Das Beijing Zhiyuan Artificial Intelligence Research Institute hat das native multimodale Weltmodell Emu3 veröffentlicht. Dieses Modell zeigt eine beeindruckende Leistung in den Bereichen Bild-, Video- und Textgenerierung und übertrifft viele bestehende Open-Source-Modelle. Basierend auf einer einzigartigen Next-Token-Vorhersagetechnologie kann Emu3 Any-to-Any-Aufgaben erfüllen, ohne auf Diffusionsmodelle oder Kombinationsmethoden angewiesen zu sein, und bietet so ein neues Paradigma für die multimodale Forschung im Bereich der künstlichen Intelligenz. Der Herausgeber von Downcodes vermittelt Ihnen ein tiefgreifendes Verständnis der Innovationen von Emu3 und seiner Open-Source-Ressourcen.
Das Beijing Zhiyuan Artificial Intelligence Research Institute gab die Einführung des nativen multimodalen Weltmodells Emu3 bekannt. Dieses Modell basiert auf der Next-Token-Vorhersagetechnologie und kann Daten in drei Modalitäten verstehen und generieren: Text, Bild und Video, ohne auf Diffusionsmodelle oder Kombinationsmethoden angewiesen zu sein. Emu3 übertrifft bestehende bekannte Open-Source-Modelle wie SDXL, LLaVA, OpenSora usw. und zeigt eine hervorragende Leistung bei Aufgaben wie Bildgenerierung, Videogenerierung und visuellem Sprachverständnis.

Das Herzstück des Emu3-Modells ist ein leistungsstarker visueller Tokenizer, der Videos und Bilder in diskrete Token umwandelt, die zusammen mit den vom Text-Tokenizer ausgegebenen diskreten Token in das Modell eingespeist werden können. Die vom Modell ausgegebenen diskreten Token können in Text, Bilder und Videos umgewandelt werden und bieten so ein einheitliches Forschungsparadigma für Any-to-Any-Aufgaben. Darüber hinaus ermöglicht die Flexibilität des nächsten Token-Vorhersage-Frameworks von Emu3 die nahtlose Anwendung der direkten Präferenzoptimierung (DPO) auf die autoregressive Vision-Generierung, wodurch das Modell an menschlichen Präferenzen ausgerichtet wird.
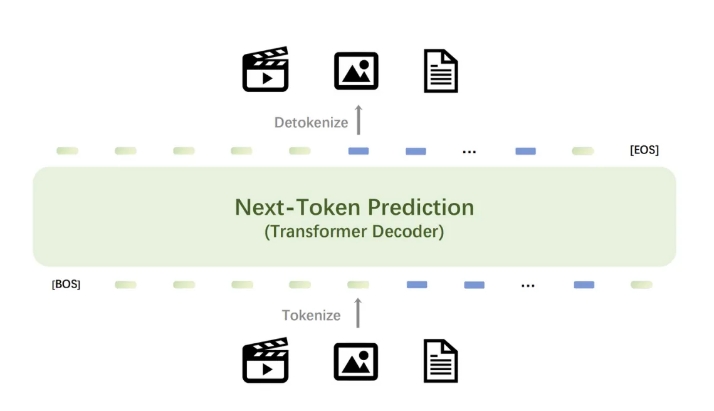
Die Forschungsergebnisse von Emu3 zeigen, dass die Next-Token-Vorhersage als leistungsstarkes Paradigma für multimodale Modelle dienen kann, das umfangreiches multimodales Lernen über die Sprache selbst hinaus ermöglicht und eine verbesserte Leistung bei multimodalen Aufgaben erzielt. Durch die Konvergenz komplexer multimodaler Designs im Token selbst erschließt Emu3 ein enormes Potenzial für groß angelegtes Training und Inferenz. Dieser Erfolg bietet einen vielversprechenden Weg für den Aufbau multimodaler AGI.
Derzeit sind die Schlüsseltechnologien und -modelle von Emu3 Open Source, einschließlich des SFT-verarbeiteten Chat-Modells und -Generierungsmodells sowie des entsprechenden SFT-Trainingscodes, um spätere Forschung sowie den Aufbau und die Integration der Community zu erleichtern.
Code : https://github.com/baaivision/Emu3
Projektseite : https://emu.baai.ac.cn/
Modell: https://huggingface.co/collections/BAAI/emu3-66f4e64f70850ff358a2e60f
Die Open-Source-Veröffentlichung von Emu3 stellt wertvolle Ressourcen für die multimodale KI-Forschung bereit und wir freuen uns darauf, die Entwicklung von AGI voranzutreiben und in Zukunft mehr Möglichkeiten zu schaffen. Weitere Informationen finden Sie unter den entsprechenden Links.