Awesome Efficient LLM
1.0.0
有效的大語言模型的精選清單
如果您想包含您的論文,或者需要更新任何詳細信息,例如會議信息或代碼URL,請隨時提交拉動請求。您可以通過填寫generate_item.py中的信息並執行python generate_item.py來生成所需的每篇論文的降價格式。我們非常感謝您對此列表的貢獻。另外,您可以通過向我發送紙張和代碼的鏈接給我發送電子郵件,我最早的方便時間將您的論文添加到列表中。
對於每個主題,我們都策劃了一系列推薦的論文列表,這些論文獲得了許多Github星星或引用。
| 標題和作者 | 介紹 | 鏈接 |
|---|---|---|
跨度:可以一擊精確修剪大型語言模型 Elias Frantar,Dan Alistarh | 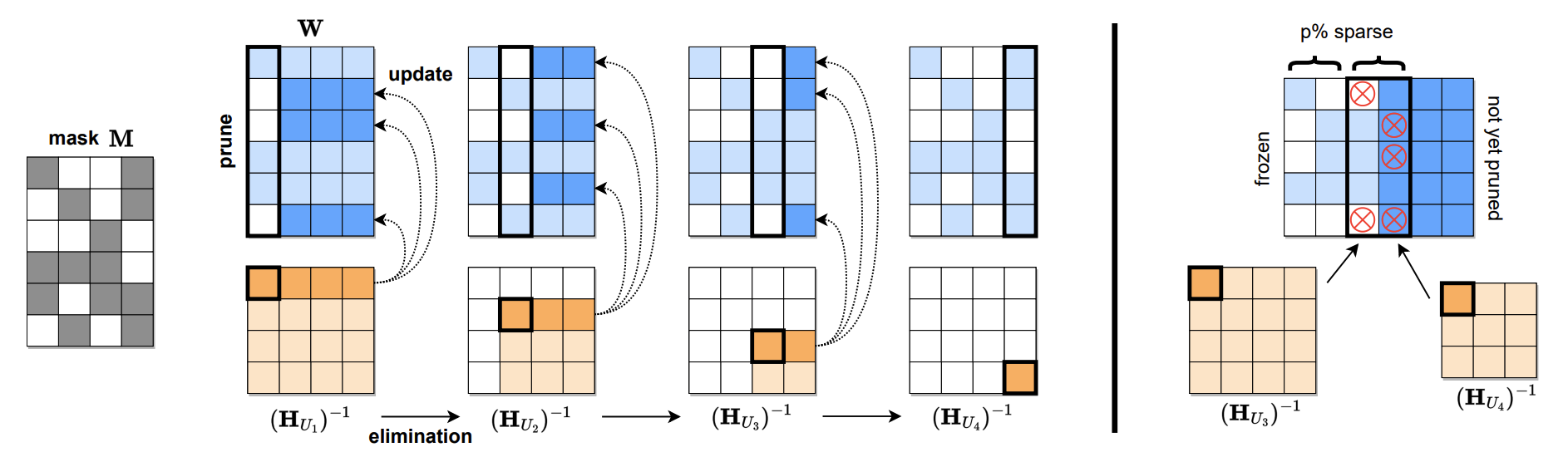 | Github紙 |
LLM-Pruner:關於大語言模型的結構修剪 Xinyin MA,Gongfan Fang,Xinchao Wang | 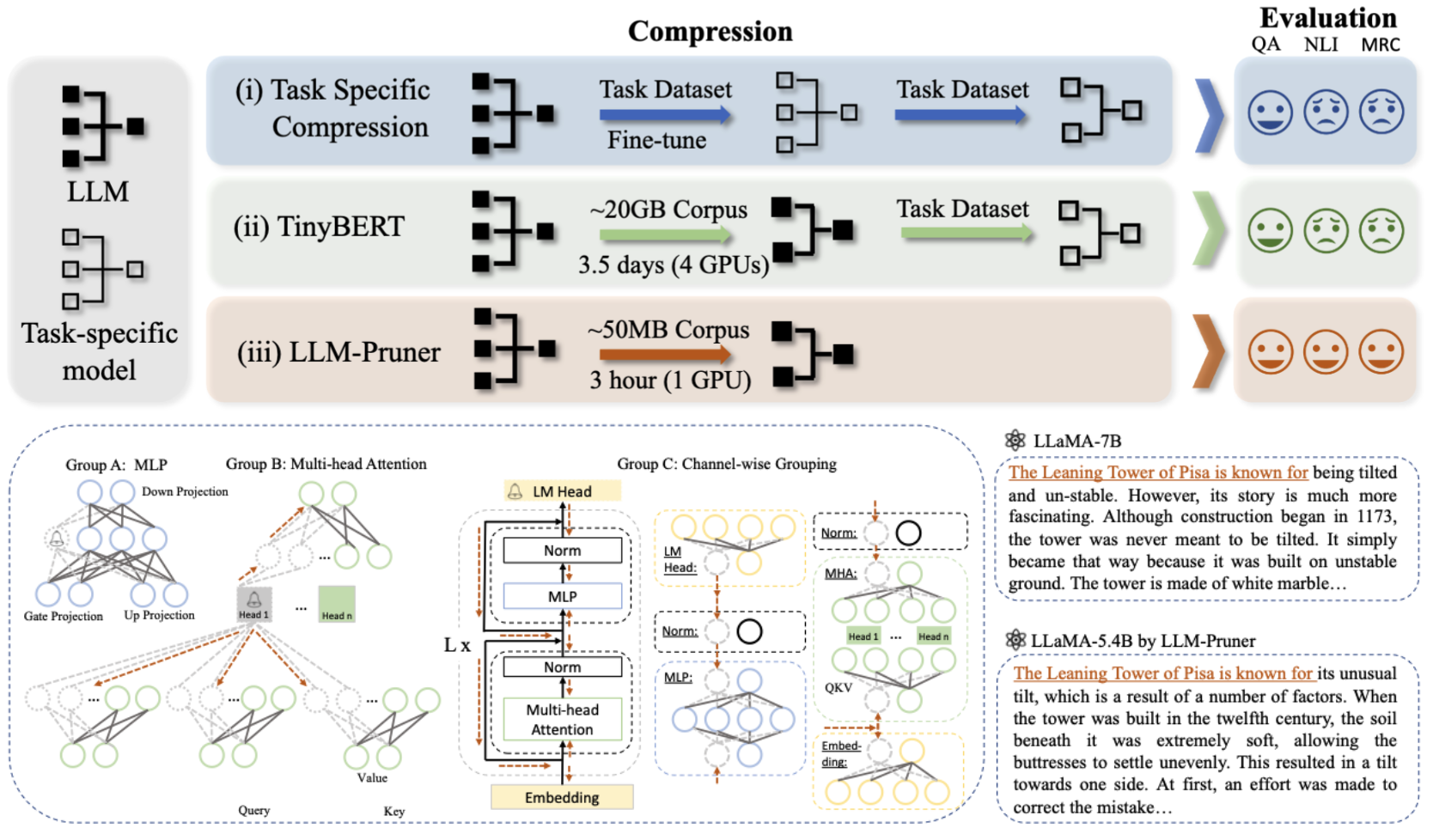 | Github紙 |
大語模型的簡單有效的修剪方法 Mingjie Sun,Zhuang Liu,Anna Bair,J。 ZicoKolter | 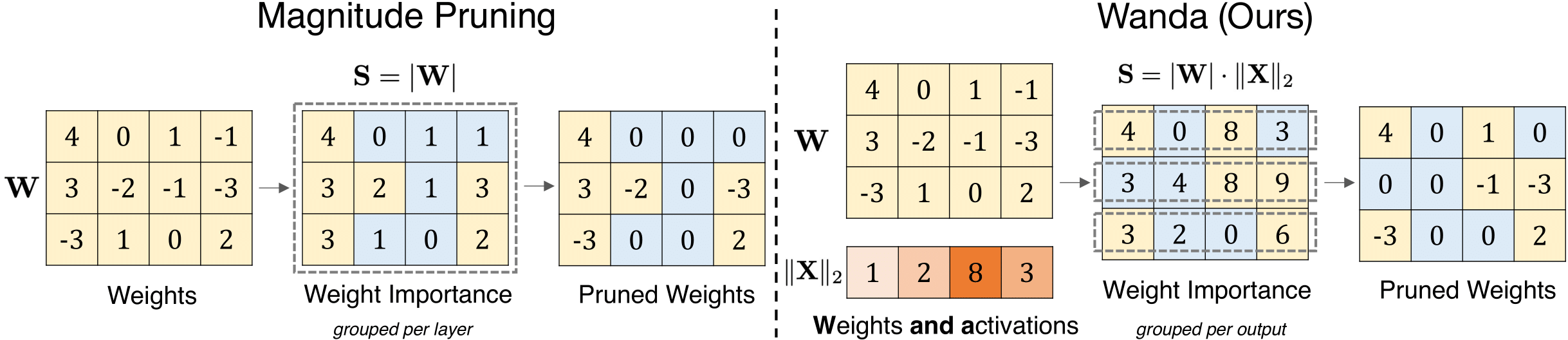 | github 紙 |
剪切的美洲駝:通過結構化修剪加速語言模型預訓練 Mengzhou Xia,Tianyu Gao,Zhiyuan Zeng,Danqi Chen | 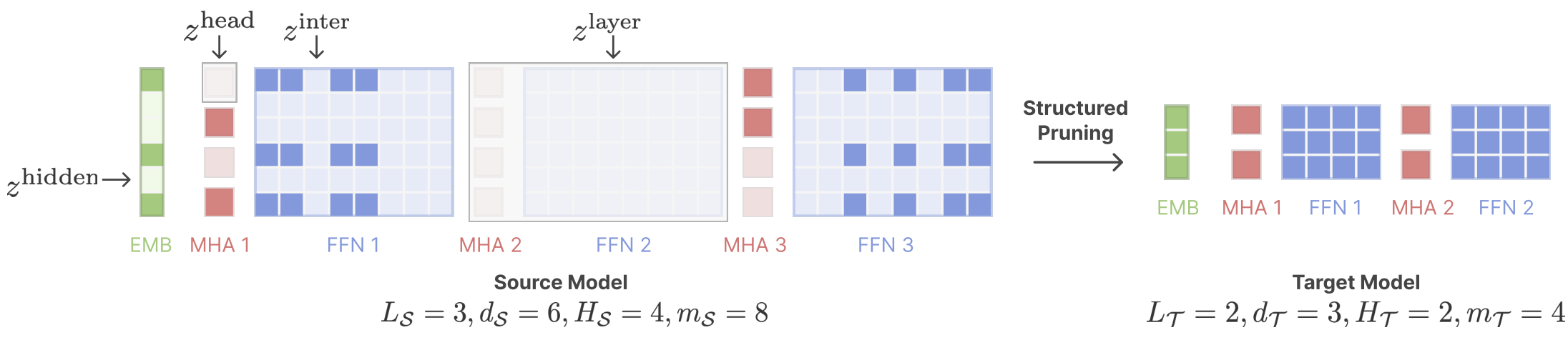 | github 紙 |
| 使用動態輸入修剪和高速緩存掩蓋的有效LLM推理 Marco Federici,Davide Belli,Mart Van Baalen,Amir Jalalirad,Andrii Skliar,Bence Major,Markus Nagel,Paul Whatmough | 紙 | |
| 難題:基於蒸餾的NAS用於推理優化的LLM Akhiad Bercovich,Tomer Ronen,Talor Abramovich,Nir Ailon,Nave Assaf,Mohammad Dabbah等人 | 紙 | |
LLMS中的重新評估層修剪:新的見解和方法 lu,Hao Cheng,Yujie Fang,Zeyu Wang,Jiaheng Wei,Dongwei Xu,Qi Xuan,Xiaoniu Yang,Zhaowei Zhu |  | github 紙 |
| 通過增強的激活方差 - 比較在大語言模型中的重要性和幻覺分析 Zichen Song,Sitan Huang,Yuxin Wu,中芬康 | 紙 | |
AMOEBALLM:構建任何形狀的大型語言模型,以進行有效和即時部署 Yonggan Fu,Zhongzhi Yu,Junwei Li,Jiayi Qian,Yongan Zhang,Xiangchi Yuan,Dachuan Shi,Roman Yakunin,Yingyan Celine Lin | github 紙 | |
| 修剪模型後訓練後訓練定律 小陳,Yuxuan Hu,Jing Zhang,Xiaokang Zhang,Cuiping Li,Hong Chen | 紙 | |
Drpruning:通過分佈強大的優化進行有效的大語言模型修剪 Hexuan Deng,Wenxiang Jiao,Xuebo Liu,Min Zhang,Zhaopeng tu |  | github 紙 |
稀疏法:朝著更大激活稀疏性的大型語言模型 Yuqi Luo,Chenyang Song,Xu Han,Yingfa Chen,Chaojun Xiao,Zhiyuan Liu,Maosong Sun |  | github 紙 |
| AVSS:通過激活方差 - 表格分析中的大語言模型中的層重要性評估 Zichen Song,Yuxin Wu,Sitan Huang,方芬 | 紙 | |
| 量身定制的lalama:通過特定於任務提示,在修剪的駱駝模型中優化幾乎沒有學習的學習 Danyal Aftab,史蒂文·戴維(Steven Davy) | 紙 | |
llmcbench:基準測試大型語言模型壓縮以進行有效部署 Ge Yang,Changyi He,Jinyang Guo,Jianyu Wu,Yifu ding,Aishan Liu,Haotong Qin,Pengliang JI,Xianglong Liu |  | github 紙 |
| 超過2:4:探索V:N:M稀疏性,用於高效變壓器推斷GPU Kang Zhao,Tao Yuan,Han Bao,Zhenfeng Su,Chang Gao,Zhaofeng Sun,Zichen Liang,Liping Jing,Jianfei Chen | 紙 | |
evopress:通過進化搜索邁向最佳動態模型壓縮 Oliver Sieberling,Denis Kuznedelev,Eldar Kurtic,Dan Alistarh |  | github 紙 |
| FEDSPALLM:大型語言模型的聯合修剪 Guangji Bai,Yijiang Li,Zilinghan Li,Liang Zhao,Kibaek Kim | 紙 | |
修剪基礎模型,以高精度而無需再培訓 Pu Zhao,Fei Sun,Xuan Shen,Pinrui Yu,Zhenglun Kong,Yanzhi Wang,Xue Lin | github 紙 | |
| 語言模型量化和修剪的自我校準 邁爾斯·威廉姆斯(Miles Williams | 紙 | |
| 提防修剪大語模型的校準數據 Yixin JI,Yang Xiang,Juntao Li,Qingrong Xia,Ping Li,Xinyu Duan,Zhefeng Wang,Min Zhang | 紙 | |
字母訓練:使用重尾的自我正則化理論,以改進大型語言模型的層次修剪 Haiquan Lu,Yefan Zhou,Shiwei Liu,Zhangyang Wang,Michael W. Mahoney,Yaoqing Yang | github 紙 | |
| 超越線性近似:一種新型的修剪方法,用於注意矩陣 Yingyu Liang,Jiangxuan Long,Zhenmei Shi,Zhao Song,Yufa Zhou | 紙 | |
disp-llm:大語模型無關維度的結構修剪 上海高,志林,丁·惠,唐寧,Yilin Shen,Hongxia Jin,Yen-chang hsu | 紙 | |
用於修剪大語模型中恢復質量的自DATA蒸餾 Vithursan Thangarasa,Ganesh Venkatesh,Nish Sinnadurai,Sean Lie | 紙 | |
| llm rank:一種修剪大語模型的理論方法 David Hoffmann,Kailash Budhathoki,Matthaeus Kleindessner | 紙 | |
C4數據集是用於修剪的最佳選擇嗎? LLM修剪的校準數據調查 Abhinav Bandari,Lu Yin,Cheng-Yu Hsieh,Ajay Kumar Jaiswal,Tianlong Chen,Li Shen,Ranjay Krishna,Shiwei Liu | github 紙 | |
| 通過神經元修剪來緩解副本學習中的複制偏見 Ameen Ali,Lior Wolf,Ivan Titov |  | 紙 |
