language_model_tf
1.0.0
Language modeling is a task that assigns probabilities to sequences of words or various linguistic units (e.g. char, subword, sentence, etc.). Language modeling is one of the most important problem in modern natural language processing (NLP) and it's used in many NLP applications (e.g. speech recognition, machine translation, text summarization, spell correction, auto-completion, etc.). In the past few years, neural approaches have achieved better results than traditional statistical approaches on many language model benchmarks. Moreover, recent work has shown language model pre-training can improve many NLP tasks in different ways, including feature-based strategies (e.g. ELMo, etc.) and fine-tuning strategies (e.g. OpenAI GPT, BERT, etc.), or even in zero-shot setting (e.g. OpenAI GPT-2, etc.).
Figure 1: An example of auto-completion powered by language modeling
# convert raw data
python preprocess/convert_data.py --dataset wikipedia --input_dir data/wikipedia/raw --output_dir data/wikipedia/processed --min_seq_len 0 --max_seq_len 512
# prepare vocab & embed files
python prepare_resource.py
--input_dir data/wikipedia/processed --max_word_size 512 --max_char_size 16
--full_embedding_file data/glove/glove.840B.300d.txt --word_embedding_file data/wikipedia/resource/lm.word.embed --word_embed_dim 300
--word_vocab_file data/wikipedia/resource/lm.word.vocab --word_vocab_size 100000
--char_vocab_file data/wikipedia/resource/lm.char.vocab --char_vocab_size 1000# run experiment in train + eval mode
python language_model_run.py --mode train_eval --config config/config_lm_template.xxx.json
# run experiment in train only mode
python language_model_run.py --mode train --config config/config_lm_template.xxx.json
# run experiment in eval only mode
python language_model_run.py --mode eval --config config/config_lm_template.xxx.json# encode text as ELMo vector
python language_model_run.py --mode encode --config config/config_lm_template.xxx.json# random search hyper-parameters
python hparam_search.py --base-config config/config_lm_template.xxx.json --search-config config/config_search_template.xxx.json --num-group 10 --random-seed 100 --output-dir config/search# visualize summary via tensorboard
tensorboard --logdir=outputGiven a sequence, the bi-directional language model computes the probability of the sequence forward,
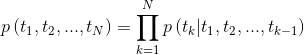
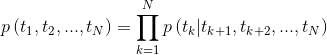
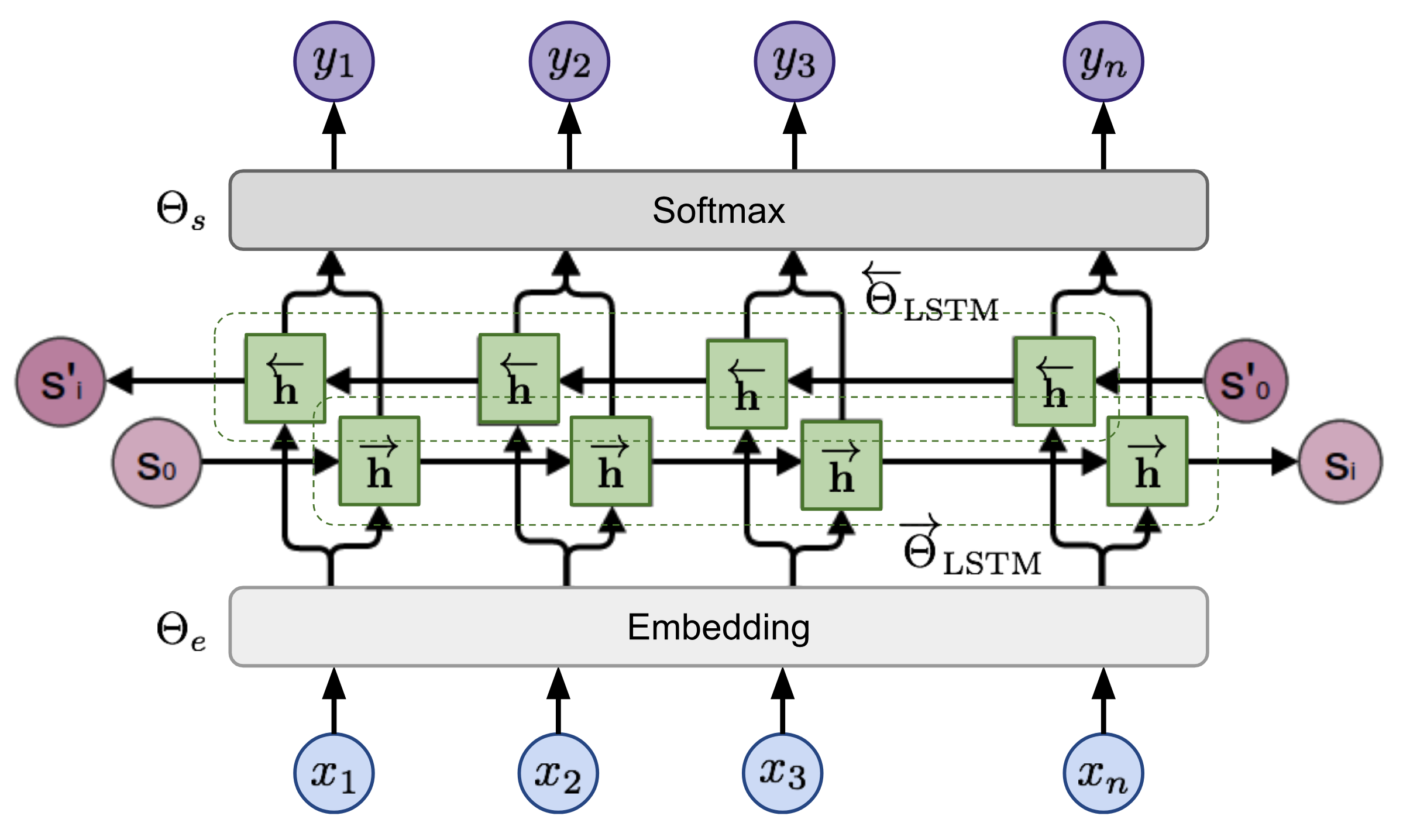
Figure 2: bi-directional language model architecture (source: Generalized Language Models)
the model is trained by jointly minimizing the negative log likelihood of the forward and backward directions,