Institut Penelitian Kecerdasan Buatan Zhiyuan Beijing telah merilis model dunia multi-modal asli Emu3. Model ini menunjukkan kinerja yang mengesankan di bidang pembuatan gambar, video, dan teks, melampaui banyak model sumber terbuka yang ada. Berdasarkan teknologi prediksi token berikutnya yang unik, Emu3 dapat mencapai tugas Any-to-Any tanpa bergantung pada model difusi atau metode kombinasi, memberikan paradigma baru untuk penelitian kecerdasan buatan multi-modal. Editor Downcodes akan membawa Anda untuk memiliki pemahaman mendalam tentang inovasi Emu3 dan sumber daya open source-nya.
Institut Penelitian Kecerdasan Buatan Zhiyuan Beijing mengumumkan peluncuran model dunia multi-modal asli Emu3. Model ini didasarkan pada teknologi prediksi token berikutnya dan dapat memahami serta menghasilkan data dalam tiga modalitas: teks, gambar, dan video tanpa bergantung pada model difusi atau metode kombinasi. Emu3 melampaui model open source terkenal yang ada, seperti SDXL, LLaVA, OpenSora, dll., menunjukkan kinerja luar biasa dalam tugas-tugas seperti pembuatan gambar, pembuatan video, dan pemahaman bahasa visual.

Inti dari model Emu3 adalah tokenizer visual yang kuat yang mengubah video dan gambar menjadi token terpisah yang dapat dimasukkan ke dalam model bersama dengan keluaran token diskrit oleh tokenizer teks. Output token terpisah dari model dapat diubah menjadi teks, gambar, dan video, sehingga memberikan paradigma penelitian terpadu untuk tugas Any-to-Any. Selain itu, fleksibilitas kerangka prediksi token Emu3 berikutnya memungkinkan optimasi preferensi langsung (DPO) diterapkan secara mulus pada pembuatan visi autoregresif, menyelaraskan model dengan preferensi manusia.
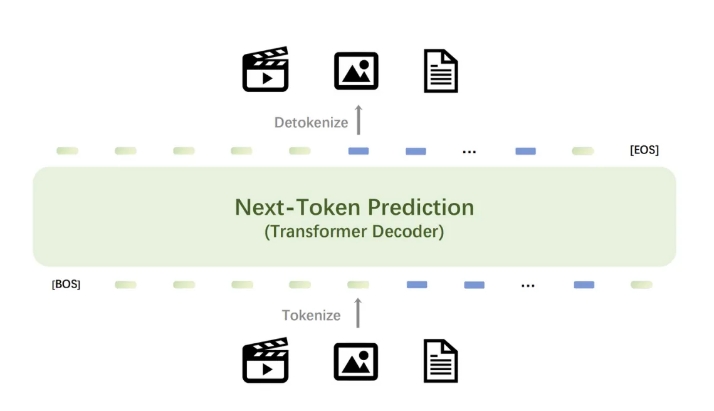
Hasil penelitian Emu3 menunjukkan bahwa prediksi token berikutnya dapat berfungsi sebagai paradigma yang kuat untuk model multimodal, memungkinkan pembelajaran multimodal skala besar di luar bahasa itu sendiri dan mencapai kinerja tingkat lanjut dalam tugas-tugas multimodal. Dengan menggabungkan desain multi-modal yang kompleks ke dalam token itu sendiri, Emu3 membuka potensi besar untuk pelatihan dan inferensi skala besar. Pencapaian ini memberikan jalan yang menjanjikan untuk membangun AGI multimodal.
Saat ini, teknologi dan model utama Emu3 telah bersumber terbuka, termasuk model Obrolan dan model pembuatan yang diproses SFT, serta kode pelatihan SFT yang sesuai, untuk memfasilitasi penelitian selanjutnya serta konstruksi dan integrasi komunitas.
Kode : https://github.com/baaivision/Emu3
Halaman proyek : https://emu.baai.ac.cn/
Model: https://huggingface.co/collections/BAAI/emu3-66f4e64f70850ff358a2e60f
Rilis open source Emu3 menyediakan sumber daya berharga untuk penelitian AI multi-modal, dan kami berharap hal ini dapat mendorong pengembangan AGI dan menciptakan lebih banyak kemungkinan di masa depan. Jangan ragu untuk mengunjungi tautan yang relevan untuk informasi lebih lanjut.