language_model_tf
1.0.0
언어 모델링은 단어 시퀀스 또는 다양한 언어 단위 (예 : Char, 하위 단어, 문장 등)에 확률을 할당하는 작업입니다. 언어 모델링은 현대 자연 언어 처리 (NLP)에서 가장 중요한 문제 중 하나이며 많은 NLP 응용 프로그램 (예 : 음성 인식, 기계 번역, 텍스트 요약, 주문 수정, 자동 완성 등)에 사용됩니다. 지난 몇 년 동안, 신경 접근법은 많은 언어 모델 벤치 마크에서 전통적인 통계 접근법보다 더 나은 결과를 얻었습니다. 또한, 최근의 연구에서 언어 모델 사전 훈련은 기능 기반 전략 (예 : ELMO 등) 및 미세 조정 전략 (예 : OpenAI GPT, Bert 등) 또는 Zero-Shot 설정 (EG OpenAI GPT-2 등)을 포함하여 다양한 NLP 작업을 다양한 방식으로 향상시킬 수 있음을 보여줍니다.
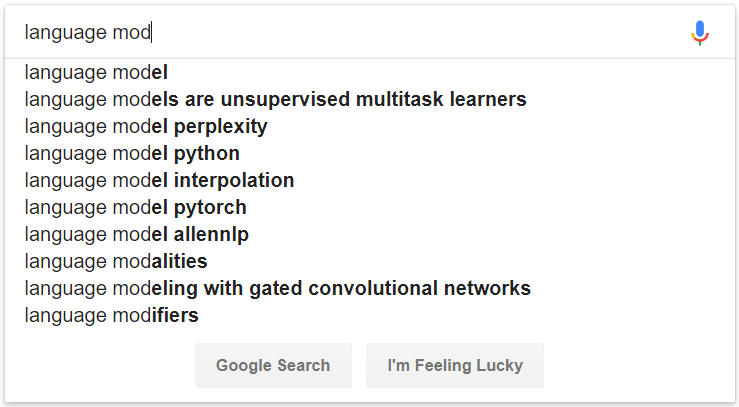
그림 1 : 언어 모델링에 의해 구동되는 자동 완성의 예
# convert raw data
python preprocess/convert_data.py --dataset wikipedia --input_dir data/wikipedia/raw --output_dir data/wikipedia/processed --min_seq_len 0 --max_seq_len 512
# prepare vocab & embed files
python prepare_resource.py
--input_dir data/wikipedia/processed --max_word_size 512 --max_char_size 16
--full_embedding_file data/glove/glove.840B.300d.txt --word_embedding_file data/wikipedia/resource/lm.word.embed --word_embed_dim 300
--word_vocab_file data/wikipedia/resource/lm.word.vocab --word_vocab_size 100000
--char_vocab_file data/wikipedia/resource/lm.char.vocab --char_vocab_size 1000 # run experiment in train + eval mode
python language_model_run.py --mode train_eval --config config/config_lm_template.xxx.json
# run experiment in train only mode
python language_model_run.py --mode train --config config/config_lm_template.xxx.json
# run experiment in eval only mode
python language_model_run.py --mode eval --config config/config_lm_template.xxx.json # encode text as ELMo vector
python language_model_run.py --mode encode --config config/config_lm_template.xxx.json # random search hyper-parameters
python hparam_search.py --base-config config/config_lm_template.xxx.json --search-config config/config_search_template.xxx.json --num-group 10 --random-seed 100 --output-dir config/search # visualize summary via tensorboard
tensorboard --logdir=output시퀀스가 주어지면 양방향 언어 모델은 순서의 확률을 계산합니다.
