El Instituto de Investigación de Inteligencia Artificial Zhiyuan de Beijing ha lanzado el modelo mundial multimodal nativo Emu3. Este modelo muestra un rendimiento impresionante en los campos de generación de imágenes, videos y texto, superando a muchos modelos de código abierto existentes. Basado en una tecnología única de predicción de tokens próximos, Emu3 puede realizar tareas Cualquiera a Cualquiera sin depender de modelos de difusión o métodos combinados, proporcionando un nuevo paradigma para la investigación de inteligencia artificial multimodal. El editor de Downcodes lo llevará a comprender en profundidad las innovaciones de Emu3 y sus recursos de código abierto.
El Instituto de Investigación de Inteligencia Artificial Zhiyuan de Beijing anunció el lanzamiento del modelo mundial multimodal nativo Emu3. Este modelo se basa en la próxima tecnología de predicción de tokens y puede comprender y generar datos en tres modalidades: texto, imagen y video sin depender de modelos de difusión o métodos combinados. Emu3 supera los modelos de código abierto conocidos existentes, como SDXL, LLaVA, OpenSora, etc., y muestra un rendimiento excelente en tareas como generación de imágenes, generación de videos y comprensión del lenguaje visual.

En el núcleo del modelo Emu3 hay un potente tokenizador visual que convierte videos e imágenes en tokens discretos que se pueden introducir en el modelo junto con los tokens discretos generados por el tokenizador de texto. Los tokens discretos generados por el modelo se pueden convertir en texto, imágenes y videos, proporcionando un paradigma de investigación unificado para tareas de cualquier tipo. Además, la flexibilidad del próximo marco de predicción de tokens de Emu3 permite aplicar sin problemas la optimización de preferencias directas (DPO) a la generación de visión autorregresiva, alineando el modelo con las preferencias humanas.
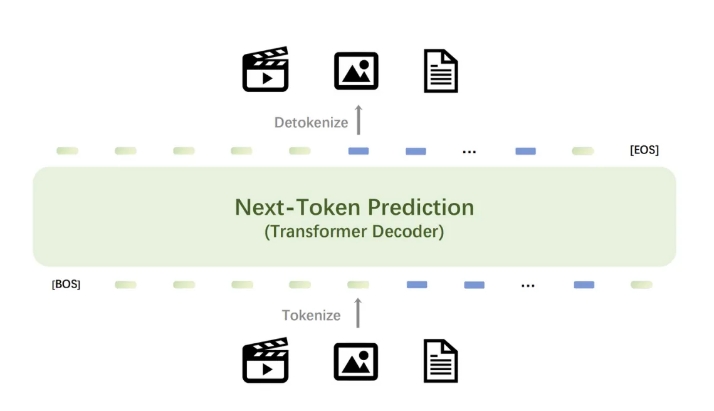
Los resultados de la investigación de Emu3 demuestran que la predicción del próximo token puede servir como un poderoso paradigma para los modelos multimodales, permitiendo un aprendizaje multimodal a gran escala más allá del lenguaje mismo y logrando un rendimiento avanzado en tareas multimodales. Al hacer converger un diseño multimodal complejo en el propio token, Emu3 desbloquea un enorme potencial para el entrenamiento y la inferencia a gran escala. Este logro proporciona un camino prometedor para construir AGI multimodal.
En la actualidad, las tecnologías y modelos clave de Emu3 han sido de código abierto, incluido el modelo de chat procesado por SFT y el modelo de generación, así como el código de capacitación SFT correspondiente, para facilitar la investigación posterior y la construcción e integración de la comunidad.
Código : https://github.com/baaivision/Emu3
Página del proyecto : https://emu.baai.ac.cn/
Modelo: https://huggingface.co/collections/BAAI/emu3-66f4e64f70850ff358a2e60f
La versión de código abierto de Emu3 proporciona recursos valiosos para la investigación de IA multimodal y esperamos que promueva el desarrollo de AGI y cree más posibilidades en el futuro. No dude en visitar los enlaces correspondientes para obtener más información.