworkX를 사용하면 매우 간단한 코드로 배울 수 있습니다.
import networkx as nx
import json
G = nx.read_edgelist('tmp/to_pagerank.txt', nodetype=str)
# ノード数とエッジ数を出力
print(nx.number_of_nodes(G))
print(nx.number_of_edges(G))
print('start calc pagerank')
pagerank = nx.pagerank(G)
print('finish calc pagerank')
json.dump(pagerank, fp=open('tmp/pagerank.json', 'w'), indent=2)
검색을 제공합니다
$ python3 K001_search_query.py
(ここで検索クエリを入力)예
$ python3 K001_search_query.py
ふわふわ
hurl weight refnum weight_norm url pagerank weight*refnum_score+pagerank
9276 36b736bccbbb95f2 0.000049 1 1.000000 https://bookwalker.jp/dea270c399-d1c5-470e-98bd-af9ba8d8464a/ 0.000146 1.009695
2783 108a6facdef1cf64 0.000037 0 0.758035 http://blog.livedoor.jp/usausa_life/archives/79482577.html 1.000000 0.995498
32712 c3ed3d4afd05fc43 0.000045 1 0.931093 https://item.fril.jp/bc7ae485a59de01d6ad428ee19671dfa 0.000038 0.940083
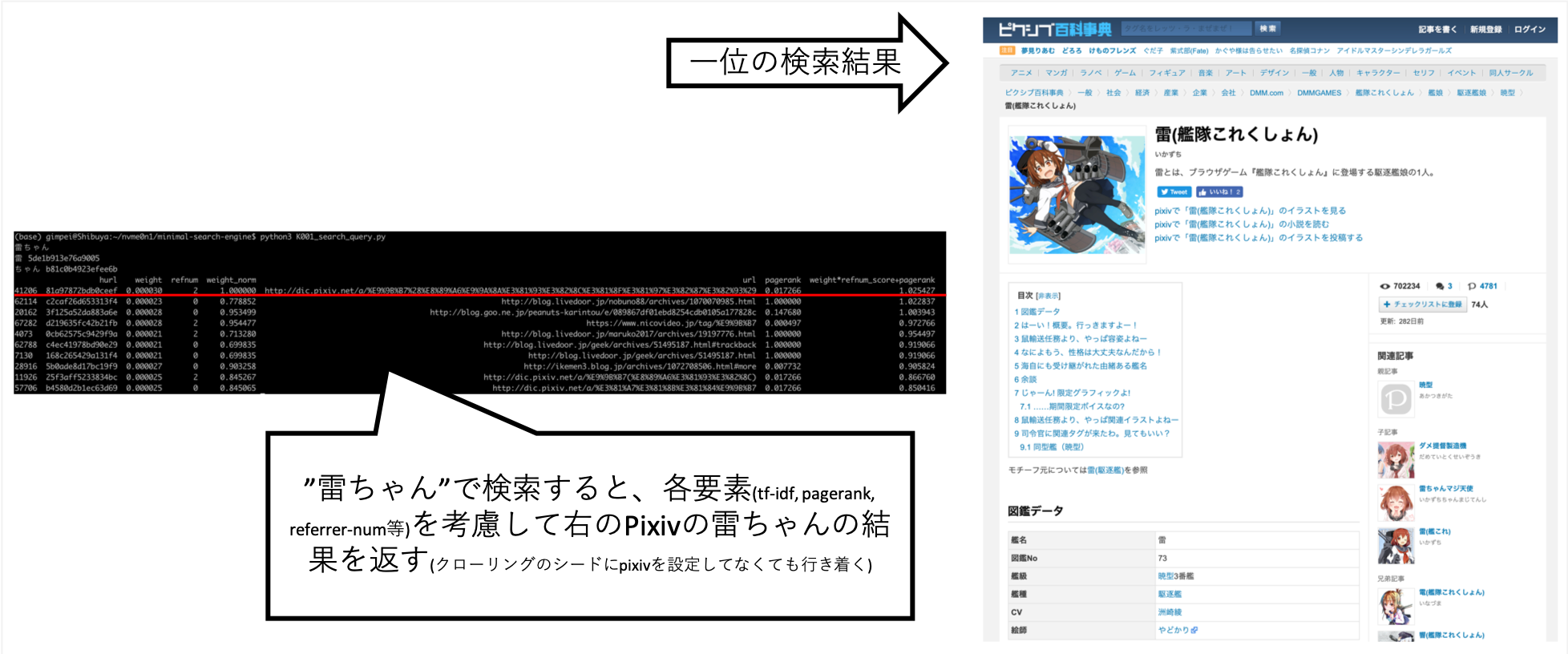
... "Rai-chan"을 검색했을 때, 내가 원하는 정보가 거의 위에 있도록 조정할 수있었습니다.
