베이징 Zhiyuan 인공 지능 연구소는 네이티브 다중 모드 세계 모델 Emu3을 출시했습니다. 이 모델은 이미지, 비디오 및 텍스트 생성 분야에서 기존의 많은 오픈 소스 모델을 능가하는 인상적인 성능을 보여줍니다. Emu3는 고유한 다음 토큰 예측 기술을 기반으로 확산 모델이나 조합 방법에 의존하지 않고 Any-to-Any 작업을 달성할 수 있어 다중 모드 인공 지능 연구에 대한 새로운 패러다임을 제공합니다. Downcodes의 편집자는 Emu3와 해당 오픈 소스 리소스의 혁신에 대한 심층적인 이해를 제공합니다.
베이징 Zhiyuan 인공 지능 연구소는 기본 다중 모드 세계 모델 Emu3의 출시를 발표했습니다. 이 모델은 차세대 토큰 예측 기술을 기반으로 하며 확산 모델이나 조합 방법에 의존하지 않고 텍스트, 이미지, 비디오의 세 가지 형식으로 데이터를 이해하고 생성할 수 있습니다. Emu3는 SDXL, LLaVA, OpenSora 등 기존의 잘 알려진 오픈 소스 모델을 능가하며 이미지 생성, 비디오 생성, 시각적 언어 이해 등의 작업에서 뛰어난 성능을 보여줍니다.

Emu3 모델의 핵심에는 비디오와 이미지를 텍스트 토크나이저에서 출력되는 개별 토큰과 함께 모델에 공급할 수 있는 개별 토큰으로 변환하는 강력한 시각적 토크나이저가 있습니다. 모델에 의해 출력된 개별 토큰은 텍스트, 이미지 및 비디오로 변환될 수 있어 Any-to-Any 작업을 위한 통합 연구 패러다임을 제공합니다. 또한 Emu3의 차세대 토큰 예측 프레임워크의 유연성을 통해 DPO(직접 선호 최적화)를 자동 회귀 비전 생성에 원활하게 적용하여 모델을 인간 선호도에 맞출 수 있습니다.
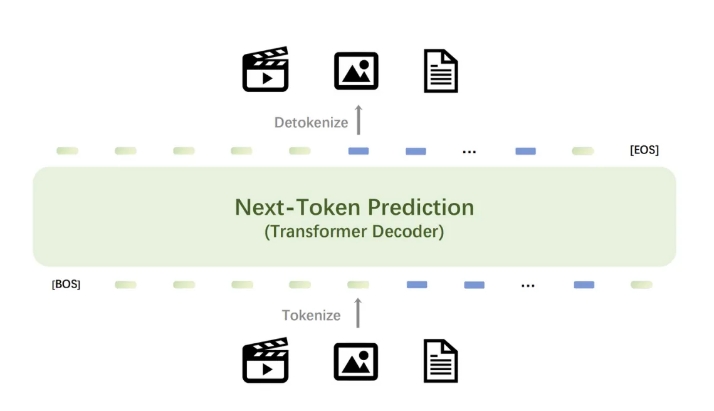
Emu3의 연구 결과는 차세대 토큰 예측이 다중 모드 모델의 강력한 패러다임 역할을 하여 언어 자체를 넘어서는 대규모 다중 모드 학습을 가능하게 하고 다중 모드 작업에서 고급 성능을 달성할 수 있음을 보여줍니다. 복잡한 다중 모드 설계를 토큰 자체에 통합함으로써 Emu3는 대규모 훈련 및 추론을 위한 엄청난 잠재력을 열어줍니다. 이 성과는 다중 모드 AGI 구축을 위한 유망한 경로를 제공합니다.
현재 SFT 처리된 채팅 모델 및 생성 모델과 해당 SFT 훈련 코드를 포함하여 Emu3의 핵심 기술과 모델은 오픈 소스로 공개되어 후속 연구와 커뮤니티 구축 및 통합을 용이하게 합니다.
코드 : https://github.com/baaivision/Emu3
프로젝트 페이지 : https://emu.baai.ac.cn/
모델: https://huggingface.co/collections/BAAI/emu3-66f4e64f70850ff358a2e60f
Emu3의 오픈 소스 릴리스는 다중 모드 AI 연구를 위한 귀중한 리소스를 제공하며, 이를 통해 AGI 개발을 촉진하고 향후 더 많은 가능성을 창출할 수 있기를 기대합니다. 자세한 내용은 관련 링크를 방문하시기 바랍니다.