amazon sagemaker personalized generative ai
1.0.0
Ce projet permet le réglage fin et la portion de modèles d'IA génératifs hyper-personnalisés à grande échelle sur AWS. Nous répondons aux besoins des fournisseurs SaaS et des startups B2C qui cherchent à évoluer rapidement. Nous proposons une architecture qui exploite Amazon Sagemaker pour rationaliser le modèle d'administration de l'IA et le déploiement, permettant un développement plus rapide, une qualité de service améliorée et une efficacité; et les points de terminaison multimodèles (MME) pour l'hébergement en temps réel, qui fournissent un moyen évolutif, à faible latence et rentable de déployer des milliers de modèles d'apprentissage en profondeur derrière un seul point final. Pour plus de détails, veuillez vous référer à cet article de blog.
npm install -g aws-cdkhttps://python-poetry.org/docs/#installationPoetry Installer Linux, MacOS, Windows (WSL)
curl -sSL https://install.python-poetry.org | python3 -Installez les dépendances avec la poésie
poetry install
Configuration de Python Env dans Shell
poetry shell
À ce stade, vous pouvez désormais synthétiser le modèle CloudFormation pour ce code.
$ cdk synth
Pour ajouter des dépendances supplémentaires, par exemple d'autres bibliothèques CDK, utilisez simplement poetry add yourpackage
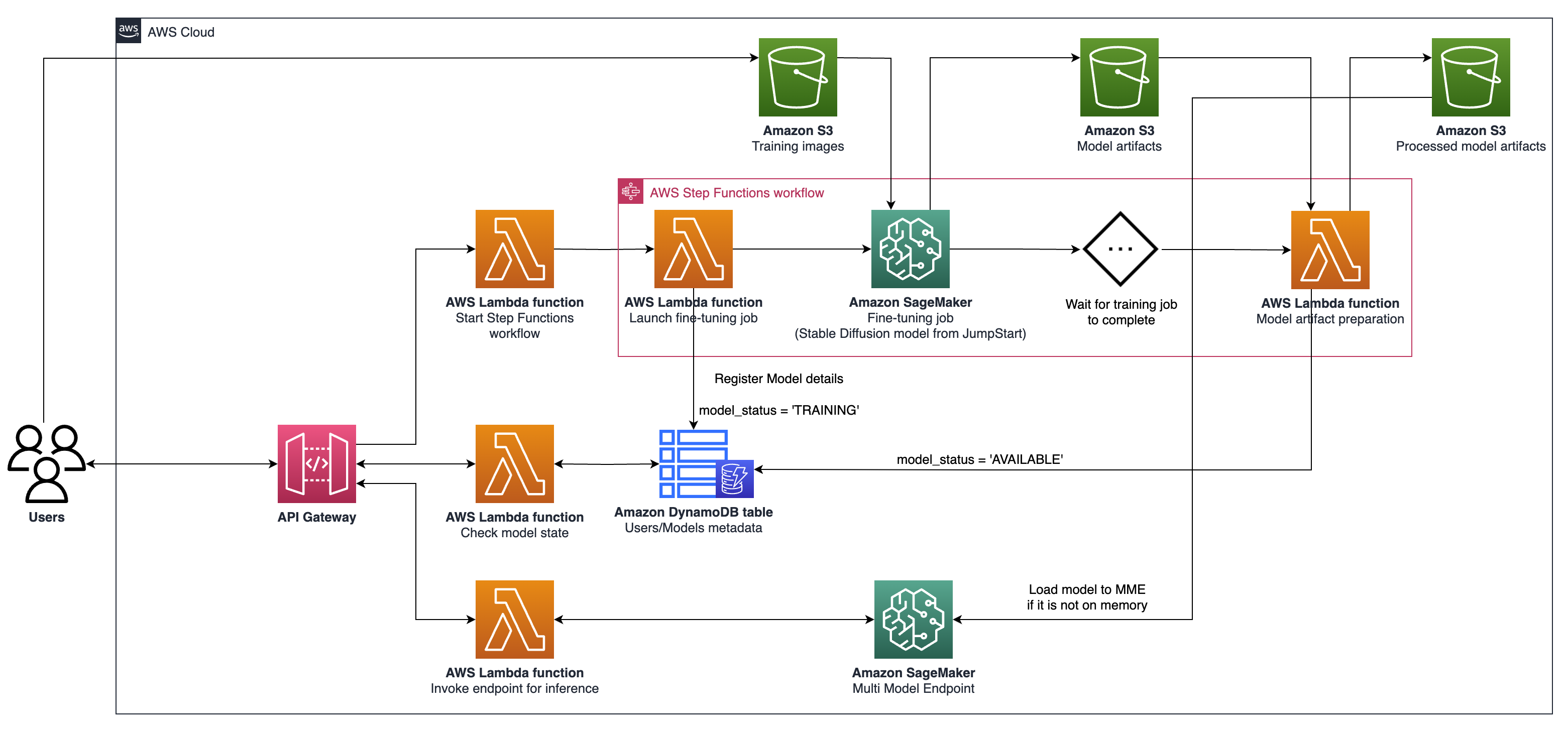
cdk ls répertorie toutes les piles de l'applicationcdk synth émet le modèle de formation de cloud synthétisécdk deploy déploie cette pile sur votre compte / région AWS par défautcdk diff Comparez la pile déployée avec l'état actuelcdk docs ouvre la documentation CDK L'architecture décrite implique un système pour les cas d'utilisation génératrice de l'IA, en mettant l'accent sur la génération de texte à image personnalisée comme exemple, en utilisant la diffusion stable V2-1. Les composantes clés de cette architecture sont les suivantes:
Sagemaker Training and Hosting API : Ces API offrent des emplois de formation entièrement gérés et des capacités de déploiement de modèles. Ils permettent aux équipes à évolution rapide de se concentrer davantage sur les caractéristiques des produits et la différenciation. Les emplois de formation Sagemaker, qui suivent un paradigme "lancement et pour l'ouvrir", conviennent aux travaux de réglage fin du modèle simultané transitoire pendant l'intégration de l'utilisateur.
