Informes del editor de códigos descendentes: OpenAI ha lanzado un nuevo punto de referencia, SimpleQA, diseñado para evaluar la precisión objetiva de las respuestas generadas por grandes modelos de lenguaje. Con el rápido desarrollo de los modelos de IA, es crucial garantizar la precisión del contenido que generan, y la aparición de SimpleQA puede resolver eficazmente el problema de la "ilusión": el modelo genera información que parece segura pero en realidad es incorrecta. SimpleQA se centra en preguntas claras y concisas y establece estándares de puntuación estrictos, esforzándose por evaluar objetivamente la precisión y las capacidades de calibración del modelo. Contiene 4326 preguntas que cubren múltiples campos y utiliza mecanismos como respuestas de revisión dual de IA y puntuación del clasificador ChatGPT para garantizar la confiabilidad de los resultados.
Recientemente, OpenAI lanzó un nuevo punto de referencia llamado SimpleQA, diseñado para evaluar la precisión objetiva de las respuestas generadas por modelos de lenguaje.
Con el rápido desarrollo de modelos de lenguaje a gran escala, existen muchos desafíos para garantizar la precisión del contenido generado, especialmente el llamado fenómeno de "alucinación", donde el modelo genera información que parece segura pero que en realidad es incorrecta o no verificable. Esta situación se ha vuelto particularmente importante en el contexto de que cada vez más personas dependen de la IA para obtener información.
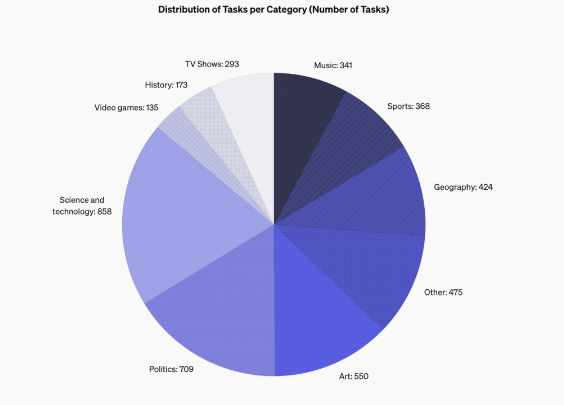
Las características de diseño de SimpleQA se centran en preguntas breves y claras que normalmente tienen una respuesta concluyente, lo que facilita evaluar si las respuestas del modelo son correctas. A diferencia de otros puntos de referencia, las preguntas de SimpleQA están cuidadosamente diseñadas para desafiar incluso modelos de última generación como GPT-4. Este punto de referencia contiene 4326 preguntas que cubren múltiples campos como historia, ciencia, tecnología, arte y entretenimiento, con un enfoque especial en evaluar la precisión y las capacidades de calibración del modelo.
SimpleQA fue diseñado siguiendo algunos principios clave. En primer lugar, cada pregunta tiene una respuesta de referencia determinada por dos formadores de IA independientes, lo que garantiza la exactitud de la respuesta.
En segundo lugar, la configuración de las preguntas evita la ambigüedad y cada pregunta puede responderse con una respuesta simple y clara, de modo que calificar resulta relativamente fácil. Además, SimpleQA utiliza el clasificador ChatGPT para calificar, marcando explícitamente las respuestas como "correctas", "incorrectas" o "no intentadas".
Otra ventaja de SimpleQA es que cubre una amplia gama de problemas, evitando la sobreespecialización del modelo y garantizando una evaluación integral. Este conjunto de datos es fácil de usar porque las preguntas y respuestas son breves, lo que hace que la prueba se ejecute más rápido y los resultados sean menos variables. Además, SimpleQA también tiene en cuenta la relevancia a largo plazo de la información, evitando así el impacto causado por los cambios en la información, convirtiéndolo en un punto de referencia "imperecedero".
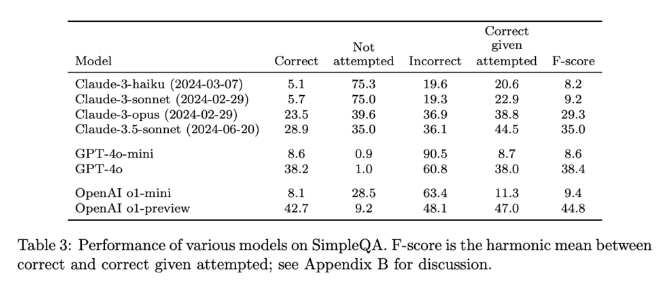
El lanzamiento de SimpleQA es un paso importante para promover la confiabilidad de la información generada por IA. No sólo proporciona un punto de referencia fácil de usar, sino que también establece un alto estándar para investigadores y desarrolladores, animándolos a crear modelos que no sólo generen lenguaje sino que también sean realistas y precisos. Al ser de código abierto, SimpleQA proporciona a la comunidad de IA una herramienta valiosa para ayudar a mejorar la precisión objetiva de los modelos de lenguaje para garantizar que los futuros sistemas de IA sean informativos y confiables.
Entrada del proyecto: https://github.com/openai/simple-evals
Página de detalles: https://openai.com/index/introtaining-simpleqa/
Con todo, el lanzamiento de SimpleQA es de gran importancia para promover la confiabilidad de la información generada por los modelos de IA. Sus características de código abierto también proporcionan recursos valiosos para la comunidad de IA, que merecen atención y aprendizaje. Esperamos que en el futuro aparezcan más pruebas comparativas similares para mejorar conjuntamente la confiabilidad y seguridad de la tecnología de inteligencia artificial.