amazon sagemaker personalized generative ai
1.0.0
Dieses Projekt ermöglicht die Feinabstimmung und das Servieren von hyperpersonalisierten generativen KI-Modellen im Maßstab auf AWS. Wir befassen uns mit den Bedürfnissen von SaaS -Anbietern und B2C -Startups, die schnell skalieren möchten. Wir schlagen eine Architektur vor, die den Amazon-Sagemaker nutzt, um die Feinabstimmung und Bereitstellung von AI-Modellen zu optimieren und eine schnellere Entwicklung, eine verbesserte Servicequalität und die Kostenwirksamkeit zu ermöglichen. und Multi-Model-Endpunkte (MMEs) für Echtzeit-Hosting, die eine skalierbare, niedrige Latenz und kostengünstige Möglichkeit bieten, Tausende von Deep-Learning-Modellen hinter einem einzigen Endpunkt einzusetzen. Weitere Informationen finden Sie in diesem Blog -Beitrag.
npm install -g aws-cdkhttps://python-poetry.org/docs/#installationPoesie Installieren Sie Linux, macOS, Windows (WSL)
curl -sSL https://install.python-poetry.org | python3 -Installieren Sie Abhängigkeiten mit Gedichten
poetry install
Setup Python Env in Shell einstellen
poetry shell
Zu diesem Zeitpunkt können Sie jetzt die CloudFormation -Vorlage für diesen Code synthetisieren.
$ cdk synth
Um zusätzliche Abhängigkeiten hinzuzufügen, beispielsweise andere CDK -Bibliotheken, verwenden Sie einfach poetry add yourpackage
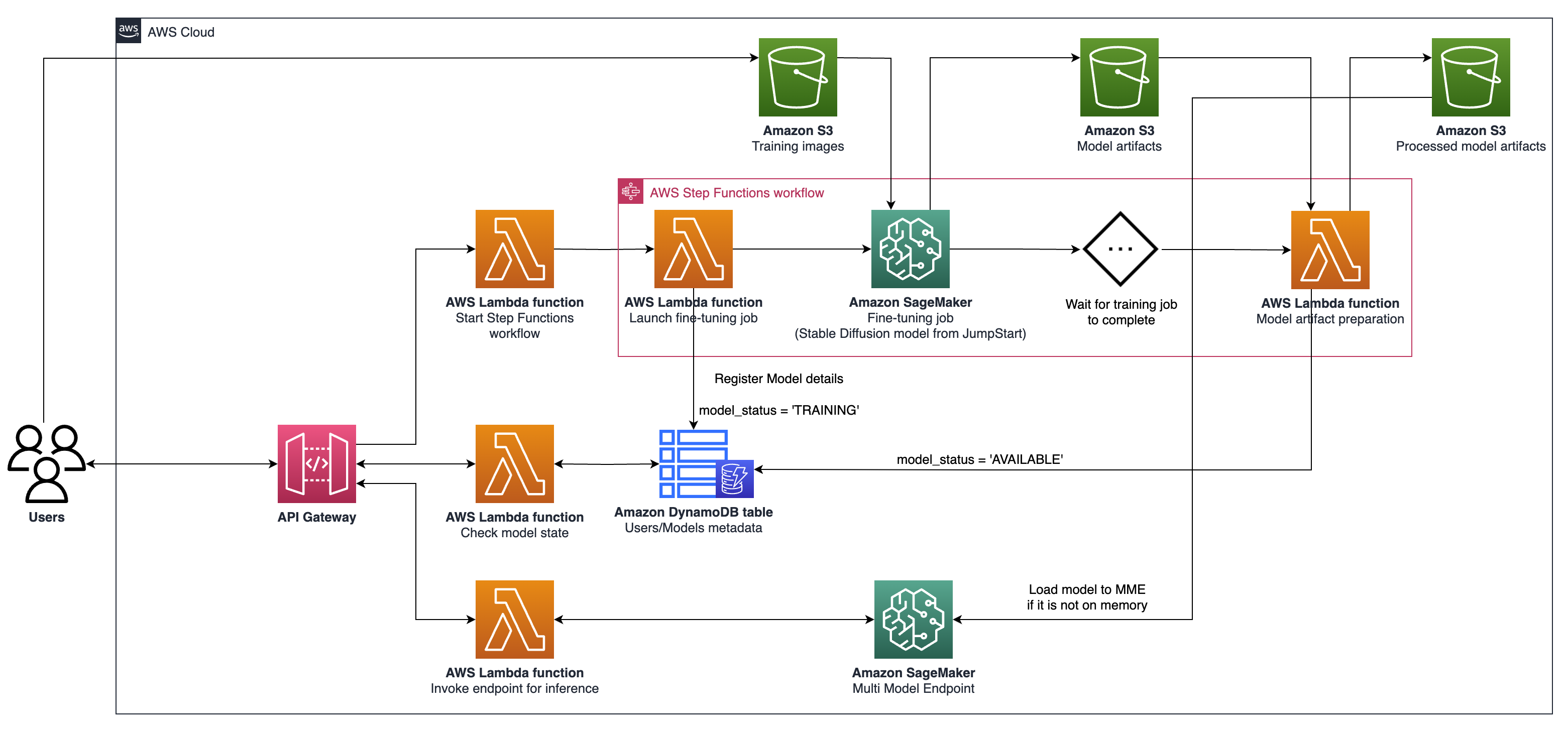
cdk ls listen Sie alle Stapel in der App aufcdk synthcdk deploy diesen Stack bereitcdk diff -Vergleichen des bereitgestellten Stacks mit dem aktuellen Zustandcdk docs Open CDK -Dokumentation Die beschriebene Architektur umfasst ein System für generative KI-Anwendungsfälle, wobei der Schwerpunkt auf der Erzeugung der personalisierten Text-zu-Image-Erzeugung unter Verwendung stabiler Diffusions-V2-1 liegt. Die Schlüsselkomponenten dieser Architektur sind wie folgt:
Sagemaker Training und Hosting -APIs : Diese APIs bieten vollständig verwaltete Schulungsjobs und Modellbereitstellungsfunktionen. Sie ermöglichen es schnell bewegenden Teams, sich mehr auf Produktmerkmale und Differenzierung zu konzentrieren. Sagemaker Training Jobs, die einem Paradigma "Start-and-forget" folgen, eignen sich für vorübergehende gleichzeitige Modellfeiner-Jobs während des Benutzers in Boarding.
