language_model_tf
1.0.0
A modelagem de idiomas é uma tarefa que atribui probabilidades a sequências de palavras ou várias unidades linguísticas (por exemplo, char, subglema, sentença etc.). A modelagem de idiomas é um dos problemas mais importantes do processamento moderno da linguagem natural (PNL) e é usado em muitos aplicativos de PNL (por exemplo, reconhecimento de fala, tradução da máquina, resumo de texto, correção de feitiços, conclusão automática etc.). Nos últimos anos, as abordagens neurais alcançaram melhores resultados do que as abordagens estatísticas tradicionais em muitos benchmarks de modelos de idiomas. Além disso, o trabalho recente mostrou que o pré-treinamento do modelo de idioma pode melhorar muitas tarefas de PNL de maneiras diferentes, incluindo estratégias baseadas em recursos (por exemplo, Elmo, etc.) e estratégias de ajuste fino (por exemplo, OpenAi GPT, Bert, etc.) ou mesmo em configuração de tiro zero (EG Open GPT-2, etc.).
Figura 1: Um exemplo de conclusão automática alimentada pela modelagem de idiomas
# convert raw data
python preprocess/convert_data.py --dataset wikipedia --input_dir data/wikipedia/raw --output_dir data/wikipedia/processed --min_seq_len 0 --max_seq_len 512
# prepare vocab & embed files
python prepare_resource.py
--input_dir data/wikipedia/processed --max_word_size 512 --max_char_size 16
--full_embedding_file data/glove/glove.840B.300d.txt --word_embedding_file data/wikipedia/resource/lm.word.embed --word_embed_dim 300
--word_vocab_file data/wikipedia/resource/lm.word.vocab --word_vocab_size 100000
--char_vocab_file data/wikipedia/resource/lm.char.vocab --char_vocab_size 1000 # run experiment in train + eval mode
python language_model_run.py --mode train_eval --config config/config_lm_template.xxx.json
# run experiment in train only mode
python language_model_run.py --mode train --config config/config_lm_template.xxx.json
# run experiment in eval only mode
python language_model_run.py --mode eval --config config/config_lm_template.xxx.json # encode text as ELMo vector
python language_model_run.py --mode encode --config config/config_lm_template.xxx.json # random search hyper-parameters
python hparam_search.py --base-config config/config_lm_template.xxx.json --search-config config/config_search_template.xxx.json --num-group 10 --random-seed 100 --output-dir config/search # visualize summary via tensorboard
tensorboard --logdir=outputDada uma sequência, o modelo de linguagem bidirecional calcula a probabilidade da sequência adiante,
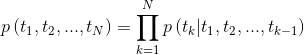
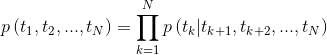
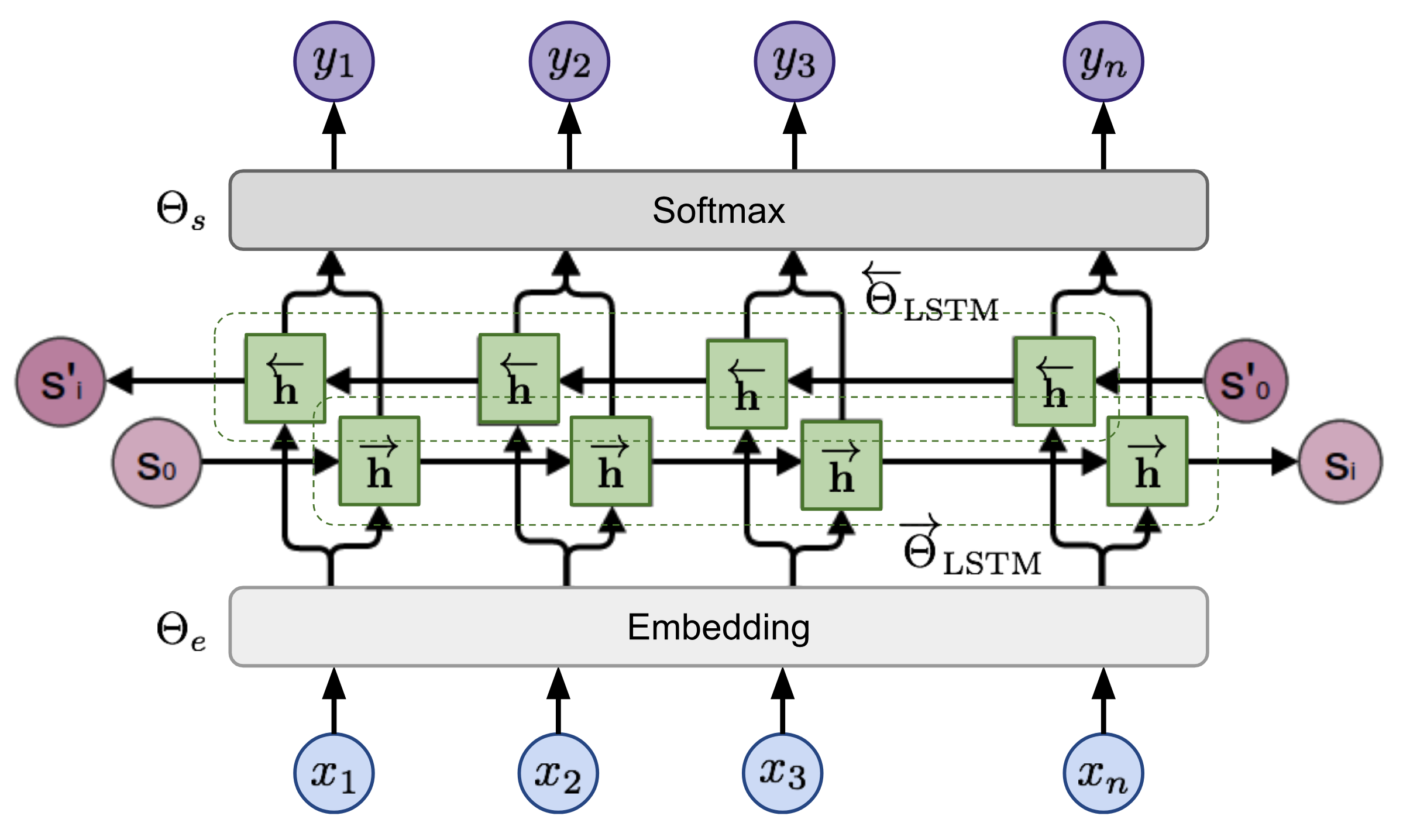
Figura 2: Arquitetura do modelo de linguagem bidirecional (fonte: modelos de idiomas generalizados)
O modelo é treinado minimizando conjuntamente a probabilidade de log negativa das direções para a frente e para trás,