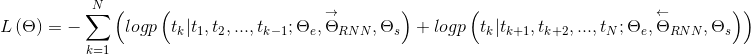language_model_tf
1.0.0
نمذجة اللغة هي مهمة تُحدد احتمالات لتسلسل الكلمات أو الوحدات اللغوية المختلفة (على سبيل المثال ، الكلمة الفرعية ، الجملة ، إلخ). تعتبر نمذجة اللغة واحدة من أهم مشكلة في معالجة اللغة الطبيعية الحديثة (NLP) وتستخدم في العديد من تطبيقات NLP (على سبيل المثال التعرف على الكلام ، الترجمة الآلية ، تلخيص النص ، تصحيح الإملاء ، الإكمال التلقائي ، إلخ). في السنوات القليلة الماضية ، حققت الأساليب العصبية نتائج أفضل من الأساليب الإحصائية التقليدية في العديد من معايير نموذج اللغة. علاوة على ذلك ، أظهر العمل الأخير أن نموذج اللغة قبل التدريب يمكن أن يحسن العديد من مهام NLP بطرق مختلفة ، بما في ذلك الاستراتيجيات القائمة على الميزات (على سبيل المثال Elmo ، إلخ) واستراتيجيات الضبط (مثل Openai GPT أو BERT ، إلخ) ، أو حتى في إعداد الصفر (مثل Openai GPT-2 ، إلخ).
الشكل 1: مثال على الإكمال التلقائي مدعوم بنمذجة اللغة
# convert raw data
python preprocess/convert_data.py --dataset wikipedia --input_dir data/wikipedia/raw --output_dir data/wikipedia/processed --min_seq_len 0 --max_seq_len 512
# prepare vocab & embed files
python prepare_resource.py
--input_dir data/wikipedia/processed --max_word_size 512 --max_char_size 16
--full_embedding_file data/glove/glove.840B.300d.txt --word_embedding_file data/wikipedia/resource/lm.word.embed --word_embed_dim 300
--word_vocab_file data/wikipedia/resource/lm.word.vocab --word_vocab_size 100000
--char_vocab_file data/wikipedia/resource/lm.char.vocab --char_vocab_size 1000 # run experiment in train + eval mode
python language_model_run.py --mode train_eval --config config/config_lm_template.xxx.json
# run experiment in train only mode
python language_model_run.py --mode train --config config/config_lm_template.xxx.json
# run experiment in eval only mode
python language_model_run.py --mode eval --config config/config_lm_template.xxx.json # encode text as ELMo vector
python language_model_run.py --mode encode --config config/config_lm_template.xxx.json # random search hyper-parameters
python hparam_search.py --base-config config/config_lm_template.xxx.json --search-config config/config_search_template.xxx.json --num-group 10 --random-seed 100 --output-dir config/search # visualize summary via tensorboard
tensorboard --logdir=outputبالنظر إلى تسلسل ، يحسب نموذج اللغة ثنائية الاتجاه احتمال التسلسل للأمام ،
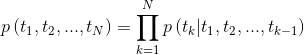
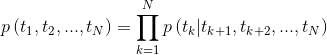
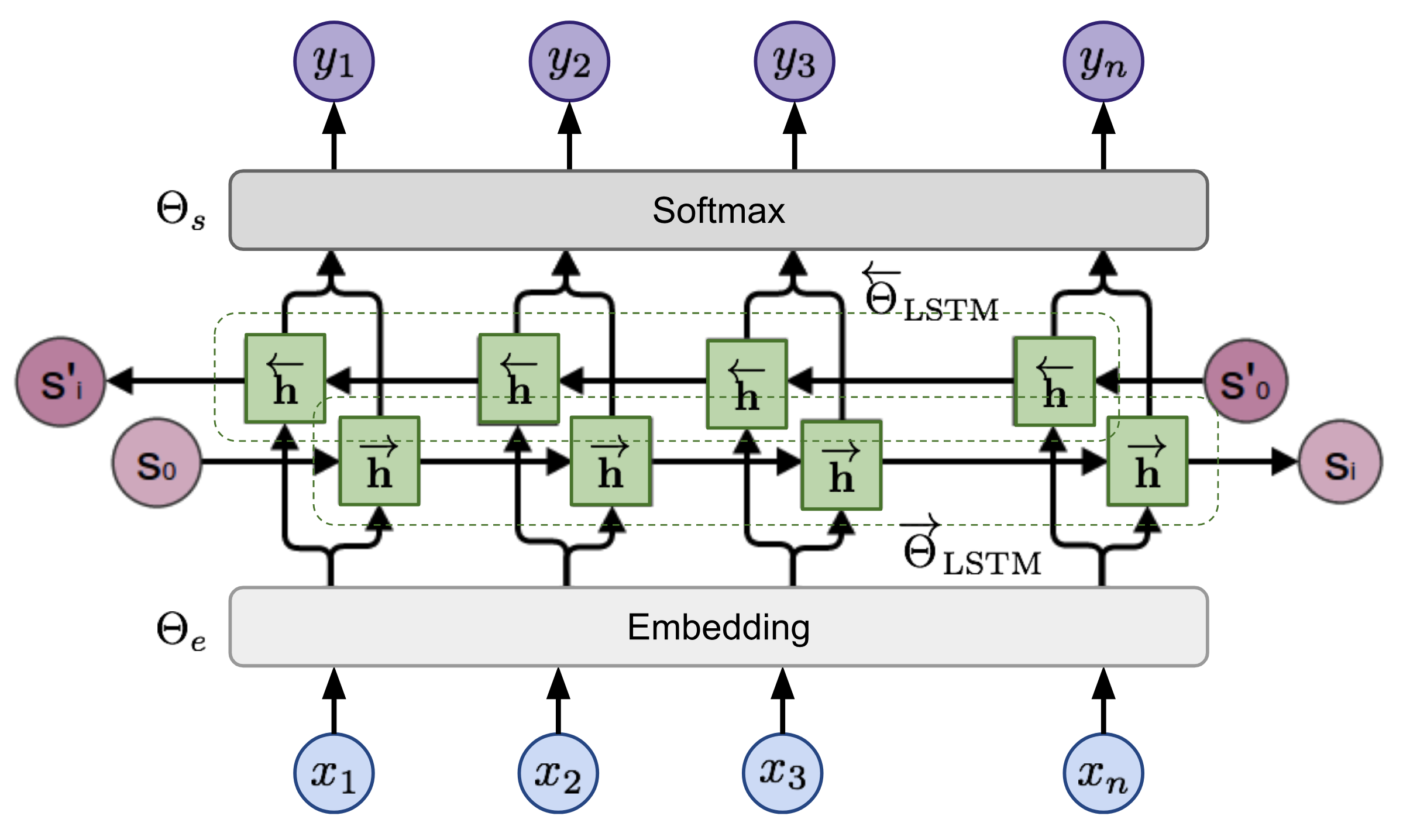
الشكل 2: بنية نموذج اللغة ثنائية الاتجاه (المصدر: نماذج اللغة المعممة)
يتم تدريب النموذج من خلال تقليل احتمال السجل السلبي للاتجاهات إلى الأمام والخلف ،