language_model_tf
1.0.0
Языковое моделирование - это задача, которая назначает вероятности последовательностям слов или различных лингвистических единиц (например, char, подвод, предложение и т. Д.). Языковое моделирование является одной из наиболее важных проблем в современной обработке естественного языка (NLP), и оно используется во многих приложениях NLP (например, распознавание речи, машинный перевод, суммирование текста, коррекция заклинаний, автоматическое завершение и т. Д.). В последние несколько лет нейронные подходы достигли лучших результатов, чем традиционные статистические подходы по многим языковым модельным показателям. Кроме того, недавняя работа показала, что предварительное обучение языковой модели может по-разному улучшать многие задачи НЛП, включая стратегии на основе функций (например, ELMO и т. Д.) И стратегии тонкой настройки (например, OpenAI GPT, BERT и т. Д.) Или даже в обстановке с нулевым выстрелом (например, OpenAI GPT-2 и т. Д.).
Рисунок 1: Пример автоматического завершения, основанного на языковом моделировании
# convert raw data
python preprocess/convert_data.py --dataset wikipedia --input_dir data/wikipedia/raw --output_dir data/wikipedia/processed --min_seq_len 0 --max_seq_len 512
# prepare vocab & embed files
python prepare_resource.py
--input_dir data/wikipedia/processed --max_word_size 512 --max_char_size 16
--full_embedding_file data/glove/glove.840B.300d.txt --word_embedding_file data/wikipedia/resource/lm.word.embed --word_embed_dim 300
--word_vocab_file data/wikipedia/resource/lm.word.vocab --word_vocab_size 100000
--char_vocab_file data/wikipedia/resource/lm.char.vocab --char_vocab_size 1000 # run experiment in train + eval mode
python language_model_run.py --mode train_eval --config config/config_lm_template.xxx.json
# run experiment in train only mode
python language_model_run.py --mode train --config config/config_lm_template.xxx.json
# run experiment in eval only mode
python language_model_run.py --mode eval --config config/config_lm_template.xxx.json # encode text as ELMo vector
python language_model_run.py --mode encode --config config/config_lm_template.xxx.json # random search hyper-parameters
python hparam_search.py --base-config config/config_lm_template.xxx.json --search-config config/config_search_template.xxx.json --num-group 10 --random-seed 100 --output-dir config/search # visualize summary via tensorboard
tensorboard --logdir=outputУчитывая последовательность, модель двунаправленного языка вычисляет вероятность вперед последовательности,
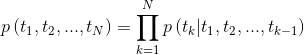
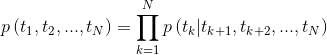
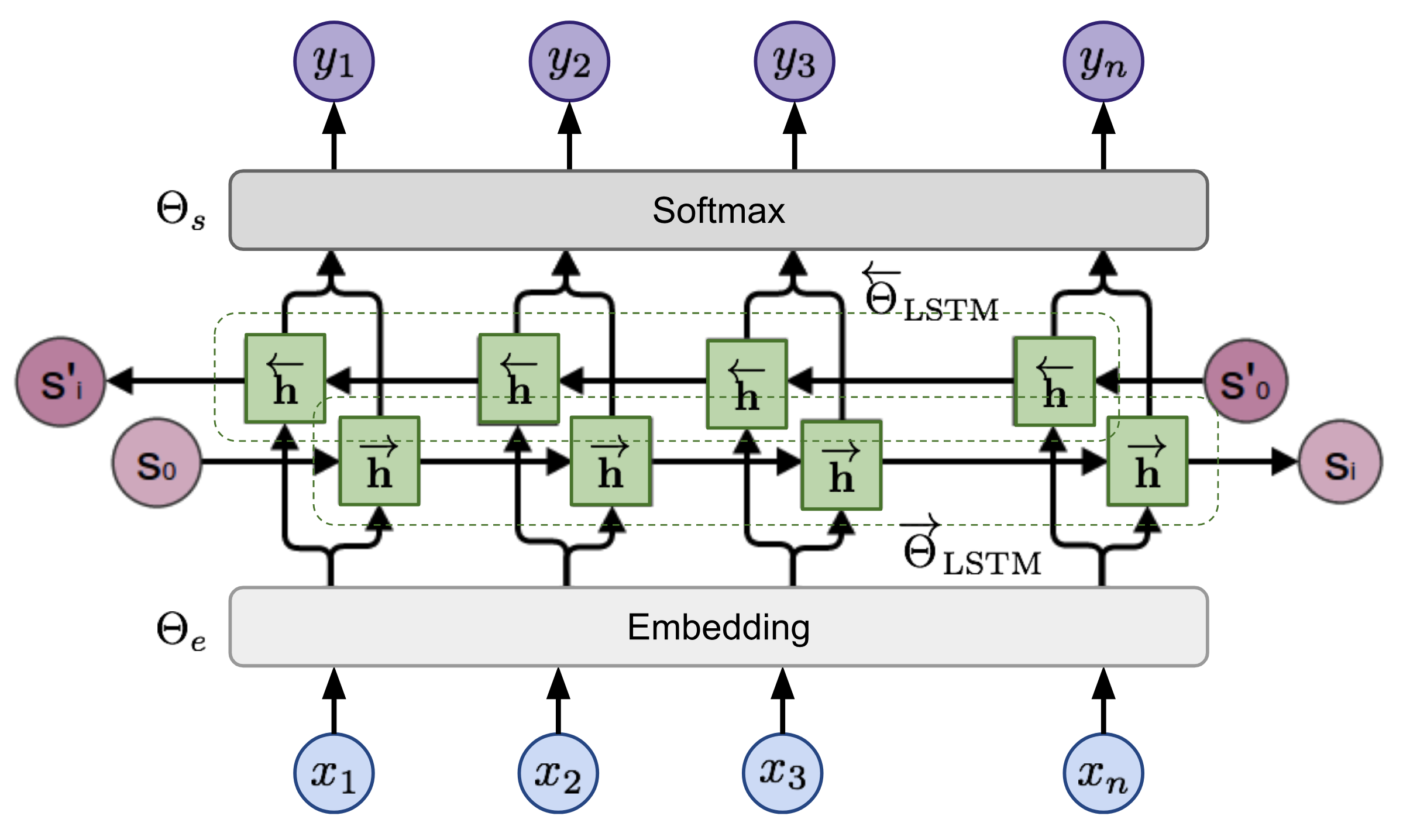
Рисунок 2: Архитектура модели двунаправленной языка (источник: модели обобщенных языков)
модель обучена совместно минимизацией отрицательной вероятности журнала направлений вперед и назад,