story chat v1
1.0.0
Sitio web Twitter
Ai trapo chatbot para historias de ficción.
Está impulsado por Llama Index, Together Ai, juntos incrustaciones y próximos.js. Incorpora las historias en story/data y almacena integración en story/cache como base de datos vectorial localmente. Luego es el juego de roles como el personaje de la historia y responde las preguntas de los usuarios.
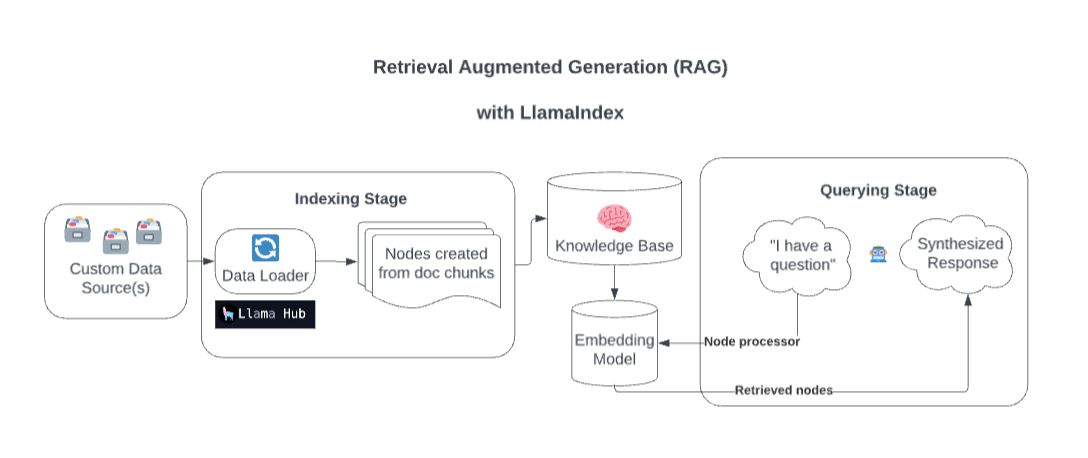
Detrás de escena, Llamaindex enriquece su modelo con fuentes de datos personalizadas a través de la generación aumentada de recuperación (RAG).
Demasiado simplificado, este proceso generalmente consta de dos etapas:
Una etapa de indexación. Llamaindex prepara la base de conocimiento ingiriendo datos y convirtiéndolo en documentos. Analiza los metadatos de esos documentos (texto, relaciones, etc.) en nodos y crea índices consultables de estos fragmentos en la base de conocimiento.
Una etapa de consulta. El contexto relevante se recupera de la base de conocimiento para ayudar al modelo a responder a las consultas. La etapa de consulta asegura que el modelo pueda acceder a datos no incluidos en sus datos de capacitación originales.
Fuente: Streamlit
Copie su archivo .example.env en un .env y reemplace el TOGETHER_API_KEY con el suyo. Especifique un valor ficticio OpenAI_api_Key en este .env para asegurarse de que funcione (hack temporal)
npm install
http://localhost:3200/api/generate . npm run dev
http://localhost:3200/http://localhost:3200/api/chatAdmite la respuesta de transmisión o la respuesta JSON.