SQFT:低精確稀疏基礎模型中的低成本模型適應 Juan Pablo Munoz,Jinjie Yuan,Nilesh Jain | 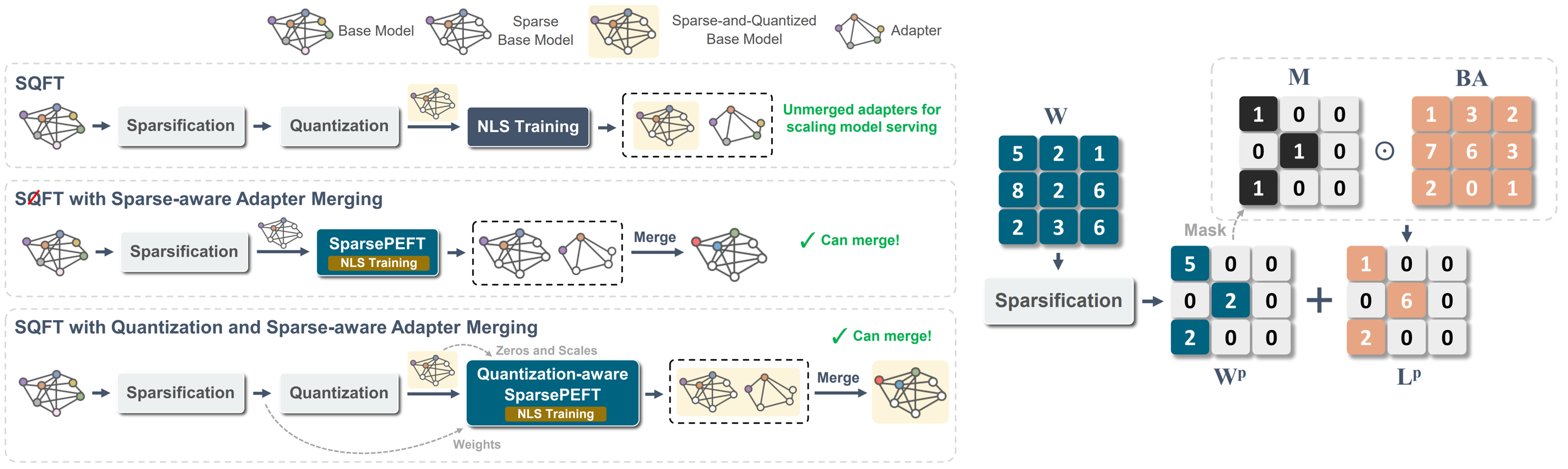 | github 紙 |
maskllm:大語言模型的可學習半結構性稀疏性 Gongfan Fang,Hongxu Yin,Saurav Muralidharan,Greg Heinrich,Jeff Pool,Jan Kautz,Pavlo Molchanov,Xinchao Wang | 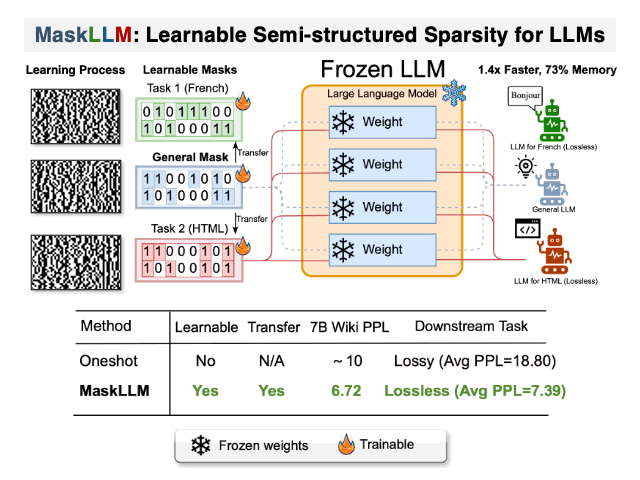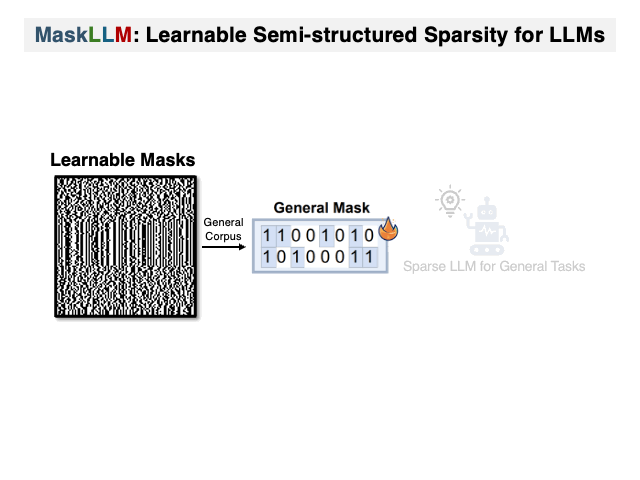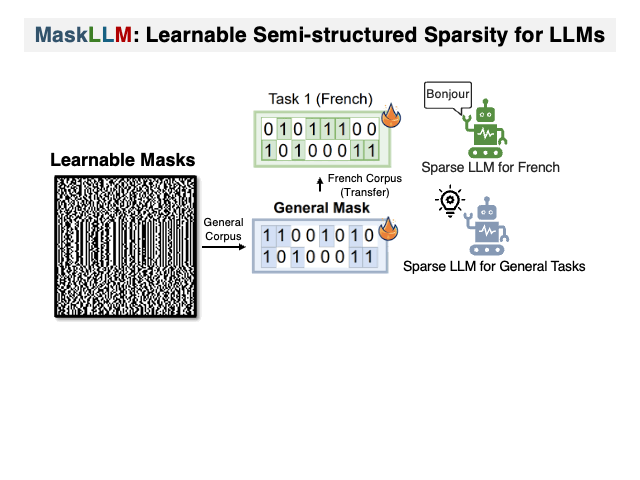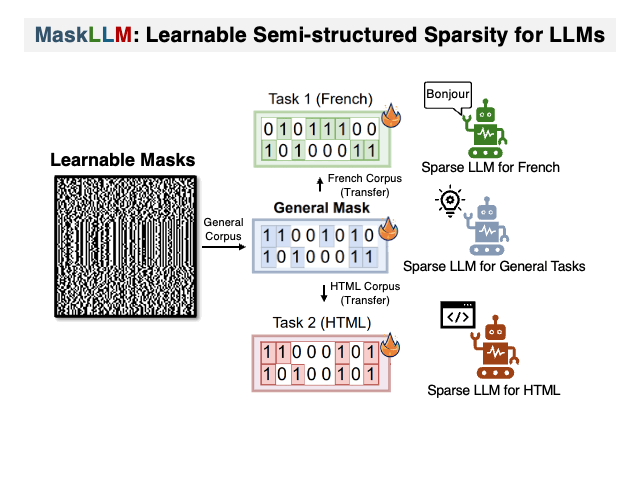 | github 紙 |
搜索有效的大語言模型 Xuan Shen,Pu Zhao,Yifan Gong,Zhenglun Kong,Zheng Zhan,Yushu Wu,Ming Lin,Chao Wu,Xue Lin,Yanzhi Wang | 紙 | |
CFSP:具有粗到1個激活信息的LLM的有效結構化修剪框架 Yuxin Wang,Minghua MA,Zekun Wang,Jingchang Chen,Huiming Fan,Liping Shan,Qing Yang,Dongliang Xu,Ming Liu,Bing Qin | github 紙 | |
| 燕麥:通過稀疏和低等級分解進行異常覺 斯蒂芬·張,瓦丹·帕皮恩 | 紙 | |
| KVPruner:結構修剪,以更快,記憶高效的大語言模型 Bo LV,Quan Zhou,Xuanang Ding,Yan Wang,Zeming MA | 紙 | |
| 評估壓縮技術對大語模型特定任務性能的影響 Bishwash Khanal,Jeffery M. Capone | 紙 | |
| Stun:結構化的,然後是無結構的修剪,用於可伸縮的MOE修剪 Jaeseong Lee,Seung-Won Hwang,Aurick Qiao,Daniel F Campos,Zhewei Yao,Yuxiong他 | 紙 | |
PAT:大語模型的修剪意識調整 Yijiang Liu,Huanrui Yang,Youxin Chen,Rongyu Zhang,Miao Wang,Yuan du,Li du |  | github 紙 |
| 標題和作者 | 介紹 | 鏈接 |
|---|---|---|
| 大型語言模型的知識蒸餾 Yuxian Gu,Li Dong,Furu Wei,Minlie Huang |  | github 紙 |
| 通過反饋驅動的蒸餾提高小語言模型的數學推理能力 Xunyu Zhu,Jian Li,Can Ma,Weiping Wang | 紙 | |
生成上下文蒸餾 Haebin Shin,Lei JI,Yeyun Gong,Sungdong Kim,Eunbi Choi,Minjoon Seo |  | github 紙 |
| 切換:與老師一起研究大語模型的知識蒸餾 Jahyun Koo,Yerin Hwang,Yongil Kim,Taegwan Kang,Hyunkyung Bae,Kyomin Jung |  | 紙 |
超越自動進展:通過時間進行自我介紹的快速llms 賈斯汀·德克納(Justin Deschenaux),卡格拉(Caglar Gulcehre) | github 紙 | |
| 大型語言模型的培訓前蒸餾:設計空間探索 Hao Peng,Xin LV,Yushi Bai,Zijun Yao,Jiajie Zhang,Lei Hou,Juanzi Li | 紙 | |
小型:培訓前語言模型的知識蒸餾 Yuxian Gu,Hao Zhou,Fandong Meng,Jie Zhou,Minlie Huang |  | github 紙 |
| 投機知識蒸餾:通過交錯抽樣彌合教師差距 Wenda Xu,Rujun Han,Zifeng Wang,Long T. Le,Dhruv Madeka,Lei Li,William Yang Wang,Rishabh Agarwal,Chen-Yu Lee,Tomas Pfister | 紙 | |
| 語言模型對齊的進化對比度蒸餾 朱利安·卡茲·薩穆爾(Julian Katz-Samuels),鄭李(Zheng Li),Yun Yun,Priyanka Nigam,Yi Xu,Vaclav Petricek,Bing Yin,Trishul Chilimbi | 紙 | |
| Babyllama-2:合奏縮放的模型始終超過有限數據的老師 Jean-Loup Tastet,Inar Timiryasov | 紙 | |
| Echoatt:參加,複製,然後調整以獲取更有效的大語言模型 Hossein Rajabzadeh,Aref Jafari,Aman Sharma,Benyamin Jami,Hyock Ju Kwon,Ali Ghodsi,Ali Ghodsi,Boxing Chen,Mehdi Rezagholizadeh | 紙 | |
Skintern:內部化符號知識,用於將更好的COT功能提煉成小語言模型 Huanxuan Liao,Shizhu He,Yupu Hao,Xiang Li,Yuanzhe Zhang,Kang Liu,Jun Zhao | github 紙 | |
LLMR:具有大型語言模型引起的獎勵的知識蒸餾 Dongheng Li,Yongchang Hao,Lili Mou | 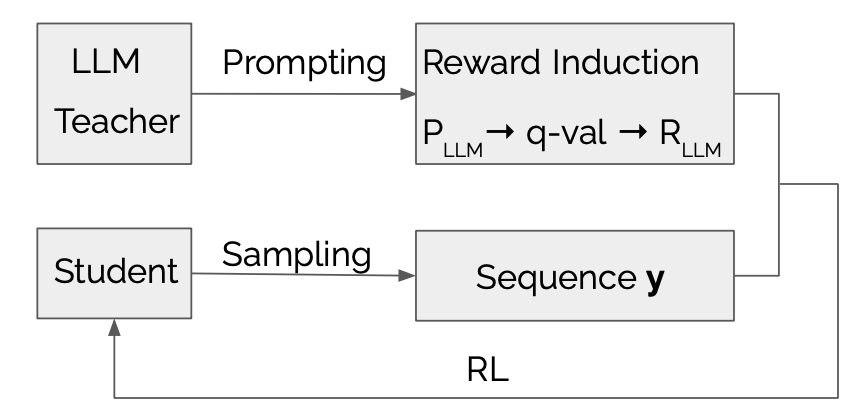 | github 紙 |
| 探索和增強自回歸語言模型知識蒸餾中分配的轉移 Jun Rao,Xuebo Liu,Zepeng Lin,Liang ding,Jing Li,Dacheng Tao | 紙 | |
| 有效的知識蒸餾:通過教師模型洞察力賦予小語言模型 Mohamad Ballout,Ulf Krumnack,Gunther Heidemann,Kai-uweKühnberger | 紙 | |
美洲駝的曼巴(Mamba):蒸餾和加速混合模型 Junxiong Wang,Daniele Paliotta,Avner May,Alexander M. Rush,Tri Dao | github 紙 |
| 標題和作者 | 介紹 | 鏈接 |
|---|---|---|
GPTQ:生成預訓練的變壓器的準確訓練後量化 Elias Frantar,Saleh Ashkboos,Torsten Hoefler,Dan Alistarh | 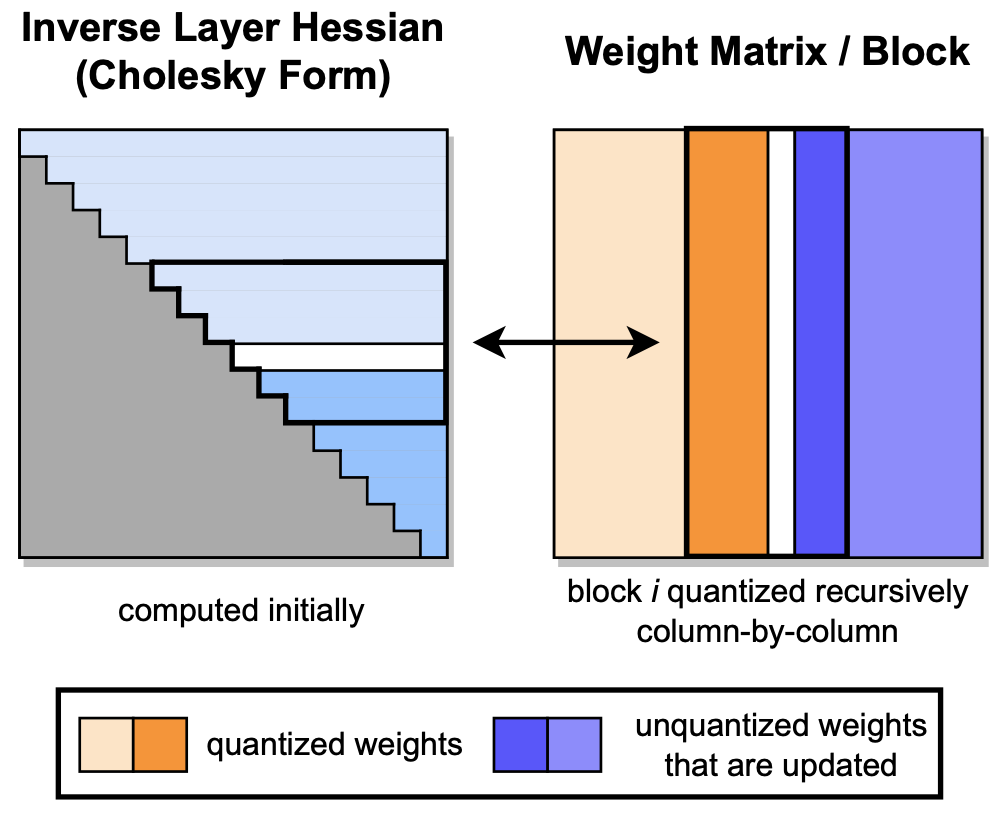 | github 紙 |
平滑:大語言模型的準確有效的培訓量化 Guangxuan Xiao,Ji Lin,Mickael Seznec,Hao Wu,Julien Demouth,Song Han | 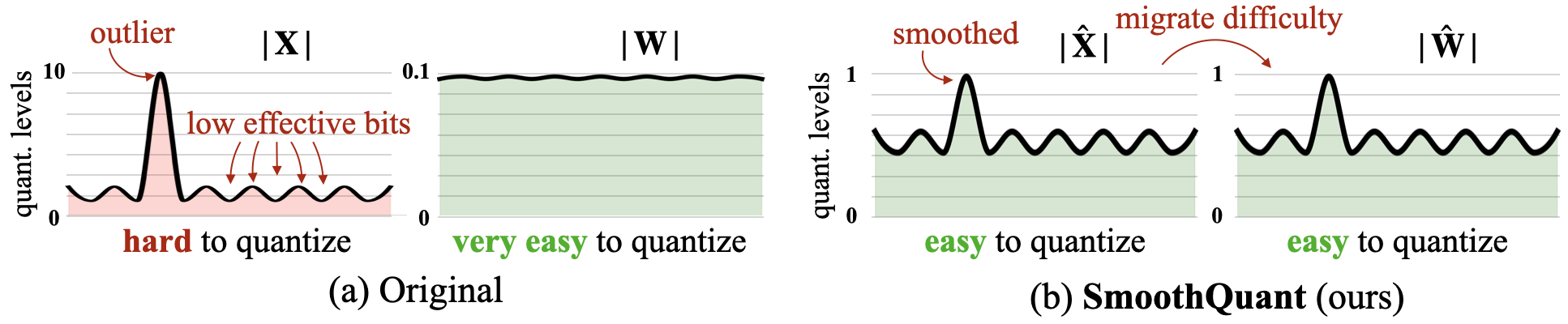 | github 紙 |
AWQ:LLM壓縮和加速度的激活意識重量量化 Ji Lin,Jiaming Tang,Haotian Tang,Shang Yang,Xingyu Dang,Song Han | 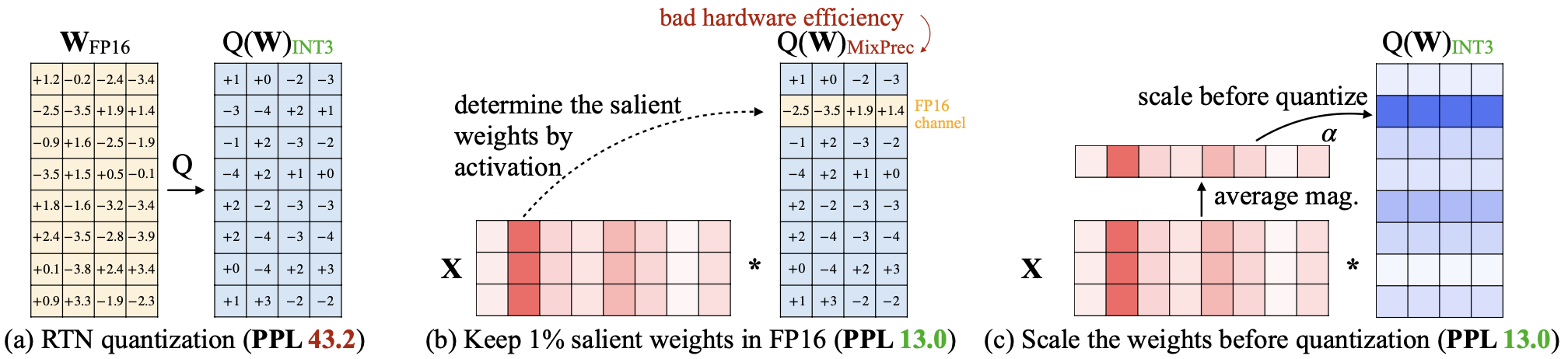 | github 紙 |
