Downcodes editor reports: OpenAI has released a new benchmark, SimpleQA, designed to evaluate the factual accuracy of answers generated by large language models. With the rapid development of AI models, it is crucial to ensure the accuracy of the content they generate, and the emergence of SimpleQA can effectively solve the "illusion" problem-the model generates information that seems confident but is actually wrong. SimpleQA focuses on concise and clear questions and sets strict scoring standards, striving to objectively evaluate the accuracy and calibration capabilities of the model. It contains 4326 questions, covering multiple fields, and uses mechanisms such as dual AI review answers and ChatGPT classifier scoring to ensure the reliability of the results.
Recently, OpenAI released a new benchmark called SimpleQA, designed to evaluate the factual accuracy of answers generated by language models.
With the rapid development of large-scale language models, there are many challenges in ensuring the accuracy of generated content, especially the so-called "hallucination" phenomenon, where the model generates information that sounds confident but is actually wrong or unverifiable. This situation has become particularly important in the context of more and more people relying on AI to obtain information.
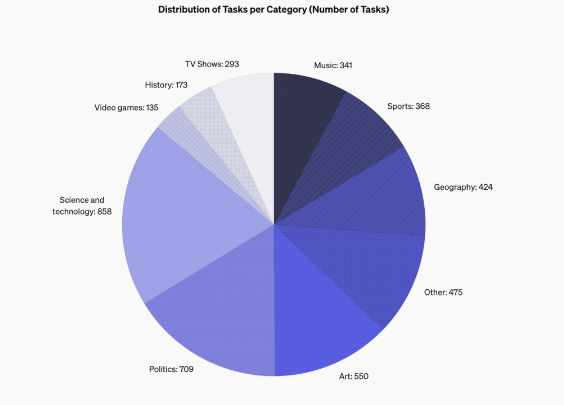
SimpleQA's design features focus on short, clear questions that usually have a conclusive answer, making it easier to evaluate whether the model's answers are correct. Unlike other benchmarks, SimpleQA's questions are carefully designed to challenge even state-of-the-art models such as GPT-4. This benchmark contains 4,326 questions covering multiple fields such as history, science, technology, art, and entertainment, with a special focus on evaluating the accuracy and calibration capabilities of the model.
SimpleQA was designed following a few key principles. First, each question has a reference answer determined by two independent AI trainers, ensuring the correctness of the answer.
Secondly, the setting of the questions avoids ambiguity, and each question can be answered with a simple and clear answer, so that scoring becomes relatively easy. In addition, SimpleQA uses the ChatGPT classifier for scoring, explicitly marking answers as "correct", "wrong" or "not attempted".
Another advantage of SimpleQA is that it covers a diverse range of problems, preventing model over-specialization and ensuring comprehensive evaluation. This data set is simple to use because the questions and answers are short, making the test run fast and the results less variable. Moreover, SimpleQA also takes into account the long-term relevance of information, thereby avoiding the impact caused by information changes, making it an "evergreen" benchmark.
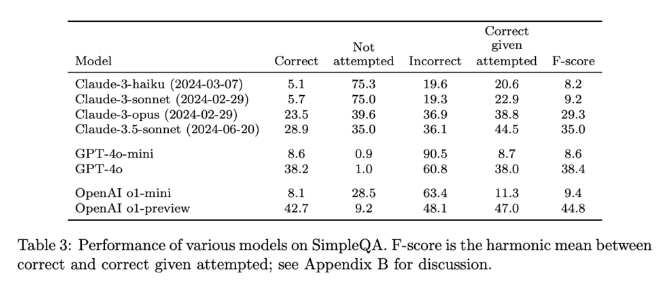
The release of SimpleQA is an important step in promoting the reliability of AI-generated information. Not only does it provide an easy-to-use benchmark, it sets a high standard for researchers and developers, encouraging them to create models that not only generate language but are also realistically accurate. By being open source, SimpleQA provides the AI community with a valuable tool to help improve the factual accuracy of language models to ensure that future AI systems are both informative and trustworthy.
Project entrance: https://github.com/openai/simple-evals
Detail page: https://openai.com/index/introducing-simpleqa/
All in all, the release of SimpleQA is of great significance in promoting the reliability of information generated by AI models. Its open source features also provide valuable resources for the AI community, which are worthy of attention and learning. We look forward to more similar benchmark tests appearing in the future to jointly improve the reliability and security of AI technology.