O Instituto de Pesquisa de Inteligência Artificial Zhiyuan de Pequim lançou o modelo mundial multimodal nativo Emu3. Este modelo mostra um desempenho impressionante nas áreas de geração de imagem, vídeo e texto, superando muitos modelos de código aberto existentes. Com base em uma tecnologia exclusiva de previsão do próximo token, o Emu3 pode realizar tarefas Any-to-Any sem depender de modelos de difusão ou métodos de combinação, fornecendo um novo paradigma para pesquisa multimodal de inteligência artificial. O editor de Downcodes levará você a um conhecimento profundo das inovações do Emu3 e de seus recursos de código aberto.
O Instituto de Pesquisa de Inteligência Artificial Zhiyuan de Pequim anunciou o lançamento do modelo mundial multimodal nativo Emu3. Este modelo é baseado na próxima tecnologia de previsão de tokens e pode compreender e gerar dados em três modalidades: texto, imagem e vídeo, sem depender de modelos de difusão ou métodos combinados. O Emu3 supera os modelos de código aberto conhecidos existentes, como SDXL, LLaVA, OpenSora, etc., mostrando excelente desempenho em tarefas como geração de imagens, geração de vídeos e compreensão de linguagem visual.

No centro do modelo Emu3 está um poderoso tokenizer visual que converte vídeos e imagens em tokens discretos que podem ser alimentados no modelo junto com os tokens discretos gerados pelo tokenizer de texto. Os tokens discretos gerados pelo modelo podem ser convertidos em texto, imagens e vídeos, fornecendo um paradigma de pesquisa unificado para tarefas Any-to-Any. Além disso, a flexibilidade da próxima estrutura de previsão de token do Emu3 permite que a otimização de preferência direta (DPO) seja aplicada perfeitamente à geração de visão autorregressiva, alinhando o modelo com as preferências humanas.
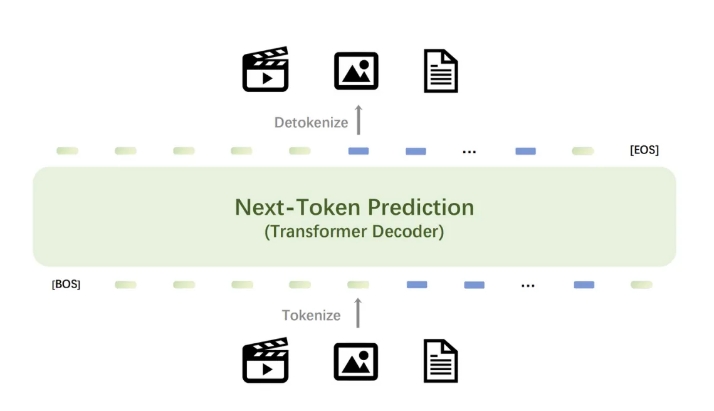
Os resultados da pesquisa da Emu3 demonstram que a previsão do próximo token pode servir como um paradigma poderoso para modelos multimodais, permitindo a aprendizagem multimodal em larga escala além da própria linguagem e alcançando desempenho avançado em tarefas multimodais. Ao convergir um design multimodal complexo para o próprio token, o Emu3 revela um enorme potencial para treinamento e inferência em larga escala. Esta conquista proporciona um caminho promissor para a construção de AGI multimodal.
Atualmente, as principais tecnologias e modelos do Emu3 são de código aberto, incluindo o modelo de bate-papo processado por SFT e o modelo de geração, bem como o código de treinamento SFT correspondente, para facilitar a pesquisa subsequente e a construção e integração da comunidade.
Código : https://github.com/baaivision/Emu3
Página do projeto : https://emu.baai.ac.cn/
Modelo: https://huggingface.co/collections/BAAI/emu3-66f4e64f70850ff358a2e60f
O lançamento de código aberto do Emu3 fornece recursos valiosos para pesquisas multimodais de IA, e esperamos que ele promova o desenvolvimento da AGI e crie mais possibilidades no futuro. Sinta-se à vontade para visitar os links relevantes para obter mais informações.