language_model_tf
1.0.0
語言建模是一項任務,將概率分配給單詞或各種語言單元的序列(例如字符,子字,句子等)。語言建模是現代自然語言處理(NLP)中最重要的問題之一,它用於許多NLP應用程序(例如語音識別,機器翻譯,文本摘要,咒語校正,自動完成等)。在過去的幾年中,與許多語言模型基準的傳統統計方法相比,神經方法取得了更好的結果。此外,最近的工作表明,語言模型預訓練可以以不同的方式改善許多NLP任務,包括基於功能的策略(例如Elmo等)和微調策略(例如OpenAI GPT,BERT等),甚至在零攝像設置(例如OpenAI GPT-2等)中。
圖1:由語言建模提供動力的自動完成的示例
# convert raw data
python preprocess/convert_data.py --dataset wikipedia --input_dir data/wikipedia/raw --output_dir data/wikipedia/processed --min_seq_len 0 --max_seq_len 512
# prepare vocab & embed files
python prepare_resource.py
--input_dir data/wikipedia/processed --max_word_size 512 --max_char_size 16
--full_embedding_file data/glove/glove.840B.300d.txt --word_embedding_file data/wikipedia/resource/lm.word.embed --word_embed_dim 300
--word_vocab_file data/wikipedia/resource/lm.word.vocab --word_vocab_size 100000
--char_vocab_file data/wikipedia/resource/lm.char.vocab --char_vocab_size 1000 # run experiment in train + eval mode
python language_model_run.py --mode train_eval --config config/config_lm_template.xxx.json
# run experiment in train only mode
python language_model_run.py --mode train --config config/config_lm_template.xxx.json
# run experiment in eval only mode
python language_model_run.py --mode eval --config config/config_lm_template.xxx.json # encode text as ELMo vector
python language_model_run.py --mode encode --config config/config_lm_template.xxx.json # random search hyper-parameters
python hparam_search.py --base-config config/config_lm_template.xxx.json --search-config config/config_search_template.xxx.json --num-group 10 --random-seed 100 --output-dir config/search # visualize summary via tensorboard
tensorboard --logdir=output給定序列,雙向語言模型計算序列前進的概率,
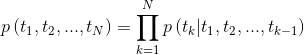
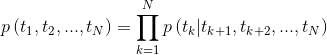
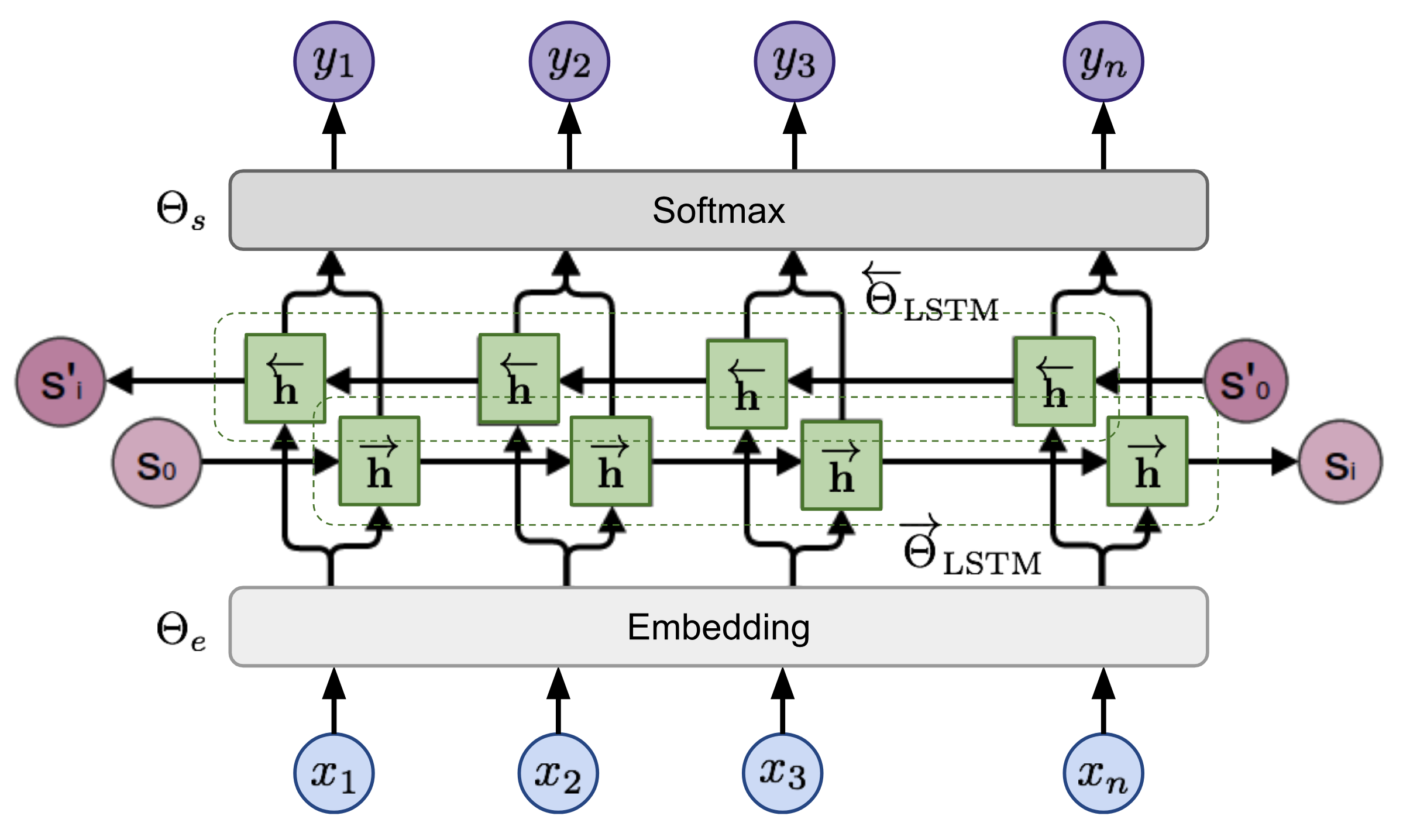
圖2:雙向語言模型體系結構(來源:廣義語言模型)
該模型是通過共同最大程度地減少向前和向後方向的負模可能性來訓練的,