北京智源人工智慧研究院重磅發布原生多模態世界模型Emu3,該模型在圖像、視訊和文字生成領域展現出令人矚目的性能,超越了許多現有的開源模型。 Emu3基於獨特的下一個token預測技術,無需依賴擴散模型或組合方法,即可實現Any-to-Any任務,為多模態人工智慧研究提供了新的範式。 Downcodes小編將帶您深入了解Emu3的創新之處及其開源資源。
北京智源人工智慧研究院宣布推出原生多模態世界模型Emu3。此模型基於下一個token預測技術,無需依賴擴散模型或組合方法,就能夠完成文字、圖像、影片三種模態資料的理解和產生。 Emu3在影像生成、視訊生成、視覺語言理解等任務中超過了現有的知名開源模型,如SDXL、LLaVA、OpenSora等,展現了卓越的性能。

Emu3模型的核心是一個強大的視覺tokenizer,它將視訊和圖像轉換為離散token,這些token可以與文字tokenizer輸出的離散token一起送入模型中。模型輸出的離散token可以轉換為文字、圖像和視頻,為Any-to-Any任務提供了統一的研究範式。此外,Emu3的下一個token預測框架的靈活性使得直接偏好最佳化(DPO)能夠無縫應用於自回歸視覺生成,使模型與人類偏好保持一致。
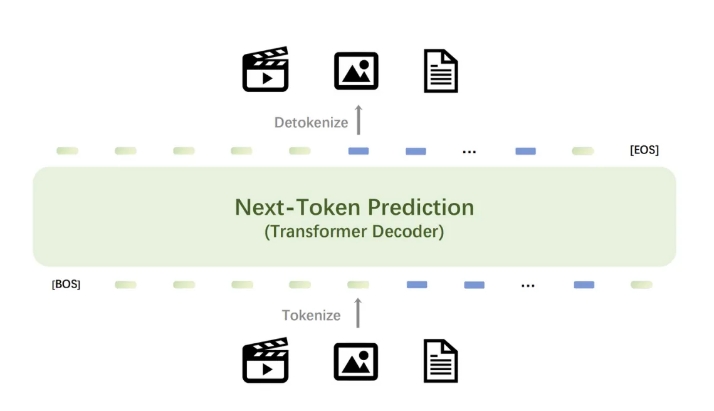
Emu3的研究結果證明了下一個token預測可以作為多模態模型的一個強大範式,實現超越語言本身的大規模多模態學習,並在多模態任務中實現先進的性能。透過將複雜的多模態設計收斂到token本身,Emu3在大規模訓練和推理中釋放了巨大的潛力。這項成果為建構多模態AGI提供了一條前景廣闊的道路。
目前,Emu3的關鍵技術和模型已經開源,包括經過SFT的Chat模型和生成模型,以及相應的SFT訓練程式碼,以便後續研究和社群建構與整合。
代碼:https://github.com/baaivision/Emu3
專案頁:https://emu.baai.ac.cn/
模型: https://huggingface.co/collections/BAAI/emu3-66f4e64f70850ff358a2e60f
Emu3的開源發佈為多模態AI研究提供了寶貴的資源,期待其在未來推動AGI發展,創造更多可能性。 歡迎造訪相關連結以了解更多資訊。