全語:大語言模型的全向校準量化 Wenqi Shao,Mengzhao Chen,Zhaoyang Zhang,Peng Xu,Lirui Zhao,Zhiqian Li,Kaipeng Zhang,Peng Gao,Yu Qiao,Ping Luo | 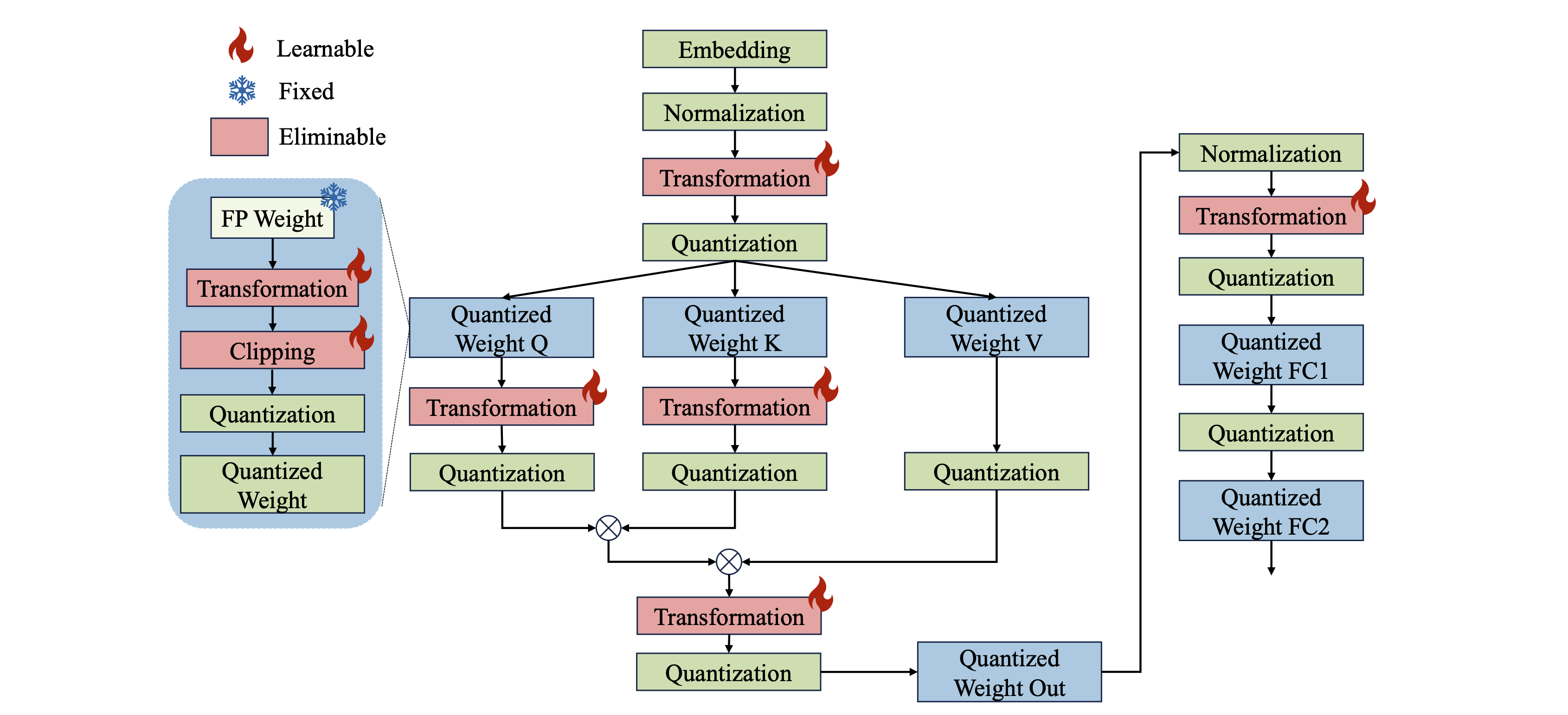 | github 紙 |
| 略讀:任何位量化都以推動訓練後量化的限制 Runsheng Bai,Qiang Liu,Bo Liu | 紙 | |
| cptquant-一種新穎的混合精度訓練後量化技術,用於大語言模型 Amitash Nanda,Sree Bhargavi Balija,Debashis Sahoo | 紙 | |
ANDA:使用可變長度分組激活數據格式解鎖有效的LLM推論 Chao Fang,Man Shi,Robin Geens,Arne Symons,Zhongfeng Wang,Marian Verhelst | 紙 | |
| Mixpe:有效LLM推理的量化和硬件共同設計 Yu Zhang,Mingzi Wang,Lancheng Zou,Wulong Liu,Hui-Ling Zhen,Mingxuan Yuan,Bei Yu | 紙 | |
BitMod:Datatype LLM加速度的比特系列混合物 Yuzong Chen,Ahmed F. Abouelhamayed,Xilai dai,Yang Wang,Marta Andronic,George A. Constantinides,Mohamed S. Abdelfattah | github 紙 | |
| AMXFP4:針對4位LLM推斷的不對稱顯微鏡浮點的馴服激活異常值 Janghwan Lee,Jiwoong Park,Jinseok Kim,Yongjik Kim,Jungju OH,Jinwook OH,Jungwook Choi | 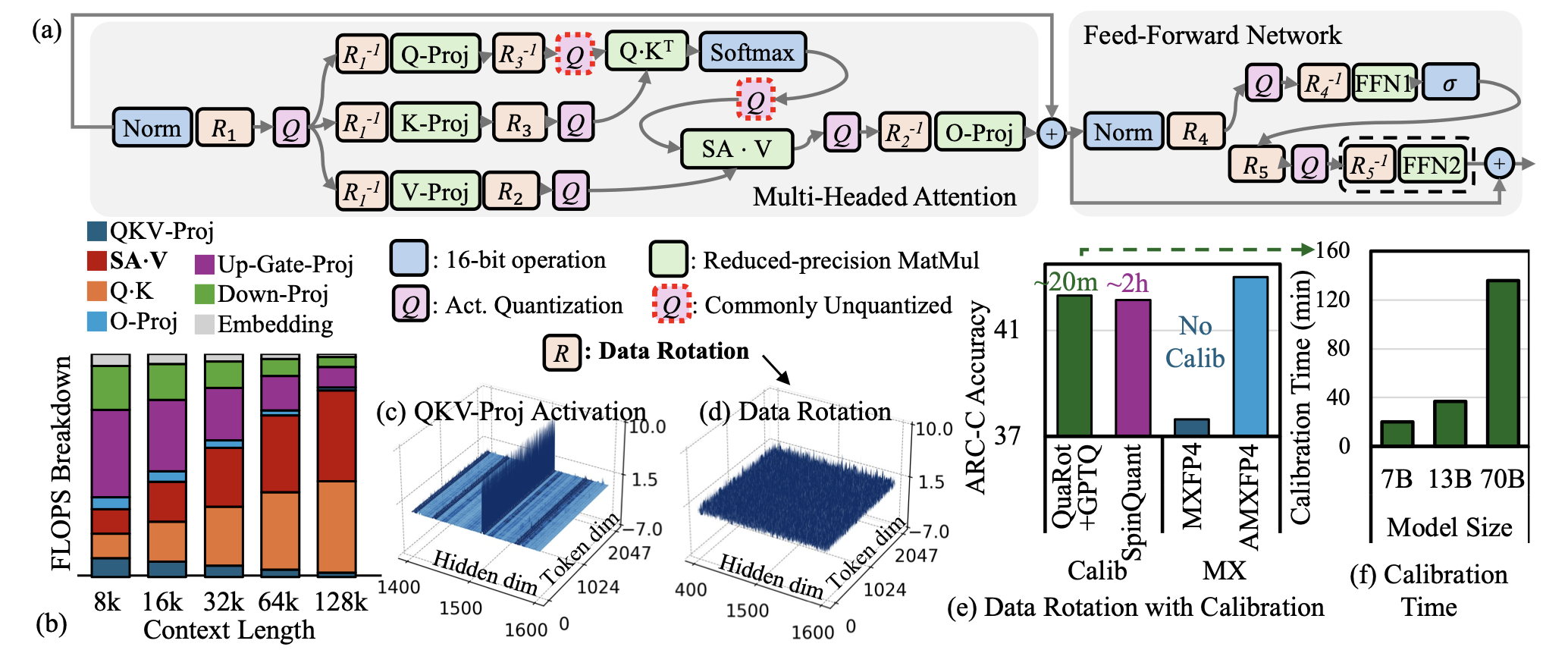 | 紙 |
| BI-MAMBA:邁向準確的1位狀態空間模型 Shengkun Tang,Liqun MA,Haonan Li,Mingjie Sun,Zhiqiang Shen | 紙 | |
| “給我BF16還是給我死亡”? LLM量化中的準確性績效權衡取捨 Eldar Kurtic,Alexandre Marques,Shubhra Pandit,Mark Kurtz,Dan Alistarh | 紙 | |
| GWQ:大語言模型的梯度感知權重量化 Yihua Shao,Siyu Liang,小林,Zijian Ling,Zixian Zhu等人 | 紙 | |
| 關於大語模型的量化技術的全面研究 Jiedong Lang,Zhehao Guo,Shuyu Huang | 紙 | |
| 比特網A4.8:1位LLM的4位激活 Hongyu Wang,MA,Furu Wei | 紙 | |
Tesseraq:超低位LLM通過塊重建後訓練後量化 Yuhang Li,Priyadarshini Panda | 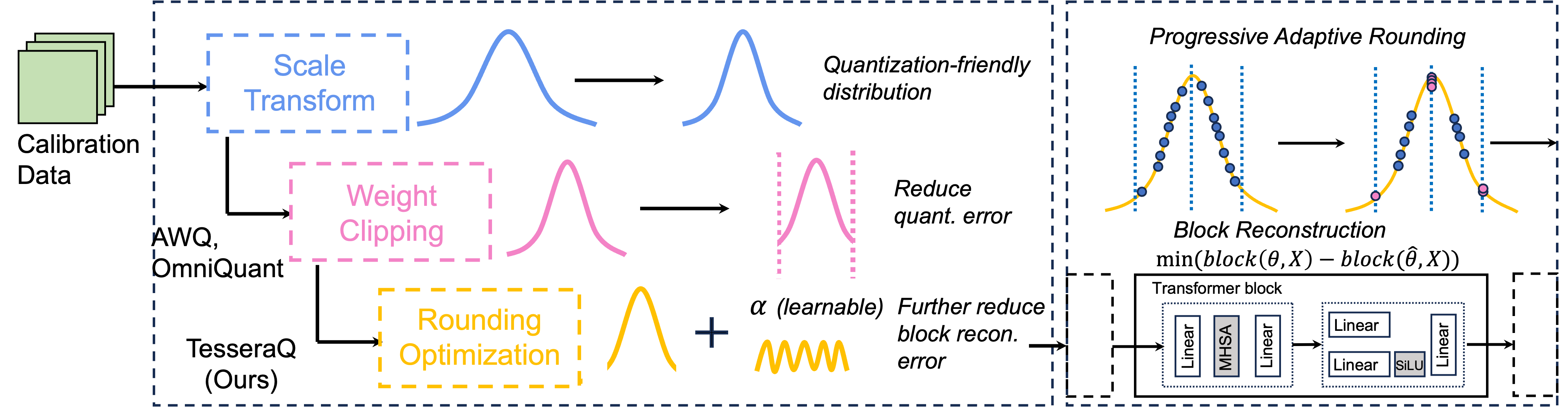 | github 紙 |
BITSTACK:在可變內存環境中壓縮大語言模型的細粒度尺寸控制 Xinghao Wang,Pengyu Wang,Bo Wang,Dong Zhang,Yunhua Zhou,Xipeng Qiu | 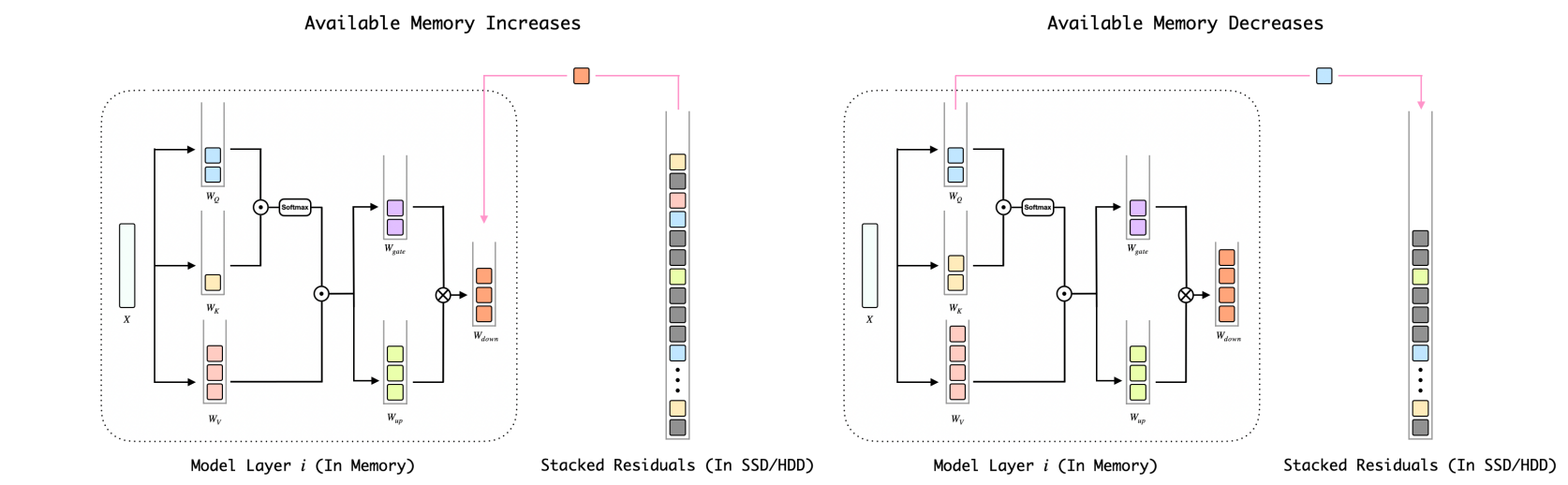 | github 紙 |
| 推理加速策略對LLM偏差的影響 Elisabeth Kirsten,Ivan Habernal,Vedant Nanda,Muhammad Bilal Zafar | 紙 | |
| 了解大語言模型的低精度訓練後量化的難度 Zifei Xu,Sayeh Sharify,Wanzin Yazar,Tristan Webb,Xin Wang | 紙 | |
1位AI Instra:第1.1部分,快速而無損的BITNET B1.58推斷CPU 金正恩(Jinheng Wang),漢港(Hansong Zhou),Ting Song,Shaoguang Mao,Shuming Ma,Hongyu Wang,Yan Xia,Furu Wei | github 紙 | |
| Quailora:Lora的量化初始化 Neal Lawton,Aishwarya Padmakumar,Judith Gaspers,Jack Fitzgerald,Anoop Kumar,Greg Ver Steeg,Aram Galstyan | 紙 | |
| 評估量化的大型語言模型,用於低資源語言基准上的代碼生成 Enkhbold Nyamsuren | 紙 | |
Squeezellm:密集量的量化 Sehoon Kim,Coleman Hooper,Amir Gholami,Zhen Dong,Xiuyu Li,Sheng Shen,Michael W. Mahoney,Kurt Keutzer | 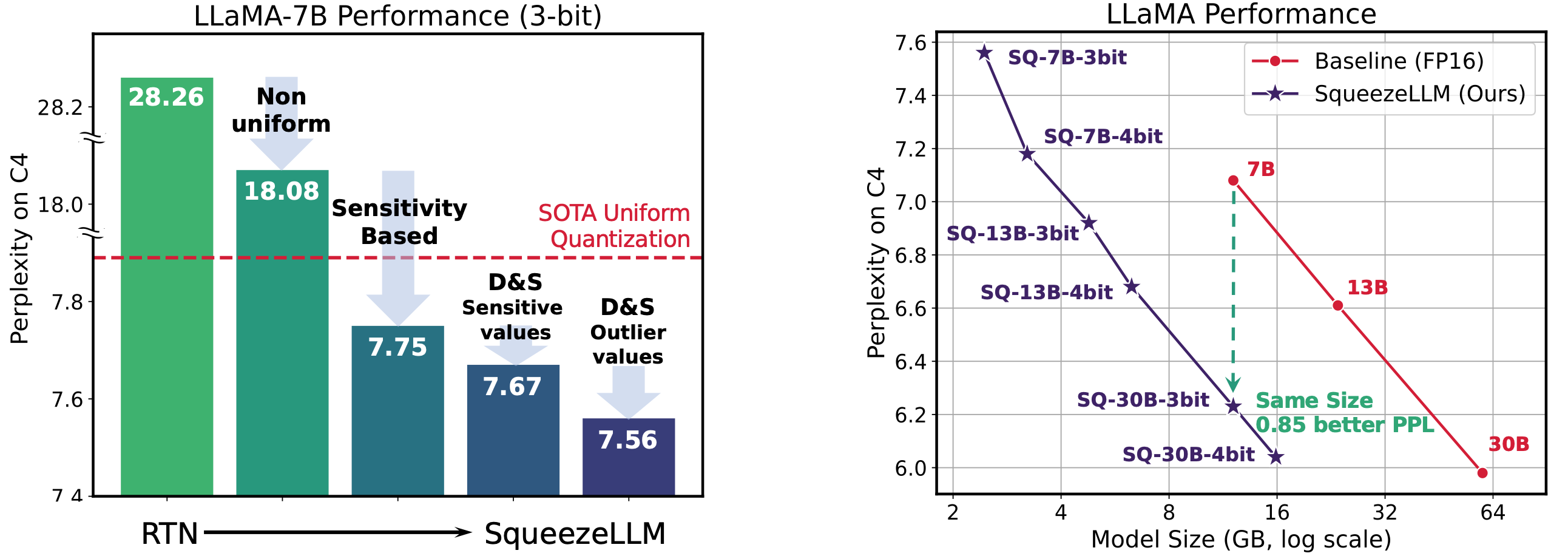 | github 紙 |
| LLM的金字塔載體量化 Tycho Fa van der Ouderaa,Maximilian L. Croci,Agrin Hilmkil,James Hensman | 紙 | |
| 幼苗:將LLM的重量壓縮到偽隨機發電機的種子中 Rasoul Shafipour,David Harrison,Maxwell Horton,Jeffrey Marker,Houman Bedayat,Sachin Mehta,Mohammad Rastegari,Mahyar Najibi,Saman Naderiparizi | 紙 | |
llm量化的扁平度很重要 Yuxuan Sun,Ruikang Liu,Haoli Bai,Han Bao,Kang Zhao,Yuening Li,Jiaxin Hu,Xianzhi Yu,Lu Hou,Chun Yuan,Xin Jiang,wulong Liu,Jun Yao,Jun Yao | github 紙 | |
Slim:單發量化的稀疏加上LLM的低級別近似值 Mohammad Mozaffari,Maryam Mehri Dehnavi | github 紙 | |
| 訓練後量化法律量化大型語言模型 Zifei Xu,Alexander Lan,Wanzin Yazar,Tristan Webb,Sayeh Shosify,Xin Wang | 紙 | |
| 連續近似來改善LLM的量化意識培訓 他李,江港,Yuanzhuo Wu,Snehal Adbol,Zonglin li | 紙 | |
DAQ:LLMS的密度感知訓練後重量量化 楊倫,春 | github 紙 | |
Quamba:選擇性狀態空間模型的訓練後量化配方 Hung-Yueh Chiang,Chi-Chih Chang,Natalia Frumkin,Kai-Chiang Wu,Diana Marculescu | github 紙 | |
| ASYMKV:通過通過層的不對稱量化配置啟用KV高速緩存的1位量化 Qian Tao,Wenyuan Yu,Jingren Zhou | 紙 | |
| 大型語言模型的渠道混合精確量化 Zihan Chen,Bike Xie,Jundong Li,Cong Shen | 紙 | |
| 進行有效LLM推斷的漸進混合精液解碼 Hao Mark Chen,Fuwen Tan,Alexandros Kouris,Royson Lee,Hongxiang粉絲,Stylianos I. Venieris | 紙 | |
