北京知源人工知能研究所は、ネイティブ マルチモーダル ワールド モデル Emu3 をリリースしました。このモデルは、画像、ビデオ、テキスト生成の分野で優れたパフォーマンスを示し、既存の多くのオープンソース モデルを上回っています。 Emu3 は、独自の次トークン予測テクノロジーに基づいて、拡散モデルや組み合わせ手法に依存せずに Any-to-Any タスクを実現でき、マルチモーダル人工知能研究に新しいパラダイムを提供します。 Downcodes のエディターは、Emu3 の革新性とそのオープン ソース リソースを深く理解するのに役立ちます。
北京知源人工知能研究所はネイティブマルチモーダルワールドモデルEmu3の発売を発表した。このモデルは次トークン予測技術に基づいており、拡散モデルや組み合わせ手法に依存することなく、テキスト、画像、ビデオの 3 つのモダリティのデータを理解して生成できます。 Emu3 は、SDXL、LLaVA、OpenSora などの既存のよく知られたオープン ソース モデルを上回り、画像生成、ビデオ生成、視覚言語理解などのタスクで優れたパフォーマンスを示します。

Emu3 モデルの中核となるのは、ビデオと画像を離散トークンに変換する強力なビジュアル トークナイザーで、テキスト トークナイザーによって出力される離散トークンとともにモデルに入力できます。モデルによって出力された個別のトークンはテキスト、画像、ビデオに変換でき、Any-to-Any タスクに統合された研究パラダイムを提供します。さらに、Emu3 の次のトークン予測フレームワークの柔軟性により、直接好みの最適化 (DPO) を自己回帰ビジョン生成にシームレスに適用して、モデルを人間の好みに合わせることができます。
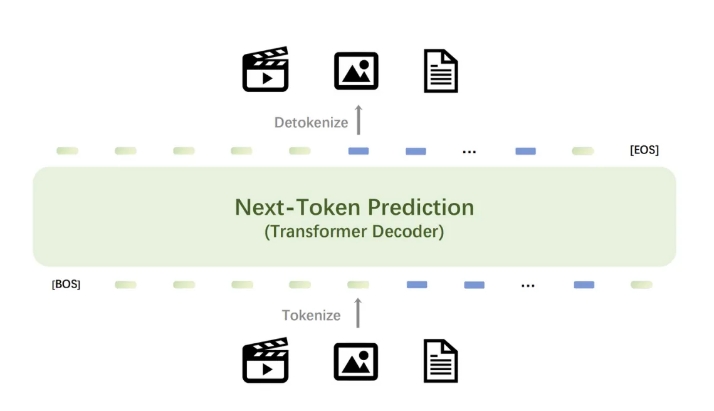
Emu3 の研究結果は、次のトークン予測がマルチモーダル モデルの強力なパラダイムとして機能し、言語自体を超えた大規模なマルチモーダル学習を可能にし、マルチモーダル タスクで高度なパフォーマンスを達成できることを示しています。複雑なマルチモーダル設計をトークン自体に統合することにより、Emu3 は大規模なトレーニングと推論のための大きな可能性を解き放ちます。この成果は、マルチモーダル AGI を構築するための有望な道を提供します。
現在、Emu3 の主要なテクノロジーとモデルは、SFT 処理されたチャット モデルと生成モデル、および対応する SFT トレーニング コードを含めてオープンソース化されており、その後の研究とコミュニティの構築と統合を容易にします。
コード: https://github.com/baaivision/Emu3
プロジェクトページ:https://emu.baai.ac.cn/
モデル: https://huggingface.co/collections/BAAI/emu3-66f4e64f70850ff358a2e60f
Emu3 のオープンソース リリースは、マルチモーダル AI 研究に貴重なリソースを提供し、AGI の開発を促進し、将来により多くの可能性を生み出すことを期待しています。 詳細については、関連リンクを参照してください。