Downcodes小編報:OpenAI發布了新的基準測試SimpleQA,旨在評估大型語言模型生成答案的事實準確性。隨著AI模型的快速發展,確保其生成內容的準確性至關重要,而SimpleQA的出現恰好能有效解決「幻覺」問題——模型生成看似自信但實則錯誤的訊息。 SimpleQA專注於簡潔明確的問題,並設定了嚴格的評分標準,力求客觀評估模型的準確性和校準能力。它包含4326個問題,涵蓋多個領域,並採用雙重AI審核答案、ChatGPT分類器評分等機制,確保結果的可靠性。
最近,OpenAI 發布了一個名為SimpleQA 的新基準測試,旨在評估語言模型產生答案的事實準確性。
隨著大型語言模型的快速發展,確保生成內容的準確性面臨著許多挑戰,尤其是那些所謂的「幻覺」 現象,即模型生成了聽起來很自信但實際上是錯誤或不可驗證的訊息。這種情況在越來越多的人依賴AI 獲取資訊的背景下,變得尤為重要。
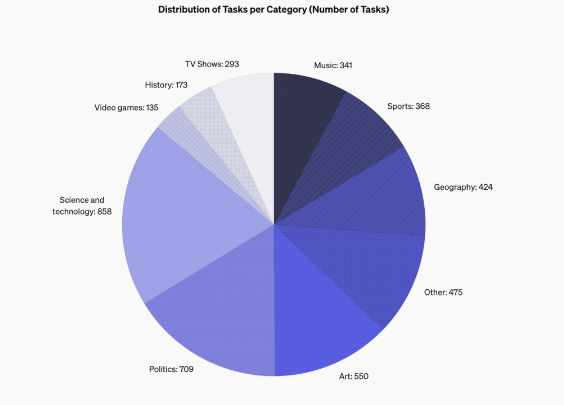
SimpleQA 的設計特色在於它專注於短小、明確的問題,這些問題通常有一個確鑿的答案,這樣就能更容易評估模型的回答是否正確。與其他基準不同,SimpleQA 的問題是經過精心設計的,旨在讓即便是最先進的模型如GPT-4也會面臨挑戰。這個基準包含了4326個問題,涵蓋歷史、科學、技術、藝術和娛樂等多個領域,特別著重評估模型的精確度和校準能力。
SimpleQA 的設計遵循了一些關鍵原則。首先,每個問題都有一個由兩個獨立的AI 訓練師確定的參考答案,確保了答案的正確性。
其次,問題的設定避免了模糊性,每個問題都能用一個簡單明確的答案來回答,這樣評分就變得相對容易。此外,SimpleQA 也使用了ChatGPT 分類器來進行評分,明確標記答案為「正確」、「錯誤」 或「未嘗試」。
SimpleQA 的另一個優點是它涵蓋了多樣化的問題,防止模型過度專門化,確保全面評估。這資料集的使用簡單,因為問題和答案都很短,使得測驗運行快速且結果變化小。而且,SimpleQA 也考慮了資訊的長期相關性,從而避免了因資訊變化而導致的影響,使其成為一個「常青」 的基準。
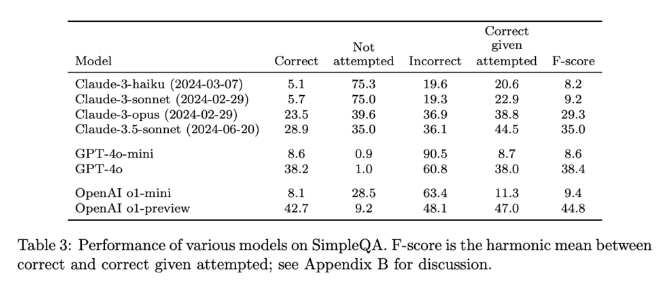
SimpleQA 的發布是推動AI 產生資訊可靠性的重要一步。它不僅提供了一個易於使用的基準測試,更為研究人員和開發者設定了一個高標準,鼓勵他們創建不僅能生成語言而且能做到真實準確的模型。透過開放原始碼,SimpleQA 為AI 社群提供了一個寶貴的工具,幫助提升語言模型的事實準確性,以確保未來的AI 系統既能提供資訊又值得信賴。
專案入口:https://github.com/openai/simple-evals
詳情頁:https://openai.com/index/introducing-simpleqa/
總而言之,SimpleQA的發布對推動AI模型產生資訊的可靠性具有重要意義,其開源特性也為AI社群提供了寶貴的資源,值得關注與學習。期待未來有更多類似的基準測試出現,共同提升AI技術的可靠性與安全性。