EXAQ:LLMS加速的指數意識量化 Moran Shkolnik,Maxim Fishman,Brian Chmiel,Hilla Ben-Yaacov,Ron Banner,Kfir Yehuda Levy | 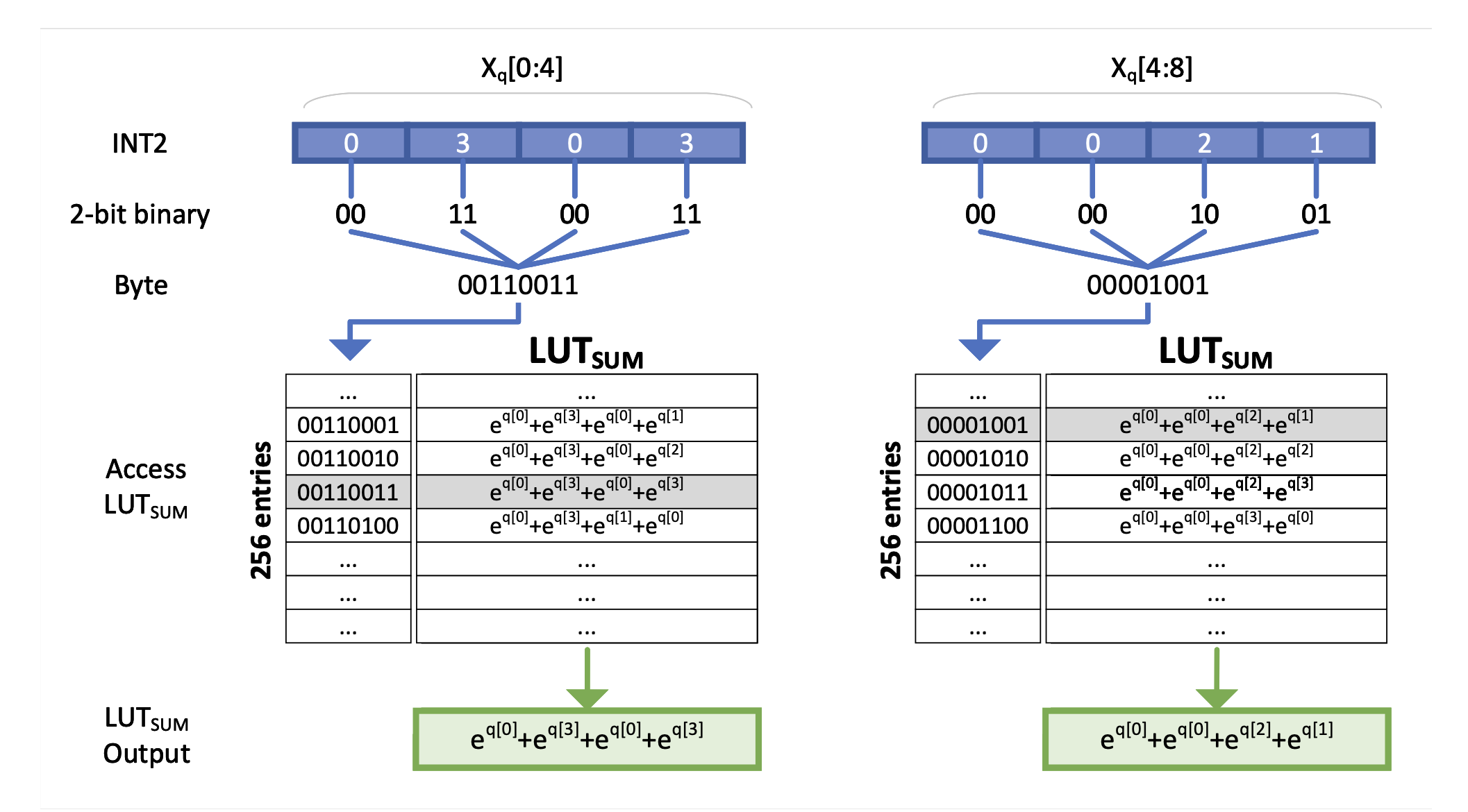 | github 紙 |
前綴:靜態量化通過LLMS中的前綴異常值擊敗動態 Mengzhao Chen,Yi Liu,Jiahao Wang,Yi bin,Wenqi Shao,Ping Luo | github 紙 | |
通過添加量化對大語言模型的極端壓縮 Vage Egiazarian,Andrei Panferov,Denis Kuznedelev,Elias Frantar,Artem Babenko,Dan Alistarh | 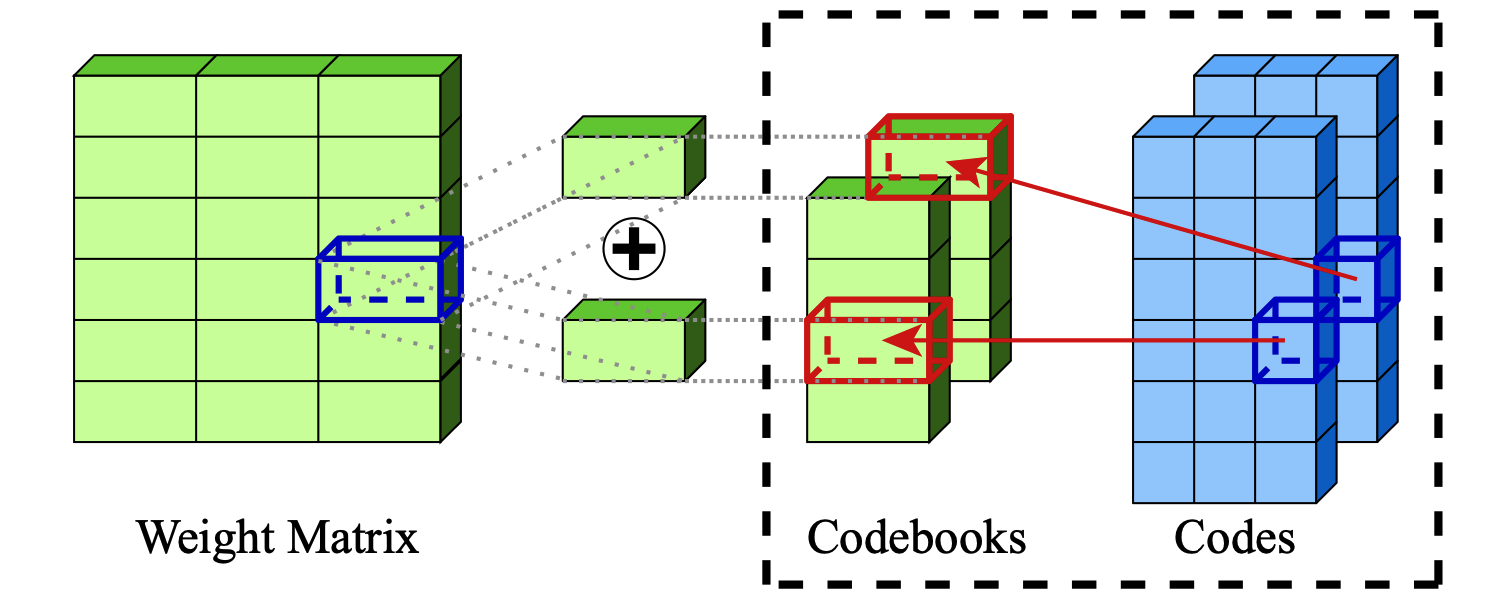 | github 紙 |
| 大語模型中混合量化的縮放定律 Zeyu Cao,Cheng Zhang,Pedro Gimenes,Jianqiao Lu,Jianyi Cheng,Yiren Zhao | 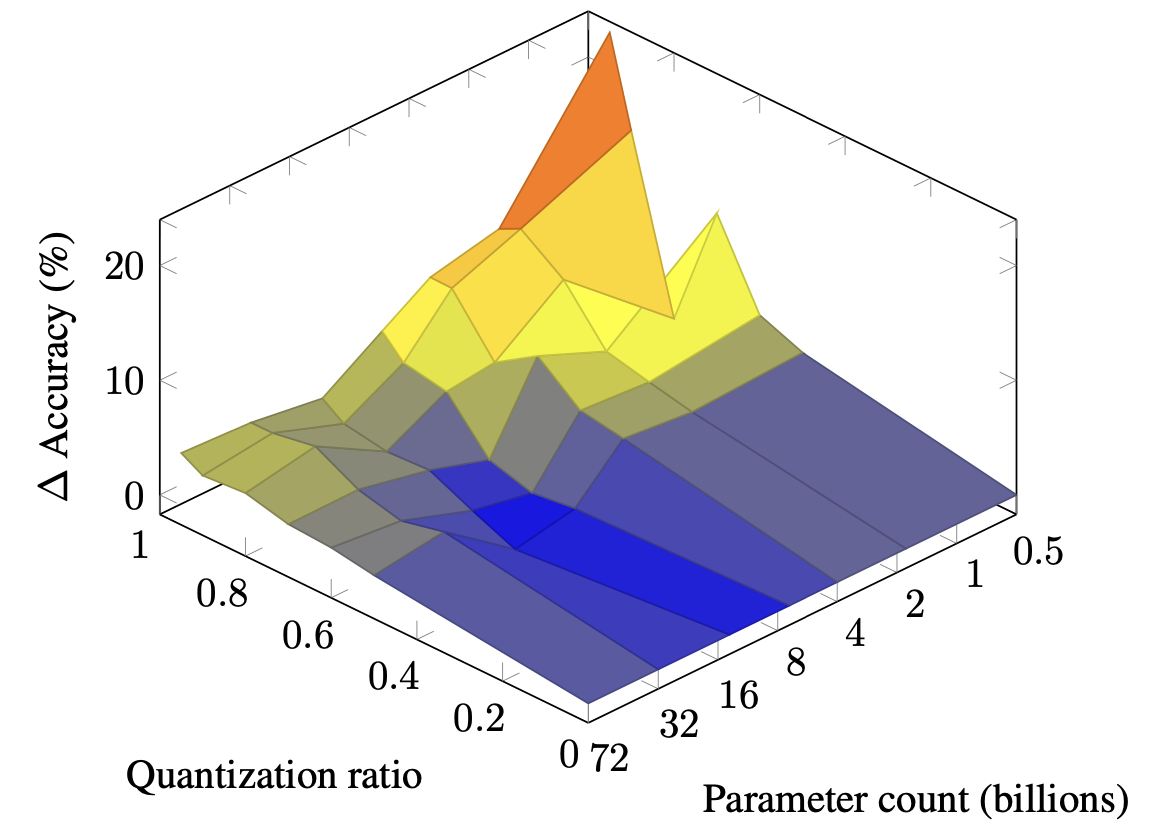 | 紙 |
| PARMBENCH:移動平台上壓縮大語言模型的全面基準 Yilong Li,Jingyu Liu,Hao Zhang,M Badri Narayanan,Utkarsh Sharma,Shuai Zhang,Pan Hu,Yijing Zeng,Jayaram Raghuram,Suman Banerjee, | 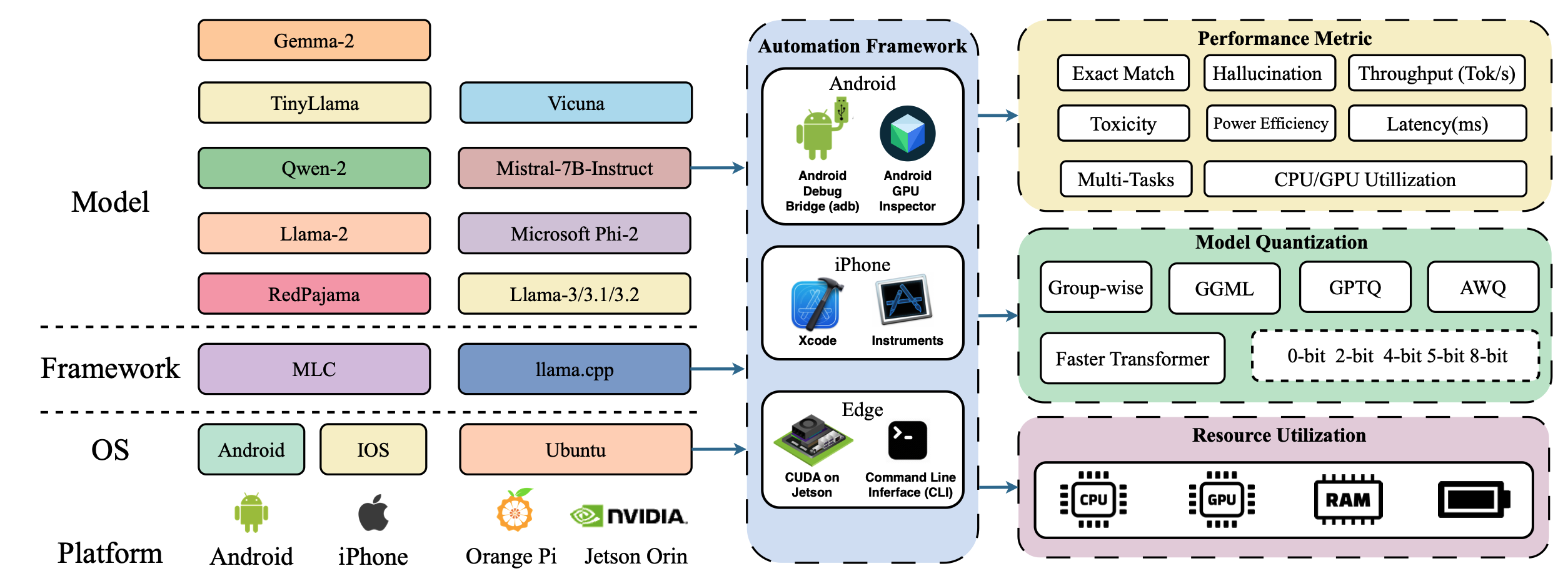 | 紙 |
| CrossQuant:一種具有較小量化內核的訓練後量化方法,用於精確的大語言模型壓縮 Wenyuan Liu,Xindian MA,Peng Zhang,Yan Wang | 紙 | |
| SageTention:插件推理的準確8位注意力 Jintao Zhang,Jia Wei,Pengle Zhang,Jun Zhu,Jianfei Chen | 紙 | |
| 增加節能語言模型所需的一切 Hongyin Luo,Wei Sun | 紙 | |
VPTQ:大語言模型的極端低位矢量訓練後量化 Yifei Liu,Jicheng Wen,Yang Wang,Shengyu Ye,Li Lyna Zhang,Ting Cao,Cheng Li,Mao Yang | 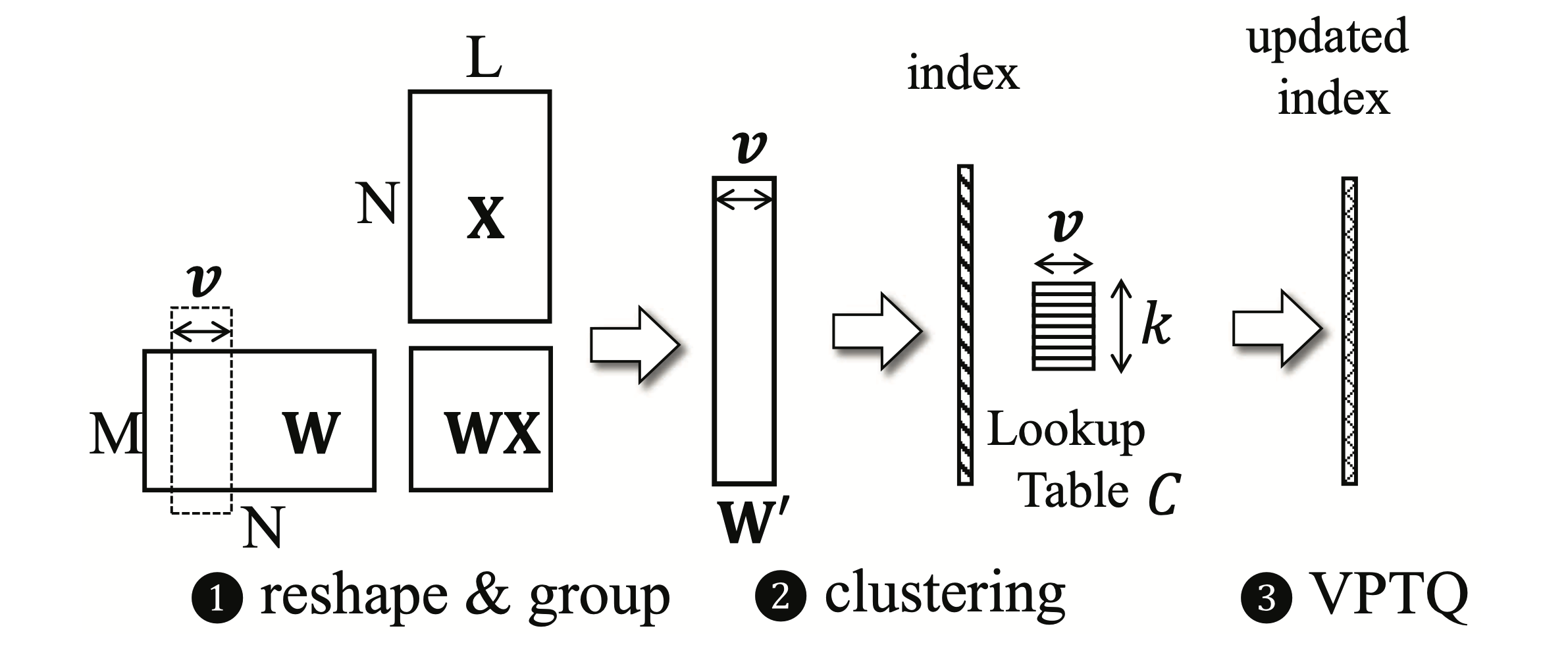 | github 紙 |
int-flashattention:引起int8量化的閃光燈 Shimao Chen,Zirui Liu,Zhiying Wu,Ce Zheng,Peizhuang Cong,Zihan Jiang,Yuhan Wu,Lei Su,Tong Yang | github 紙 | |
| 累加器感知的訓練後量化 Ian Colbert,Fabian Grob,Giuseppe Franco,Jinjie Zhang,Rayan Saab | 紙 | |
DUQUANT:通過雙重變換分發異常值使更強的量化LLM Haokun Lin,Haobo Xu,Yichen Wu,Jingzhi Cui,Yingtao Zhang,Linzhan Mou,Linqi Song,Zhenan Sun,Ying Wei | 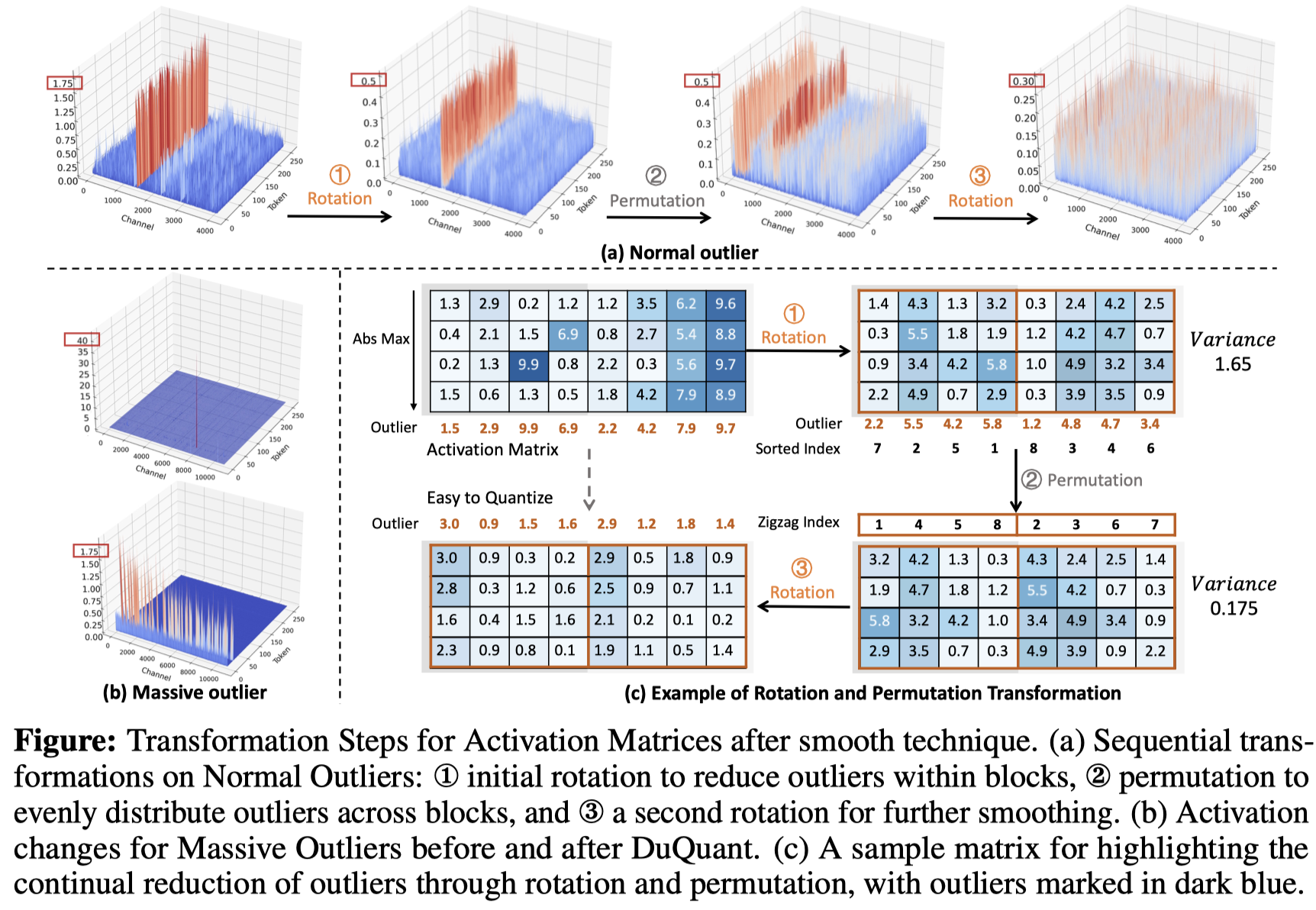 | github 紙 |
| 對量化指導調整的大語言模型的全面評估:最高405B的實驗分析 Jemin Lee,Sihyeong Park,Jinse Kwon,Jihun OH,Yongin Kwon | 紙 | |
| 通過通道量化的Llama3-70b的獨特性:一項經驗研究 Minghai Qin | 紙 |
| 標題和作者 | 介紹 | 鏈接 |
|---|---|---|
DEJA VU:推理時有效LLM的上下文稀疏性 Zichang Liu,Jue Wang,Tri Dao,Tianyi Zhou,Binhang Yuan,Zhao Song,Anshumali Shrivastava,Ce Zhang,Yuandong Tian,Christopher RE,Beidi Chen,Beidi Chen | 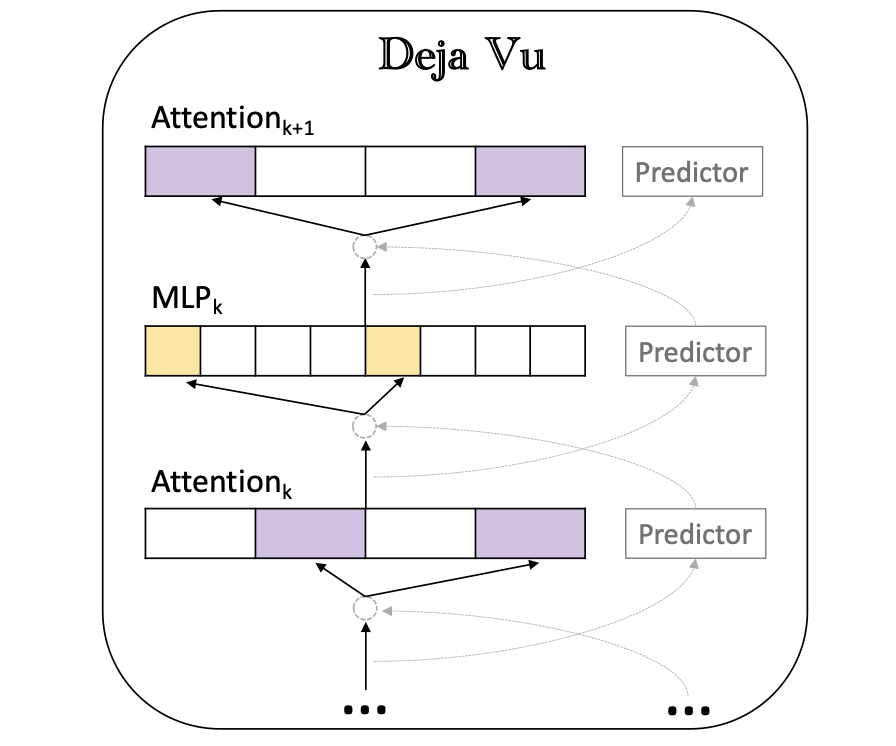 | github 紙 |
Specinfer:加速使用投機推理和令牌樹驗證的生成LLM Xupeng Miao,Gabriele Oliaro,Zhihao Zhang,Xinhao Cheng,Zeyu Wang,Rae Ying Ying Yee Wong,Zhuoming Chen,Daiyaan Arfeen,Reyna Abhyankar,Zhihao Jia Jia | 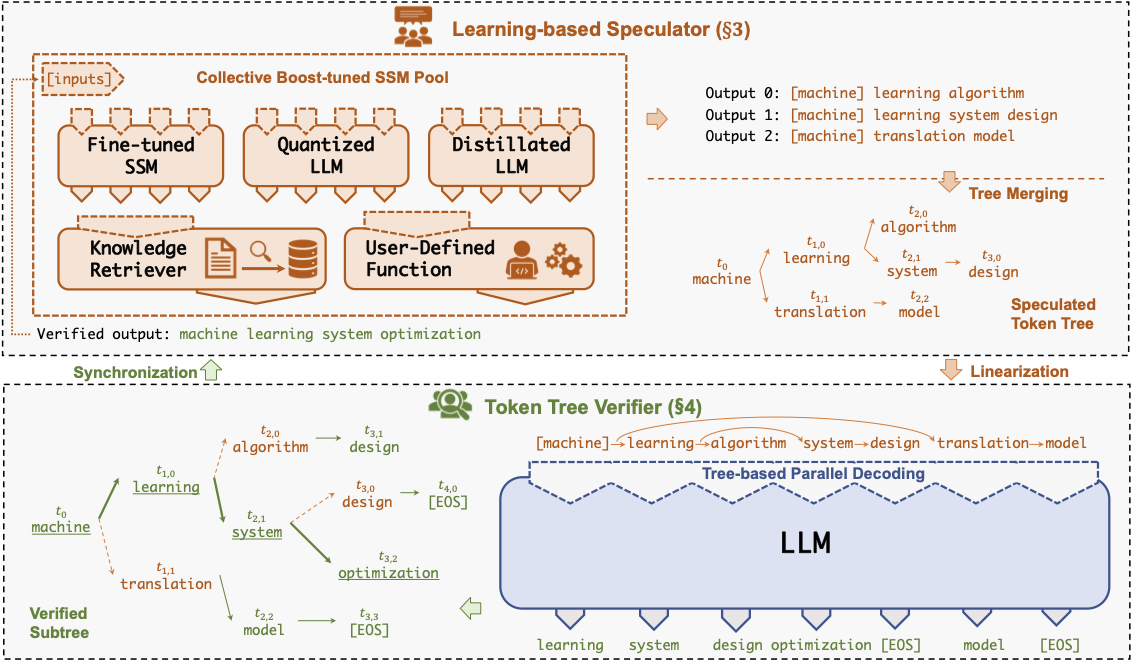 | github 紙 |
有效的流式語言模型帶有註意力集 廣X山,Yuandong Tian,Beidi Chen,Song Han,Mike Lewis | 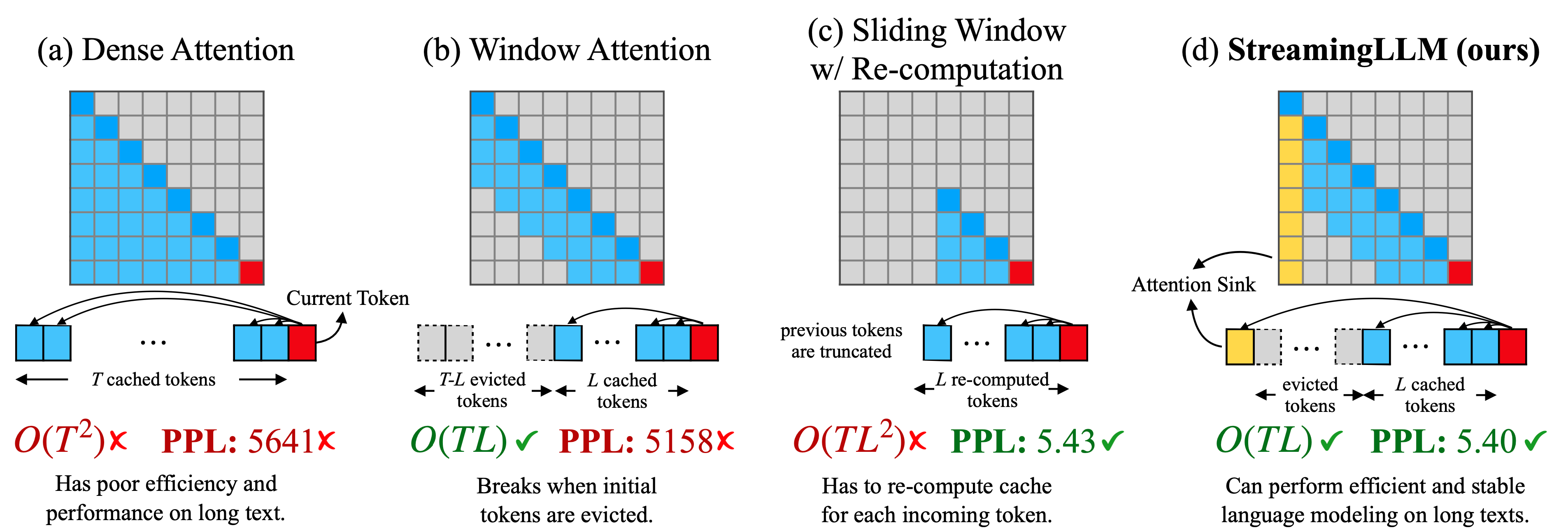 | github 紙 |
鷹:LLM通過特徵外推解碼的無損加速度 Yuhui Li,Chao Zhang和Hongyang Zhang | 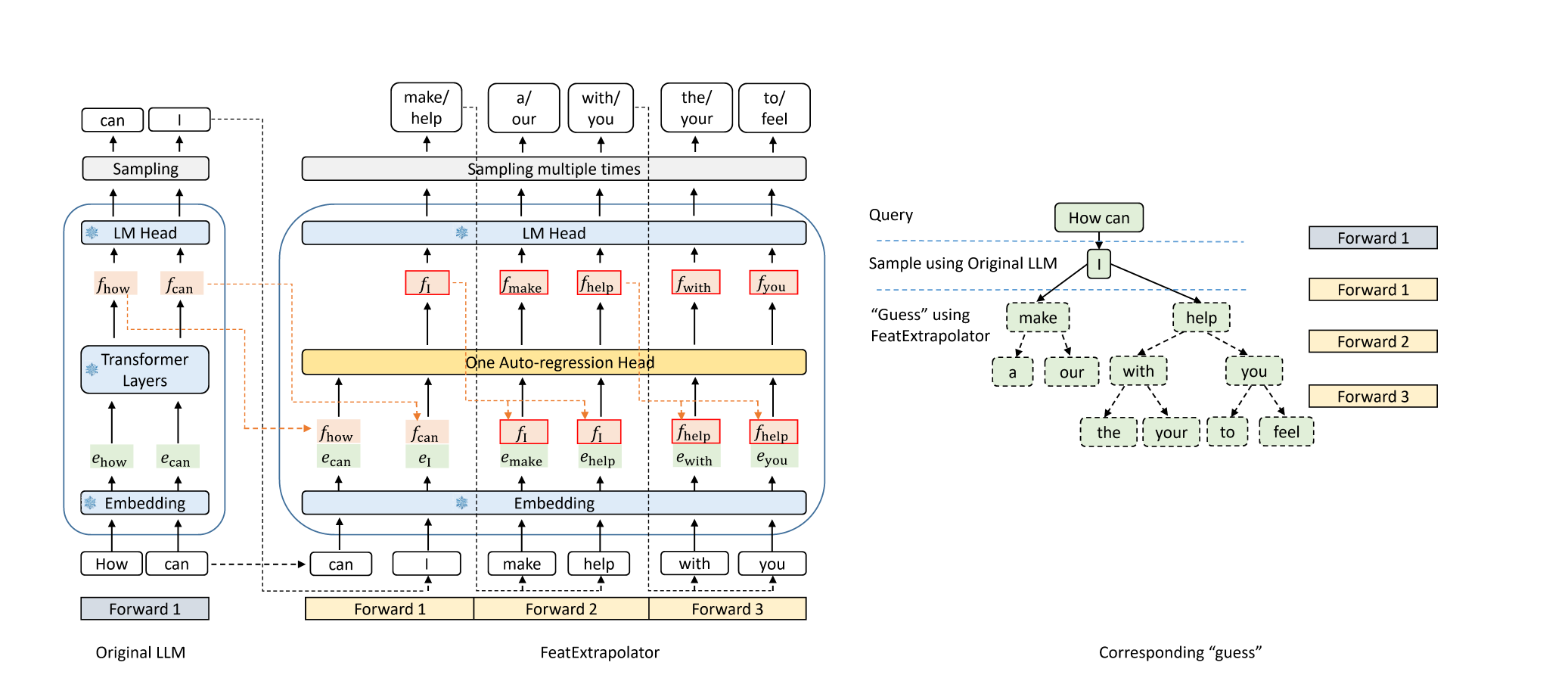 | github 部落格 |
美杜莎:簡單的LLM推理加速框架,帶有多個解碼頭 Tianle Cai,Yuhong Li,Zhengyang Geng,Hongwu Peng,Jason D. Lee,Deming Chen,Tri Dao | github 紙 | |
| 使用LLM推理加速的基於CTC的草稿模型進行投機解碼 Zhuofan Wen,上海Gui,楊馮 | 紙 | |
| PLD+:通過利用語言模型工件加速LLM推論 Shwetha Somasundaram,Anirudh Phukan,Apoorv Saxena | 紙 | |
Fastdraft:如何訓練草稿 Ofir Zafrir,Igor Margulis,Dorin Shteyman,Guy Boudoukh | 紙 | |
Smoa:改善具有稀疏代理混合物的多門語言模型 Dawei Li,Zhen Tan,Peijia Qian,Yifan Li,Kumar Satvik Chaudhary,Lijie Hu,Jiayi Shen | 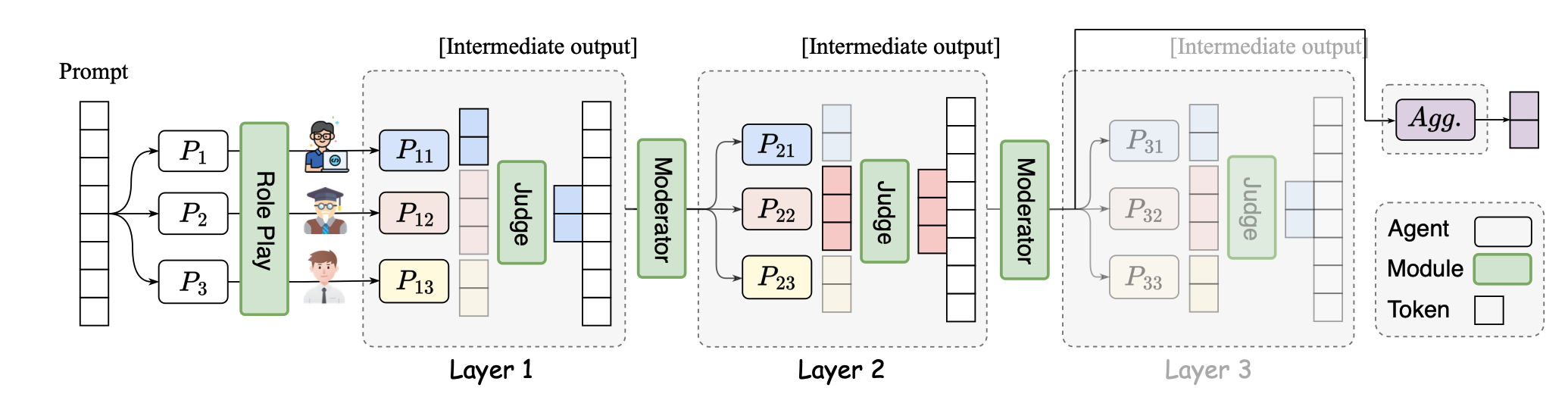 | github 紙 |
| N-Grammys:通過無學習的猜測加速自迴旋推理 勞倫斯·斯圖爾特(Lawrence Stewart),馬修·特拉格(Matthew Trager),蘇揚·庫馬爾·貢多德拉(Sujan Kumar Gonugondla) | 紙 | |
| 通過動態執行方法加速AI推論 Haim Barad,Jascha Achterberg,Tien Pei Chou,Jean Yu | 紙 | |
| suffixDecoding:一種無模型的方法來加快大型語言模型推理 Gabriele Oliaro,Zhihao Jia,Daniel Campos,Aurick Qiao | 紙 | |