GPU-fähiger Hosting : Sagemaker unterstützt GPU-fähige Hosting-Optionen für die Bereitstellung von Deep Learning-Modellen im Maßstab. Dies beinhaltet die Integration des NVIDIA Triton Inference Servers in das Sagemaker -Ökosystem. Sagemaker bietet auch GPU-Unterstützung für Multi-Model-Endpunkte (MMEs), die den Einsatz von Tausenden von Deep-Learning-Modellen hinter einem einzigen Endpunkt ermöglichen, um Skalierbarkeit, niedrige Latenz und Kosteneffizienz zu gewährleisten.
Infrastrukturebene : Auf der Infrastrukturebene basiert die Architektur auf erstklassigen Rechenoptionen wie dem G5-Instanztyp, der mit NVIDIA A10G Tensor Core GPUs (einzigartig für AWS) ausgestattet ist. Dieser Instanztyp bietet ein günstiges Preis-Leistungs-Verhältnis sowohl für das Modell Training als auch für das Hosting und liefert effiziente Rechenleistung pro Geld.
Die Architektur eignet sich besonders gut für Anwendungsfälle für Text-zu-Image-Generation. Es unterteilt den Lösungs -Workflow in zwei Hauptphasen:
Phase A (Benutzer Onboarding) : In dieser Phase können Benutzer die Erstellung eines oder mehrerer benutzerdefinierter Modelle anfordern. Sie können jederzeit nach dem Verfügbarkeitsstatus ihrer Modelle suchen, um zu wissen, wann das Training fertig ist.
Phase B (On-Demand-Inferenz) : Nach der Feinabstimmung ist das Modell für die Echtzeit-Bildgenerierung von On-Demand-Bild durch Endbenutzer bereit.
Befolgen Sie die folgenden Schritte, um mit Ihrem API -Gateway zu interagieren, das mit AWS CDK bereitgestellt wird:
Öffnen Sie den Postboten und importieren Sie die Sammlung aus der documentation .
Setzen Sie die Anforderungsmethode (z. B. GET, POST) und geben Sie den URL -Endpunkt der API -Gateway ein.
Wenn Ihre API eine Authentifizierung erfordert, konfigurieren Sie die erforderlichen Header oder Token.
Fügen Sie alle erforderlichen Anforderungsparameter oder Daten hinzu.
Klicken Sie auf "Senden", um die Anfrage zu stellen und die Antwort zu erhalten.
Hinweis: Stellen Sie sicher, dass Ihre AWS -Ressourcen und Ihr API -Gateway für die Anforderung korrekt konfiguriert sind.


