language_model_tf
1.0.0
Die Sprachmodellierung ist eine Aufgabe, die Sequenzen von Wörtern oder verschiedenen sprachlichen Einheiten Wahrscheinlichkeiten zuweist (z. B. Zeichen, Subword, Satz usw.). Die Sprachmodellierung ist eines der wichtigsten Probleme in der modernen natürlichen Sprachverarbeitung (NLP) und wird in vielen NLP-Anwendungen verwendet (z. In den letzten Jahren haben neuronale Ansätze bessere Ergebnisse erzielt als herkömmliche statistische Ansätze bei vielen Langusemodell -Benchmarks. Darüber hinaus hat jüngste Arbeiten gezeigt, dass Sprachmodell-Voraussetzungen viele NLP-Aufgaben auf unterschiedliche Weise verbessern können, einschließlich featurbasierter Strategien (z. B. Elmo usw.) und Feinabstimmungsstrategien (z. B. OpenAI GPT, Bert usw.) oder sogar in Null-Shot-Einstellung (z. B. OpenAI GPT-2 usw.).
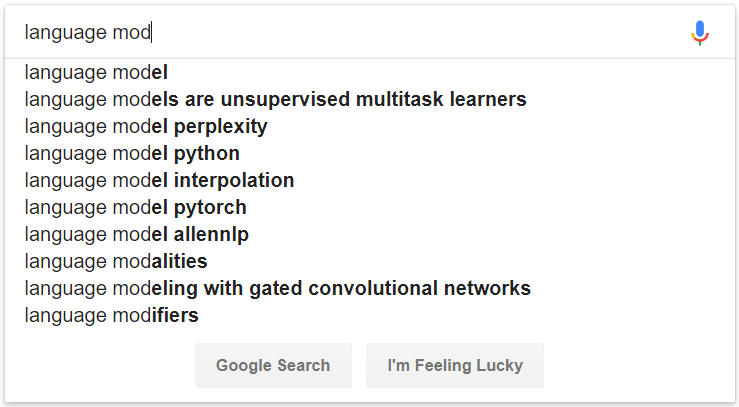
Abbildung 1: Ein Beispiel für die automatische Vervollständigung durch Sprachmodellierung
# convert raw data
python preprocess/convert_data.py --dataset wikipedia --input_dir data/wikipedia/raw --output_dir data/wikipedia/processed --min_seq_len 0 --max_seq_len 512
# prepare vocab & embed files
python prepare_resource.py
--input_dir data/wikipedia/processed --max_word_size 512 --max_char_size 16
--full_embedding_file data/glove/glove.840B.300d.txt --word_embedding_file data/wikipedia/resource/lm.word.embed --word_embed_dim 300
