ダウンコード エディター レポート: OpenAI は、大規模な言語モデルによって生成された回答の事実の正確さを評価するように設計された新しいベンチマーク SimpleQA をリリースしました。 AI モデルの急速な発展に伴い、生成されるコンテンツの正確性を確保することが重要になっており、SimpleQA の出現により、モデルが自信があるように見えるが実際には間違っている情報を生成する「錯覚」問題を効果的に解決できます。 SimpleQA は、簡潔かつ明確な質問に重点を置き、厳格な採点基準を設定し、モデルの精度とキャリブレーション機能を客観的に評価するよう努めています。複数の分野をカバーする 4,326 の質問が含まれており、デュアル AI レビュー回答や ChatGPT 分類子スコアリングなどのメカニズムを使用して結果の信頼性を確保しています。
最近、OpenAI は、言語モデルによって生成された回答の事実の正確さを評価するように設計された SimpleQA と呼ばれる新しいベンチマークをリリースしました。
大規模な言語モデルの急速な開発に伴い、生成されたコンテンツの正確性を確保する上で多くの課題が生じており、特にいわゆる「幻覚」現象が問題になっています。この現象では、自信に満ちているように見えても、実際には間違っているか検証できない情報がモデルによって生成されます。この状況は、情報を取得するために AI に依存する人がますます増えている状況において特に重要になっています。
SimpleQA の設計機能は、通常は決定的な答えがある短くて明確な質問に焦点を当てており、モデルの答えが正しいかどうかの評価が容易になります。他のベンチマークとは異なり、SimpleQA の質問は、GPT-4 などの最先端のモデルにも挑戦できるように慎重に設計されています。このベンチマークには、歴史、科学、技術、芸術、エンターテイメントなどの複数の分野をカバーする 4,326 の質問が含まれており、モデルの精度とキャリブレーション機能の評価に特に重点を置いています。
SimpleQA は、いくつかの重要な原則に従って設計されました。まず、各質問には 2 人の独立した AI トレーナーによって決定された参照回答があり、回答の正確性が保証されます。
第二に、質問の設定が曖昧さを避け、各質問にシンプルかつ明確に回答できるため、採点が比較的容易になります。さらに、SimpleQA はスコア付けに ChatGPT 分類子を使用し、回答を「正しい」、「間違っている」、または「未試行」として明示的にマークします。
SimpleQA のもう 1 つの利点は、さまざまな問題をカバーするため、モデルの過度の特殊化を防ぎ、包括的な評価を保証できることです。このデータ セットは、質問と回答が短く、テストが高速に実行され、結果のばらつきが少ないため、使いやすいです。さらに、SimpleQA は情報の長期的な関連性も考慮しているため、情報の変更による影響を回避でき、「エバーグリーン」ベンチマークとなります。
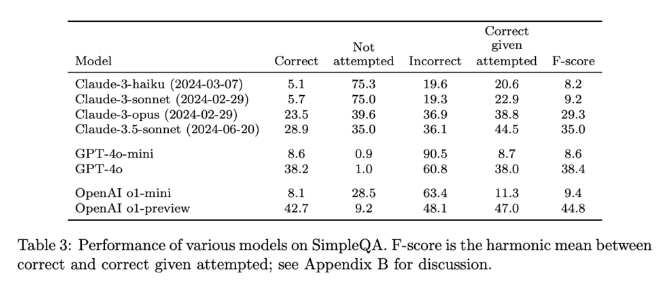
SimpleQA のリリースは、AI によって生成された情報の信頼性を高めるための重要なステップです。使いやすいベンチマークを提供するだけでなく、研究者や開発者に高い基準を設定し、言語を生成するだけでなく現実的に正確なモデルを作成することを奨励します。 SimpleQA はオープンソースであることで、言語モデルの事実の正確性を向上させ、将来の AI システムが有益で信頼できるものになるよう支援する貴重なツールを AI コミュニティに提供します。
プロジェクトの入り口: https://github.com/openai/simple-evals
詳細ページ:https://openai.com/index/introducing-simpleqa/
全体として、SimpleQA のリリースは、AI モデルによって生成された情報の信頼性を高める上で非常に重要であり、そのオープンソース機能は、注目と学習に値する貴重なリソースも AI コミュニティに提供します。 AI テクノロジーの信頼性とセキュリティを共同で向上させるために、今後さらに同様のベンチマーク テストが行われることを期待しています。