다운코드 편집자 보고서: OpenAI는 대규모 언어 모델에서 생성된 답변의 실제 정확성을 평가하도록 설계된 새로운 벤치마크인 SimpleQA를 출시했습니다. AI 모델의 급속한 발전으로 인해 생성되는 콘텐츠의 정확성을 보장하는 것이 중요하며, SimpleQA의 등장은 모델이 자신감 있어 보이지만 실제로는 잘못된 정보를 생성하는 '환상' 문제를 효과적으로 해결할 수 있습니다. SimpleQA는 간결하고 명확한 질문에 중점을 두고 엄격한 채점 기준을 설정하여 모델의 정확성과 보정 능력을 객관적으로 평가하기 위해 노력하고 있습니다. 여기에는 여러 필드를 포괄하는 4326개의 질문이 포함되어 있으며 이중 AI 검토 답변 및 ChatGPT 분류기 점수와 같은 메커니즘을 사용하여 결과의 신뢰성을 보장합니다.
최근 OpenAI는 언어 모델에서 생성된 답변의 사실적 정확성을 평가하도록 설계된 SimpleQA라는 새로운 벤치마크를 출시했습니다.
대규모 언어 모델의 급속한 발전으로 인해 생성된 콘텐츠의 정확성을 보장하는 데 많은 어려움이 있으며, 특히 모델이 자신감 있게 들리지만 실제로는 잘못되었거나 검증할 수 없는 정보를 생성하는 소위 "환각" 현상이 있습니다. 이러한 상황은 점점 더 많은 사람들이 정보를 얻기 위해 AI에 의존하고 있다는 맥락에서 특히 중요해졌습니다.
SimpleQA의 디자인 기능은 일반적으로 결정적인 답변이 있는 짧고 명확한 질문에 중점을 두므로 모델의 답변이 올바른지 더 쉽게 평가할 수 있습니다. 다른 벤치마크와 달리 SimpleQA의 질문은 GPT-4와 같은 최첨단 모델에도 도전할 수 있도록 신중하게 설계되었습니다. 이 벤치마크에는 역사, 과학, 기술, 예술, 엔터테인먼트 등 다양한 분야를 다루는 4,326개의 질문이 포함되어 있으며 특히 모델의 정확성과 보정 기능을 평가하는 데 중점을 두고 있습니다.
SimpleQA는 몇 가지 주요 원칙에 따라 설계되었습니다. 첫째, 각 질문에는 두 명의 독립적인 AI 트레이너가 결정한 참조 답변이 있어 답변의 정확성을 보장합니다.
둘째, 문항의 설정이 모호함을 피하고, 각 문항에 대해 간단명료하게 답변할 수 있어 상대적으로 채점이 용이하다. 또한 SimpleQA는 채점을 위해 ChatGPT 분류자를 사용하여 답변을 "올바름", "틀림" 또는 "시도하지 않음"으로 명시적으로 표시합니다.
SimpleQA의 또 다른 장점은 다양한 범위의 문제를 다루어 모델의 과도한 전문화를 방지하고 포괄적인 평가를 보장한다는 것입니다. 이 데이터 세트는 질문과 답변이 짧기 때문에 사용이 간편하며, 테스트 실행 속도가 빠르고 결과의 변동성이 적습니다. 또한 SimpleQA는 정보의 장기적인 관련성을 고려하여 정보 변경으로 인한 영향을 방지하여 "상시" 벤치마크로 만듭니다.
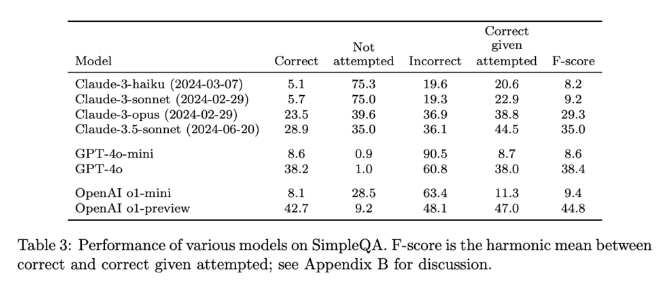
SimpleQA의 출시는 AI 생성 정보의 신뢰성을 높이는 중요한 단계입니다. 사용하기 쉬운 벤치마크를 제공할 뿐만 아니라 연구자와 개발자에게 높은 표준을 설정하여 언어를 생성할 뿐만 아니라 현실적으로 정확한 모델을 만들도록 장려합니다. SimpleQA는 오픈 소스를 통해 AI 커뮤니티에 언어 모델의 사실적 정확성을 향상시켜 미래의 AI 시스템이 유익하고 신뢰할 수 있도록 보장하는 귀중한 도구를 제공합니다.
프로젝트 입구: https://github.com/openai/simple-evals
상세 페이지: https://openai.com/index/introducing-simpleqa/
전체적으로 SimpleQA의 출시는 AI 모델에서 생성된 정보의 신뢰성을 높이는 데 큰 의미가 있습니다. 또한 SimpleQA의 오픈 소스 기능은 관심과 학습의 가치가 있는 AI 커뮤니티에 귀중한 리소스를 제공합니다. 우리는 AI 기술의 신뢰성과 보안성을 공동으로 향상시키기 위해 앞으로 더 유사한 벤치마크 테스트가 등장하기를 기대합니다.