amazon sagemaker personalized generative ai
1.0.0
Este proyecto permite el ajuste y el servicio de modelos AI generativos hiperpersonalizados a escala en AWS. Abordamos las necesidades de los proveedores de SaaS y las nuevas empresas B2C que buscan escalar rápidamente. Proponemos una arquitectura que aproveche a Amazon Sagemaker para racionalizar el modelo de AI ajustado y despliegue, permitiendo un desarrollo más rápido, mejor calidad del servicio y rentabilidad; y puntos finales multimodelo (MME) para el alojamiento en tiempo real, que proporcionan una forma escalable, de baja latencia y rentable de desplegar miles de modelos de aprendizaje profundo detrás de un solo punto final. Para más detalles, consulte esta publicación de blog.
npm install -g aws-cdkhttps://python-poetry.org/docs/#installationPoetry Instalar Linux, MacOS, Windows (WSL)
curl -sSL https://install.python-poetry.org | python3 -Instalar dependencias con poesía
poetry install
Configurar python env en shell
poetry shell
En este punto, ahora puede sintetizar la plantilla de CloudFormation para este código.
$ cdk synth
Para agregar dependencias adicionales, por ejemplo, otras bibliotecas de CDK, solo use poetry add yourpackage
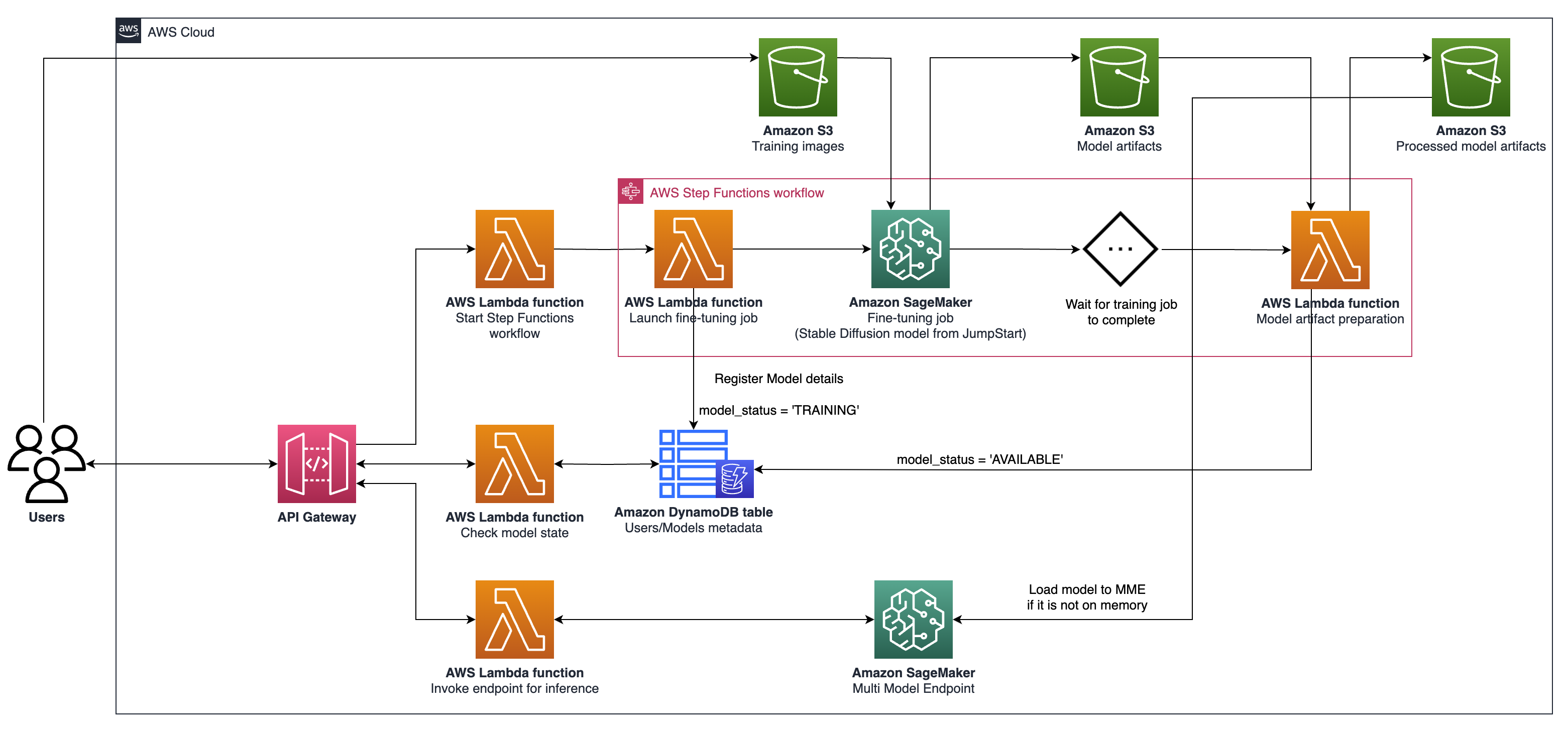
cdk ls Lista todas las pilas en la aplicacióncdk synth emite la plantilla de formación de nubes sintetizadacdk deploy implementar esta pila en su cuenta/región predeterminada de AWScdk diff Compare la pila implementada con el estado actualcdk docs Open Documentation CDK La arquitectura descrita implica un sistema para casos generativos de uso de IA, con un enfoque en la generación personalizada de texto a imagen como ejemplo, utilizando la difusión estable V2-1. Los componentes clave de esta arquitectura son los siguientes:
API de capacitación y alojamiento de Sagemaker : estas API proporcionan trabajos de capacitación totalmente administrados y capacidades de implementación de modelos. Permiten que los equipos de movimiento rápido se concentren más en las características del producto y la diferenciación. Los trabajos de capacitación de Sagemaker, que siguen a un paradigma de "lanzamiento y olvido", son adecuados para trabajos de ajuste finos concurrentes transitorios durante la incorporación del usuario.
