Awesome Efficient LLM
1.0.0
Uma lista com curadoria para modelos de linguagem eficientes grandes
Se você deseja incluir seu artigo ou precisar atualizar qualquer detalhe como informações da conferência ou URLs de código, sinta -se à vontade para enviar uma solicitação de tração. Você pode gerar o formato de marcação necessário para cada artigo preenchendo as informações em generate_item.py e execute python generate_item.py . Agradecemos calorosamente suas contribuições para esta lista. Como alternativa, você pode me enviar um e -mail com os links para o seu papel e código, e eu adicionaria seu papel à lista o mais rápido possível.
Para cada tópico, selecionamos uma lista de documentos recomendados que receberam muitas estrelas ou citações do Github.
| Título e autores | Introdução | Links |
|---|---|---|
Sparsegpt: Modelos de linguagem maciços podem ser podados com precisão em um tiro Elias Frantar, Dan Alistarh | 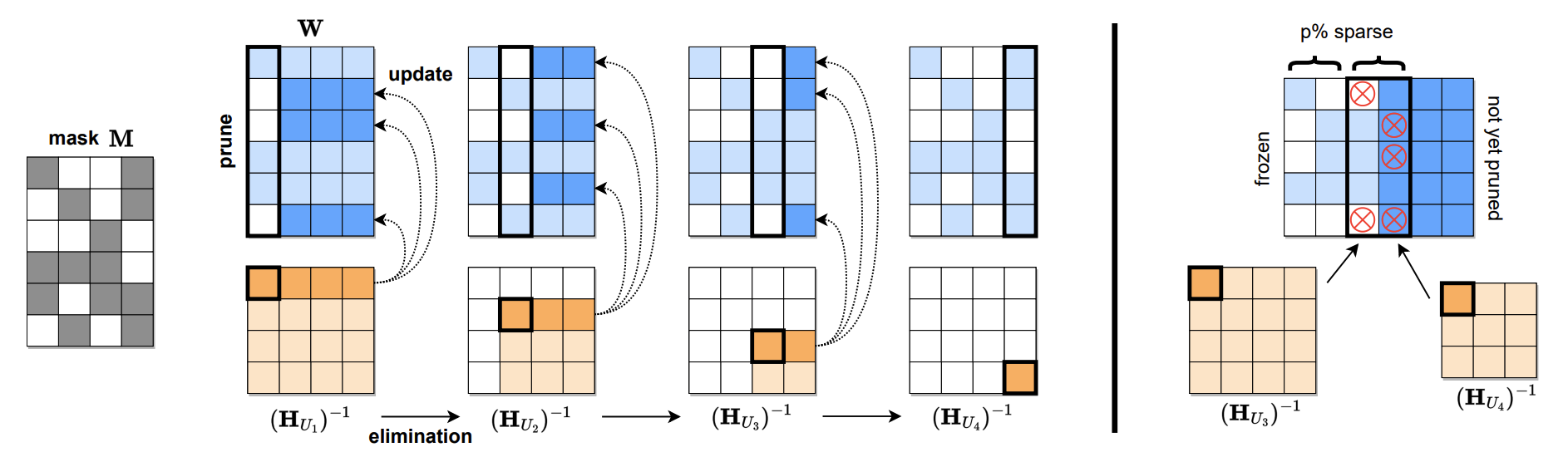 | Papel Github |
LLM-PRUNER: Sobre a poda estrutural de grandes modelos de linguagem Xinyin ma, gongfan fang, xinchao wang | 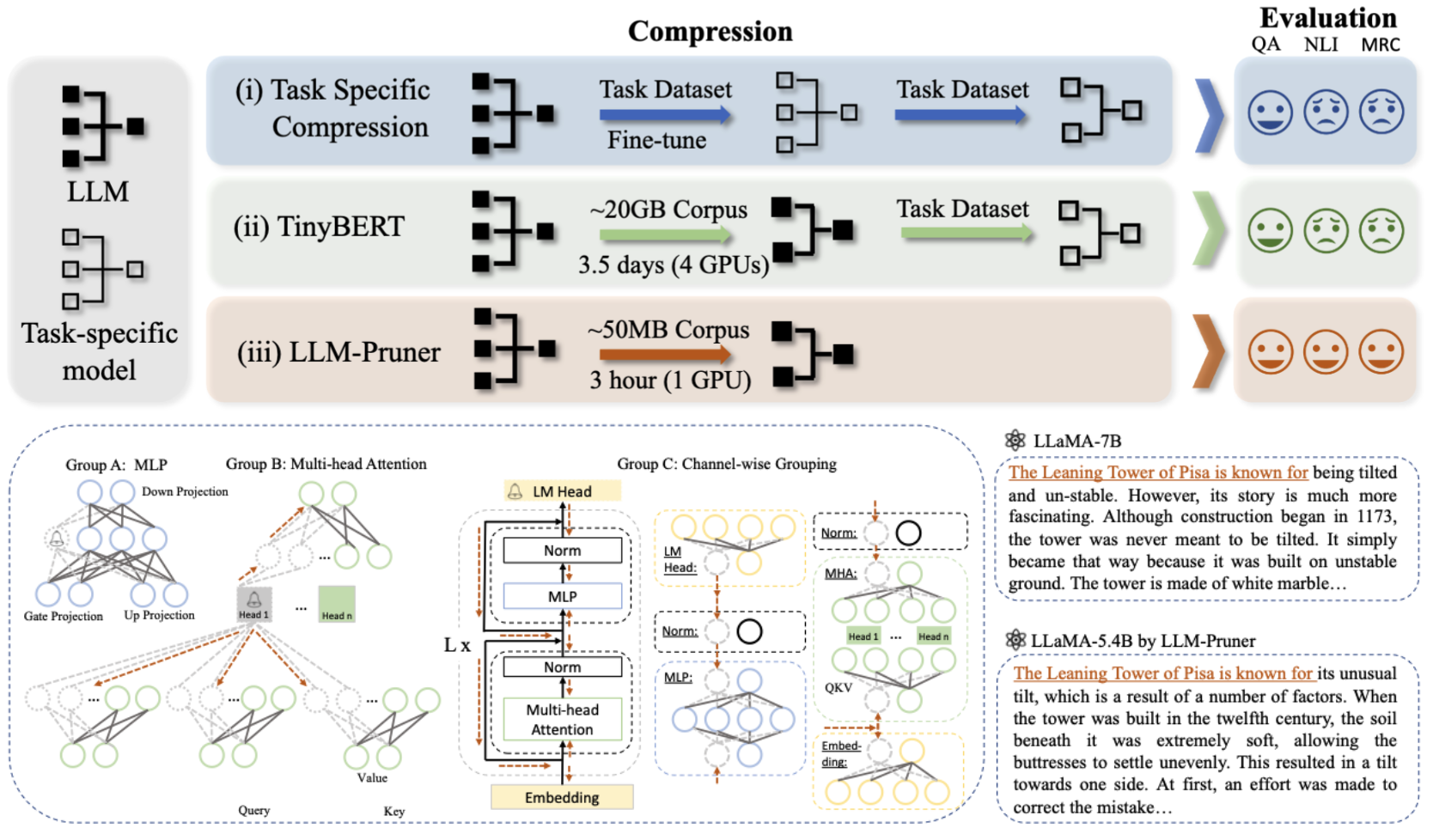 | Papel Github |
Uma abordagem de poda simples e eficaz para grandes modelos de linguagem Mingjie Sun, Zhuang Liu, Anna Bair, J. Zico Kolter | 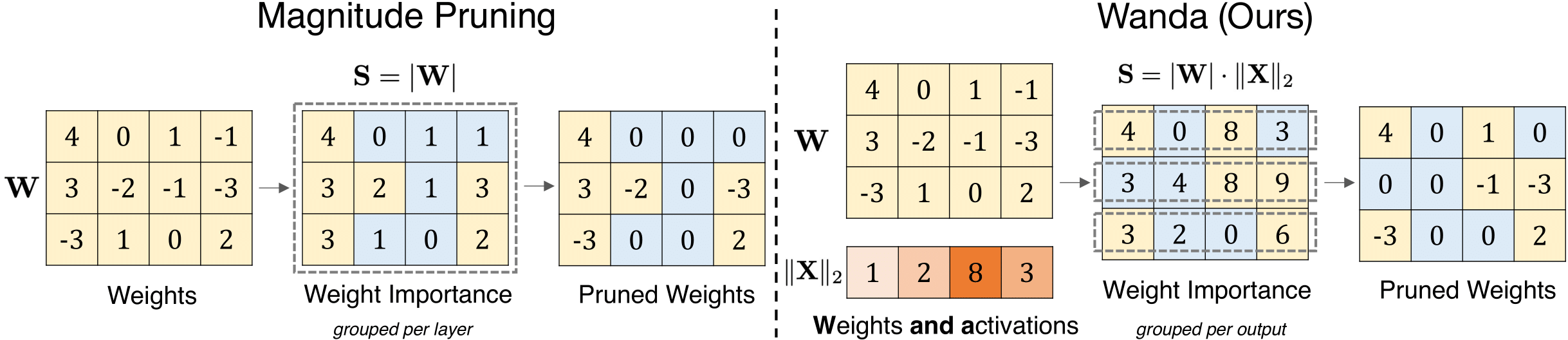 | Github Papel |
Lhama cisalhada: acelerando o modelo de idioma pré-treinamento via poda estruturada Mengzhou Xia, Tianyu Gao, Zhiyuan Zeng, Danqi Chen | 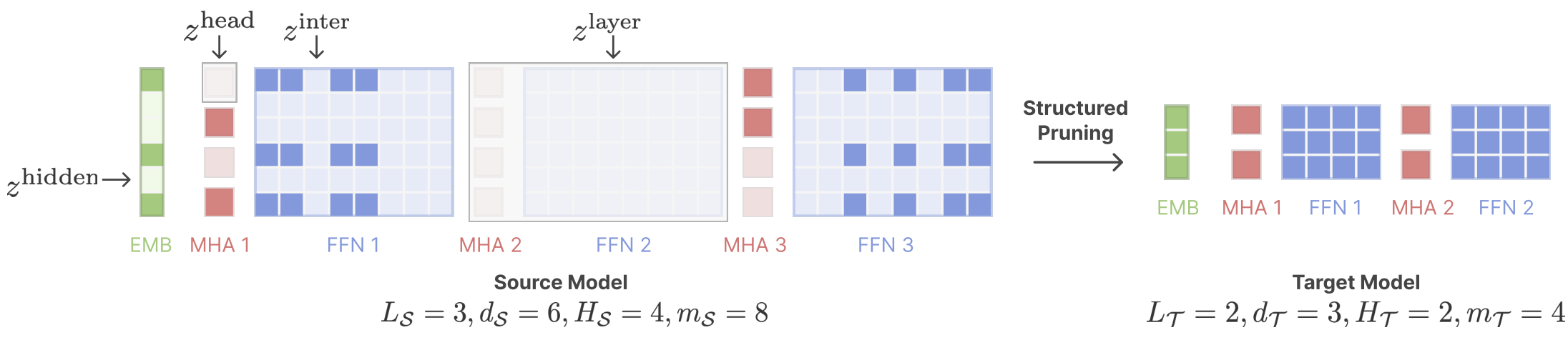 | Github Papel |
| Inferência eficiente de LLM usando a poda de entrada dinâmica e mascarar com consciência de cache Marco Federici, Davide Belli, Mart Van Baalen, Amir Jalalirad, Andrii Skliar, Major de Bence, Markus Nagel, Paul Whatmough | Papel | |
| Puzzle: NAS baseado em destilação para LLMs otimizados para inferência Akhiad Bercovich, Tomer Ronen, Talor Abramovich, Nir Ailon, Nave Assáf, Mohammad Dabbah et al | Papel | |
Reavaliando a poda da camada no LLMS: Novas idéias e métodos Yao Lu, Hao Cheng, Yujie Fang, Zeyu Wang, Jiaheng Wei, Dongwei Xu, Qi Xuan, Xiaoniu Yang, Zhaowei Zhu | 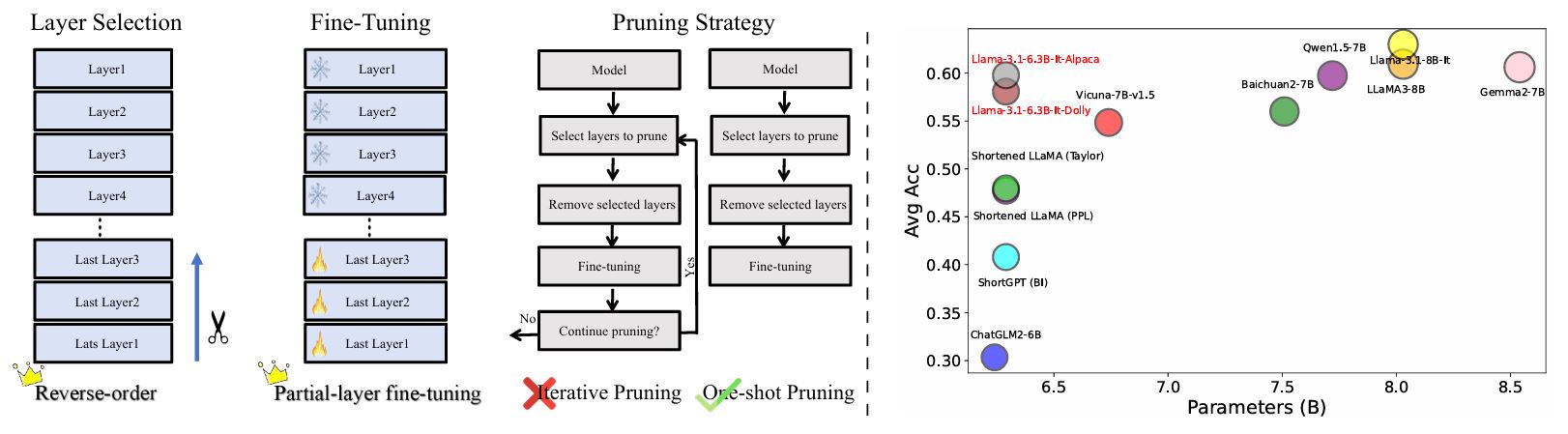 | Github Papel |
| Importância da camada e análise de alucinação em grandes modelos de idiomas por meio de aprimoramento da variância de ativação de ativação Música Zichen, Sitan Huang, Yuxin Wu, Zhongfeng Kang | Papel | |
Amoeballm: Construindo qualquer modelos de idiomas de qualquer forma para implantação eficiente e instantânea Yonggan Fu, Zhongzhi YU, Junwei Li, Jiayi Qian, Yongan Zhang, Xiangchi Yuan, Dachuan Shi, Roman Yakunin, Yingyan Celine Lin | Github Papel | |
| Lei de escala para pós-treinamento após a poda do modelo Xiaodong Chen, Yuxuan Hu, Jing Zhang, Xiaokang Zhang, Cuiping Li, Hong Chen | Papel | |
DRPRUNING: Modelo de linguagem grande eficiente podando por meio de otimização distribuída robusta distribuída Hexuan Deng, Wenxiang Jiao, Xuebo Liu, Min Zhang, Zhaopeng Tu |  | Github Papel |
Lei de Sparsing: Rumo a grandes modelos de idiomas com maior escassez de ativação Yuqi Luo, Chenyang Song, Xu Han, Yingfa Chen, Chaojun Xiao, Zhiyuan Liu, Maosong Sun | 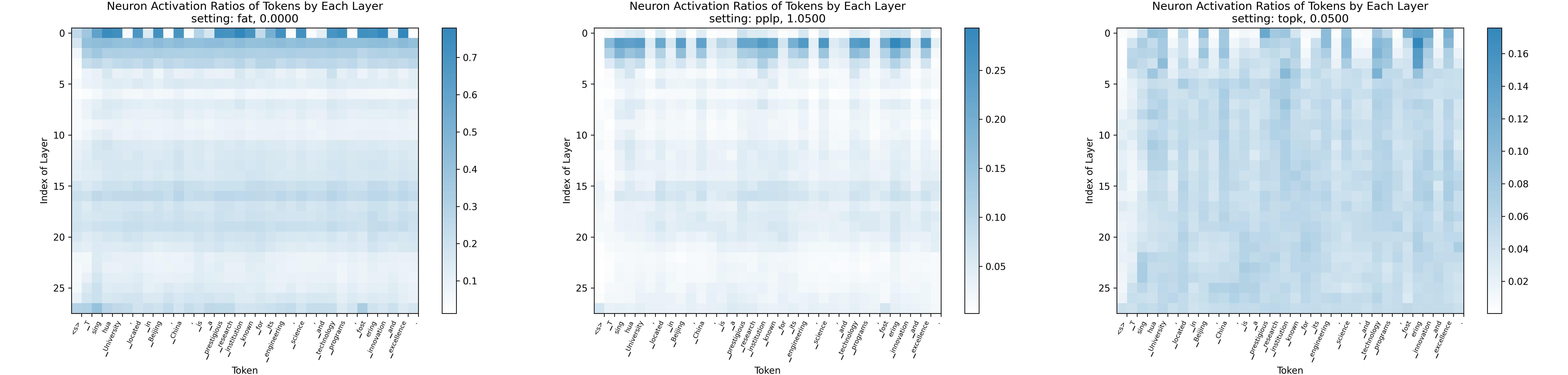 | Github Papel |
| AVSS: Avaliação de importância da camada em grandes modelos de linguagem por meio de análise de variação de ativação Sparsity Analysis Zichen Song, Yuxin Wu, Sitan Huang, Zhongfeng Kang | Papel | |