| 通過大語言模型回答有效問題的動態策略計劃 Tanmay Parekh,Pradyot Prakash,Alexander Radovic,Akshay Shekher,Denis Savenkov | 紙 | |
MagicPig:LSH抽樣有效的LLM生成 Zhuoming Chen,Ranajoy Sadhukhan,Zihao Ye,Yang Zhou,Jianyu Zhang,Niklas Nolte,Yuandong Tian,Matthijs Douze,Leon Bottou,Zhihao Jia,Beidi Chen,Beidi Chen | github 紙 | |
| 使用張量分解的更快的語言模型,具有更好的多句預測 Artem Basharin,Andrei Chertkov,Ivan Oseledets | 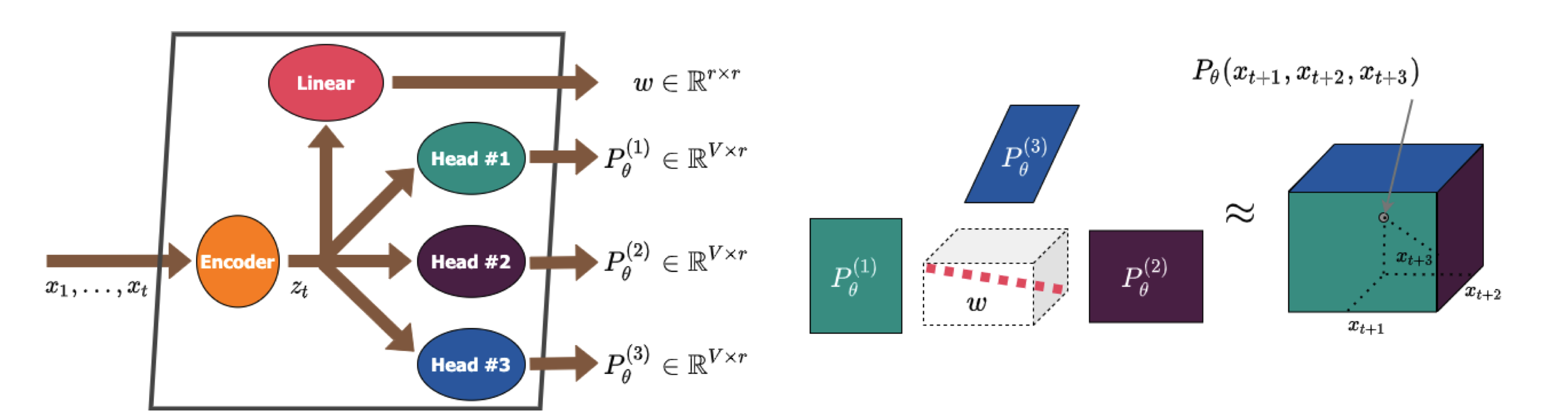 | 紙 |
| 增強大語言模型的有效推斷 Rana Shahout,Cong Liang,Shiji Xin,Qianru Lao,Yong Cui,Minlan Yu,Michael Mitzenmacher | 紙 | |
早期外觀LLM中的動態詞彙修剪 jort Vincenti,Karim Abdel Sadek,Joan Velja,Matteo Nulli,Metod Jazbec |  | github 紙 |
Coreinfer:以語義為靈感的自適應稀疏激活加速大型語言模型推斷 Qinsi Wang,Saeed Vahidian,Hancheng Ye,Jianyang Gu,Jianyi Zhang,Yiran Chen | github 紙 | |
二重奏:有效的長篇文化LLM推斷帶有檢索和流式的頭部 Guangxuan Xiao,Jiaming Tang,Jingwei Zuo,Junxian Guo,Shang Yang,Haotian Tang,Yao Fu,Song Han | 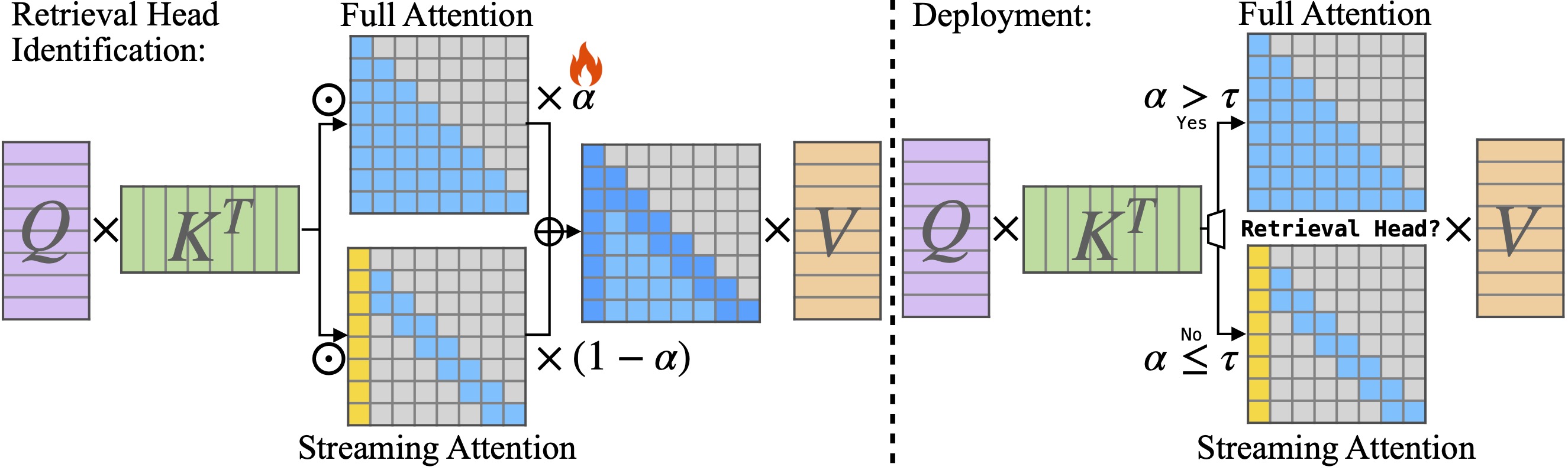 | github 紙 |
| DYSPEC:使用動態令牌樹結構更快的投機解碼 Yunfan Xiong,Ruoyu Zhang,Yanzeng Li,Tianhao Wu,Lei Zou | 紙 | |
| QSPEC:使用互補量化方案進行投機解碼 Juntao Zhao,Wenhao Lu,Sheng Wang,Lingpeng Kong,Chuan Wu | 紙 | |
| Tidaldecode:快速準確的LLM解碼,位置持續稀疏注意 lijie Yang,Zhihao Zhang,Zhuofu Chen,Zikun Li,Zhihao jia | 紙 | |
| ParallelsPec:平行起草者,用於有效投機解碼 Zilin Xiao,Hongming Zhang,Tao GE,Siru Ouyang,Vicente Ordonez,Dong Yu | 紙 | |
Swift:LLM推理加速度的自然自我指導解碼 海明Xia,Yongqi li,Jun Zhang,Cunxiao du,Wenjie li |  | github 紙 |
TurrOrag:加速帶有預先計算的KV緩存,以加速帶有塊狀文本 Songshuo Lu,Hua Wang,Yutian Rong,Zhi Chen,Yaohua Tang | 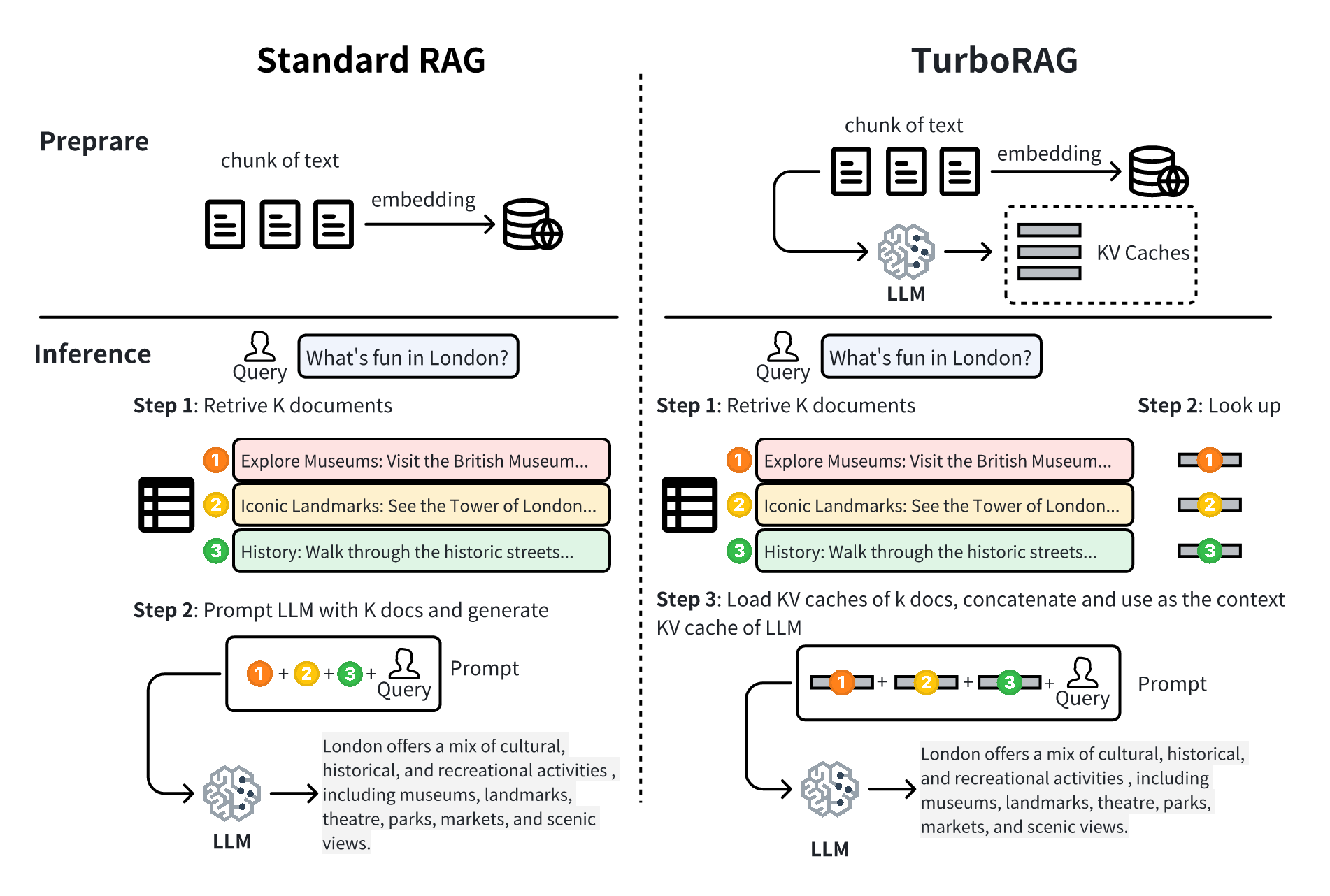 | github 紙 |
| 一點點走很長一段路:有效的長篇小說培訓和對部分環境的推斷 Suyu GE,Xihui Lin,Yunan Zhang,Jiawei Han,Hao Peng | 紙 | |
| Mnemosyne:有效服務數百萬上下文長度LLM推理請求的並行化策略,而無需近似 Amey Agrawal,Junda Chen,íññigoGoiri,Ramachandran Ramjee,Chaojie Zhang,Alexey Tumanov,Esha Choukse | 紙 | |
在早期發現寶石:以1000倍的輸入令牌減少加速長篇小說LLM Zhenmei Shi,Yifei Ming,Xuan-Phi Nguyen,Yingyu Liang,Shafiq Joty | github 紙 | |
| 有效LLM推斷的動態寬度投機梁解碼 Zongyue Qin,Zifan HE,Neha Prakriya,Jason Cong,Yizhou Sun | 紙 | |
Critiprefill:一種基於細分的基於批判性的方法,用於預填充LLMS Junlin LV,Yuan Feng,Xike Xie,Xin Jia,Qirong Peng,Guiming Xie | github 紙 | |
| 檢索:通過矢量檢索加速長篇小說LLM推斷 Di Liu, Meng Chen, Baotong Lu, Huiqiang Jiang, Zhenhua Han, Qianxi Zhang, Qi Chen, Chengruidong Zhang, Bailu Ding, Kai Zhang, Chen Chen, Fan Yang, Yuqing Yang, Lili Qiu | 紙 | |
小天狼星:有效LLM的上下文稀疏性和校正 Yang Zhou,Zhuoming Chen,Zhaozhuo Xu,Victoria Lin,Beidi Chen | github 紙 | |
OneGen:LLM的有效的一通統一生成和檢索 Jintian Zhang,Cheng Peng,Mengshu Sun,Xiang Chen,Lei Liang,Zhiqiang Zhang,Jun Zhou,Huajun Chen,Ningyu Zhang | 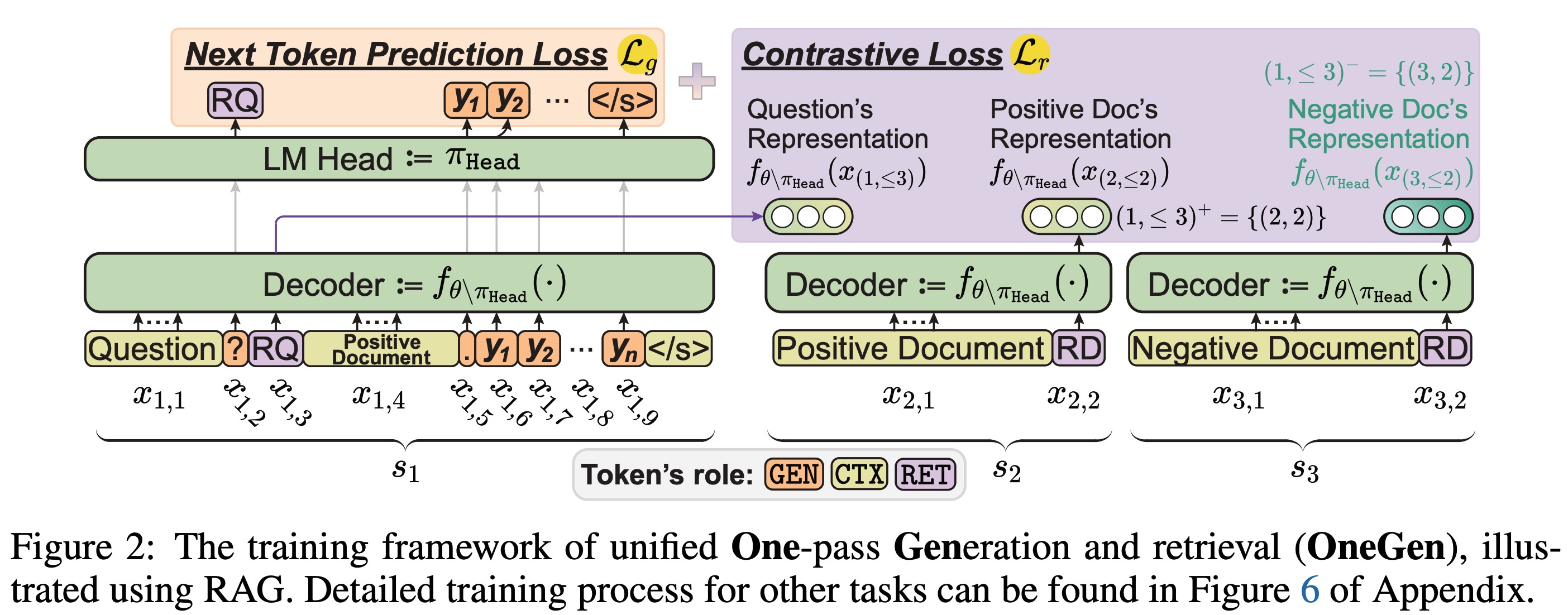 | github 紙 |
| 路徑矛盾:在LLM中有效推斷的前綴增強 Jiace Zhu,Yingtao Shen,Jie Zhao,Zou | 紙 | |
| 通過特徵抽樣和部分比對蒸餾來提高無損投機解碼 Lujun Gui,Bin Xiao,Lei Su,Weipeng Chen | 紙 |
| 標題和作者 | 介紹 | 鏈接 |
|---|---|---|
與卸載的混合物語言模型的快速推斷 Artyom Eliseev,Denis Mazur |  | github 紙 |
凝結,而不僅僅是修剪:提高MOE層修剪的效率和性能 Mingyu Cao,Li,Ji Ji,Jiaqi Zhang,Siaolong MA,Shiwei Liu,Lu Yin | github 紙 | |
| 高效移動設備推理的高速緩存專家的混合物 Andrii Skliar,領帶Van Rozendaal,Romain Lepert,Todor Boinovski,Mart Van Baalen,Markus Nagel,Paul Whatmough,Babak Ehteshami Bejnordi | 紙 | |
MONTA:與網絡交通感知的平行優化加速培訓的混合物訓練 Jingming Guo,Yan Liu,Yu Meng,Zhiwei Tao,Banglan Liu,Gang Chen,Xiang Li | github 紙 | |
MOE-I2:專家模型的壓縮混合物通過跨式植物修剪和內部雜貨低級分解 Cheng Yang,Yang Sui,Jinqi Xiao,Lingyi Huang,Yu Gong,Yuanlin Duan,Wenqi Jia,Miao Yin,Yu Cheng,Yu Cheng,Bo Yuan | github 紙 | |
