amazon sagemaker personalized generative ai
1.0.0
Proyek ini memungkinkan penyesuaian dan penyajian model AI generatif yang hiper-personalisasi pada skala pada AWS. Kami memenuhi kebutuhan penyedia SaaS dan startup B2C yang ingin skala dengan cepat. Kami mengusulkan arsitektur yang memanfaatkan Amazon Sagemaker untuk merampingkan fine dan penyebaran model AI, memungkinkan pengembangan yang lebih cepat, peningkatan kualitas layanan, dan efektivitas biaya; dan titik akhir multi-model (MME) untuk hosting real-time, yang memberikan cara yang dapat diskalakan, latensi rendah, dan hemat biaya untuk menggunakan ribuan model pembelajaran mendalam di balik satu titik akhir. Untuk detail lebih lanjut, silakan merujuk ke posting blog ini.
npm install -g aws-cdkhttps://python-poetry.org/docs/#installationPuisi Instal Linux, MacOS, Windows (WSL)
curl -sSL https://install.python-poetry.org | python3 -Pasang dependensi dengan puisi
poetry install
Setup python env di shell
poetry shell
Pada titik ini Anda sekarang dapat mensintesis templat CloudFormation untuk kode ini.
$ cdk synth
Untuk menambahkan dependensi tambahan, misalnya perpustakaan CDK lainnya, cukup gunakan poetry add yourpackage
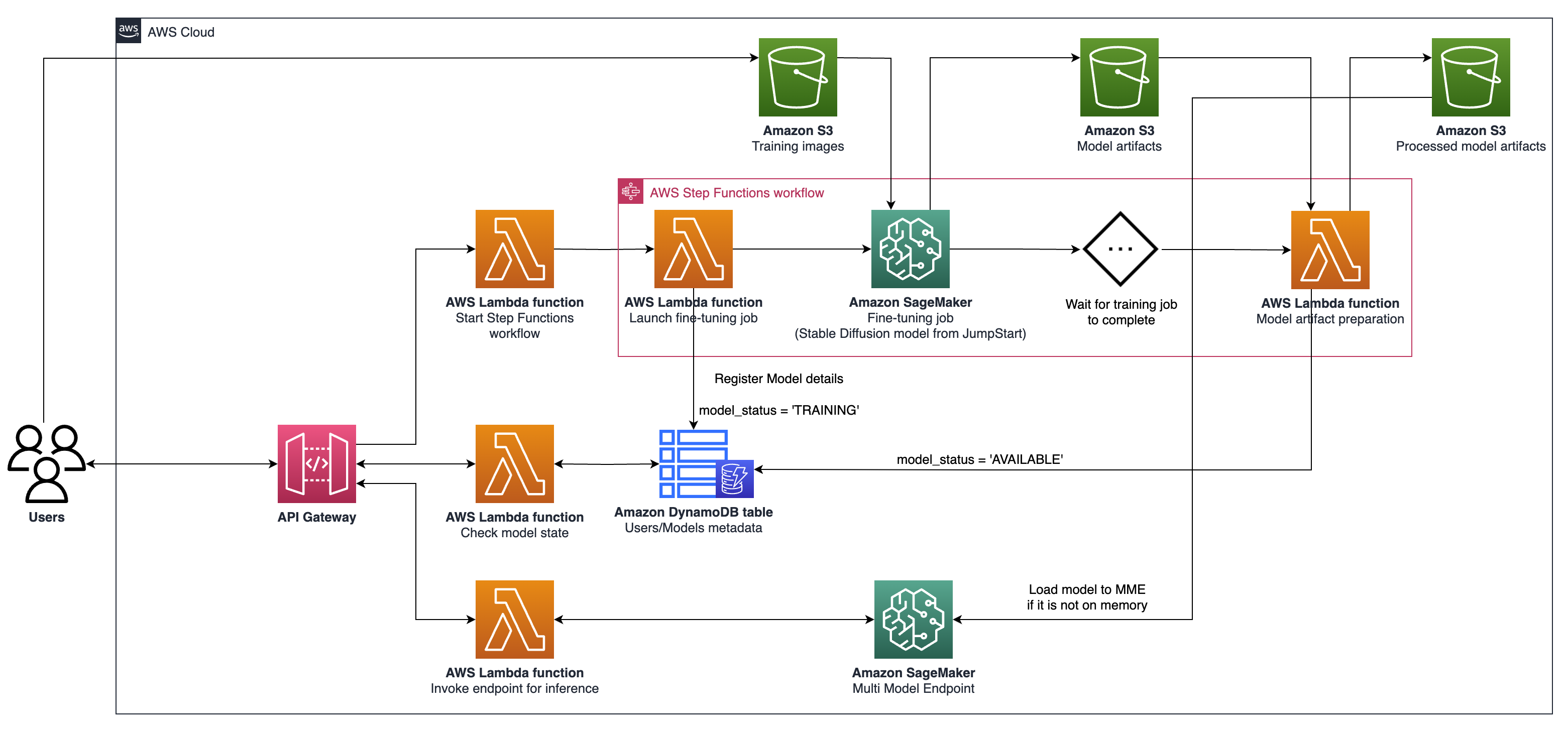
cdk ls Semua tumpukan di aplikasicdk synth memancarkan template Cloudformation yang disintesiscdk deploy menggunakan tumpukan ini ke akun/wilayah AWS default Andacdk diff Compare Deployed Stack dengan keadaan saat inicdk docs Buka Dokumentasi CDK Arsitektur yang dijelaskan melibatkan sistem untuk kasus penggunaan AI generatif, dengan fokus pada pembuatan teks-ke-gambar yang dipersonalisasi sebagai contoh, menggunakan difusi stabil V2-1. Komponen utama dari arsitektur ini adalah sebagai berikut:
Pelatihan Sagemaker dan Hosting API : API ini menyediakan pekerjaan pelatihan yang dikelola penuh dan kemampuan penyebaran model. Mereka memungkinkan tim yang bergerak cepat untuk lebih berkonsentrasi pada fitur dan diferensiasi produk. Pekerjaan Pelatihan Sagemaker, yang mengikuti paradigma "peluncuran dan laba", cocok untuk pekerjaan fine-tuning model konkuren transien selama onboarding pengguna.