| Llama personalizado: otimizando o aprendizado de poucos anos em modelos de llama podados com prompts específicos de tarefas Danyal Aftab, Steven Davy | Papel | |
LLMCBEnch: Benchmarking Language Model Compression para implantação eficiente Ge Yang, Changyi He, Jinyang Guo, Jianyu Wu, Yifu Ding, Aishan Liu, Haotong Qin, Pengliang Ji, Xianglong Liu | 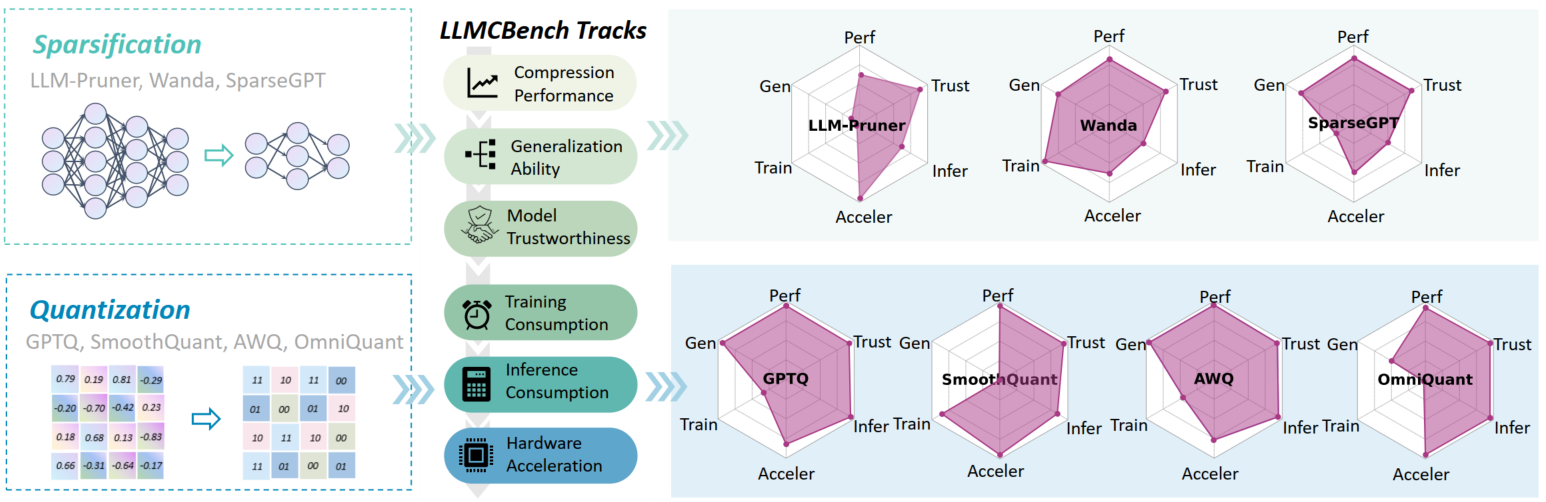 | Github Papel |
| Além de 2: 4: Explorando V: N: M Sparsidade para Inferência eficiente do transformador em GPUs Kang Zhao, Tao Yuan, Han Bao, Zhenfeng Su, Chang Gao, Zhaofeng Sun, Zichen Liang, Liping Jing, Jianfei Chen | Papel | |
Evapress: Rumo à compactação ideal do modelo dinâmico via pesquisa evolutiva Oliver Sieberling, Denis Kuznedelev, Eldar Kurtic, Dan Alistarh |  | Github Papel |
| Fedspallm: poda federada de grandes modelos de linguagem Guangji Bai, Yijiang Li, Zilinghan Li, Liang Zhao, Kibaek Kim | Papel | |
Modelos de Fundação de poda para alta precisão sem reciclagem Pu Zhao, Fei Sun, Xuan Shen, Pinrui Yu, Zhenglun Kong, Yanzhi Wang, Xue Lin | Github Papel | |
| Autocalibração para quantização e poda do modelo de linguagem Miles Williams, George Chryssostomou, Nikolaos Aletras | Papel | |
| Cuidado com dados de calibração para podar grandes modelos de linguagem Yixin Ji, Yang Xiang, Juntao Li, Qingrong Xia, Ping Li, Xinyu Duan, Zhefeng Wang, Min Zhang | Papel | |
Alphapruning: Usando teoria de regularização de cauda pesada para melhorar a poda de camada de grandes modelos de linguagem Haiquan Lu, Yefan Zhou, Shiwei Liu, Zhangyang Wang, Michael W. Mahoney, Yaoqing Yang | Github Papel | |
| Além das aproximações lineares: uma nova abordagem de poda para matriz de atenção Yingyu Liang, Jiangxuan Long, Zhenmei Shi, Zhao Song, Yufa Zhou | Papel | |
Disp-llm: poda estrutural independente da dimensão para modelos de idiomas grandes Shangqian Gao, Chi-Heng Lin, Ting Hua, Tang Zheng, Yilin Shen, Hongxia Jin, Yen-Chang Hsu | Papel | |
Destilação de auto-dados para recuperar a qualidade em grandes modelos de linguagem Vithursan Thangarasa, Ganesh Venkatesh, Nish Sinnadurai, Sean Lie | Papel | |
| LLM-RANK: Uma abordagem teórica do gráfico para podar grandes modelos de linguagem David Hoffmann, Kailash Budhathoki, Matthaeus Kleindessner | Papel | |
O conjunto de dados C4 é ideal para poda? Uma investigação de dados de calibração para a poda de LLM Abhinav Bandari, Lu Yin, Cheng-Yu Hsieh, Ajay Kumar Jaiswal, Tianlong Chen, Li Shen, Ranjay Krishna, Shiwei Liu Liu | Github Papel | |
| Mitigar o viés de cópia no aprendizado no contexto através da poda de neurônios Ameen Ali, Lior Wolf, Ivan Titov | 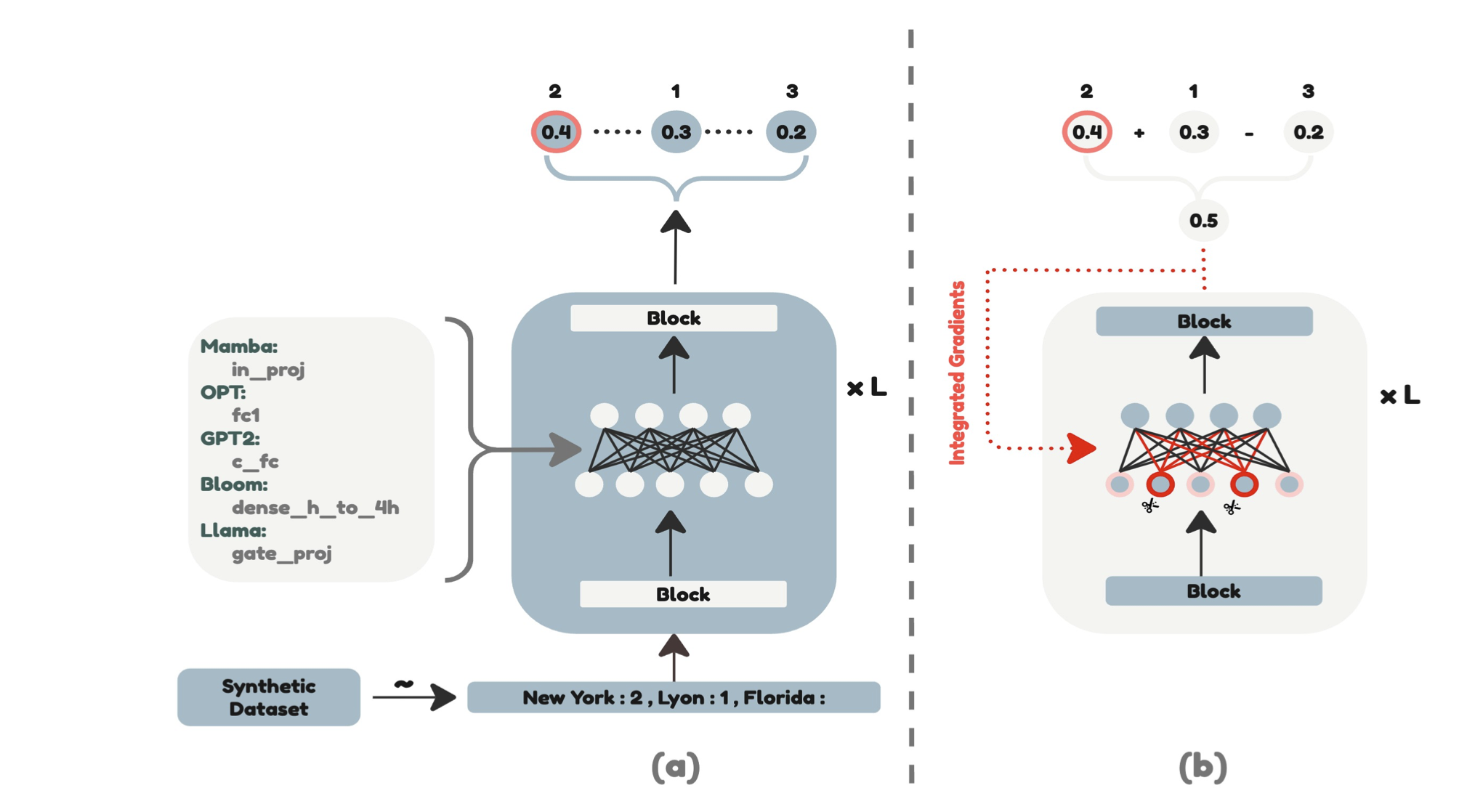 | Papel |
Sqft: adaptação de modelo de baixo custo em modelos de base esparsa de baixa precisão Juan Pablo Munoz, Jinjie Yuan, Nilesh Jain | 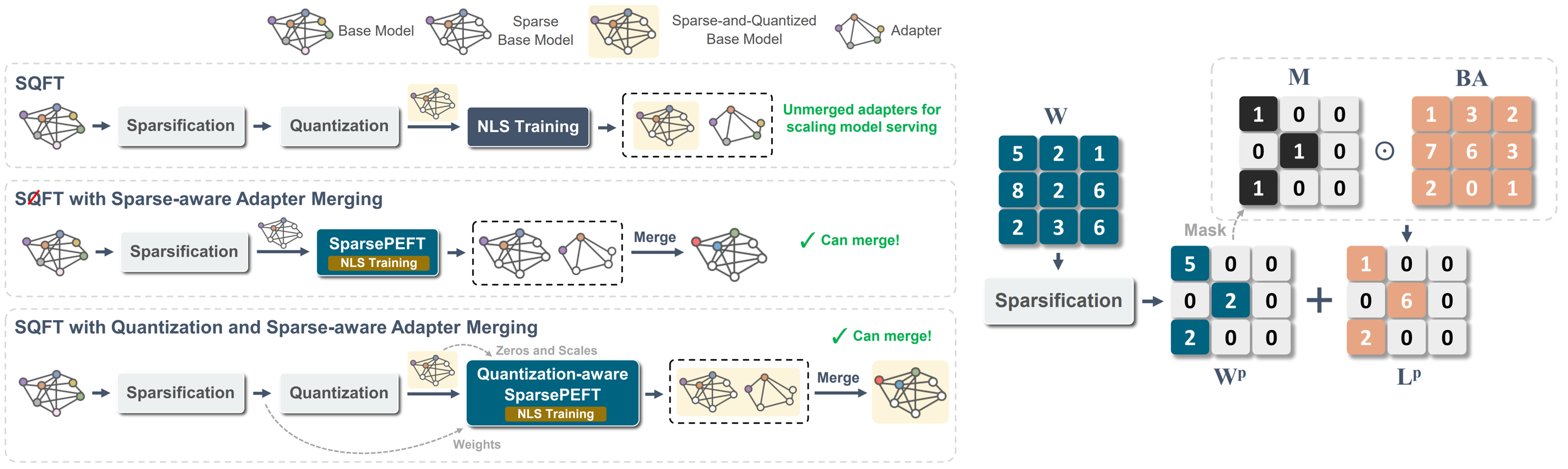 | Github Papel |
Maskllm: Sparsidade semiestruturada aprendida para modelos de idiomas grandes Gongfan Fang, Hongxu Yin, Saurav Muralidharan, Greg Heinrich, Jeff Pool, Jan Kautz, Pavlo Molchanov, Xinchao Wang | 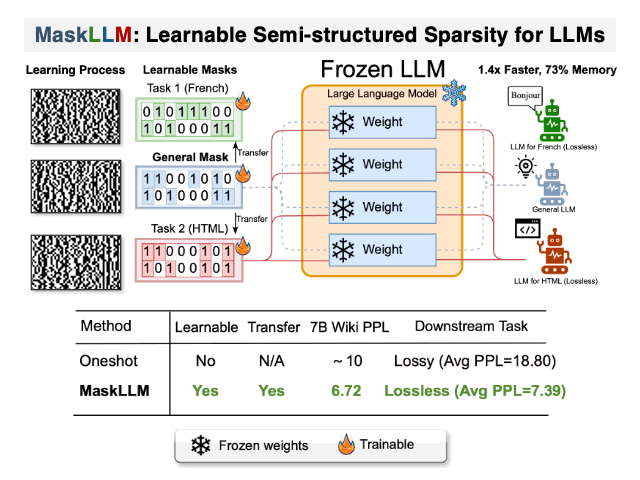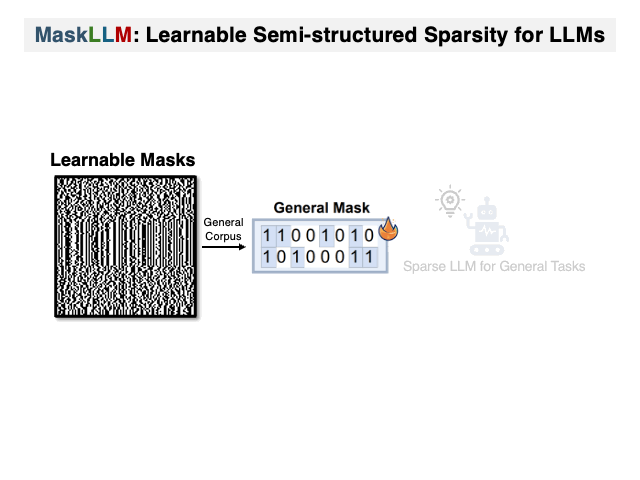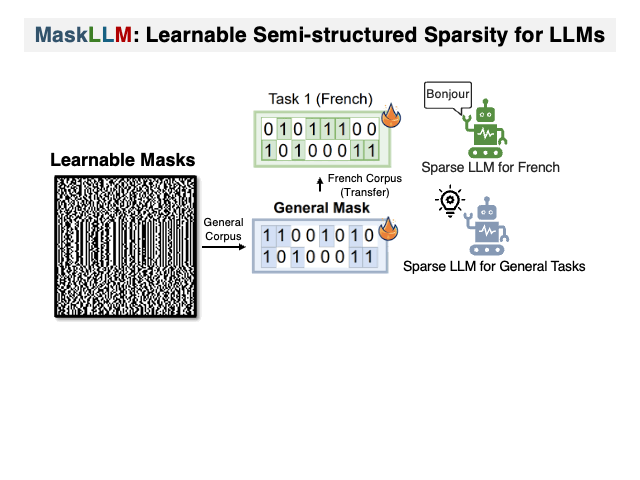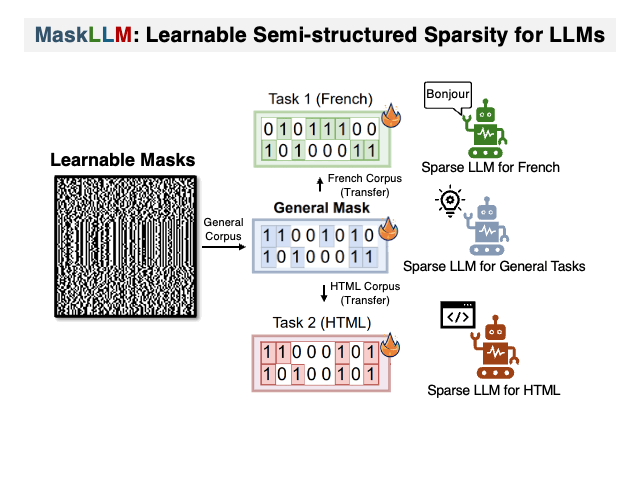 | Github Papel |
Pesquise modelos de linguagem eficientes grandes de linguagem Xuan Shen, Pu Zhao, Yifan Gong, Zhenglun Kong, Zheng Zhan, Yushu Wu, Ming Lin, Chao Wu, Xue Lin, Yanzhi Wang | Papel | |
