Rapports de l'éditeur de downcodes : OpenAI a publié un nouveau benchmark, SimpleQA, conçu pour évaluer l'exactitude factuelle des réponses générées par de grands modèles de langage. Avec le développement rapide des modèles d'IA, il est crucial de garantir l'exactitude du contenu qu'ils génèrent, et l'émergence de SimpleQA peut résoudre efficacement le problème de « l'illusion » : le modèle génère des informations qui semblent sûres mais qui sont en réalité fausses. SimpleQA se concentre sur des questions concises et claires et établit des normes de notation strictes, en s'efforçant d'évaluer objectivement la précision et les capacités d'étalonnage du modèle. Il contient 4 326 questions, couvrant plusieurs domaines, et utilise des mécanismes tels que les réponses à double examen par IA et la notation du classificateur ChatGPT pour garantir la fiabilité des résultats.
Récemment, OpenAI a publié un nouveau benchmark appelé SimpleQA, conçu pour évaluer l'exactitude factuelle des réponses générées par les modèles de langage.
Avec le développement rapide des modèles linguistiques à grande échelle, il existe de nombreux défis pour garantir l'exactitude du contenu généré, en particulier le phénomène dit « d'hallucination », où le modèle génère des informations qui semblent sûres mais qui sont en réalité fausses ou invérifiables. Cette situation est devenue particulièrement importante dans le contexte où de plus en plus de personnes comptent sur l’IA pour obtenir des informations.
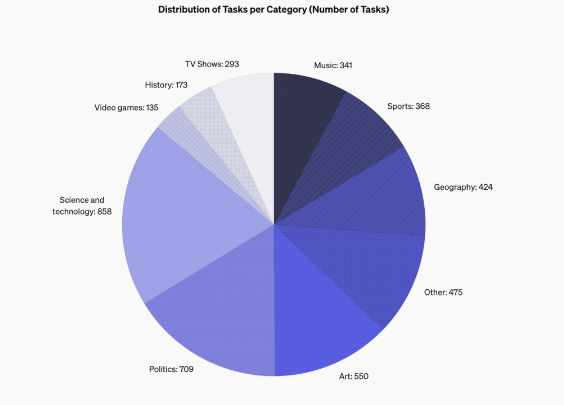
Les fonctionnalités de conception de SimpleQA se concentrent sur des questions courtes et claires qui ont généralement une réponse concluante, ce qui facilite l'évaluation de l'exactitude des réponses du modèle. Contrairement à d'autres benchmarks, les questions de SimpleQA sont soigneusement conçues pour remettre en question même les modèles les plus avancés tels que GPT-4. Ce benchmark contient 4 326 questions couvrant plusieurs domaines tels que l'histoire, la science, la technologie, l'art et le divertissement, avec un accent particulier sur l'évaluation de la précision et des capacités d'étalonnage du modèle.
SimpleQA a été conçu selon quelques principes clés. Premièrement, chaque question a une réponse de référence déterminée par deux formateurs en IA indépendants, garantissant l'exactitude de la réponse.
Deuxièmement, la formulation des questions évite toute ambiguïté et chaque question peut recevoir une réponse simple et claire, de sorte que la notation devient relativement facile. De plus, SimpleQA utilise le classificateur ChatGPT pour la notation, marquant explicitement les réponses comme « correctes », « fausses » ou « non tentées ».
Un autre avantage de SimpleQA est qu'il couvre un large éventail de problèmes, empêchant la surspécialisation des modèles et garantissant une évaluation complète. Cet ensemble de données est simple à utiliser car les questions et réponses sont courtes, ce qui rend le test rapide et les résultats moins variables. De plus, SimpleQA prend également en compte la pertinence à long terme des informations, évitant ainsi l'impact causé par les changements d'informations, ce qui en fait une référence « permanente ».
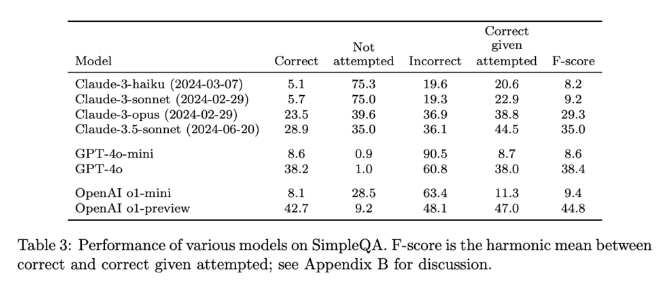
La sortie de SimpleQA constitue une étape importante dans la promotion de la fiabilité des informations générées par l’IA. Non seulement il fournit une référence facile à utiliser, mais il établit des normes élevées pour les chercheurs et les développeurs, les encourageant à créer des modèles qui non seulement génèrent du langage, mais qui sont également réalistes et précis. En étant open source, SimpleQA fournit à la communauté IA un outil précieux pour aider à améliorer la précision factuelle des modèles de langage afin de garantir que les futurs systèmes d'IA soient à la fois informatifs et dignes de confiance.
Entrée du projet : https://github.com/openai/simple-evals
Page de détails : https://openai.com/index/introducing-simpleqa/
Dans l'ensemble, la sortie de SimpleQA revêt une grande importance pour promouvoir la fiabilité des informations générées par les modèles d'IA. Ses fonctionnalités open source fournissent également des ressources précieuses pour la communauté de l'IA, qui méritent attention et apprentissage. Nous attendons avec impatience que d’autres tests de référence similaires apparaissent à l’avenir pour améliorer conjointement la fiabilité et la sécurité de la technologie de l’IA.