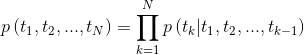
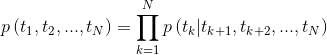
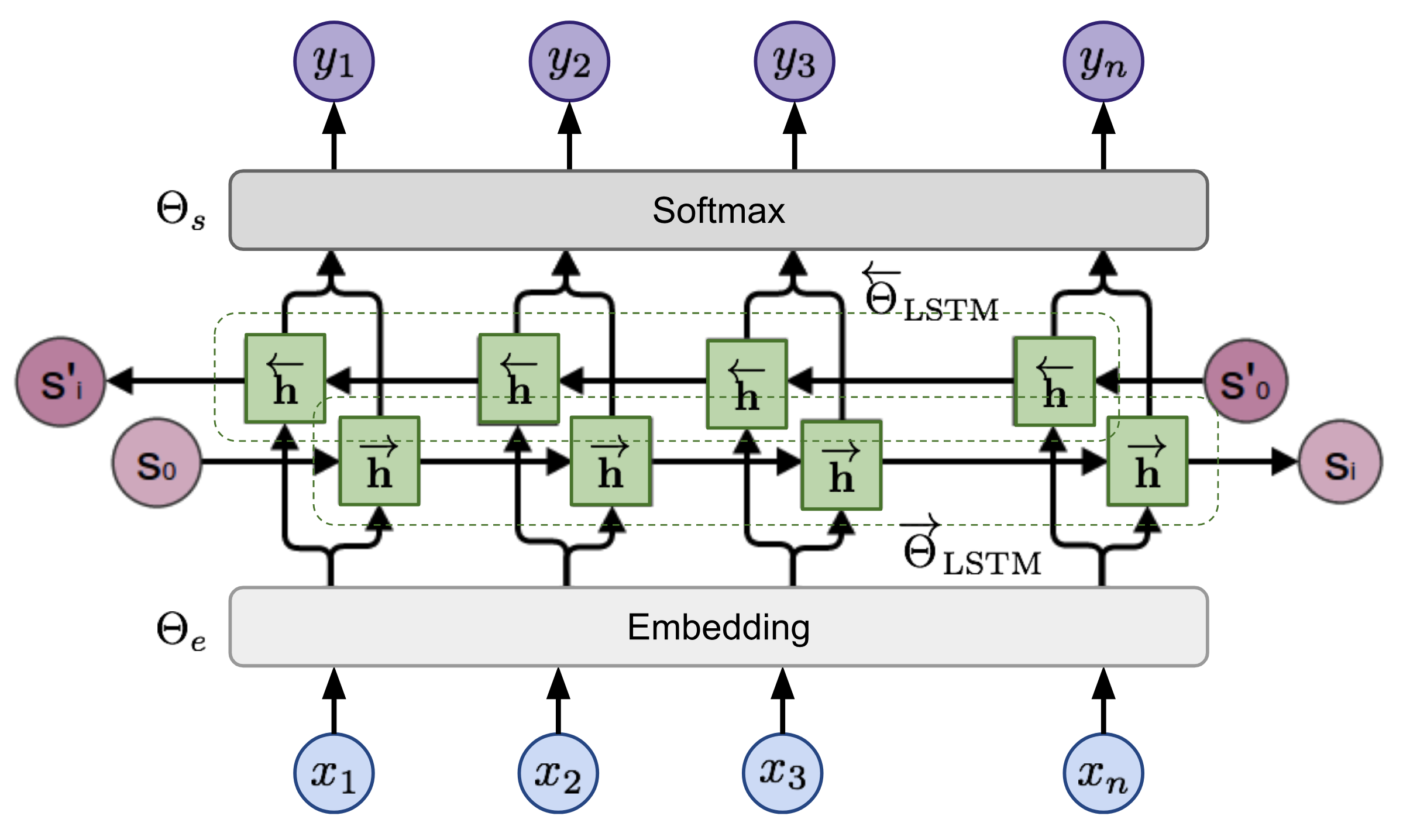
그림 2 : 양방향 언어 모델 아키텍처 (출처 : 일반 언어 모델)
이 모델은 전방 및 후진 방향의 음의 로그 가능성을 공동으로 최소화하여 교육을받습니다.