CFSP: uma estrutura de poda estruturada eficiente para LLMs com informações de ativação grossa para a fila Yuxin Wang, Minghua MA, Zekun Wang, Jingchang Chen, Huiming Fan, Liping Shan, Qing Yang, Dongliang Xu, Ming Liu, Bing Qin | Github Papel | |
| Aveia: poda de cedimento de outlier através da decomposição esparsa e de baixa classificação Stephen Zhang, Vardan Papyan | Papel | |
| KVPRUNER: poda estrutural para modelos de linguagem grande e com eficiência de memória mais rápidos e com eficiência de memória Bo Lv, Quan Zhou, Xuanang Ding, Yan Wang, Zeming MA | Papel | |
| Avaliando o impacto das técnicas de compressão no desempenho específico da tarefa de grandes modelos de linguagem Bishwash Khanal, Jeffery M. Capone | Papel | |
| Atordo: a poda estruturada-then-thestutured para a poda de moe escalável Jaeseong Lee, Seung-Won Hwang, Aurick Qiao, Daniel F Campos, Zhewei Yao, Yuxiong Ele | Papel | |
Pat: Ajuste com reconhecimento de poda para modelos de idiomas grandes Yijiang Liu, Huanrui Yang, Youxin Chen, Rongyu Zhang, Miao Wang, Yuan du, Li du Du | 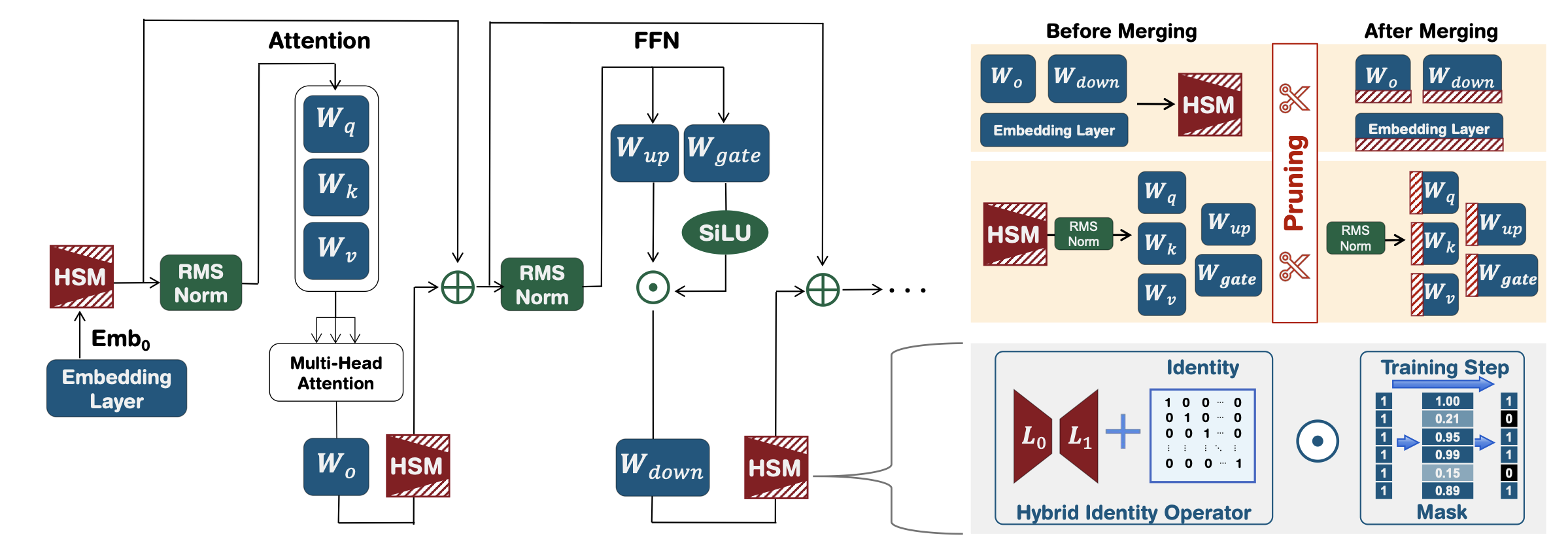 | Github Papel |
| Título e autores | Introdução | Links |
|---|---|---|
| Destilação de conhecimento de grandes modelos de linguagem Yuxian Gu, Li Dong, Furu Wei, Minlie Huang |  | Github Papel |
| Melhorando os recursos de raciocínio matemático de modelos de pequenos modelos por meio de destilação orientada por feedback Xunyu Zhu, Jian Li, Can Ma, Weiping Wang | Papel | |
Destilação de contexto generativo Haebin Shin, Lei JI, Yeyun Gong, Sungdong Kim, Eunbi Choi, Minjoon SEO | 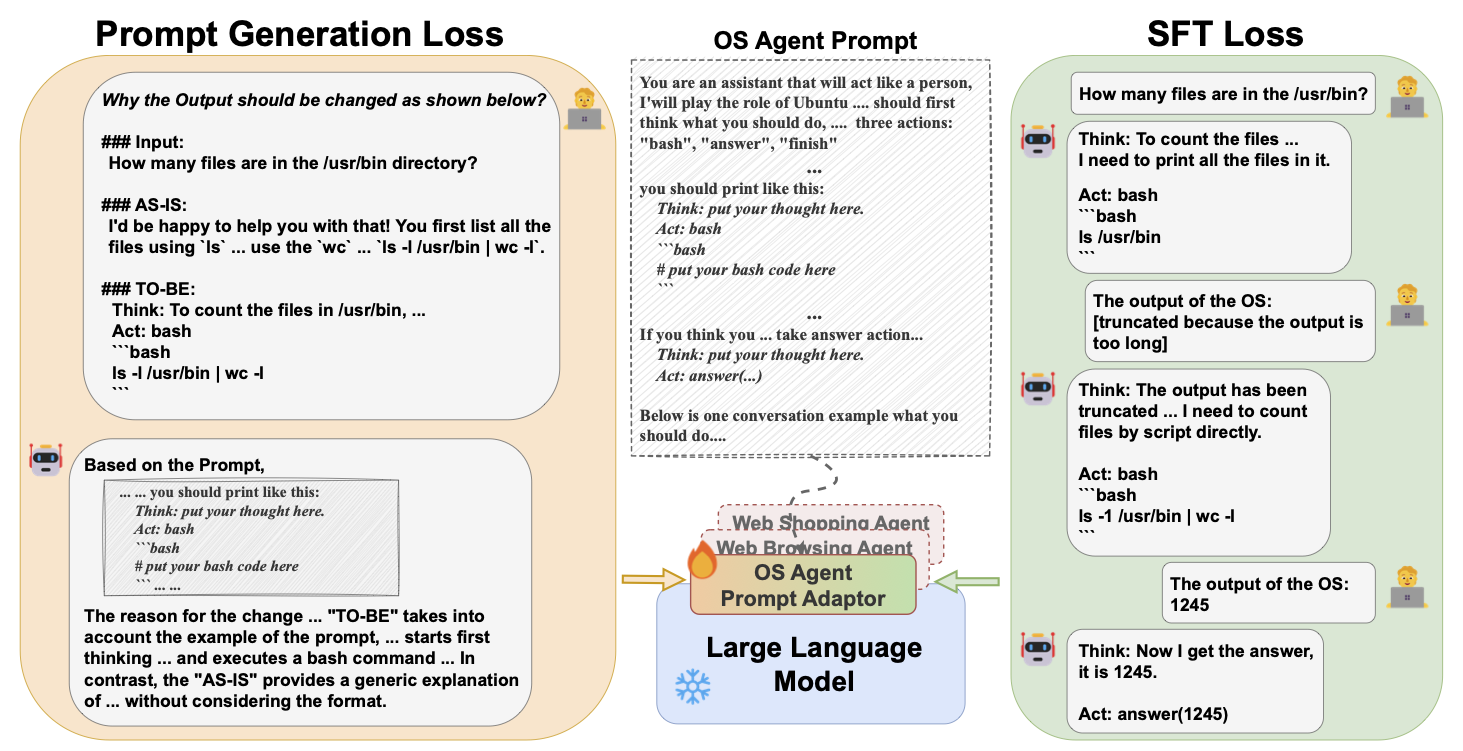 | Github Papel |
| Switch: estudando com o professor para destilação de conhecimento de grandes modelos de idiomas Jahyun Koo, Yerin Hwang, Yongil Kim, Taegwan Kang, Hyunkyung Bae, Kyomin Jung |  | Papel |
Além da AutoRegression: Fast LLMs via auto-distribuição ao longo do tempo Justin Deschenaux, Caglar Gulcehre | Github Papel | |
| Destilação pré-treinamento para modelos de linguagem grande: uma exploração de espaço de design Hao Peng, Xin LV, Yushi Bai, Zijun Yao, Jiajie Zhang, Lei Hou, Juanzi Li | Papel | |
MiniplM: destilação de conhecimento para modelos de idiomas pré-treinamento Yuxian Gu, Hao Zhou, Fandong Meng, Jie Zhou, Minlie Huang | 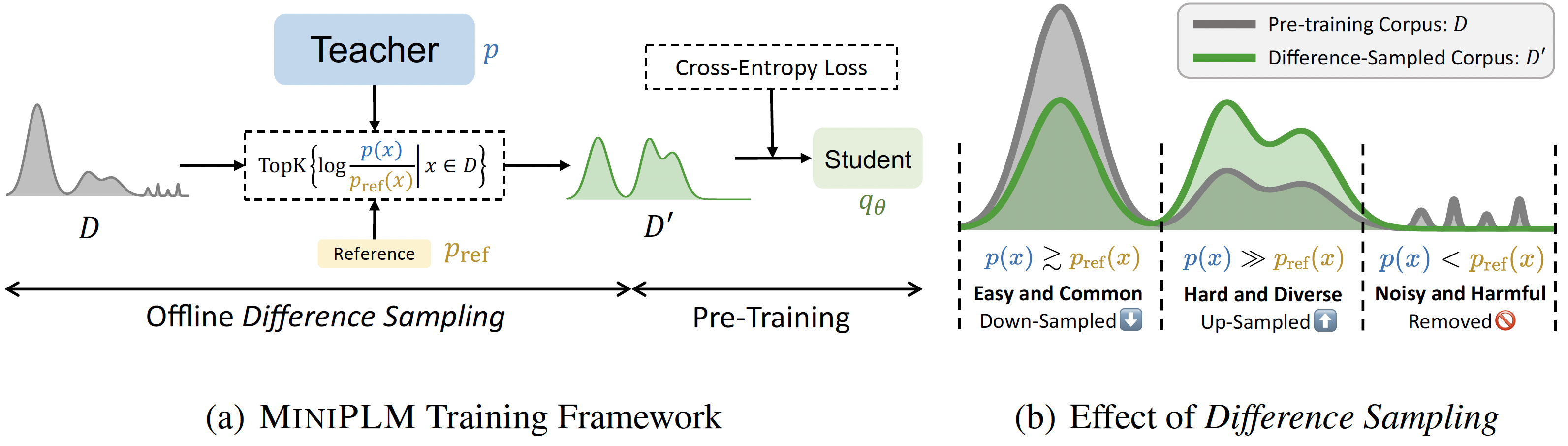 | Github Papel |
| Destilação do conhecimento especulativo: Bridging da lacuna de professor-aluno através de amostragem intercalada Wenda Xu, Rujun Han, Zifeng Wang, Long T. Le, Dhruv Madeka, Lei Li, William Yang Wang, Rishabh Agarwal, Chen-Yu Lee, Tomas Pfister | Papel | |
| Destilação contrastiva evolutiva para o alinhamento do modelo de linguagem Julian Katz-Samuels, Zheng Li, Hyokun Yun, Priyanka Nigam, Yi Xu, Vaclav Petricek, Bing Yin, Trishul Chilimbi | Papel | |
| Babyllama-2: modelos dististidos de conjunto superam os professores de forma consistente com dados limitados Jean-Loup Tastet, Ino Timiryasov | Papel | |
| Echoatt: Participe, copie e ajuste para modelos de idiomas grandes mais eficientes Hossein Rajabzadeh, Aref Jafari, Aman Sharma, Benyamin Jami, Hyock Ju Kwon, Ali Ghodsi, Boxing Chen, Mehdi Rezagholizadeh | Papel | |
Skintern: Internalizando o conhecimento simbólico para destilar melhores recursos de COT em modelos de idiomas pequenos Huanxuan Liao, Shizhu He, Yupu Hao, Xiang Li, Yuanzhe Zhang, Kang Liu, Jun Zhao | Github Papel | |