Hosting yang diaktifkan GPU : Sagemaker mendukung opsi hosting yang mendukung GPU untuk menggunakan model pembelajaran mendalam pada skala. Ini termasuk integrasi server inferensi NVIDIA Triton ke dalam ekosistem Sagemaker. Sagemaker juga menawarkan dukungan GPU untuk titik akhir multi-model (MME), yang memungkinkan penyebaran ribuan model pembelajaran mendalam di balik titik akhir tunggal, memastikan skalabilitas, latensi rendah, dan efektivitas biaya.
Tingkat Infrastruktur : Pada tingkat infrastruktur, arsitektur bergantung pada opsi komputasi terbaik di kelasnya, seperti tipe instance G5, yang dilengkapi dengan NVIDIA A10G Tensor Core GPU (unik untuk AWS). Jenis instance ini menawarkan rasio kinerja harga yang menguntungkan untuk pelatihan model dan hosting, memberikan daya komputasi yang efisien per dolar yang dihabiskan.
Arsitektur ini sangat cocok untuk kasus penggunaan pembuatan teks-ke-gambar. Ini membagi alur kerja solusi menjadi dua fase utama:
Fase A (User Onboarding) : Dalam fase ini, pengguna dapat meminta pembuatan satu atau lebih model kustom yang disesuaikan. Mereka dapat memeriksa status ketersediaan model mereka setiap saat, untuk mengetahui kapan pelatihan telah selesai.
Fase B (Inferensi On-Demand) : Setelah menyempurnakan, model siap untuk pembuatan gambar real-time berdasarkan permintaan oleh pengguna akhir.
Untuk berinteraksi dengan gateway API Anda yang digunakan menggunakan AWS CDK, ikuti langkah -langkah ini:
Buka tukang pos dan impor koleksi dari documentation folder.
Atur metode permintaan (misalnya, dapatkan, posting) dan masukkan titik akhir URL API Gateway.
Jika API Anda memerlukan otentikasi, konfigurasikan header atau token yang diperlukan.
Tambahkan parameter atau data permintaan yang diperlukan.
Klik "Kirim" untuk mengajukan permintaan dan menerima tanggapan.
Catatan: Pastikan sumber daya AWS dan API Gateway Anda dikonfigurasi dengan benar untuk menangani permintaan.