| 霍比特人:快速MOE推理的混合精確專家卸載系統 Peng Tang,Jiacheng Liu,Xiaofeng Hou,Yifei PU,Jing Wang,Pheng-Ann Heng,Chao Li,Minyi Guo | 紙 | |
| promoe:基於MOE快速的LLM使用主動緩存服務 Xiaoniu Song,Zihang Zhong,Rong Chen | 紙 | |
| 專家流:優化的專家激活和代幣分配,以進行有效的專家推理 XIN HE,Shunkang Zhang,Yuxin Wang,Haiyan Yin,Zihao Zeng,Shaohuai Shi,Zhenheng Tang,Xiaowen Chu,Ivor Tsang,Ong Yew很快 | 紙 | |
| EPS-MOE:具有成本效益的MOE推理的專家管道調度程序 Yulei Qian,Fancun Li,Xiangyang JI,Xiaoyu Zhao,Jianchao Tan,Kefeng Zhang,Xunliang Cai | 紙 | |
MC-MOE:混合物的混合物llms llms的混合壓縮機增加了 Wei Huang,Yue Liao,Jianhui Liu,Ruifei He,Haoru Tan,Shiming Zhang,Hongsheng Li,Si Liu,si liu,xiaojuan Qi | 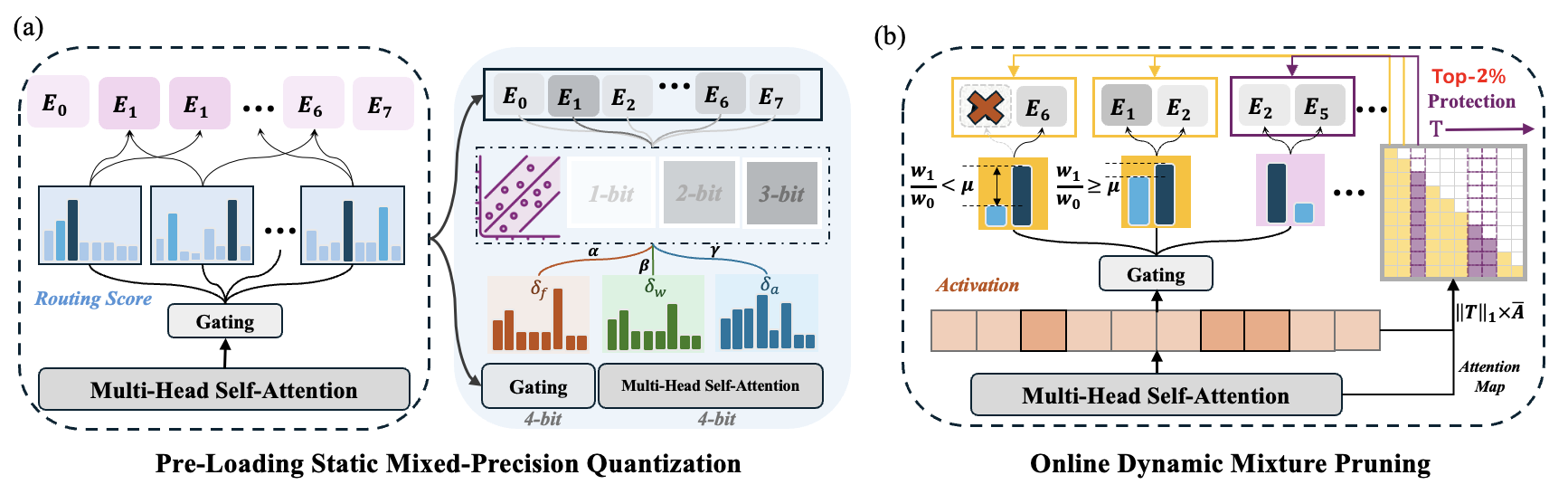 | github 紙 |
| 標題和作者 | 介紹 | 鏈接 |
|---|---|---|
Mobillama:朝著準確且輕巧的完全透明的GPT Omkar Thawakar,Ashmal Vayani,Salman Khan,Hisham Cholakal,Rao M. Anwer,Michael Felsberg,Tim Baldwin,Eric P. Xing,Fahad Shahbaz Khan |  | github 紙 模型 |
Megalodon:有效的LLM預處理和無限上下文長度的推斷 Xuezhe MA,Yang Yang,Wenhan Xiong,Beidi Chen,Lili Yu,Hao Zhang,Jonathan May,Luke Zettlemoyer,Omer Levy,Chunting Zhou | 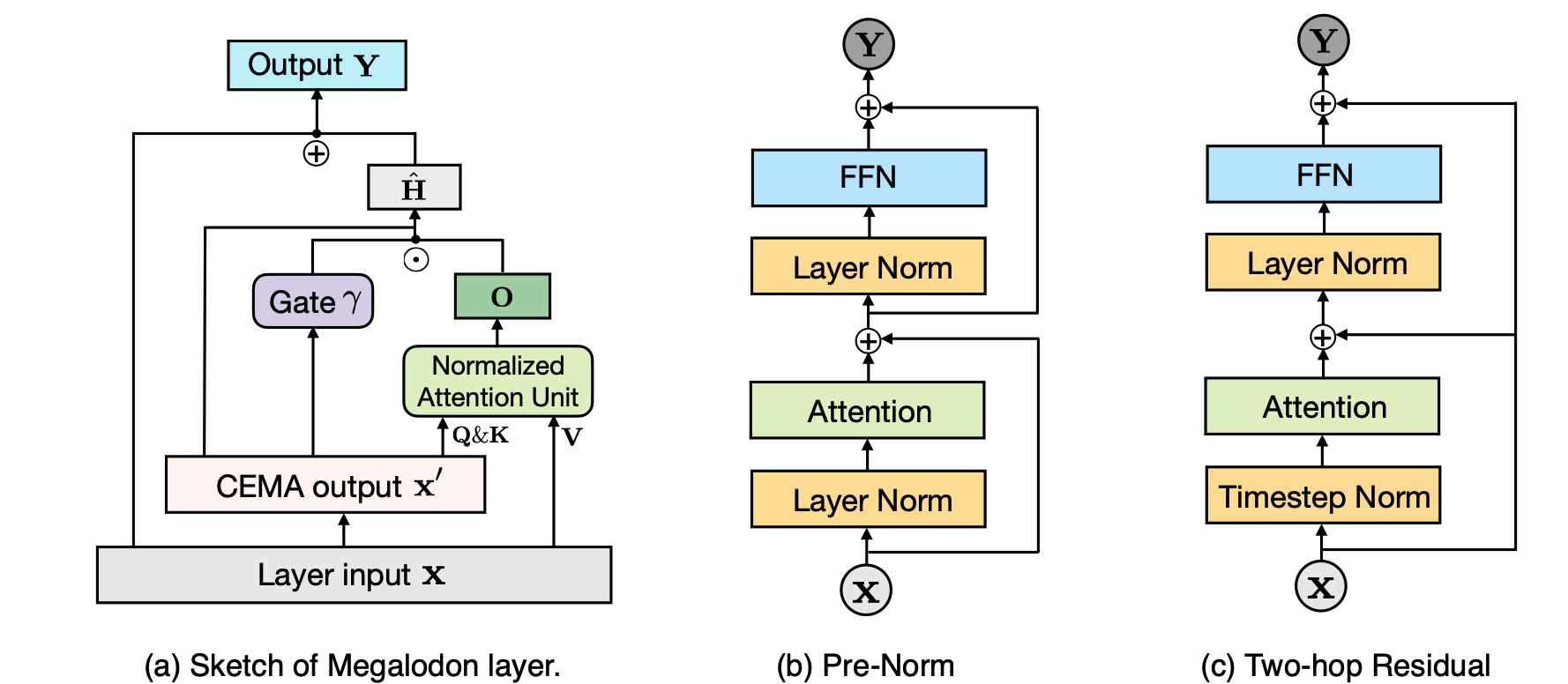 | github 紙 |
| Taipan:具有選擇性關注的高效和表達狀態空間語言模型 Chien van nguyen,Huy Huu Nguyen,Thang M. Pham,Ruiyi Zhang,Hanieh Deilamsalehy,Puneet Mathur,Ryan A. Rossi,Trung Bui,Trung Bui,Viet Dac Lai,Franck Dernoncourt,Thien Huu Nguyen | 紙 | |
聲明:在LLMS中學習固有的稀疏關注 Yizhao Gao,Zhichen Zeng,Dayou du,Shijie Cao,Hayden Kwok-hay So,Ting Cao,Fan Yang,Mao Yang Yang Yang | github 紙 | |
基礎共享:大語言模型壓縮的跨層參數共享 Jingcun Wang,Yu-Guang Chen,Ing-Chao Lin,Bing Li,Grace Li Zhang | github 紙 | |
| Rodimus*:通過有效的注意力打破準確的效率折衷 Zhihao He,Hang Yu,Zi Gong,Shizhan Liu,Jianguo Li,Weiyao Lin | 紙 |
| 標題和作者 | 介紹 | 鏈接 |
|---|---|---|
| 模型告訴您要丟棄什麼:LLMS的自適應KV緩存壓縮 Suyu GE,Yunan Zhang,Liyuan Liu,Minjia Zhang,Jiawei Han,Jianfeng Gao |  | 紙 |
| clusterKV:在語義空間中操縱LLM KV緩存以進行可回憶的壓縮 liu,chengwei li,jieru zhao,chenqi Zhang,minyi guo | 紙 | |
| 使用LeanKV統一大型語言模型的KV緩存壓縮 Yanqi Zhang,Yuwei Hu,Runyuan Zhao,John CS Lui,Haibo Chen | 紙 | |
| 通過層間注意力相似性來壓縮長篇文化LLM推斷的KV緩存 Da Ma,Lu Chen,Situo Zhang,Yuxun Miao,Su Zhu,Zhi Chen,Hongshen Xu,Hanqi Li,Shuai Fan,Lei Pan,Kai Yu | 紙 | |
| MiniKV:通過2位層 - 歧義kV緩存推動LLM推理的限制 Akshat Sharma,Hangliang Ding,Jianping Li,Neel Dani,Minjia Zhang | 紙 | |
| TokenSelect:通過動態令牌kV緩存選擇LLM的有效長篇小說推斷和長度外推。 Wei Wu,Zhuoshi Pan,Chao Wang,Liyi Chen,Yunchu Bai,Kun Fu,Zheng Wang,Hui Xiong | 紙 | |
並非所有的頭都重要:帶有集成檢索和推理的頭部級KV緩存壓縮方法 Yu Fu,Zefan Cai,Abedelkadir Asi,Wayne Xiong,Yue Dong,Wen Xiao |  | github 紙 |
嗡嗡聲:蜂巢結構的稀疏kV緩存,分段重型擊球手用於有效的LLM推理 Junqi Zhao,Zhijin Fang,Shu Li,Shaohui Yang,Shichao他 | github 紙 | |
對有效LLM推斷的跨層KV共享的系統研究 你吳,海耶·吳,凱威·托 |  | github 紙 |
| 無損KV緩存壓縮至2% Zhen Yang,Jnhan,Kan Wu,Ruobing Xie,An Wang,Xingwu Sun,Zhanhui Kang | 紙 | |
| Matryoshkakv:通過可訓練的正交投影自適應KV壓縮 Bokai Lin,Zihao Zeng,Zipeng Xiao,Siqi Kou,Tianqi Hou,Xiaofeng Gao,Hao Zhang,Zhijie Deng | 紙 | |
大語言模型中KV緩存壓縮的剩餘矢量量化 Ankur Kumar | github 紙 | |
KVSharer:通過層次不同的KV緩存共享有效推斷 Yifei Yang,Zouying Cao,Qiguang Chen,Libo Qin,Dongjie Yang,Hai Zhao,Zhi Chen |  | github 紙 |
| LORC:LLMS KV高速緩存的低級壓縮策略 Rongzhi Zhang,Kuang Wang,Liyuan Liu,Shuohang Wang,Hao Cheng,Chao Zhang,Yelong Shen | 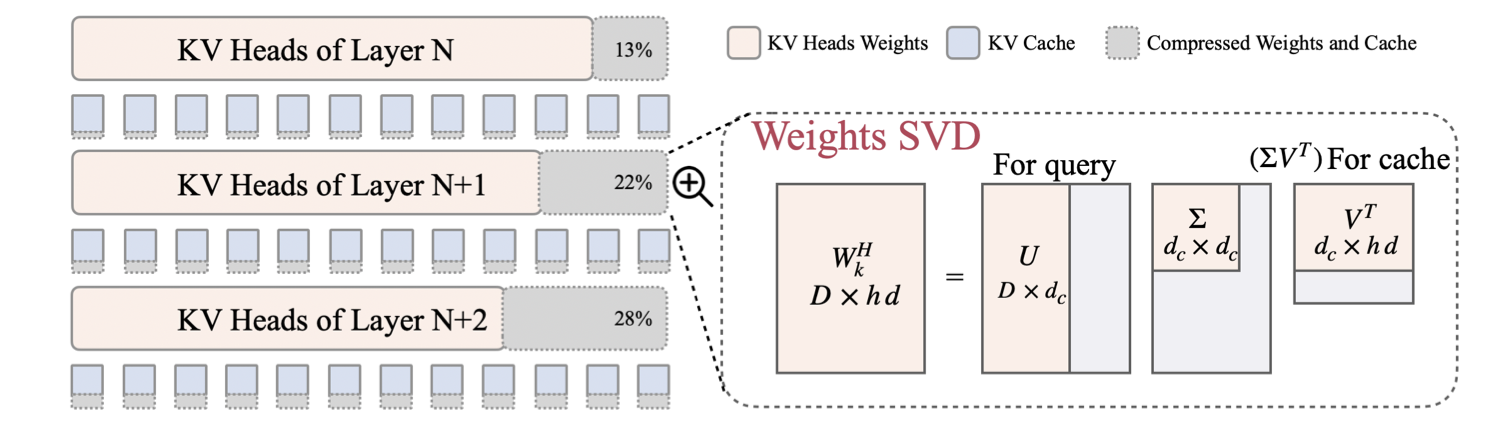 | 紙 |
| SwiftKV:通過知識保護模型轉換快速預填充推理 Aurick Qiao,Zhewei Yao,Samyam Rajbhandari,Yuxiong他 | 紙 | |
動態內存壓縮:加速推理的翻新LLM Piotr Nawrot,Adrianolańcucki,Marcin Chochowski,David Tarjan,Edoardo M. Ponti | 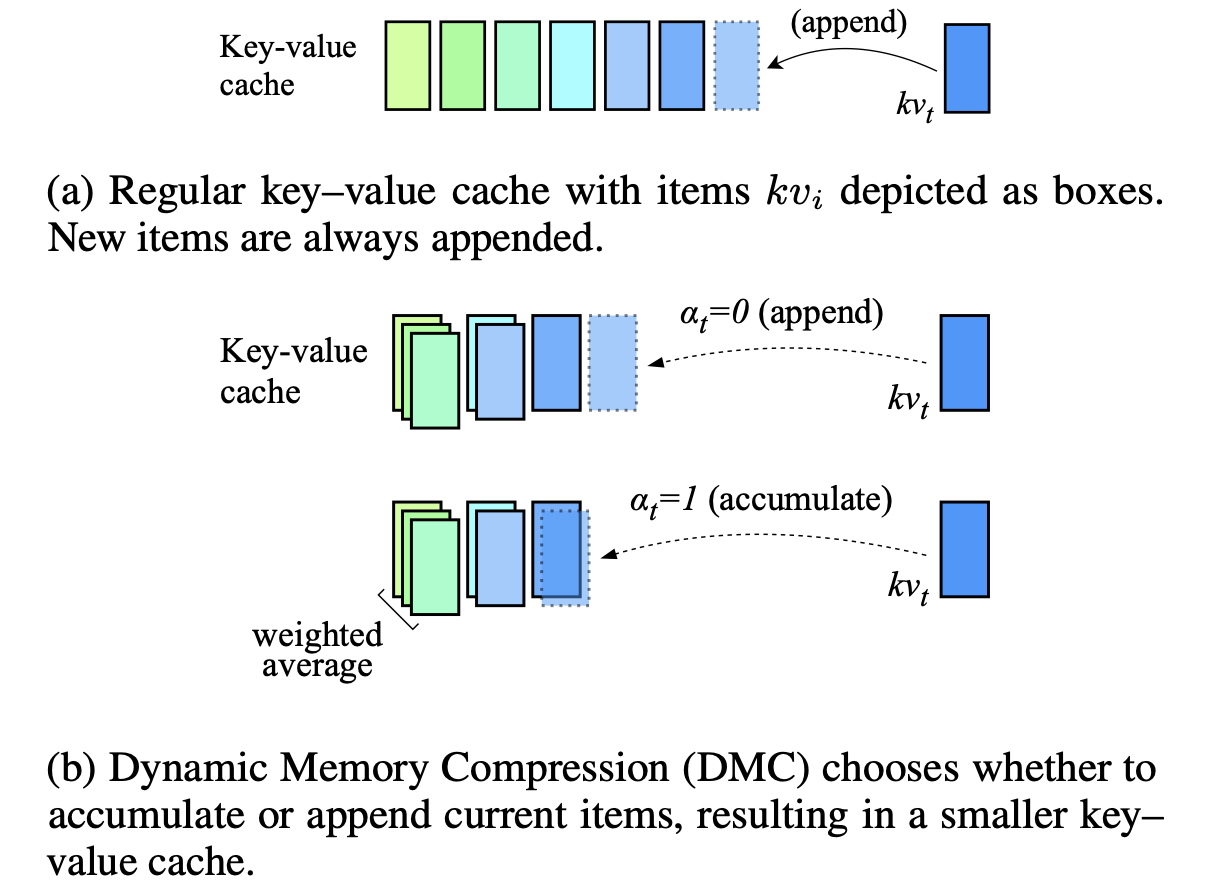 | 紙 |