LLMR: destilação de conhecimento com uma grande recompensa induzida por modelo de linguagem Dongheng Li, Yongchang Hao, Lili MOU | 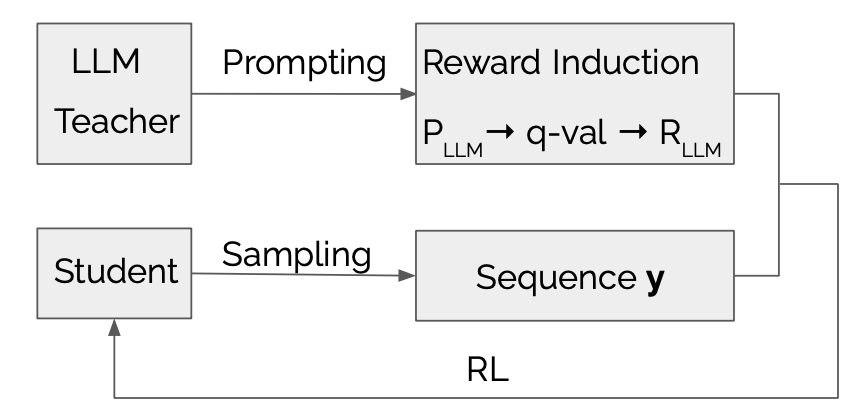 | Github Papel |
| Explorando e aprimorando a transferência de distribuição na destilação do conhecimento para modelos de linguagem autoregressiva Jun Rao, Xuebo Liu, Zepeng Lin, Liang Ding, Jing Li, Dacheng Tao | Papel | |
| Distilação eficiente do conhecimento: capacitar pequenos modelos de idiomas com insights de modelos de professores Mohamad Ballout, Ulf Krumnack, Gunther Heidemann, Kai-Uwe Kühnberger | Papel | |
O Mamba na llama: destilando e acelerando modelos híbridos Junxiong Wang, Daniele Paliotta, Avner May, Alexander M. Rush, Tri Dao | Github Papel |
| Título e autores | Introdução | Links |
|---|---|---|
GPTQ: quantização precisa do pós-treinamento para transformadores pré-treinados generativos Elias Frantar, Saleh Ashkboos, Torsten Hoefler, Dan Alistarh | 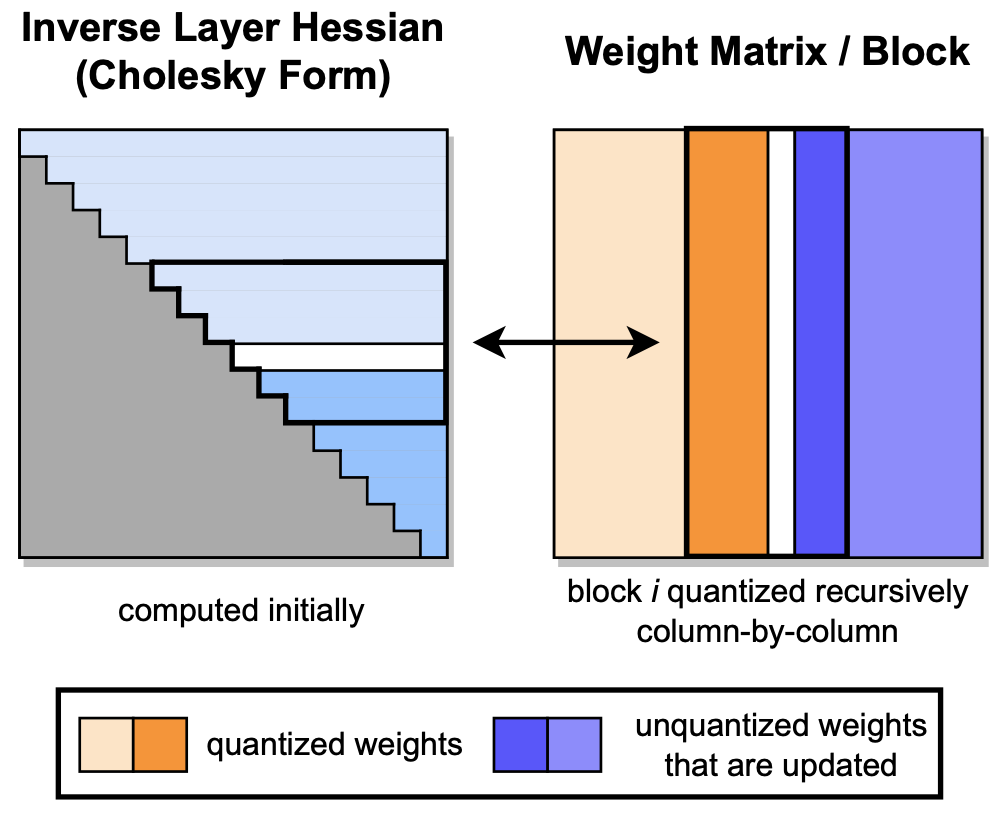 | Github Papel |
Smoothquant: quantização pós-treinamento precisa e eficiente para modelos de linguagem grandes Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, Song Han | 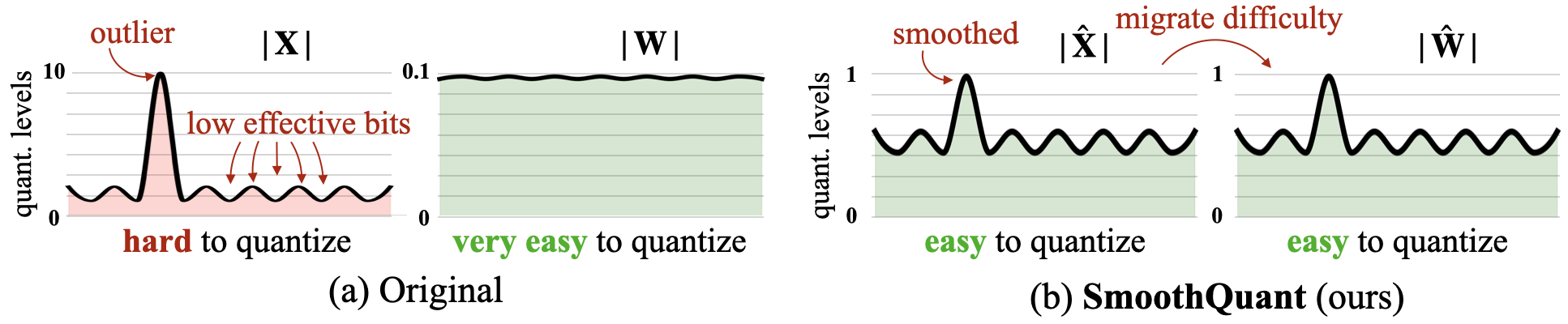 | Github Papel |
AWQ: quantização de peso com consciência de ativação para compactação e aceleração de LLM Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Xingyu Dang, Song Han | 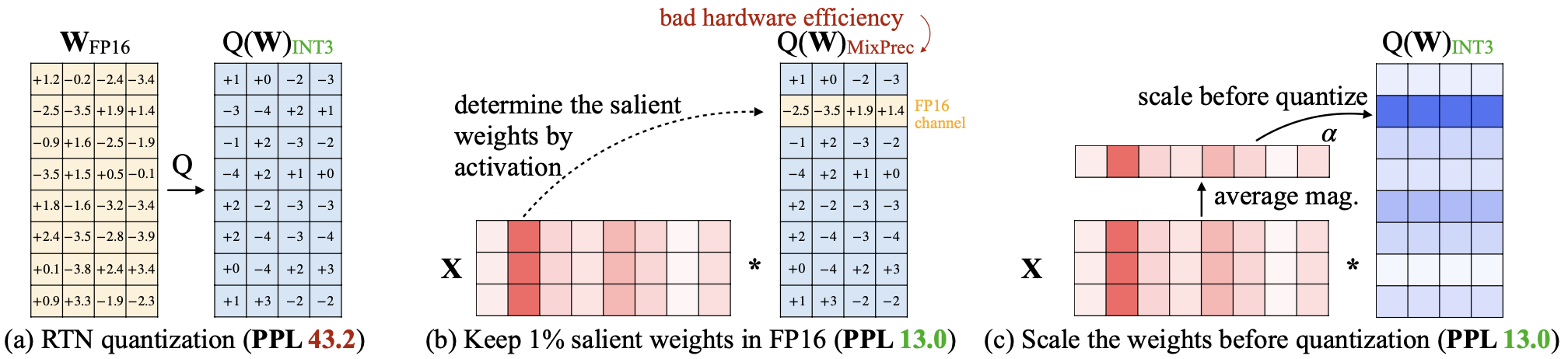 | Github Papel |
Omniquante: quantização onidirecionalmente calibrada para modelos de linguagem grandes Wenqi Shao, Mengzhao Chen, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqian Li, Kaipeng Zhang, Peng Gao, Yu Qiao, Ping Luo | 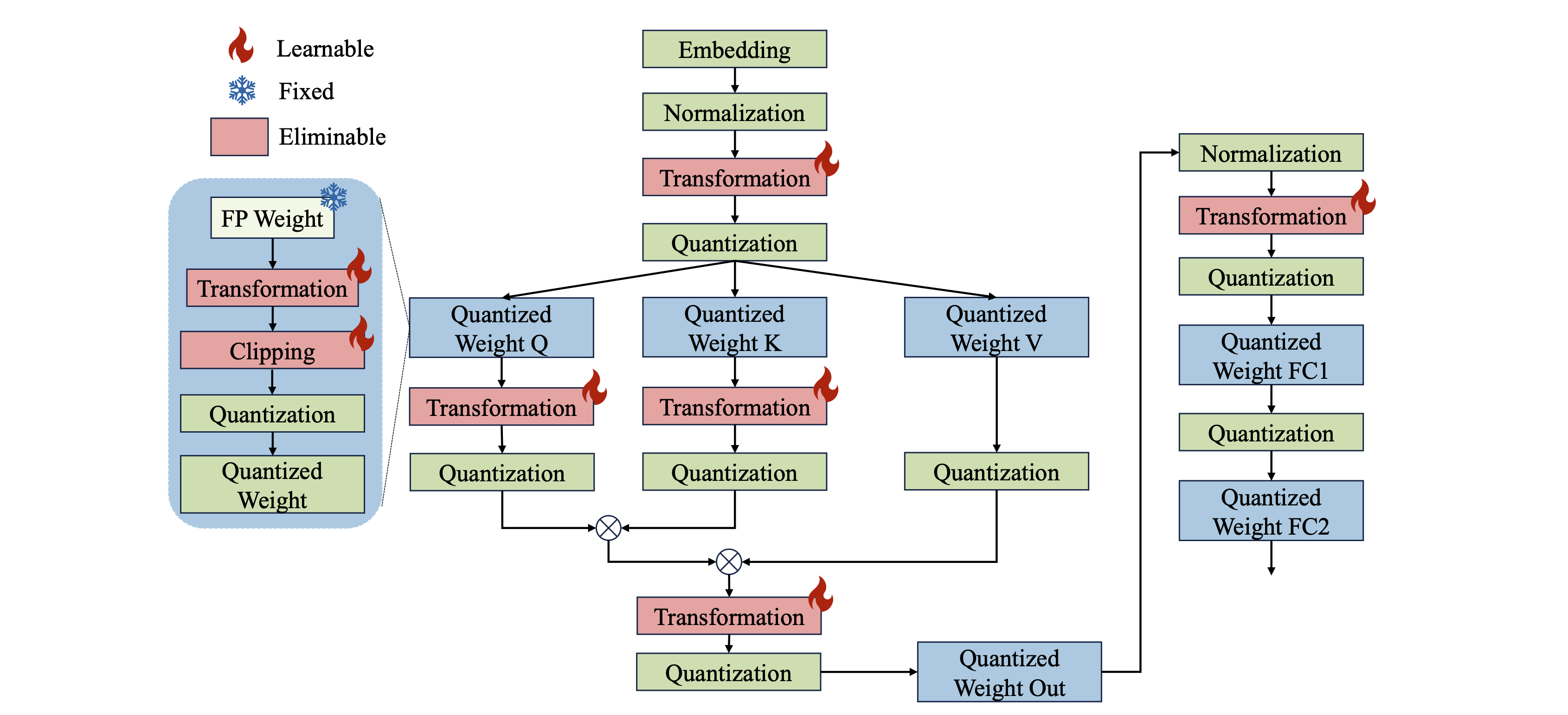 | Github Papel |
| SKIM: Quantização de qualquer bit Pursando os limites da quantização pós-treinamento Rundsheng Bai, Qiang Liu, Bo Liu | Papel | |
| CPTQUANT-Uma nova precisão mista pós-treinamento técnicas de quantização para modelos de linguagem grandes Amitash Nanda, Sree Bhargavi Balija, Debashis Sahoo | Papel | |
ANDA: Desbloqueando a inferência eficiente de LLM com um formato de dados de ativação agrupado de comprimento variável Chao Fang, Man Shi, Robin Geens, Arne Symons, Zhongfeng Wang, Marian Verhelst | Papel | |
| Mixpe: quantização e co-design de hardware para inferência eficiente de LLM Yu Zhang, Mingzi Wang, Lancheng Zou, Wulong Liu, Hui-Ling Zhen, Mingxuan Yuan, Bei Yu | Papel | |
Bitmod: Aceleração da mistura de dados de bit-serial-Datatype LLM Yuzong Chen, Ahmed F. Abouelamayed, Xilai Dai, Yang Wang, Marta Andronic, George A. Constantinides, Mohamed S. Abdelfattah | Github Papel | |
| AMXFP4: Excesso de atividades domesticantes com ponto flutuante de microscaling assimétrico para inferência de 4 bits LLM Janghwan Lee, Jiwoong Park, Jinseok Kim, Yongjik Kim, Jungju Oh, Jinwook Oh, Jungwook Choi | 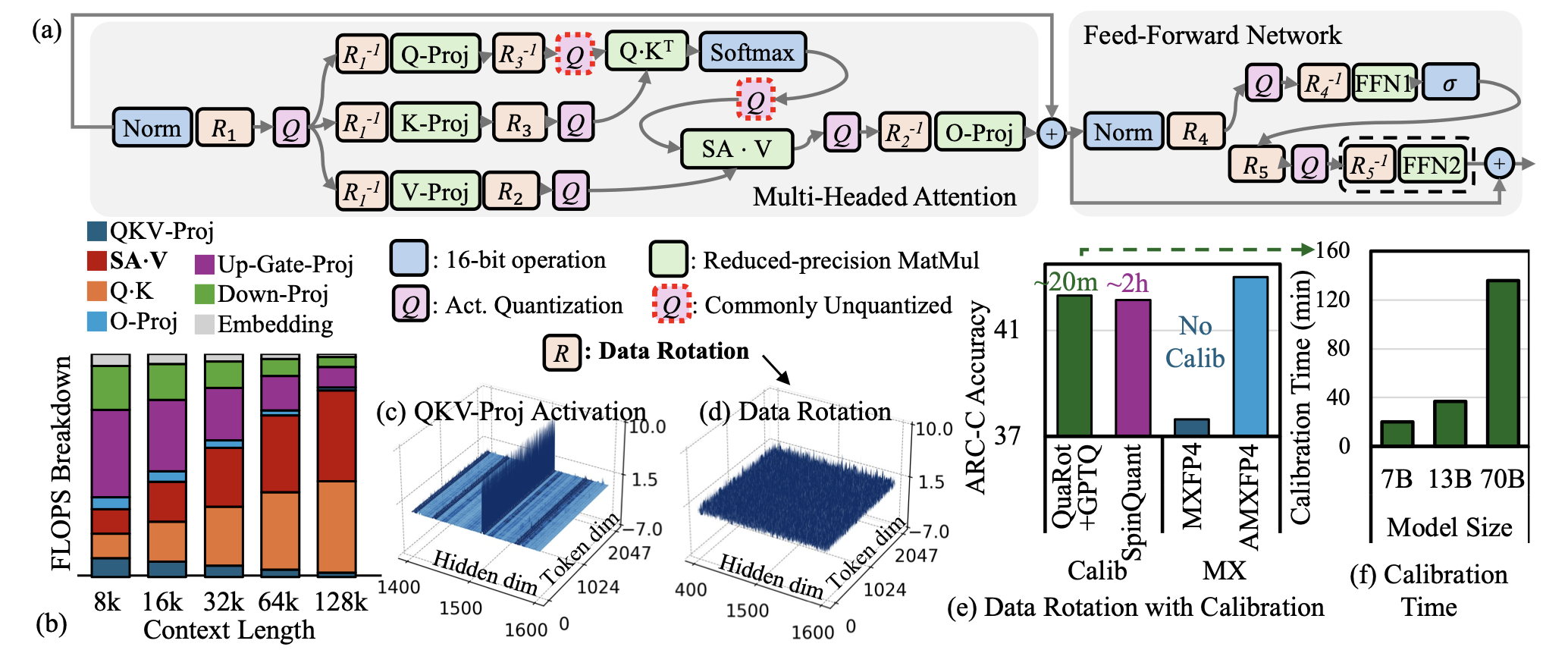 | Papel |
| Bi-Mamba: em direção a modelos precisos de espaço de estado de 1 bits Shengkun Tang, Liqun MA, Haonan Li, Mingjie Sun, Zhiqiang Shen | Papel | |
| "Dê -me BF16 ou me dê a morte"? Compensações de desempenho da precisão na quantização de LLM Eldar Kurtic, Alexandre Marques, Shubhra Pandit, Mark Kurtz, Dan Alistarh | Papel | |
| GWQ: quantização de peso com reconhecimento de gradiente para grandes modelos de linguagem Yihua Shao, Siyu Liang, Xiaolin Lin, Zijian Ling, Zixian Zhu et al | Papel | |
