Beijing Zhiyuan Artificial Intelligence Research Institute has released the native multi-modal world model Emu3. This model shows impressive performance in the fields of image, video and text generation, surpassing many existing open source models. Based on a unique next token prediction technology, Emu3 can achieve Any-to-Any tasks without relying on diffusion models or combination methods, providing a new paradigm for multi-modal artificial intelligence research. The editor of Downcodes will take you to have an in-depth understanding of the innovations of Emu3 and its open source resources.
Beijing Zhiyuan Artificial Intelligence Research Institute announced the launch of the native multi-modal world model Emu3. This model is based on the next token prediction technology and can understand and generate data in three modalities: text, image, and video without relying on diffusion models or combination methods. Emu3 surpasses existing well-known open source models, such as SDXL, LLaVA, OpenSora, etc., showing excellent performance in tasks such as image generation, video generation, and visual language understanding.

At the core of the Emu3 model is a powerful visual tokenizer that converts videos and images into discrete tokens that can be fed into the model along with the discrete tokens output by the text tokenizer. The discrete tokens output by the model can be converted into text, images and videos, providing a unified research paradigm for Any-to-Any tasks. Additionally, the flexibility of Emu3’s next token prediction framework enables direct preference optimization (DPO) to be seamlessly applied to autoregressive vision generation, aligning the model with human preferences.
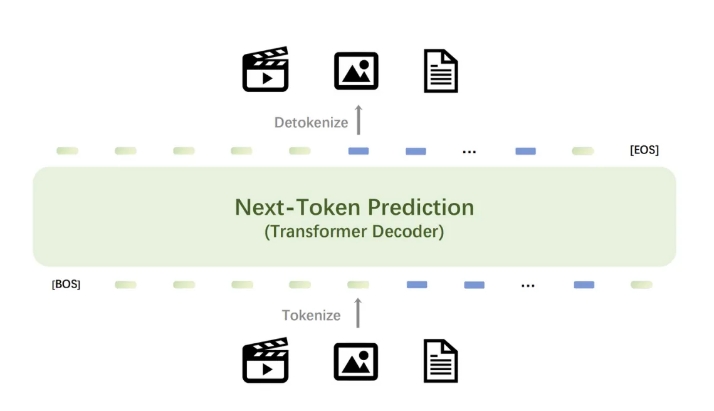
Emu3’s research results demonstrate that next token prediction can serve as a powerful paradigm for multimodal models, enabling large-scale multimodal learning beyond language itself and achieving advanced performance in multimodal tasks. By converging complex multi-modal design into the token itself, Emu3 unlocks huge potential for large-scale training and inference. This achievement provides a promising path for building multi-modal AGI.
At present, the key technologies and models of Emu3 have been open sourced, including the SFT-processed Chat model and generation model, as well as the corresponding SFT training code, to facilitate subsequent research and community construction and integration.
Code : https://github.com/baaivision/Emu3
Project page : https://emu.baai.ac.cn/
Model: https://huggingface.co/collections/BAAI/emu3-66f4e64f70850ff358a2e60f
The open source release of Emu3 provides valuable resources for multi-modal AI research, and we look forward to it promoting the development of AGI and creating more possibilities in the future. Feel free to visit the relevant links for more information.