| KV壓縮:每個注意力頭的分類KV-CACHE壓縮率具有可變的壓縮率 艾薩克·雷格(Isaac Rehg) | 紙 | |
ADA-KV:通過自適應預算分配優化KV緩存驅逐有效的LLM推理 Yuan Feng,Junlin LV,Yukun Cao,Xike Xie,S。 KevinZhou | 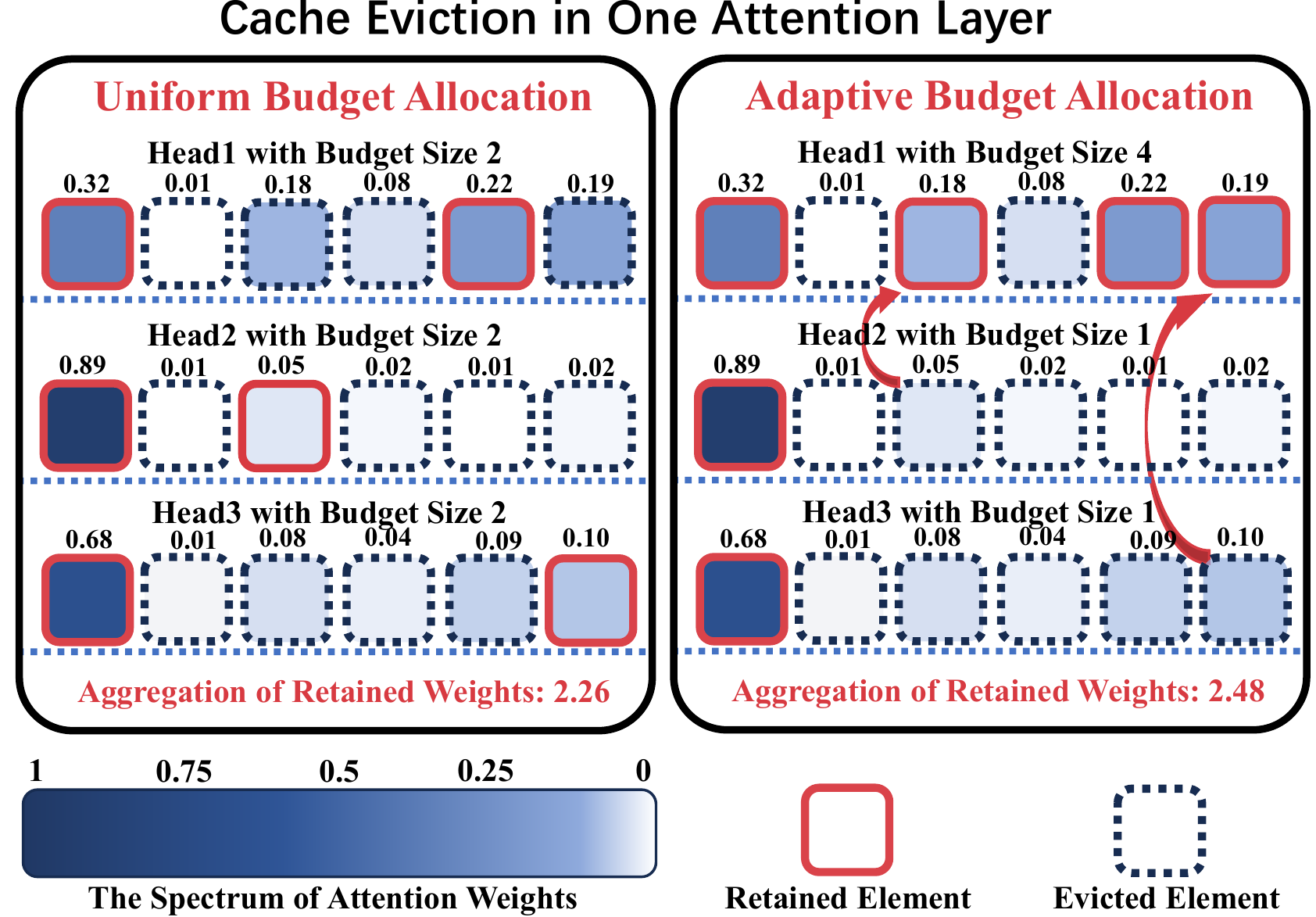 | github 紙 |
AlignedKV:通過精確對準的量化減少KV-CACHE的內存訪問 Yifan Tan,Haoze Wang,Chao Yan,Yangdong Deng | github 紙 | |
| CSKV:在長篇文化場景中,訓練效率的頻道縮小了KV高速緩存 Luning Wang,Shiyao Li,Xuefei Ning,Zhihang Yuan,Shengen Yan,Guohao Dai,Yu Wang | 紙 | |
| 首先查看有效且安全的設備LLM針對KV洩漏的推斷 Huan Yang,Deyu Zhang,Yudong Zhao,Yuanchun Li,Yunxin Liu | 紙 |
| 標題和作者 | 介紹 | 鏈接 |
|---|---|---|
llmlingua:壓縮提示以加速大語模型的推理 Huiqiang Jiang,Qianhui Wu,Chin-Yew Lin,Yuqing Yang,Lili Qiu | 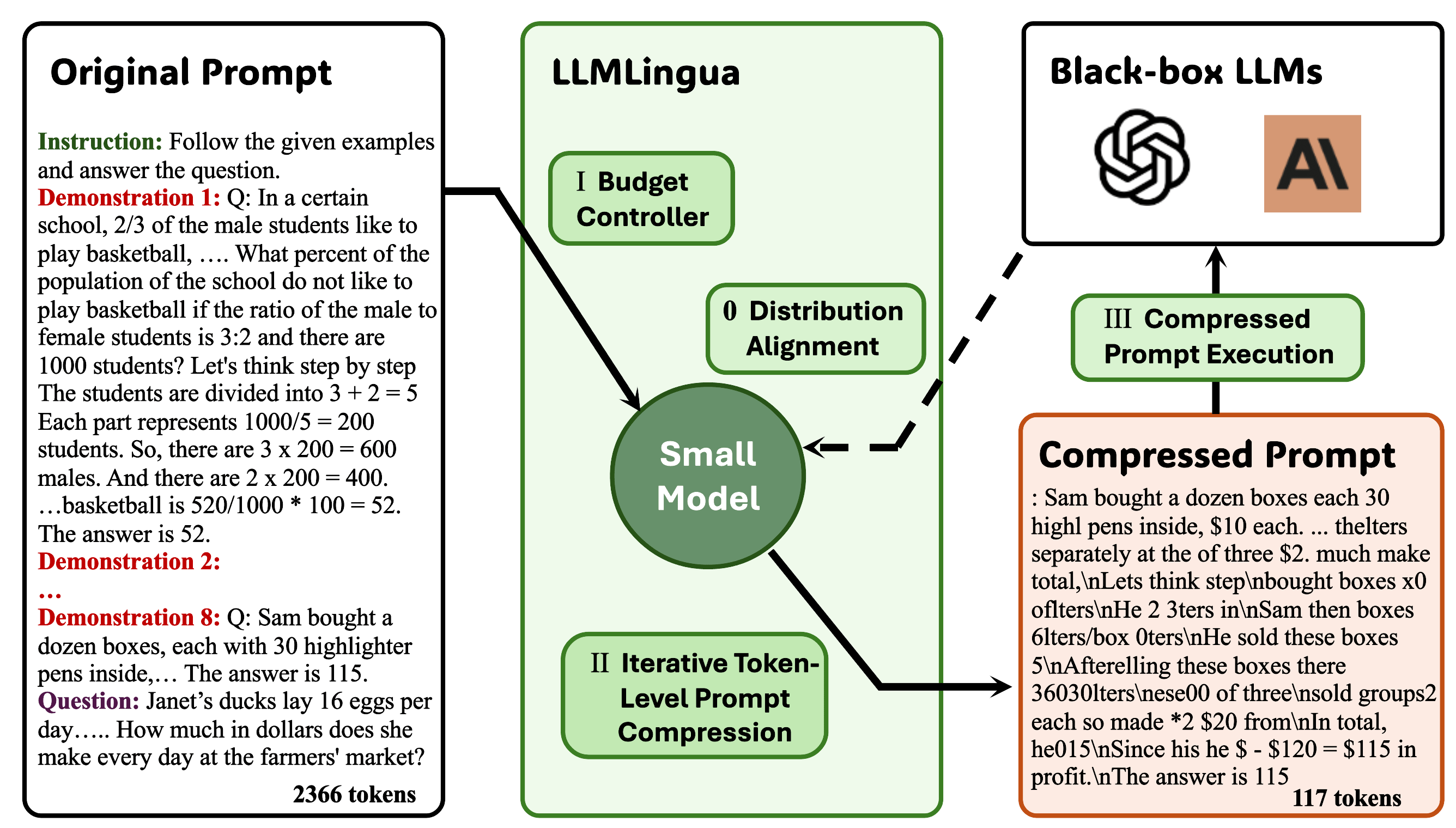 | github 紙 |
longllmlingua:通過及時壓縮在長上下文方案中加速和增強LLM Huiqiang Jiang,Qianhui Wu,Xufang Luo,Dongsheng Li,Chin-Yew Lin,Yuqing Yang,Lili Qiu | 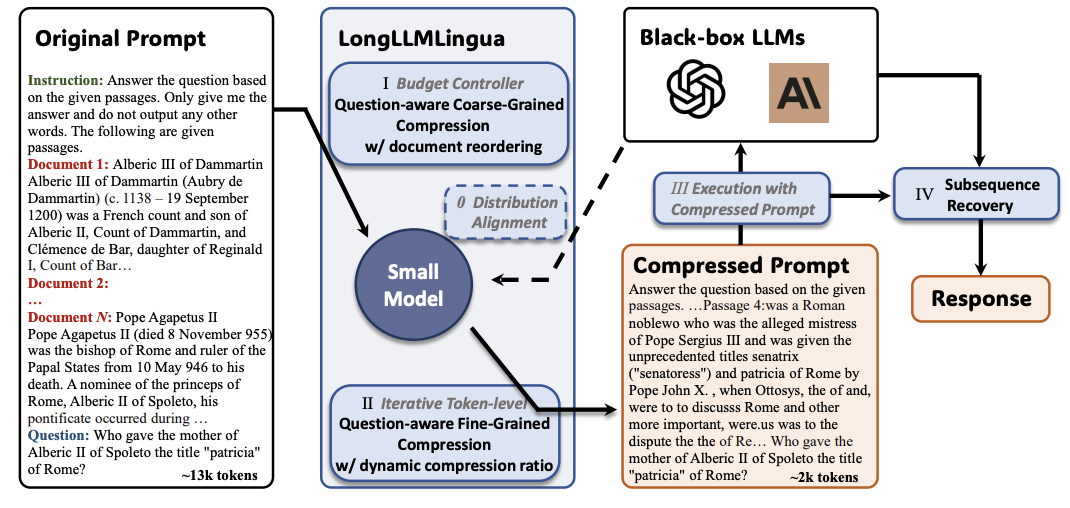 | github 紙 |
| JPPO:加速大型語言模型服務的聯合力量和及時優化 Feiran You,Hongyang DU,Kaibin Huang,Abbas Jamalipour | 紙 | |
生成上下文蒸餾 Haebin Shin,Lei JI,Yeyun Gong,Sungdong Kim,Eunbi Choi,Minjoon Seo | | github 紙 |
Multitok:適用於LZW壓縮的有效LLM的可變長度令牌化 Noel Elias,Homa Esfahanizadeh,Kaan Kale,Sriram Vishwanath,Muriel Medard | github 紙 | |
Selection-P:自我監督的任務無關及格及時壓縮,以實現忠誠和可轉讓性 TSZ Ting Chung,Leyang Cui,Lemao Liu,Xinting Huang,Shuming Shi,Dit-Yan Yeung | 紙 | |
從閱讀到壓縮:探索多文件讀取器以進行提示壓縮 Eunseong Choi,Sunkyung Lee,Minjin Choi,June Park,Jongwuk Lee | 紙 | |
| 感知壓縮機:在長上下文場景中的一種無訓練的及時壓縮方法 Jiwei Tang,Jin Xu,Tingwei Lu,Hai Lin,Yiming Zhao,Hai-Tao Zheng | 紙 | |
FineZip:推動大型語言模型的限制以進行實際無損文本壓縮 Fazal Mittu,Yihuan BU,Akshat Gupta,Ashok Devireddy,Alp Eren Ozdarendeli,Anant Singh,Gopala Anumandanchipalli | github 紙 | |
解析樹引導LLM提示壓縮 Wenhao Mao,Chengbin Hou,Tianyu Zhang,Xinyu Lin,Ke Tang,Hairong LV | github 紙 | |
Alphazip:神經網絡增強無損文本壓縮 Swathi Shree Narashiman,Nitin Chandrachoodan | github 紙 | |
| TACO-RL:通過增強學習的任務意識提高壓縮優化 Shivam Shandilya,Menglin Xia,Supriyo Ghosh,Huiqiang Jiang,Jue Zhang,Qianhui Wu,VictorRühle | 紙 | |
| 有效的LLM上下文蒸餾 Rajesh Upadhayaya,Zachary Smith,Chritopher Kottmyer,Manish Raj Osti | 紙 | |
通過指導感知的上下文壓縮來增強和加速大型語言模型 Haowen Hou,Fei MA,Binwen Bai,Xinxin Zhu,Fei Yu | github 紙 |
| 標題和作者 | 介紹 | 鏈接 |
|---|---|---|
天然盛事:加速盛放,用於記憶效率的LLM訓練和微調 Arijit Das | github 紙 | |
| 緊湊:記憶效率LLM訓練的壓縮激活 Yara Shamshoum,Nitzan Hodos,Yuval Sieradzki,Assaf Schuster | 紙 | |
ESPACE:減少模型壓縮激活的維度 Charbel Sakr,Brucek Khailany | 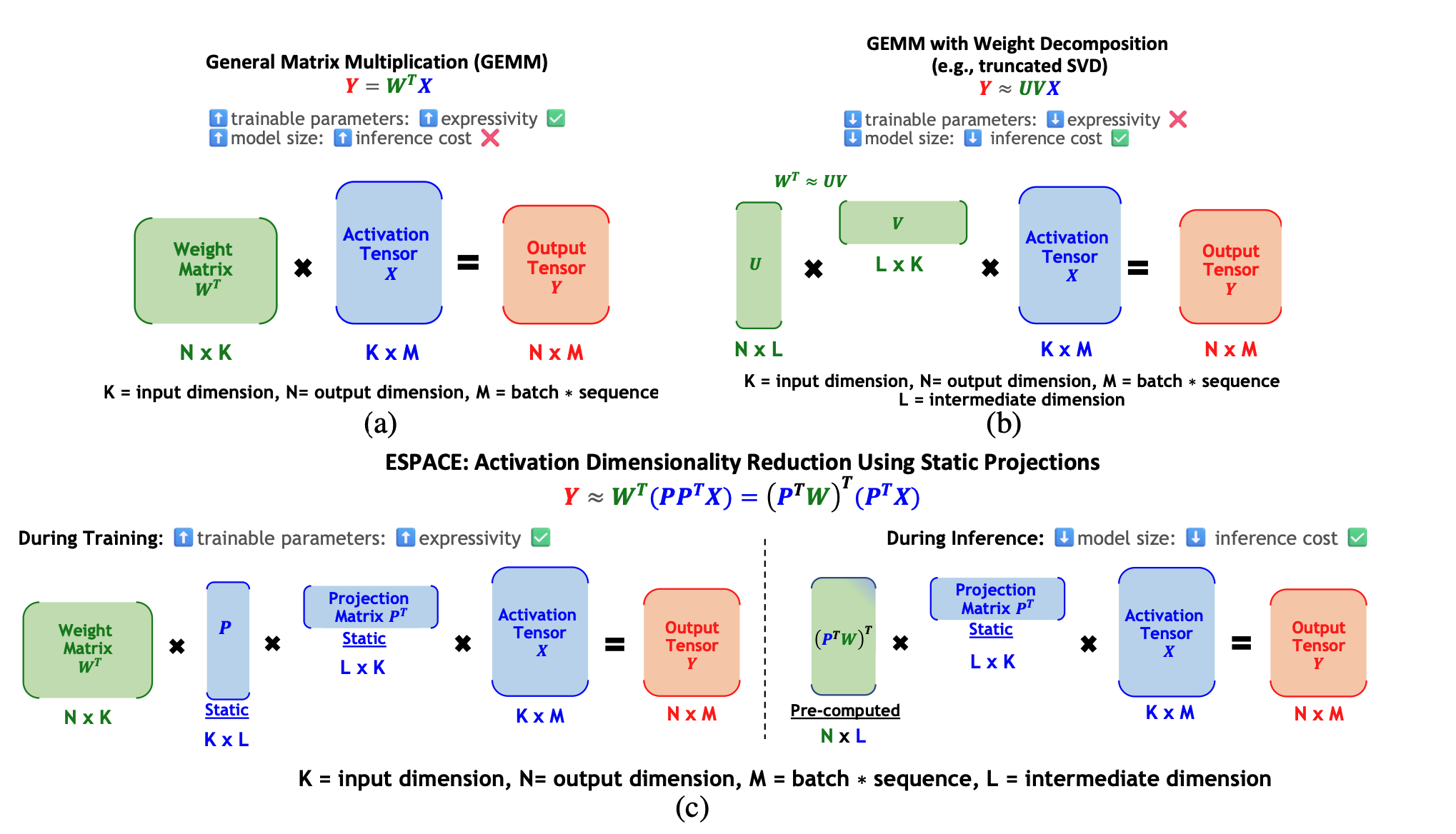 | 紙 |
| 標題和作者 | 介紹 | 鏈接 |
|---|---|---|
| FastSwitch:優化公平意識的上下文切換效率 - 大型語言模型服務 Ao Shen,Zhiyao li,mingyu gao | 紙 | |
| CE-Collm:通過雲邊緣協作的高效和自適應大語模型 金彭金,揚佐·吳 | 紙 | |
| 波紋:加速LLM推斷具有相關性神經元管理的智能手機 Tuowei Wang,Ruwen Fan,Minxing Huang,Zixu Hao,Kun Li,Ting Cao,Youyou Lu,Yaoxue Zhang,Ju Ren | 紙 | |
Alise:加速使用投機計劃的大型語言模型 Youpeng Zhao,Jun Wang | 紙 | |
| 史詩:用於服務大語言模型的有效依賴位置的上下文緩存 Junhao Hu,Wenrui Huang,Haoyi Wang,Weidong Wang,Tiancheng Hu,Qin Zhang,Hao Feng,Xusheng Chen,Yizhou Shan,Tao Xie Xie | 紙 | |
SDP4BIT:在LLM培訓的碎片數據並行中邁向4位通信量化 Jinda Jia,Cong Xie,Hanlin Lu,Daoce Wang,Hao Feng,Chengming Zhang,Baixi Sun,Haibin Lin,Zhi Zhang,Zhang,Xin Liu,Dingwen Tao | 紙 | |
| 快速發音:將Flashattention 2擴展到NPU和低資源GPU Haoran Lin,Xianzhi Yu,Kang Zhao,Lu Hou,Zongyuan Zhan等人 | 紙 | |
| POD - 注意:為更快的LLM推理解鎖完整的預填寫重疊 Aditya K Kamath,Ramya Prabhu,Jayashree Mohan,Simon Peter,Ramachandran Ramjee,Ashish Panwar | 紙 | |