| Um estudo abrangente sobre técnicas de quantização para grandes modelos de linguagem Jiedong Lang, Zhehao Guo, Shuyu Huang | Papel | |
| Ativações BitNet A4.8: 4 bits para LLMs de 1 bits Hongyu Wang, Shuming MA, Furu Wei | Papel | |
Tesseraq: quantização pós-treinamento LLM de bit-bit com reconstrução de blocos Yuhang Li, Priyadarshini Panda | 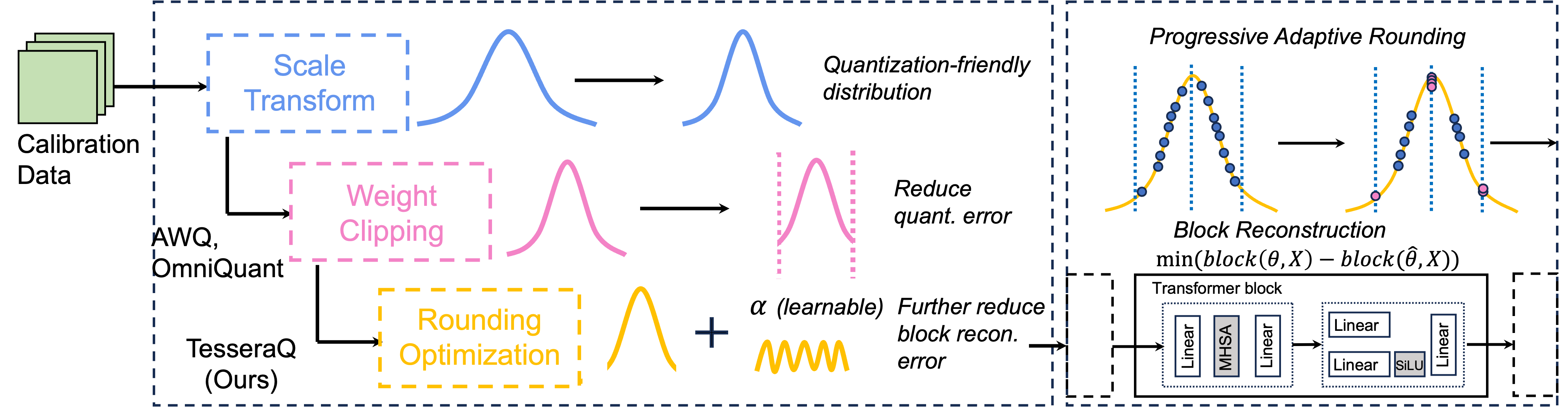 | Github Papel |
Bitstack: Controle de tamanho de grão fino para modelos de linguagem grande compactada em ambientes de memória variável Xinghao Wang, Pengyu Wang, Bo Wang, Dong Zhang, Yunhua Zhou, XIPENG QIU | 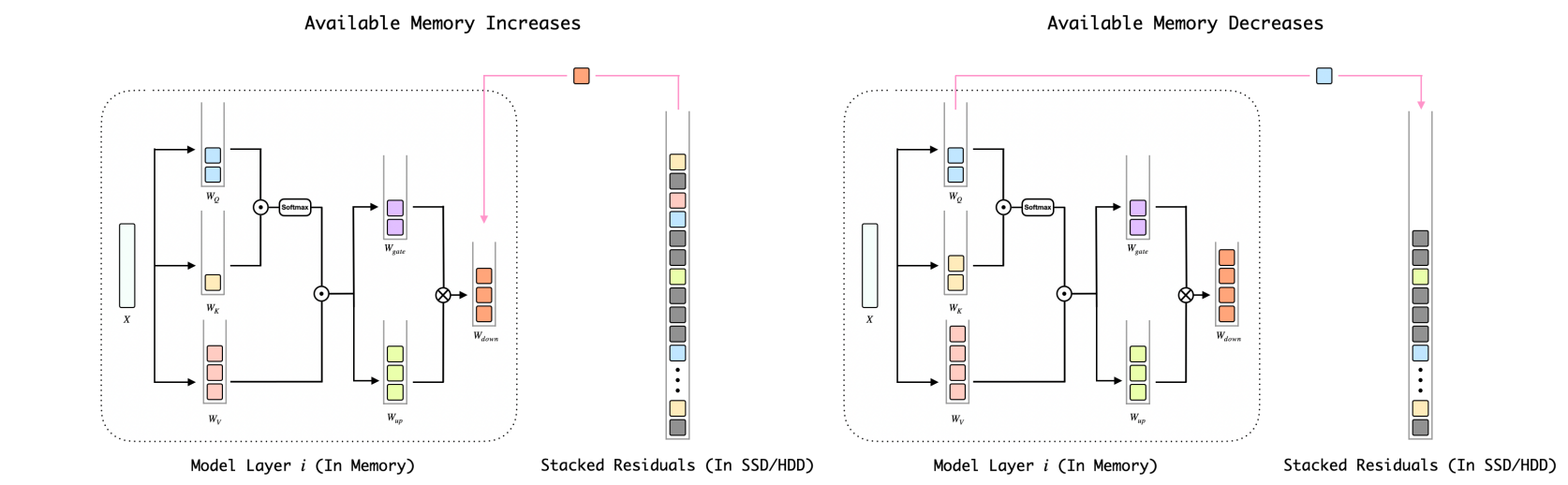 | Github Papel |
| O impacto das estratégias de aceleração de inferência no viés do LLMS Elisabeth Kirsten, Ivan Habernal, Vedant Nanda, Muhammad Bilal Zafar | Papel | |
| Compreendendo a dificuldade da quantização pós-treinamento de baixa precisão de grandes modelos de linguagem Zifei Xu, Sayeh Sharify, Wanzin Yazar, Tristan Webb, Xin Wang | Papel | |
Infra de AI de 1 bit: Parte 1.1, BitNet Fast e sem perdas B1.58 Inferência nas CPUs Jinheng Wang, Hansong Zhou, Ting Song, Shaoguang Mao, Shuming MA, Hongyu Wang, Yan Xia, Furu Wei | Github Papel | |
| Quailora: inicialização de quantização e consciência para Lora Neal Lawton, Aishwarya Padmakumar, Judith Gaspers, Jack Fitzgerald, Anoop Kumar, Greg Vereg, Aram Galstyan | Papel | |
| Avaliando modelos de linguagem quantizados grandes para geração de código em benchmarks de idioma de baixo recurso Enkhbold Nyamsuren | Papel | |
Squeezellm: quantização densa e pouca Sehoon Kim, Coleman Hooper, Amir Gholami, Zhen Dong, Xiuyu Li, Sheng Shen, Michael W. Mahoney, Kurt Keutzer | 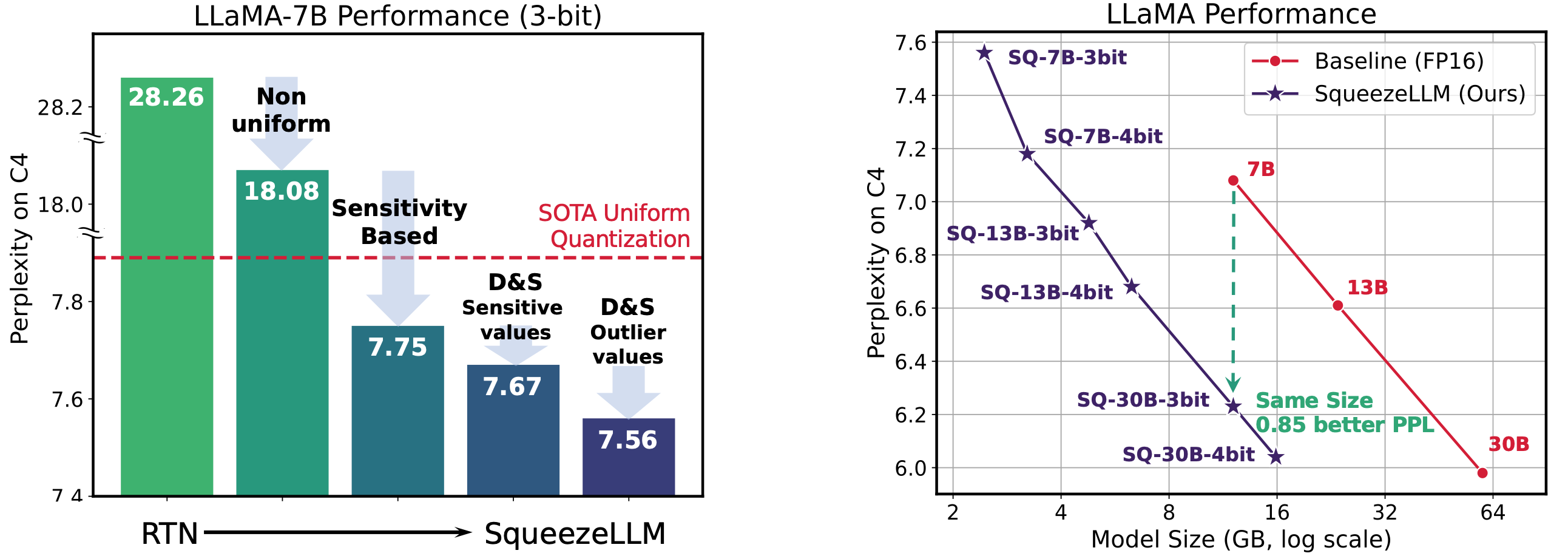 | Github Papel |
| Quantização de vetor de pirâmide para LLMS Tycho Fa van der Ougeraa, Maximilian L. Croci, Agrin Hilmkil, James Hensman | Papel | |
| MEDLM: Comprimindo pesos LLM em sementes de geradores pseudo-aleatórios Rasoul Shafipour, David Harrison, Maxwell Horton, Jeffrey Marker, Houman Bedayat, Sachin Mehta, Mohammad Rastegari, Mahyar Najibi, Saman Naderiparizi | Papel | |
FlatQuant: Andless Matters for LLM Quantization Yuxuan Sun, Ruikang Liu, Haoli Bai, Han Bao, Kang Zhao, Yuening Li, Jiaxin Hu, Xianzhi Yu, Lu Hou, Chun Yuan, Xin Jiang, Wulong Liu, Jun Yao | Github Papel | |
Slim: S-Shot Quantized Sparse Plus Baixa Aproximação de LLMs Mohammad Mozaffari, Maryam Mehri Dehnavi | Github Papel | |
| Leis de dimensionamento para modelos de linguagem grande pós-treinamento quantizados Zifei Xu, Alexander Lan, Wanzin Yazar, Tristan Webb, Sayeh Sharify, Xin Wang | Papel | |
| Aproximações contínuas para melhorar o treinamento consciente da quantização do LLMS Ele Li, Jianhang Hong, Yuanzhuo Wu, Snehal Adbol, Zonglin Li | Papel | |
DAQ: quantização de peso pós-treinamento com reconhecimento de densidade para LLMS Yingsong Luo, Ling Chen | Github Papel | |
Quamba: uma receita de quantização pós-treinamento para modelos de espaço de estado seletivo Hung-Yueh Chiang, Chi-Chih Chang, Natalia Frumkin, Kai-Chiang Wu, Diana Marculescu | Github Papel | |
| ASYMKV: Habilitando quantização de 1 bit de cache de kv com configurações de quantização assimétrica de camada em camada Qian Tao, Wenyuan Yu, Jingren Zhou | Papel | |
| Quantização de precisão mista no canal para modelos de idiomas grandes Zihan Chen, Bike Xie, Jundong Li, Cong Shen | Papel | |