Pixiv는 크롤링 목적지로 명시 적으로 설정되지는 않지만 A의 크롤러의 결과로 링크를 따르고 인덱스 생성으로 자동으로 획득되었습니다.
"Shokuro"와 같은 다른 쿼리는 내가 원하는 결과를 반환했습니다.
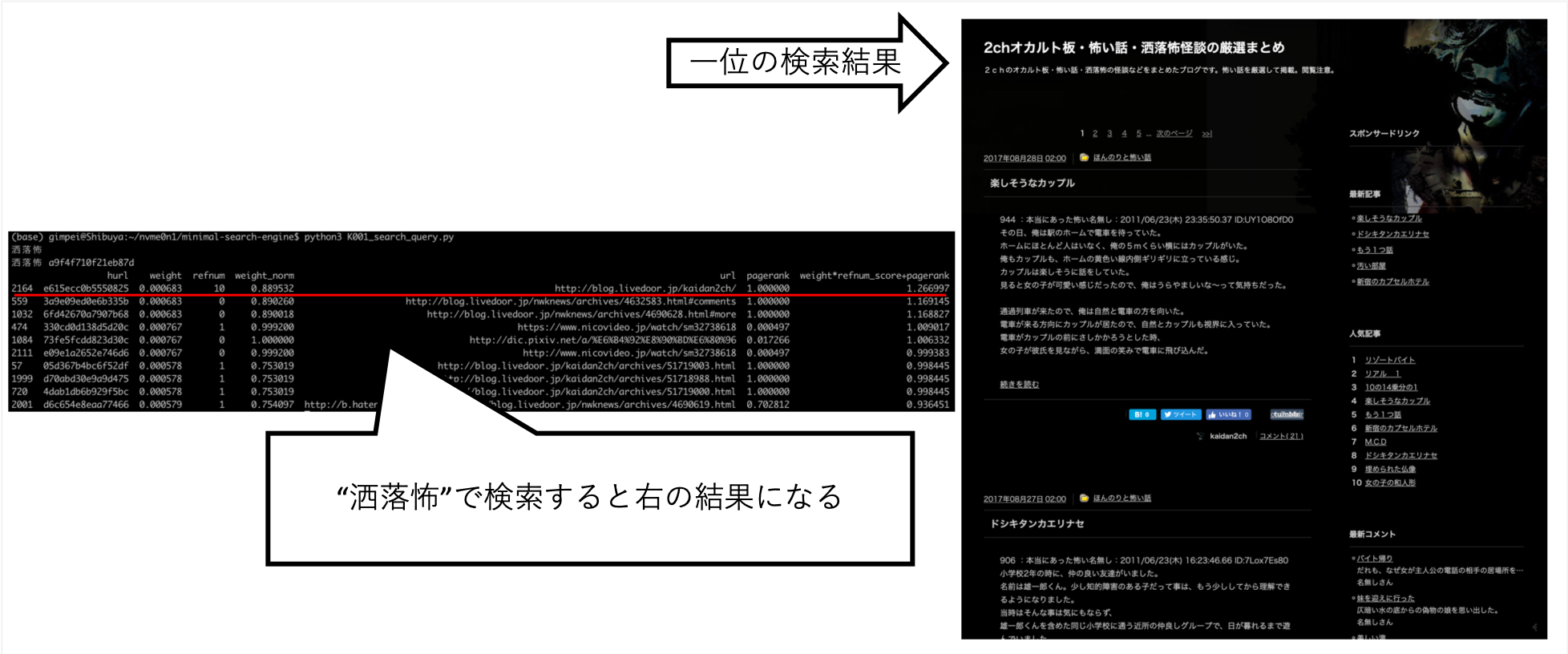
손으로 다양한 것을 시도한 후, 나는 이것이 최고의 점수라는 것을 알았습니다. (나는 올바른 데이터입니다)