Alojamiento habilitado para GPU : Sagemaker admite opciones de alojamiento habilitadas para GPU para implementar modelos de aprendizaje profundo a escala. Esto incluye la integración del servidor de inferencia Nvidia Triton en el ecosistema de Sagemaker. Sagemaker también ofrece soporte de GPU para puntos finales de múltiples modelos (MME), que permiten el despliegue de miles de modelos de aprendizaje profundo detrás de un solo punto final, asegurando la escalabilidad, la baja latencia y la rentabilidad.
Nivel de infraestructura : en el nivel de infraestructura, la arquitectura se basa en las mejores opciones de cómputo de clase, como el tipo de instancia G5, equipado con GPU NVIDIA A10G Tensor Core (exclusivo de AWS). Este tipo de instancia ofrece una relación de precio-rendimiento favorable tanto para la capacitación de modelos como para el alojamiento, ofreciendo una potencia de cómputo eficiente por dólar gastado.
La arquitectura es particularmente adecuada para los casos de uso de generación de texto a imagen. Divide el flujo de trabajo de la solución en dos fases principales:
Fase A (incorporación del usuario) : en esta fase, los usuarios pueden solicitar la creación de uno o más modelos personalizados y ajustados. Pueden verificar el estado de disponibilidad de sus modelos en todo momento, para saber cuándo ha terminado la capacitación.
Fase B (inferencia a pedido) : después de ajustar, el modelo está listo para la generación de imágenes en tiempo real a pedido por parte de los usuarios finales.
Para interactuar con su puerta de enlace API implementada utilizando AWS CDK, siga estos pasos:
Abra Costman e importe la colección desde la documentation de la carpeta.
Establezca el método de solicitud (por ejemplo, get, publica) e ingrese el punto final de URL de la puerta de enlace API.
Si su API requiere autenticación, configure los encabezados o tokens necesarios.
Agregue los parámetros o datos de solicitud requeridos.
Haga clic en "Enviar" para realizar la solicitud y recibir la respuesta.
Nota: Asegúrese de que sus recursos de AWS y API Gateway estén configurados correctamente para manejar la solicitud.