| Decodificação progressiva de precisão mista para inferência eficiente de LLM Hao Mark Chen, Fuwen Tan, Alexandros Kouris, Royson Lee, Hongxiang Fan, Stylianos I. Venieris | Papel | |
ExAQ: quantização ciente do expoente para aceleração do LLMS Moran Shkolnik, Maxim Fishman, Brian Chmiel, Hilla Ben-Yaacov, Ron Banner, Kfir Yehuda Levy | 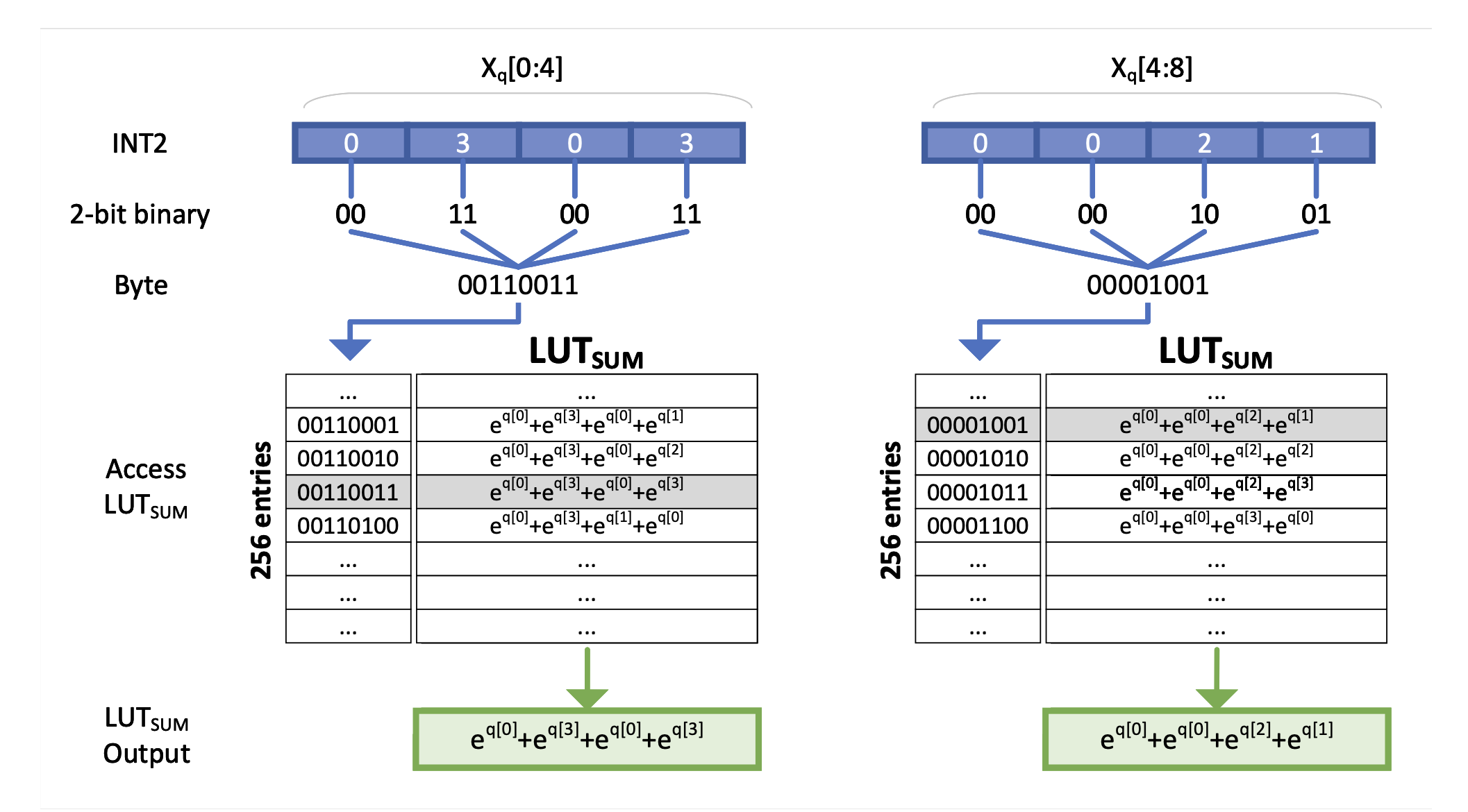 | Github Papel |
Prefixquant: A quantização estática bate dinâmica através de outliers prefixados no LLMS Mengzhao Chen, Yi Liu, Jiahao Wang, Yi Bin, Wenqi Shao, Ping Luo | Github Papel | |
Compressão extrema de grandes modelos de linguagem via quantização aditiva Vage Egiazarian, Andrei Panferov, Denis Kuznedelev, Elias Frantar, Artem Babenko, Dan Alistarh | 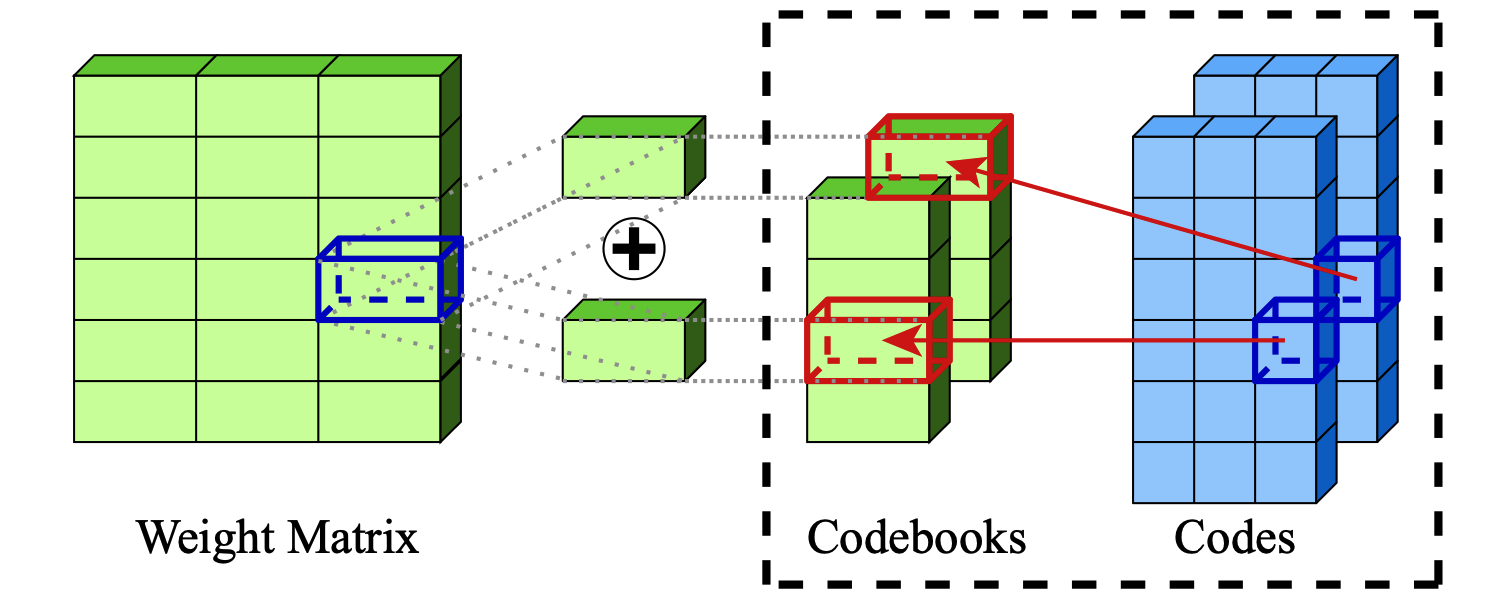 | Github Papel |
| Leis de dimensionamento para quantização mista em grandes modelos de linguagem Zeyu Cao, Cheng Zhang, Pedro Gimenes, Jianqiao Lu, Jianyi Cheng, Yiren Zhao | 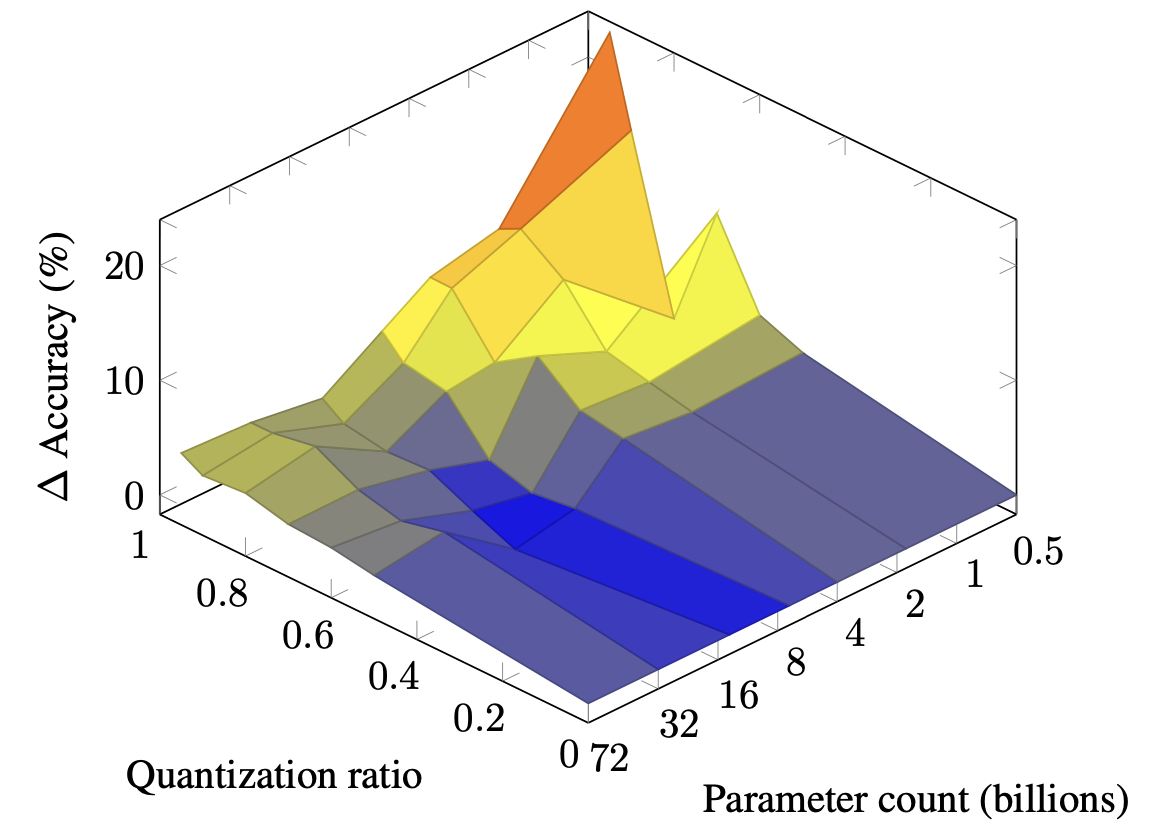 | Papel |
| Palmbench: uma referência abrangente de grandes modelos de idiomas compactados em plataformas móveis Yilong Li, Jingyu Liu, Hao Zhang, M Badri Narayanan, Utkarsh Sharma, Shuai Zhang, Pan Hu, Yijing Zeng, Jayaram Raghuram, Suman Banerjee | 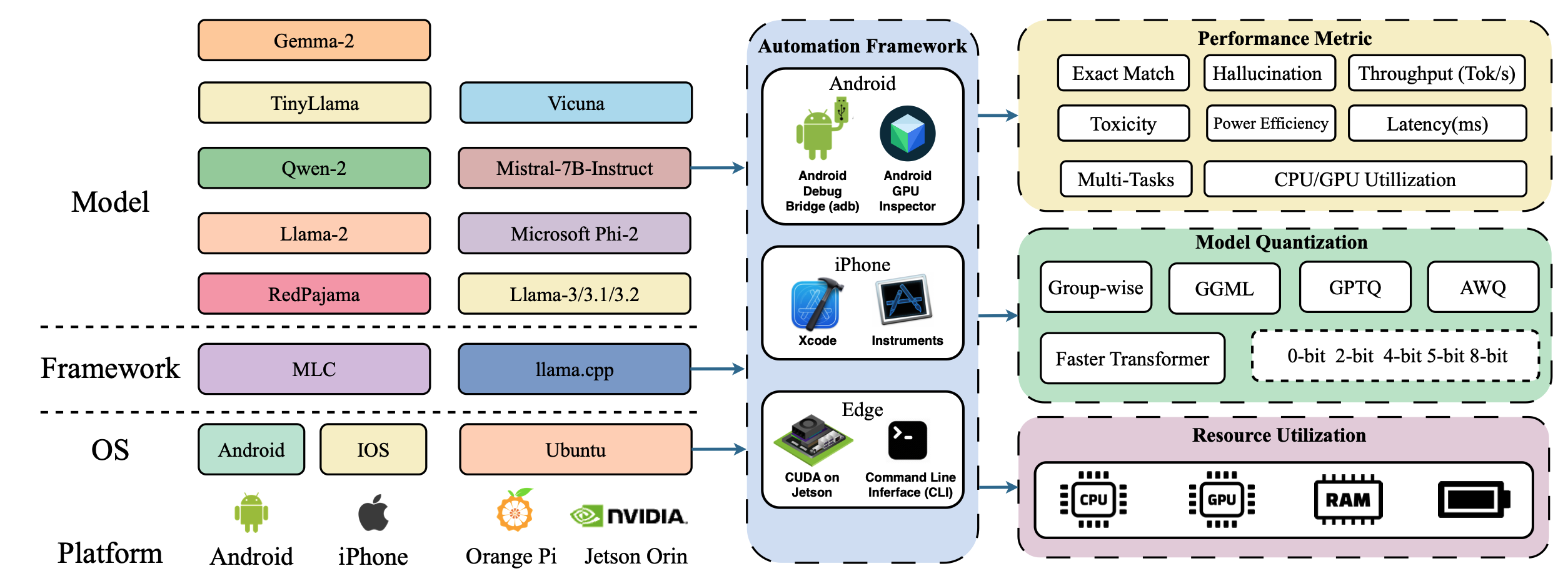 | Papel |
| Crossquant: um método de quantização pós-treinamento com núcleo de quantização menor para compressão precisa do modelo de linguagem grande de grande linguagem Wenyuan Liu, Xindian MA, Peng Zhang, Yan Wang | Papel | |
| SAGATTENÇÃO: atenção precisa de 8 bits para aceleração de inferência plug-and-play Jintao Zhang, Jia Wei, Pengle Zhang, Jun Zhu, Jianfei Chen | Papel | |
| Além disso, é tudo o que você precisa para modelos de linguagem com eficiência energética Hongyin Luo, Wei Sun | Papel | |
VPTQ: quantização pós-treinamento de vetor de baixo bit extremo para modelos de idiomas grandes Yifei Liu, Jicheng Wen, Yang Wang, Shengyu Ye, Li Lyna Zhang, Ting Cao, Cheng Li, Mao Yang | 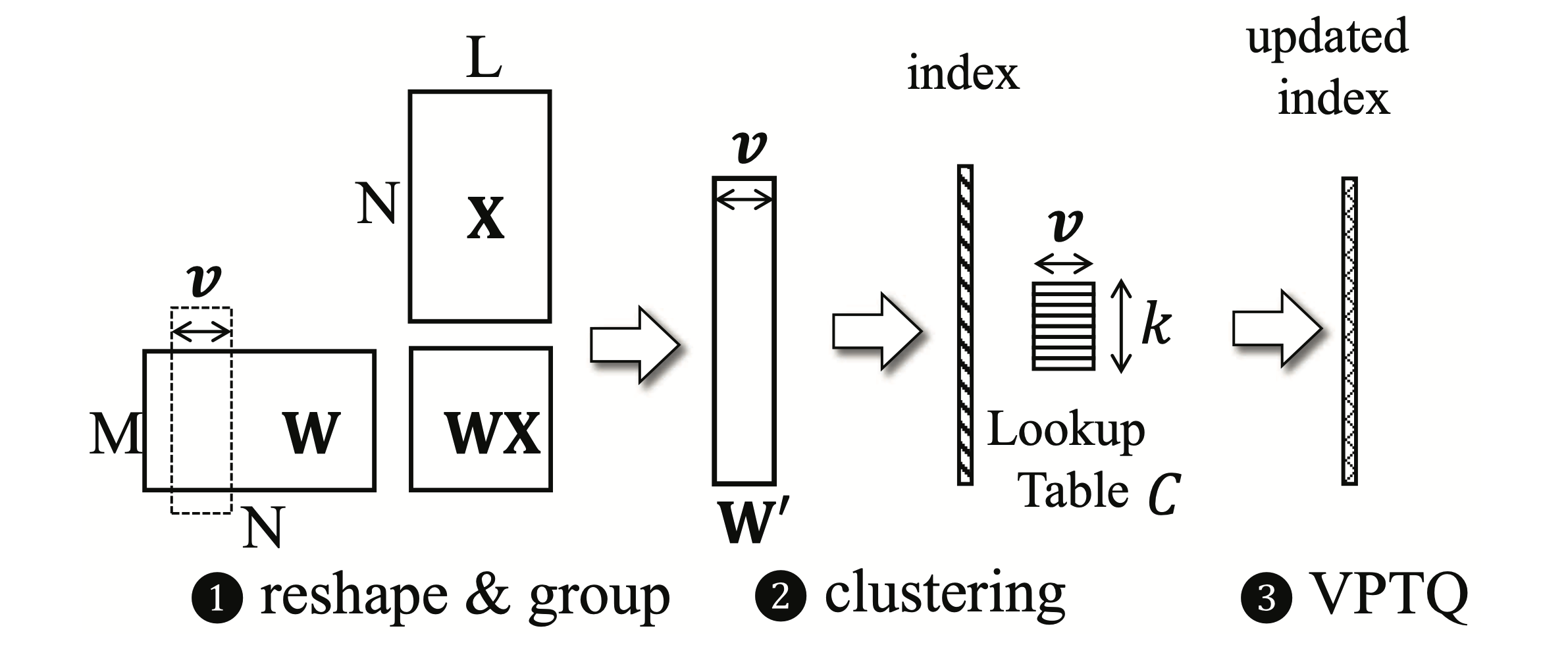 | Github Papel |
Int-Flashattion: Ativando a atenção do flash para quantização INT8 Shimao Chen, Zirui Liu, Zhiying Wu, Ce Zheng, Peizhuang Cong, Zihan Jiang, Yuhan Wu, Lei SU, Tong Yang | Github Papel | |
| Quantização pós-treinamento com reconhecimento de acumulador Ian Colbert, Fabian Grob, Giuseppe Franco, Jinjie Zhang, Rayan Saab | Papel | |
Duquant: distribuir outliers por transformação dupla torna LLMs quantizados mais fortes Haokun Lin, Haobo Xu, Yichen Wu, Jingzhi Cui, Yingtao Zhang, Linzhan Mou, Linqi Song, Zhenan Sun, Ying Wei | 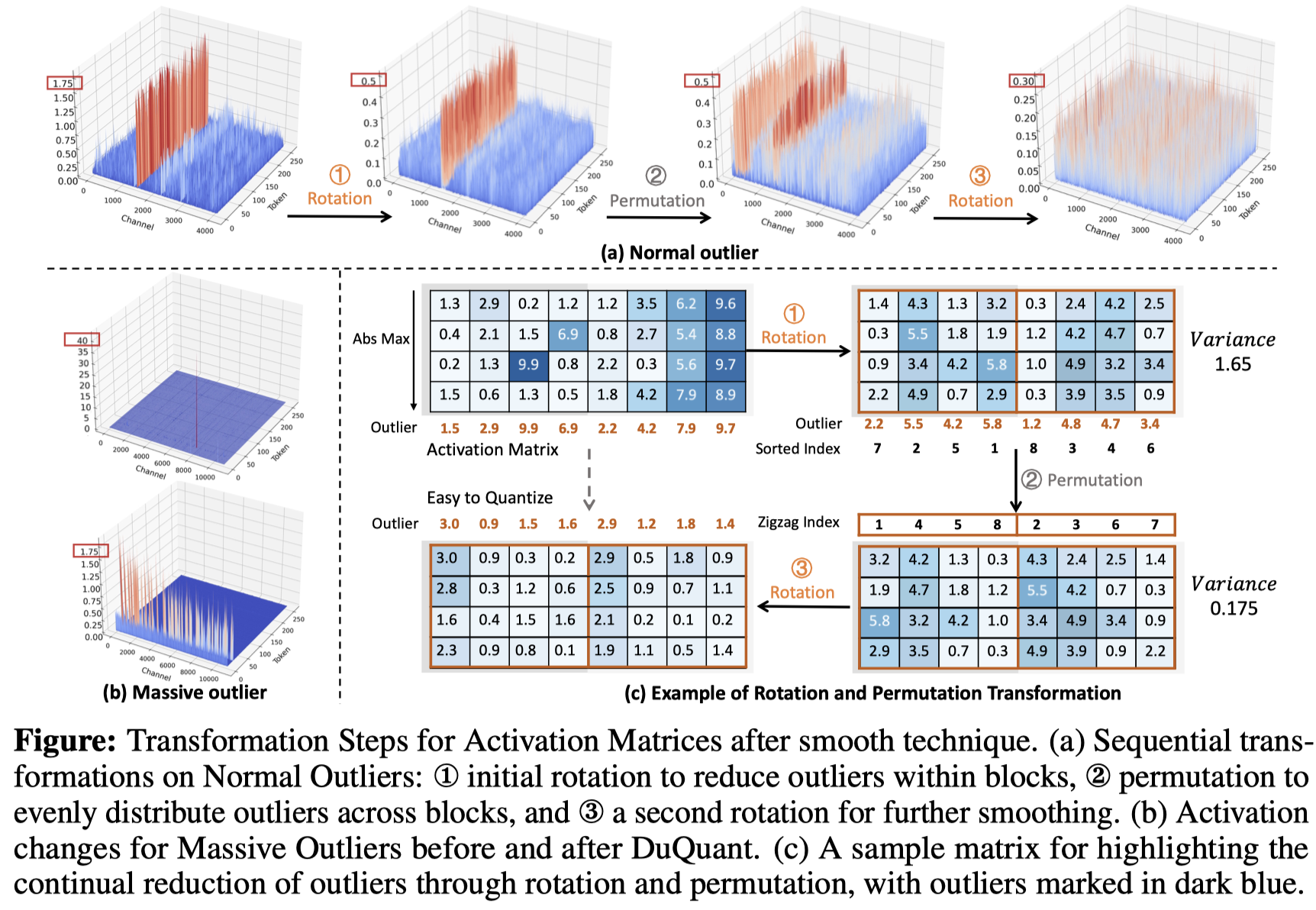 | Github Papel |
| Uma avaliação abrangente de modelos de idiomas grandes de instrução quantizados: uma análise experimental de até 405b Jemin Lee, Sihyeong Park, Jinse Kwon, Jihun Oh, Yongin Kwon | Papel | |
| A singularidade de llama3-70b com quantização por canal: um estudo empírico Minghai Qin | Papel |
| Título e autores | Introdução | Links |
|---|---|---|
DEJA VU: Sparsidade contextual para LLMs eficientes em tempo de inferência Zichang Liu, Jue Wang, Tri Dao, Tianyi Zhou, Binhang Yuan, Zhao Song, Anshumali Shrivastava, CE Zhang, Yuandong Tian, Christopher Re, Beidi Chen | 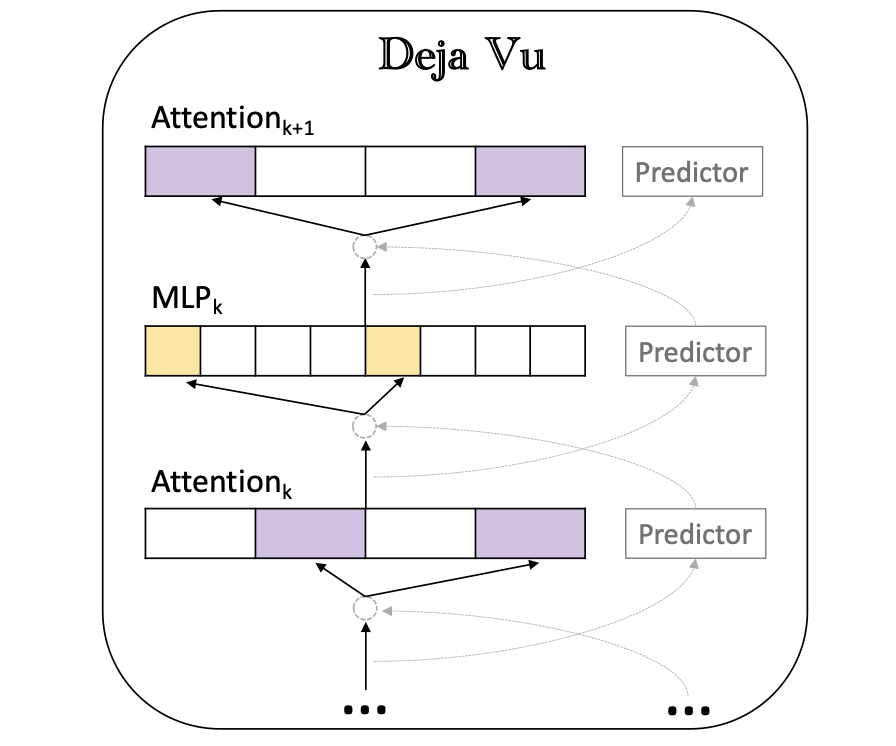 | Github Papel |
