Laporan editor downcode: OpenAI telah merilis tolok ukur baru, SimpleQA, yang dirancang untuk mengevaluasi keakuratan faktual jawaban yang dihasilkan oleh model bahasa besar. Dengan pesatnya perkembangan model AI, sangat penting untuk memastikan keakuratan konten yang dihasilkannya, dan kemunculan SimpleQA dapat secara efektif memecahkan masalah "ilusi" - model tersebut menghasilkan informasi yang tampak meyakinkan tetapi sebenarnya salah. SimpleQA berfokus pada pertanyaan yang ringkas dan jelas serta menetapkan standar penilaian yang ketat, berupaya mengevaluasi keakuratan dan kemampuan kalibrasi model secara objektif. Ini berisi 4326 pertanyaan, mencakup berbagai bidang, dan menggunakan mekanisme seperti jawaban tinjauan AI ganda dan penilaian pengklasifikasi ChatGPT untuk memastikan keandalan hasil.
Baru-baru ini, OpenAI merilis tolok ukur baru yang disebut SimpleQA, yang dirancang untuk mengevaluasi keakuratan faktual jawaban yang dihasilkan oleh model bahasa.
Dengan pesatnya perkembangan model bahasa berskala besar, terdapat banyak tantangan dalam memastikan keakuratan konten yang dihasilkan, terutama yang disebut fenomena "halusinasi", di mana model tersebut menghasilkan informasi yang terdengar meyakinkan namun sebenarnya salah atau tidak dapat diverifikasi. Situasi ini menjadi sangat penting mengingat semakin banyaknya orang yang mengandalkan AI untuk memperoleh informasi.
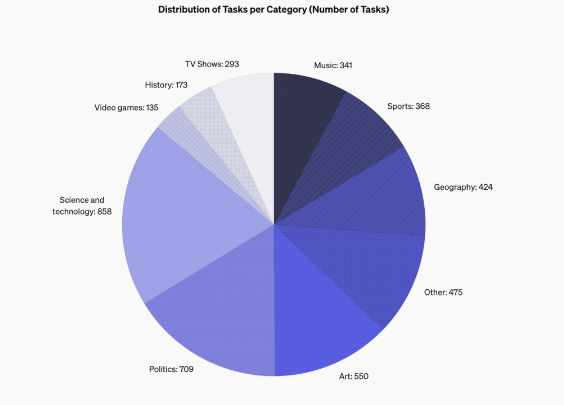
Fitur desain SimpleQA berfokus pada pertanyaan singkat dan jelas yang biasanya memiliki jawaban konklusif, sehingga memudahkan untuk mengevaluasi apakah jawaban model sudah benar. Tidak seperti tolok ukur lainnya, pertanyaan SimpleQA dirancang dengan cermat untuk menantang model tercanggih sekalipun seperti GPT-4. Tolok ukur ini berisi 4.326 pertanyaan yang mencakup berbagai bidang seperti sejarah, sains, teknologi, seni, dan hiburan, dengan fokus khusus pada evaluasi keakuratan dan kemampuan kalibrasi model.
SimpleQA dirancang mengikuti beberapa prinsip utama. Pertama, setiap pertanyaan memiliki jawaban referensi yang ditentukan oleh dua pelatih AI independen, sehingga memastikan kebenaran jawabannya.
Kedua, susunan pertanyaan menghindari ambiguitas, dan setiap pertanyaan dapat dijawab dengan jawaban yang sederhana dan jelas, sehingga penilaian menjadi relatif mudah. Selain itu, SimpleQA menggunakan pengklasifikasi ChatGPT untuk penilaian, secara eksplisit menandai jawaban sebagai "benar", "salah", atau "tidak dicoba".
Keuntungan lain dari SimpleQA adalah mencakup beragam masalah, mencegah spesialisasi model yang berlebihan, dan memastikan evaluasi yang komprehensif. Kumpulan data ini mudah digunakan karena pertanyaan dan jawabannya singkat, membuat tes berjalan cepat dan hasilnya tidak terlalu bervariasi. Selain itu, SimpleQA juga memperhitungkan relevansi informasi jangka panjang, sehingga menghindari dampak yang disebabkan oleh perubahan informasi, menjadikannya tolok ukur yang "hijau".
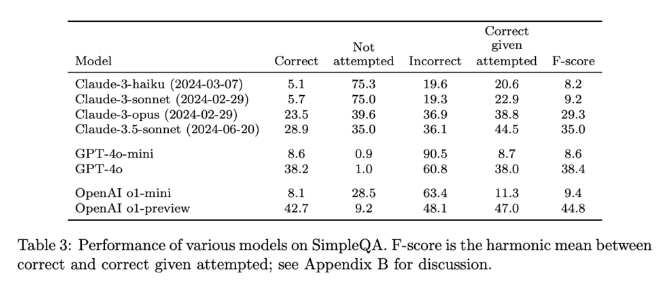
Peluncuran SimpleQA merupakan langkah penting dalam mempromosikan keandalan informasi yang dihasilkan AI. Tidak hanya memberikan tolok ukur yang mudah digunakan, namun juga menetapkan standar tinggi bagi peneliti dan pengembang, mendorong mereka untuk membuat model yang tidak hanya menghasilkan bahasa tetapi juga akurat secara realistis. Dengan menjadi open source, SimpleQA memberi komunitas AI alat yang berharga untuk membantu meningkatkan keakuratan faktual model bahasa guna memastikan bahwa sistem AI di masa depan bersifat informatif dan dapat dipercaya.
Pintu masuk proyek: https://github.com/openai/simple-evals
Halaman detail: https://openai.com/index/introducing-simpleqa/
Secara keseluruhan, peluncuran SimpleQA sangat penting dalam mempromosikan keandalan informasi yang dihasilkan oleh model AI. Fitur open source-nya juga menyediakan sumber daya berharga bagi komunitas AI, yang layak untuk diperhatikan dan dipelajari. Kami menantikan lebih banyak pengujian benchmark serupa di masa depan untuk bersama-sama meningkatkan keandalan dan keamanan teknologi AI.