language_model_tf
1.0.0
言語モデリングは、単語またはさまざまな言語単位のシーケンス(char、subword、centeなど)のシーケンスに確率を割り当てるタスクです。言語モデリングは、現代の自然言語処理(NLP)で最も重要な問題の1つであり、多くのNLPアプリケーション(たとえば、音声認識、機械翻訳、テキストの要約、呪文修正、自動完了など)で使用されています。過去数年間で、ニューラルアプローチは、多くの言語モデルベンチマークで従来の統計的アプローチよりも優れた結果を達成してきました。さらに、最近の研究では、言語モデルの事前トレーニングが、機能ベースの戦略(ELMOなど)や微調整戦略(Openai GPT、BERTなど)、またはゼロショット設定(OpenAI GPT-2など)など、さまざまな方法で多くのNLPタスクを改善できることが示されています。
図1:言語モデリングを搭載した自動完了の例
# convert raw data
python preprocess/convert_data.py --dataset wikipedia --input_dir data/wikipedia/raw --output_dir data/wikipedia/processed --min_seq_len 0 --max_seq_len 512
# prepare vocab & embed files
python prepare_resource.py
--input_dir data/wikipedia/processed --max_word_size 512 --max_char_size 16
--full_embedding_file data/glove/glove.840B.300d.txt --word_embedding_file data/wikipedia/resource/lm.word.embed --word_embed_dim 300
--word_vocab_file data/wikipedia/resource/lm.word.vocab --word_vocab_size 100000
--char_vocab_file data/wikipedia/resource/lm.char.vocab --char_vocab_size 1000 # run experiment in train + eval mode
python language_model_run.py --mode train_eval --config config/config_lm_template.xxx.json
# run experiment in train only mode
python language_model_run.py --mode train --config config/config_lm_template.xxx.json
# run experiment in eval only mode
python language_model_run.py --mode eval --config config/config_lm_template.xxx.json # encode text as ELMo vector
python language_model_run.py --mode encode --config config/config_lm_template.xxx.json # random search hyper-parameters
python hparam_search.py --base-config config/config_lm_template.xxx.json --search-config config/config_search_template.xxx.json --num-group 10 --random-seed 100 --output-dir config/search # visualize summary via tensorboard
tensorboard --logdir=outputシーケンスが与えられた場合、双方向言語モデルは、シーケンスの前方の確率を計算します。
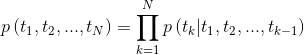
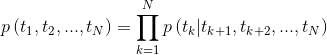
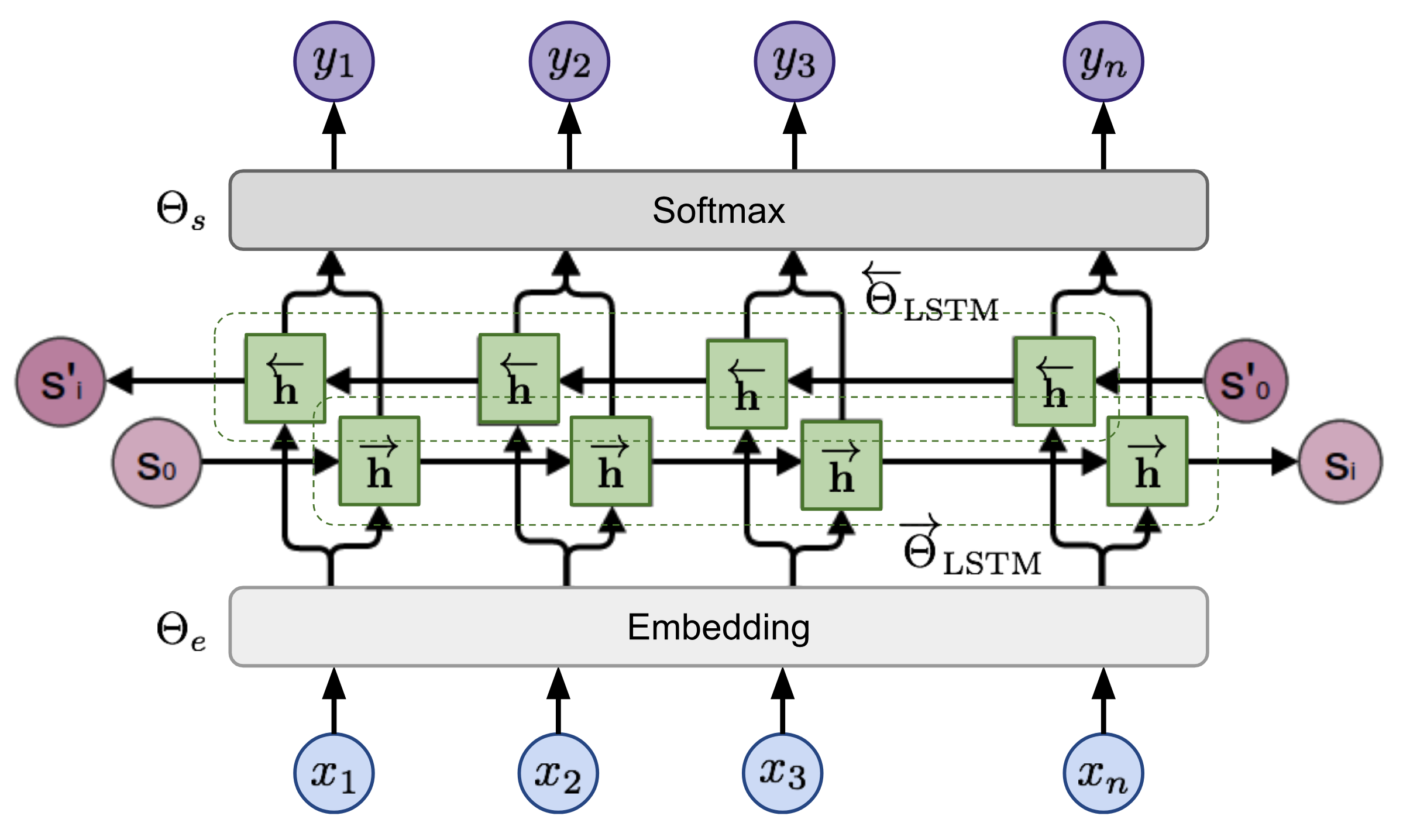
図2:双方向言語モデルアーキテクチャ(出典:一般化言語モデル)
このモデルは、前方方向と後方方向の負のログの可能性を共同で最小限に抑えることによってトレーニングされます。