Especinfer: acelerando LLM generativo que serve com inferência especulativa e verificação de árvores de token Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Rae Ying Yee Wong, Zhuoming Chen, Daiyaan Arfeen, Reyna Abhyankar, Zhihao Jia | 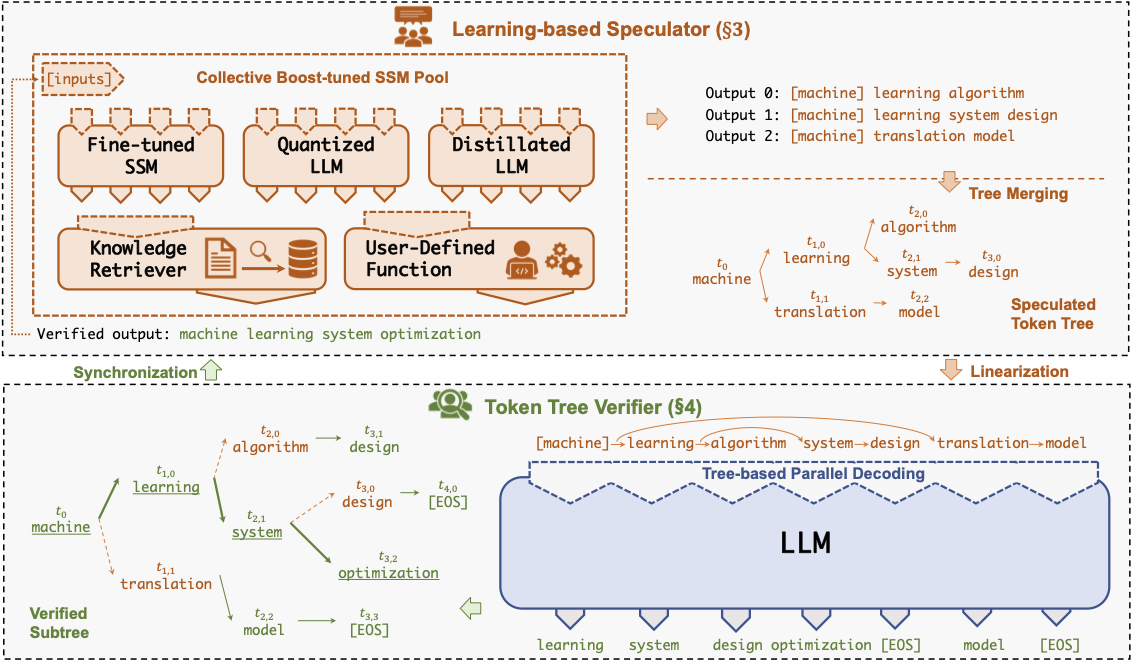 | Github papel |
Modelos de linguagem de streaming eficientes com afundamentos de atenção Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, Mike Lewis | 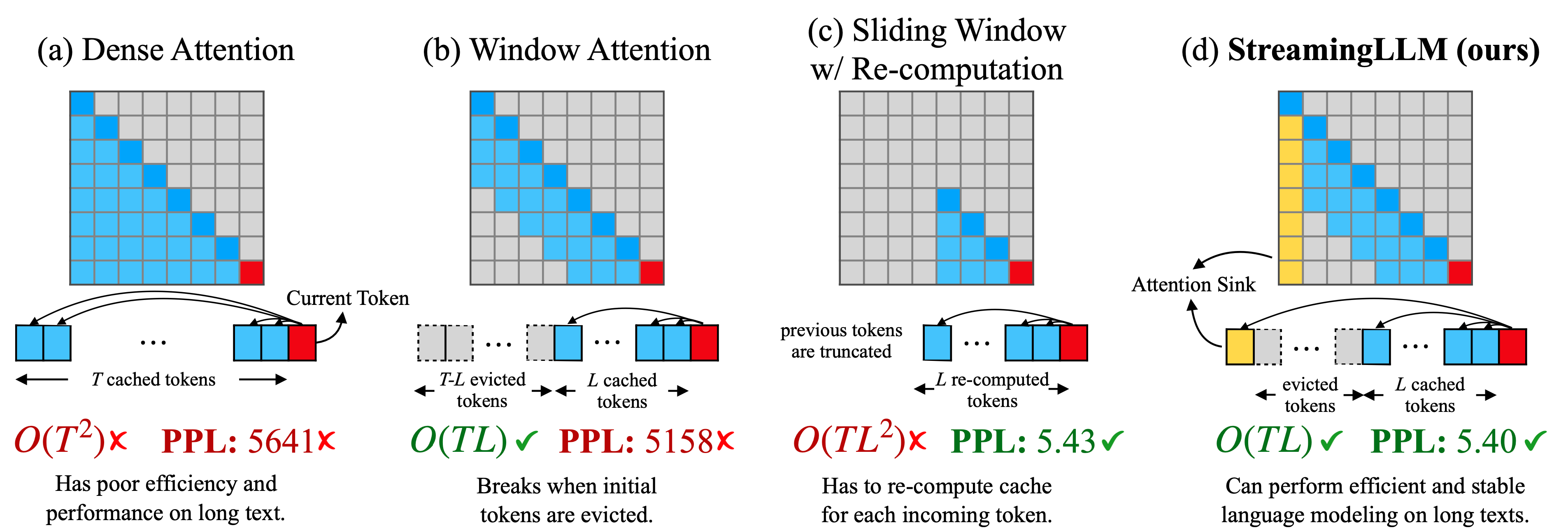 | Github Papel |
Águia: Aceleração sem perdas da decodificação de LLM por extrapolação de recursos Yuhui Li, Chao Zhang e Hongyang Zhang | 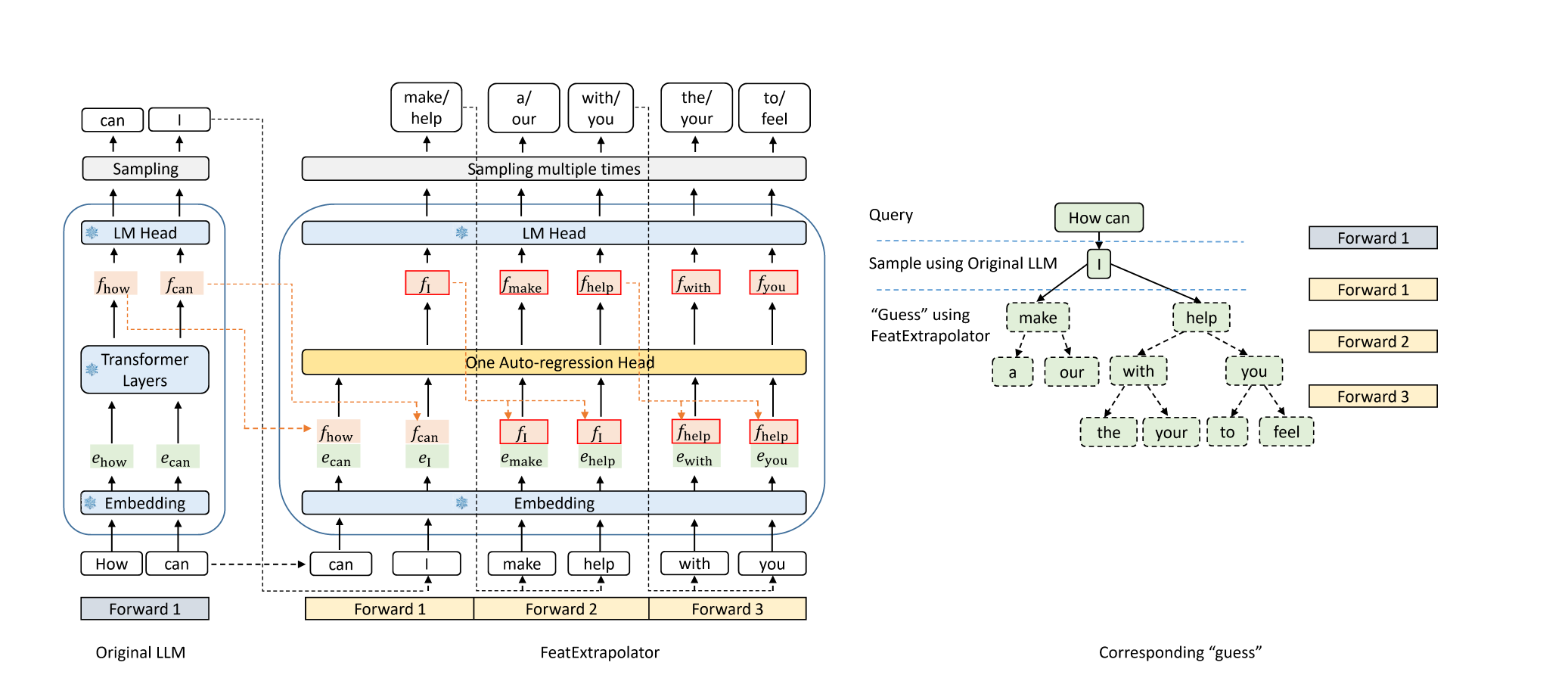 | Github Blog |
Medusa: estrutura de aceleração de inferência LLM simples com várias cabeças de decodificação Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, Tri Dao | Github Papel | |
| Decodificação especulativa com modelo de rascunho baseado em CTC para aceleração de inferência de LLM Zhuofan Wen, Shangtong GUI, Yang Feng | Papel | |
| PLD+: Acelerando a inferência LLM alavancando artefatos do modelo de linguagem Shwetha Somasundaram, Anirudh Phukan, Apoorv Saxena | Papel | |
FastDraft: como treinar seu rascunho Ofir Zafrir, Igor Margulis, Dorin Shteyman, Guy Boudoukh | Papel | |
SMOA: Melhorando modelos de idiomas grandes multi-agentes com mistura de agentes esparsas Dawei Li, Zhen Tan, Peijia Qian, Yifan Li, Kumar Satvik Chaudhary, Lijie Hu, Jiayi Shen | 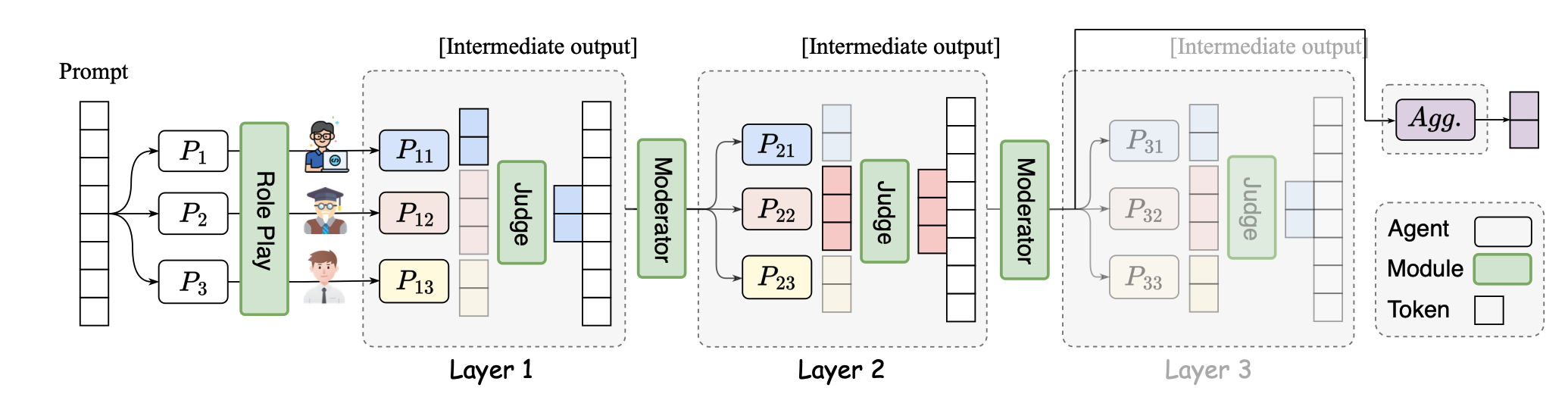 | Github Papel |
| O N-Grammys: Acelerando a inferência autoregressiva com especulações em lotes sem aprendizagem Lawrence Stewart, Matthew Trager, Sujan Kumar Gonugondla, Stefano Soatto | Papel | |
| Inferência acelerada de IA através de métodos de execução dinâmica Haim Barad, Jascha Achterberg, Tien Pei Chou, Jean Yu | Papel | |
| Sufixo Decodificação: Uma abordagem sem modelo para acelerar a grande inferência do modelo de linguagem Gabriele Oliaro, Zhihao Jia, Daniel Campos, Aurick Qiao | Papel | |
| Planejamento de estratégia dinâmica para responder a perguntas eficientes com grandes modelos de linguagem Tanmay Parekh, Pradyot Prakash, Alexander Radovic, Akshay Shekher, Denis Savenkov | Papel | |
Magicpig: amostragem LSH para geração eficiente de LLM Zhuoming Chen, Ranajoy Sadhukhan, Zihao Ye, Yang Zhou, Jianyu Zhang, Niklas Nolte, Yuandong Tian, Matthijs Douze, Leon Bottou, Zhihao Jia, Beidi Chen | Github Papel | |
| Modelos de idiomas mais rápidos com melhor previsão de vários toques usando decomposição tensor Artem Basharin, Andrei Chertkov, Ivan Oseledets |  | Papel |
| Inferência eficiente para grandes modelos de linguagem aumentados Rana Shahout, Cong Liang, Shiji Xin, Qianru Lao, Yong Cui, Minlan Yu, Michael Mitzenmacher | Papel | |
Vocabulário dinâmico podando Jort Vincenti, Karim Abdel Sadek, Joan Velja, Matteo Nulli, Metod Jazbec |  | Github Papel |
CoreInfer: acelerando o grande modelo de linguagem inferência com a ativação esparsa adaptativa inspirada na semântica Qinsi Wang, Saeed Vahidian, Hancheng Ye, Jianyang Gu, Jianyi Zhang, Yiran Chen | Github Papel | |
DUOATTENÇÃO: Inferência eficiente de longo contexto LLM com recuperação e cabeças de streaming Guangxuan Xiao, Jiaming Tang, Jingwei Zuo, Junxian Guo, Shang Yang, Haotian Tang, Yao Fu, Song Han | 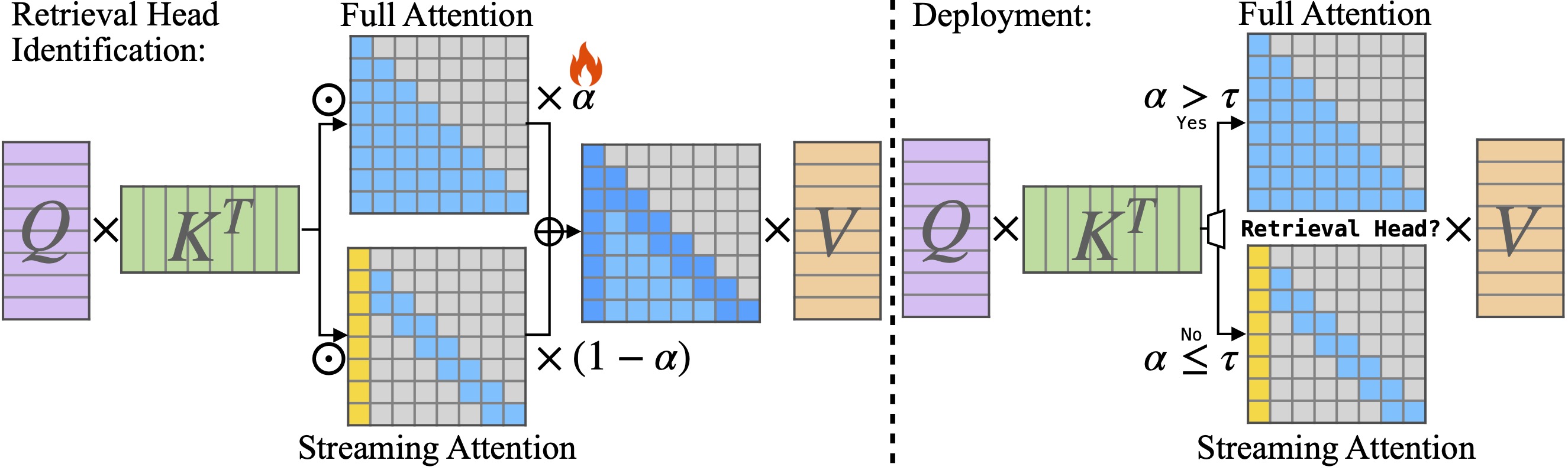 | Github Papel |
| Dyspec: decodificação especulativa mais rápida com estrutura de árvore de token dinâmica Yunfan Xiong, Ruoyu Zhang, Yanzeng Li, Tianhao Wu, Lei Zou | Papel | |