Hébergement compatible GPU : SageMaker prend en charge les options d'hébergement compatibles GPU pour le déploiement de modèles d'apprentissage en profondeur à grande échelle. Cela inclut l'intégration du serveur d'inférence Nvidia Triton dans l'écosystème SageMaker. Sagemaker offre également un support GPU pour les points de terminaison multimodel (MME), qui permettent le déploiement de milliers de modèles d'apprentissage en profondeur derrière un seul point final, garantissant l'évolutivité, la faible latence et la rentabilité.
Niveau d'infrastructure : Au niveau de l'infrastructure, l'architecture s'appuie sur les meilleures options de calcul de classe, telles que le type d'instance G5, équipé de GPU de base du tenseur NVIDIA A10G (unique à AWS). Ce type d'instance offre un ratio prix-performance favorable pour la formation du modèle et l'hébergement, offrant une puissance de calcul efficace par dollar dépensé.
L'architecture est particulièrement bien adaptée aux cas d'utilisation de la génération de texte à l'image. Il divise le flux de travail de la solution en deux phases principales:
Phase A (intégration de l'utilisateur) : Dans cette phase, les utilisateurs peuvent demander la création d'un ou plusieurs modèles personnalisés et affinés. Ils peuvent vérifier le statut de disponibilité de leurs modèles à tout moment, pour savoir quand l'entraînement a terminé.
Phase B (inférence à la demande) : Après un réglage fin, le modèle est prêt pour la génération d'images en temps réel à la demande par les utilisateurs finaux.
Pour interagir avec votre passerelle API déployée à l'aide d'AWS CDK, suivez ces étapes:
Ouvrez Postman et importez la collection à partir de la documentation du dossier.
Définissez la méthode de demande (par exemple, get, post) et entrez le point de terminaison de l'URL de la passerelle API.
Si votre API nécessite une authentification, configurez les en-têtes ou les jetons nécessaires.
Ajoutez tous les paramètres ou données de demande requis.
Cliquez sur "Envoyer" pour faire la demande et recevoir la réponse.
Remarque: Assurez-vous que vos ressources AWS et votre passerelle API sont correctement configurées pour gérer la demande.