TPI-LLM:在低資源邊緣設備上有效地服務70B級LLM Zonghang Li,Wenjiao Feng,Mohsen Guizani,Hongfang Yu | github 紙 | |
GPU張量核上大語言模型的有效任意精度加速度 Shaobo MA,Chao Fang,Haikuo Shao,宗芬 | 紙 | |
蛋白石:離群保存的顯微鏡量化量化量的生成大語言模型 Jahyun Koo,Dahoon Park,Sangwoo Jung,Jaeha功夫 | 紙 | |
| 通過基於混合GPU的壓縮加速大型語言模型培訓 Lang Xu,Quentin Anthony,Qinghua Zhou,Nawras Alnaasan,Radha R. Gulhane,Aamir Shafi,Hari Subramoni,Dhabaleswar K. Panda | 紙 |
| 標題和作者 | 介紹 | 鏈接 |
|---|---|---|
| Helene:Hessian層剪切和梯度退火,用於通過零訂單優化加速微調LLM Huaqin Zhao,Jiaxi Li,Yi Pan,Shizhe Liang,Xiaofeng Yang,Wei Liu,Xiang Li,Fei Dou,Tianming Liu,Jin Lu | 紙 | |
通過貝葉斯重新聚集低級適應的LLM的強大而有效的LLM進行微調 Ayan Sengupta,Vaibhav Seth,Arinjay Pathak,Natraj Raman,Sriram Gopalakrishnan,Tanmoy Chakraborty | github 紙 | |
MILORA:大語模型的低排名適應的有效混合物微調 Jingfan Zhang,Yi Zhao,Dan Chen,Xing Tian,Huanran Zheng,Wei Zhu | 紙 | |
Rocoft:具有行列更新的大型語言模型的有效填充 MD Kowsher,Tara Esmaeilbeig,Chun-Nam Yu,Mojtaba Soltanalian,Niloofar Yousefi | 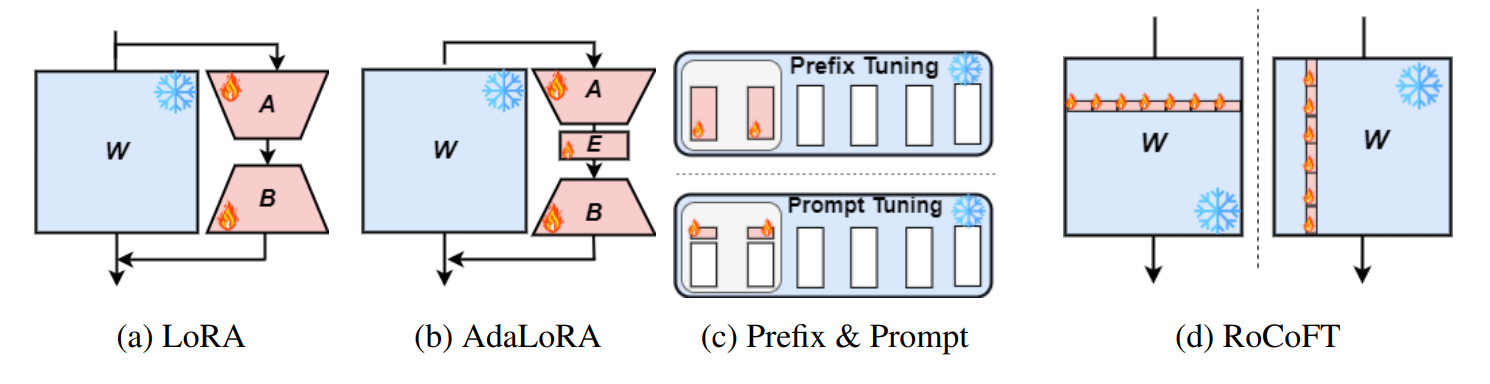 | github 紙 |
重要的重要性重要:在大型語言模型的參數有效微調中,記憶力較小 Kai Yao,Penlei Gao,Lichun Li,Yuan Zhao,Xiaofeng Wang,Wei Wang,Jianke Zhu | github 紙 | |
使用語義知識調整大型語言模型的參數有效微調 Nusrat Jahan Prottasha,Asif Mahmud,Md。 ShohanurIslam Sobuj,Prakash Bhat,MD Kowsher,Niloofar Yousefi,Ozlem Ozmen Garibay | 紙 | |
QEFT:量化LLM有效微調的量化 Changhun Lee,Jun-Gyu Jin,Younghyun Cho,Eunhyeok Park | github 紙 | |
Bipeft:預算引導的迭代搜索參數有效的大型語言模型 Aofei Chang,Jiaqi Wang,Han Liu,Parminder Bhatia,Cao Xiao,Ting Wang,Fanglong MA | github 紙 | |
SparseGrad:一種有效微調MLP層的選擇性方法 Viktoriia Chekalina,Anna Rudenko,Gleb Mezentsev,Alexander Mikhalev,Alexander Panchenko,Ivan Oseledets | github 紙 | |
| Spallm:用草圖對大型語言模型的統一壓縮改編 Tianyi Zhang,Junda SU,Oscar Wu,Zhaozhuo Xu,Anshumali Shrivastava | 紙 | |
骨頭:大型語言模型的參數有效微調方法的塊仿射轉換 Jiale Kang | github 紙 | |
| 僅使用推理引擎啟用LLMS的資源有效的對設備進行微調 Lei Gao,Amir Ziashabi,Yue Niu,Salman Avestimehr,Murali Annavaram | 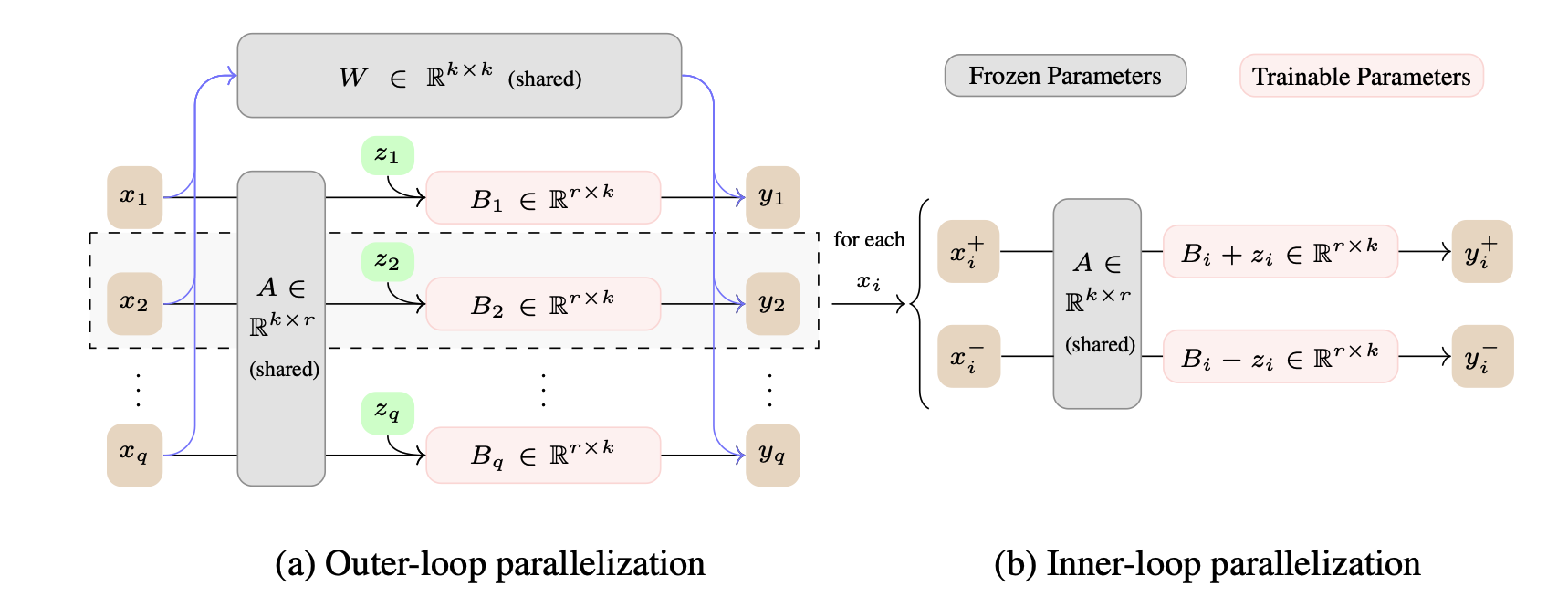 | 紙 |
| 標題和作者 | 介紹 | 鏈接 |
|---|---|---|
| AutomixQ:高性能記憶有效微調的自調整量化 Changhai Zhou,Shiyang Zhang,Yuhua Zhou,Zekai Liu,Shicha Weng |  | 紙 |
具有低維投影注意的大型語言模型的可擴展有效培訓 Xingtai LV,Ning Ding,Kaiyan Zhang,Ermo Hua,Ganqu Cui,Bowen Zhou | github 紙 | |
| 更少的是:極端梯度提升級別1適應性升級LLMS Yifei Zhang,Hao Zhu,Aiwei Liu,Han Yu,Piotr Koniusz,Irwin King | 紙 | |
外套:壓縮優化器狀態和用於記憶效率的FP8訓練的激活 Haocheng XI,Han Cai,Ligeng Zhu,Yao Lu,Kurt Keutzer,Jianfei Chen,Song Han | 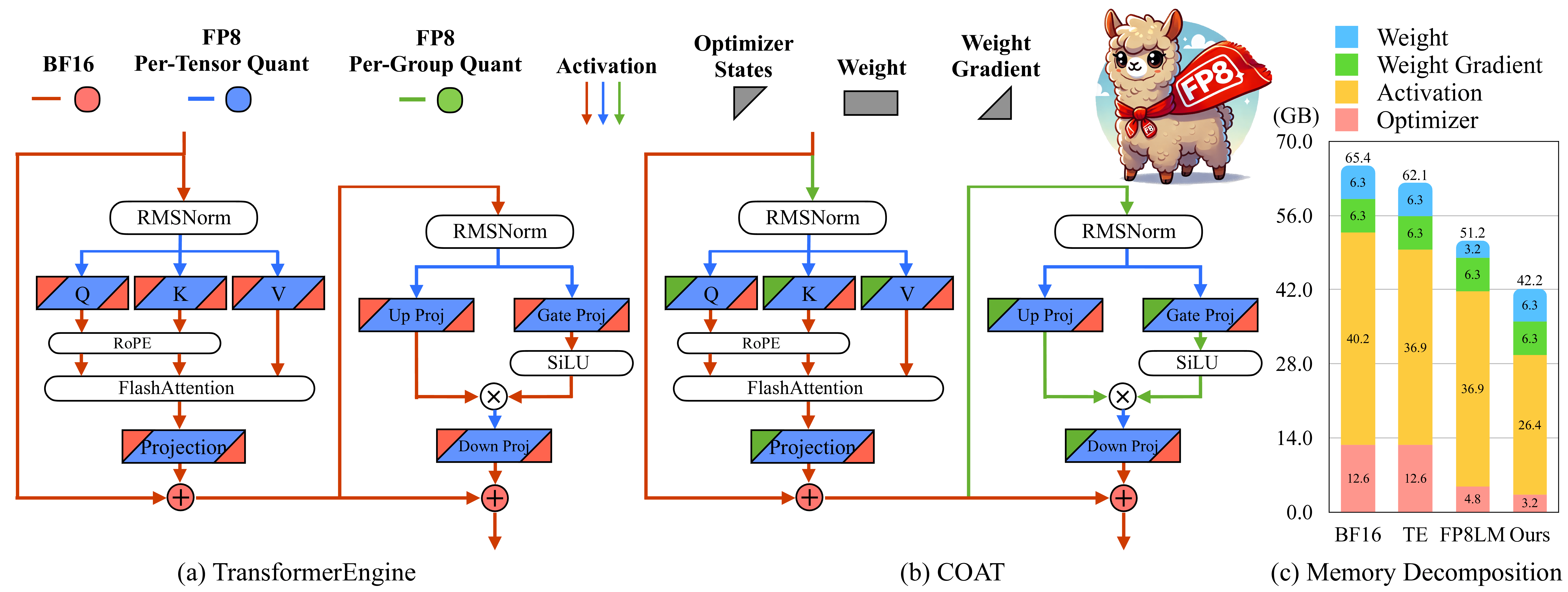 | github 紙 |
BitPipe:雙向交織管道並行,用於加速大型型號訓練 Houming Wu,Ling Chen,Wenjie Yu |  | github 紙 |
| 標題和作者 | 介紹 | 鏈接 |
|---|---|---|
| 仔細研究有效的推理方法:投機解碼的調查 Hyun Ryu,Eric Kim | 紙 | |
LLM推導台:AI加速器上大語言模型的推理基準測試 Krishna Teja Chitty-Venkata,Siddhisanket Raskar,Bharat Kale,Farah Ferdaus等人 | github 紙 | |
大型語言模型的及時壓縮:調查 Zongqian Li,Yinhong Liu,Yixuan SU,Nigel Collier | github 紙 | |
| 大型語言模型推理加速度:全面的硬件觀點 Jinhao Li,Jiaming Xu,Shan Huang,Yonghua Chen,Wen Li,Jun Liu,Yaoxiu Lian,Jiayi Pan,Li ding,Hao Zhou,Guohao Dai | 紙 | |
| 低位大語言模型的調查:基礎,系統和算法 Ruihao Gong,Yifu ding,Zining Wang,Chengtao LV,Xingyu Zheng,Jinyang DU,Haotong Qin,Jinyang Guo,Michele Magno,Xianglong Liu | 紙 | |
大型語言模型的檢索增強生成中的上下文壓縮:一項調查 Sourav Verma |  | github 紙 |
| 量化大型模型的藝術和科學:全面的概述 Yanshu Wang,Tong Yang,Xiyan Liang,Guoan Wang,Hanning Lu,Xu Zhe,Yaoming Li,Li Weitao | 紙 | |
| LLM的硬件加速度:一項全面的調查和比較 Nikoletta Koilia,Christoforos Kachris | 紙 | |
| 大語言模型的符號知識蒸餾的調查 卡馬爾·阿查里亞(Kamal Acharya),阿爾瓦羅·維拉斯克斯(Alvaro Velasquez),赫伯·赫伯特(Houbing Herbert) | 紙 |