--word_vocab_file data/wikipedia/resource/lm.word.vocab --word_vocab_size 100000
--char_vocab_file data/wikipedia/resource/lm.char.vocab --char_vocab_size 1000 # run experiment in train + eval mode
python language_model_run.py --mode train_eval --config config/config_lm_template.xxx.json
# run experiment in train only mode
python language_model_run.py --mode train --config config/config_lm_template.xxx.json
# run experiment in eval only mode
python language_model_run.py --mode eval --config config/config_lm_template.xxx.json # encode text as ELMo vector
python language_model_run.py --mode encode --config config/config_lm_template.xxx.json # random search hyper-parameters
python hparam_search.py --base-config config/config_lm_template.xxx.json --search-config config/config_search_template.xxx.json --num-group 10 --random-seed 100 --output-dir config/search # visualize summary via tensorboard
tensorboard --logdir=outputBei einer Sequenz berechnet das bidirektionale Sprachmodell die Wahrscheinlichkeit der Sequenz vorwärts,
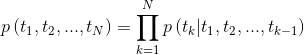
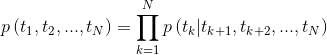
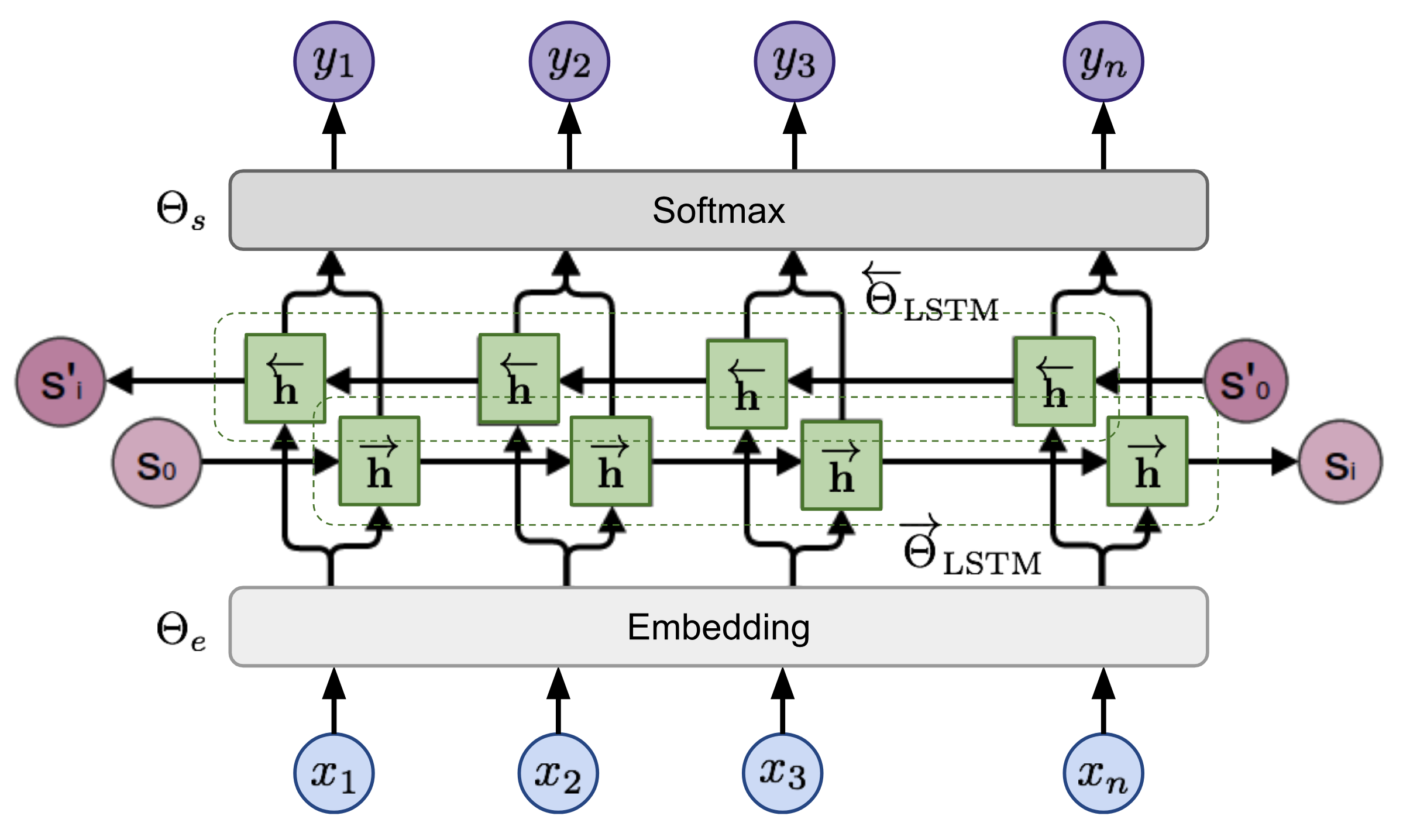
Abbildung 2: Bidirektionale Sprachmodellarchitektur (Quelle: Verallgemeinerte Sprachmodelle)
Das Modell wird trainiert, indem die negative Log -Wahrscheinlichkeit der Vorwärts- und Rückwärtsrichtungen gemeinsam minimiert wird.