Downcodes-Editorberichte: OpenAI hat mit SimpleQA einen neuen Benchmark veröffentlicht, der die sachliche Genauigkeit von Antworten bewerten soll, die von großen Sprachmodellen generiert werden. Angesichts der rasanten Entwicklung von KI-Modellen ist es von entscheidender Bedeutung, die Genauigkeit der von ihnen generierten Inhalte sicherzustellen, und das Aufkommen von SimpleQA kann das „Illusions“-Problem effektiv lösen – das Modell generiert Informationen, die sicher erscheinen, aber tatsächlich falsch sind. SimpleQA konzentriert sich auf prägnante und klare Fragen und legt strenge Bewertungsstandards fest, um die Genauigkeit und Kalibrierungsfähigkeiten des Modells objektiv zu bewerten. Es enthält 4326 Fragen, die mehrere Bereiche abdecken, und nutzt Mechanismen wie duale KI-Review-Antworten und ChatGPT-Klassifikatorbewertung, um die Zuverlässigkeit der Ergebnisse sicherzustellen.
Kürzlich hat OpenAI einen neuen Benchmark namens SimpleQA veröffentlicht, der die sachliche Genauigkeit von Antworten bewerten soll, die von Sprachmodellen generiert werden.
Mit der rasanten Entwicklung groß angelegter Sprachmodelle gibt es viele Herausforderungen bei der Gewährleistung der Genauigkeit generierter Inhalte, insbesondere das sogenannte „Halluzinations“-Phänomen, bei dem das Modell Informationen generiert, die sicher klingen, aber tatsächlich falsch oder nicht überprüfbar sind. Diese Situation ist besonders wichtig geworden, da immer mehr Menschen auf KI angewiesen sind, um Informationen zu erhalten.
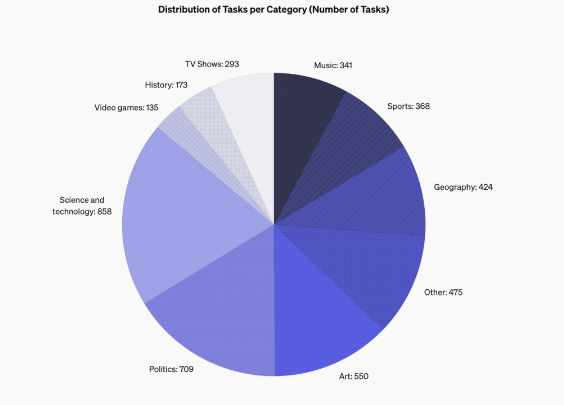
Die Designfunktionen von SimpleQA konzentrieren sich auf kurze, klare Fragen, auf die es in der Regel eine schlüssige Antwort gibt, wodurch es einfacher wird, zu beurteilen, ob die Antworten des Modells richtig sind. Im Gegensatz zu anderen Benchmarks sind die Fragen von SimpleQA sorgfältig darauf ausgelegt, selbst hochmoderne Modelle wie GPT-4 herauszufordern. Dieser Benchmark enthält 4.326 Fragen zu verschiedenen Bereichen wie Geschichte, Wissenschaft, Technologie, Kunst und Unterhaltung, wobei ein besonderer Schwerpunkt auf der Bewertung der Genauigkeit und Kalibrierungsfähigkeiten des Modells liegt.
SimpleQA wurde nach einigen Grundprinzipien entwickelt. Zunächst gibt es für jede Frage eine Referenzantwort, die von zwei unabhängigen KI-Trainern festgelegt wird, um die Richtigkeit der Antwort sicherzustellen.
Zweitens vermeidet die Formulierung der Fragen Mehrdeutigkeiten und jede Frage kann mit einer einfachen und klaren Antwort beantwortet werden, sodass die Bewertung relativ einfach wird. Darüber hinaus nutzt SimpleQA den ChatGPT-Klassifikator zur Bewertung und markiert Antworten explizit als „richtig“, „falsch“ oder „nicht versucht“.
Ein weiterer Vorteil von SimpleQA besteht darin, dass es eine Vielzahl von Problemen abdeckt, eine Überspezialisierung des Modells verhindert und eine umfassende Bewertung gewährleistet. Dieser Datensatz ist einfach zu verwenden, da die Fragen und Antworten kurz sind, wodurch der Test schnell abläuft und die Ergebnisse weniger schwanken. Darüber hinaus berücksichtigt SimpleQA auch die langfristige Relevanz von Informationen und vermeidet so die Auswirkungen von Informationsänderungen, was es zu einem „immergrünen“ Benchmark macht.
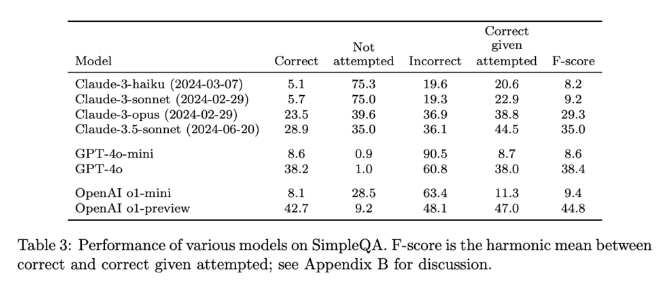
Die Veröffentlichung von SimpleQA ist ein wichtiger Schritt zur Förderung der Zuverlässigkeit KI-generierter Informationen. Es bietet nicht nur einen benutzerfreundlichen Benchmark, sondern setzt auch einen hohen Standard für Forscher und Entwickler und ermutigt sie, Modelle zu erstellen, die nicht nur Sprache generieren, sondern auch realistisch genau sind. Da SimpleQA Open Source ist, stellt es der KI-Community ein wertvolles Werkzeug zur Verfügung, das dazu beiträgt, die sachliche Genauigkeit von Sprachmodellen zu verbessern und sicherzustellen, dass zukünftige KI-Systeme sowohl informativ als auch vertrauenswürdig sind.
Projekteingang: https://github.com/openai/simple-evals
Detailseite: https://openai.com/index/introducing-simpleqa/
Alles in allem ist die Veröffentlichung von SimpleQA von großer Bedeutung für die Förderung der Zuverlässigkeit der von KI-Modellen generierten Informationen. Seine Open-Source-Funktionen stellen auch wertvolle Ressourcen für die KI-Community bereit, die Aufmerksamkeit und Lernen verdienen. Wir freuen uns darauf, dass in Zukunft weitere ähnliche Benchmark-Tests erscheinen, um gemeinsam die Zuverlässigkeit und Sicherheit der KI-Technologie zu verbessern.