| QSpec: decodificação especulativa com esquemas de quantização complementares Juntao Zhao, Wenhao Lu, Sheng Wang, Lingpeng Kong, Chuan Wu | Papel | |
| TidalDecode: Decodificação rápida e precisa do LLM com a posição de posição persistente e escassa Lijie Yang, Zhihao Zhang, Zhuofu Chen, Zikun Li, Zhihao Jia | Papel | |
| Parallelspec: Redador paralelo para decodificação especulativa eficiente Zilin Xiao, Hongming Zhang, Tao Ge, Siru Ouyang, Vicente Ordonez, Dong Yu | Papel | |
Swift: Decodificação auto-especulativa em voar para aceleração de inferência de LLM Heming Xia, Yongqi Li, Jun Zhang, Cunxiao DU, Wenjie Li |  | Github Papel |
Turborag: geração acelerada de recuperação de recuperação com caches KV pré-computados para texto em chunked Songshuo Lu, Hua Wang, Yutian Rong, Zhi Chen, Yaohua Tang | 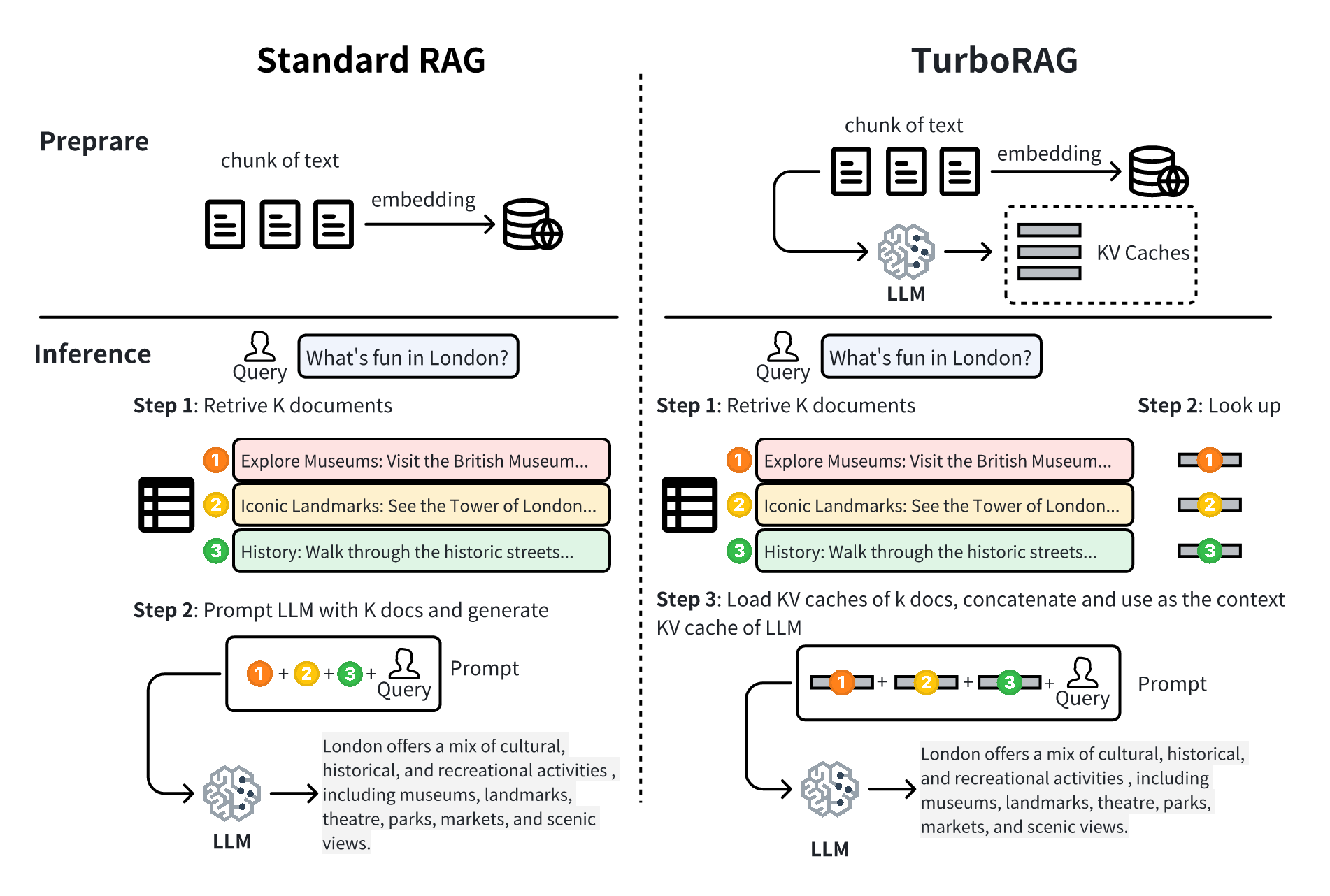 | Github Papel |
| Um pouco percorre um longo caminho: treinamento eficiente de contexto longo e inferência com contextos parciais Suyu Ge, Xihui Lin, Yunan Zhang, Jiawei Han, Hao Peng | Papel | |
| Mnemosyne: Estratégias de paralelização para servir com eficiência a solicitações de inferência de comprimento de contexto de vários milhões de dólares sem aproximações Amey Agrawal, Junda Chen, Íñigo Goiri, Ramachandran Ramjee, Chaojie Zhang, Alexey Tumanov, Esha Choukse | Papel | |
Descobrindo as jóias em camadas iniciais: acelerando LLMs de longo contexto com redução de token de entrada 1000X Zhenmei Shi, Yifei Ming, Xuan-Phi Nguyen, Yingyu Liang, Shafiq Joty | Github Papel | |
| Decodificação de feixe especulativo de largura dinâmica para inferência eficiente de LLM Zongyue Qin, Zifan He, Neha Prakriya, Jason Cong, Yizhou Sun | Papel | |
CritiPrefil: Uma abordagem baseada em criticidade em segmento para a aceleração de pré-encerramento no LLMS Junlin LV, Yuan Feng, Xike Xie, Xin Jia, Qirong Peng, Guiming Xie | Github Papel | |
| Recuperação: acelerando a inferência de longo contexto LLM via recuperação de vetores Di Liu, Meng Chen, Baotong Lu, Huiqiang Jiang, Zhenhua Han, Qianxi Zhang, Qi Chen, Chengruidong Zhang, Bailu Ding, Kai Zhang, Chen Chen, Fan Yang, Yuqing Yang, Lili Qiu | Papel | |
Sirius: Sparsidade contextual com correção para LLMs eficientes Yang Zhou, Zhuoming Chen, Zhaozhuo Xu, Victoria Lin, Beidi Chen | Github Papel | |
OneGen: geração unificada e eficiente de uma passagem e recuperação para LLMS Jintian Zhang, Cheng Peng, Mengshu Sun, Xiang Chen, Lei Liang, Zhiqiang Zhang, Jun Zhou, Huajun Chen, Ningyu Zhang | 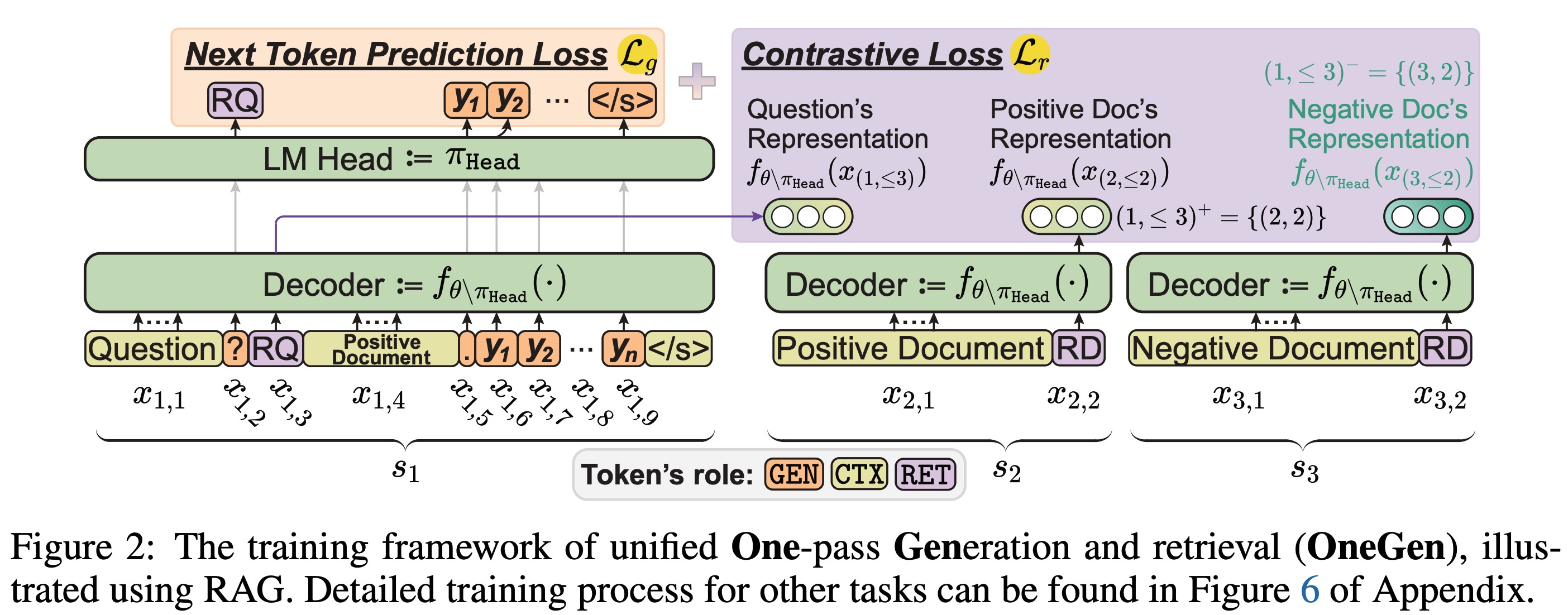 | Github Papel |
| Consistência de caminho: aprimoramento do prefixo para inferência eficiente no LLM Jiace Zhu, Yingtao Shen, Jie Zhao, um Zou | Papel | |
| Aumentar a decodificação especulativa sem perda por meio de amostragem de recursos e destilação de alinhamento parcial Lujun Gui, Bin Xiao, Lei Su, Weipeng Chen | Papel |
| Título e autores | Introdução | Links |
|---|---|---|
Inferência rápida dos modelos de linguagem da mistura de especialistas com descarga Artyom Eliseev, Denis Mazur |  | Github Papel |
Condense, não apenas poda: melhorar a eficiência e o desempenho na poda da camada MOE Mingyu Cao, Gen Li, Jie Ji, Jiaqi Zhang, Xiaolong MA, Shiwei Liu, Lu Yin | Github Papel | |
| Mistura de especialistas condicionais de cache para inferência eficiente do dispositivo móvel Andrii Skliar, Ties Van Rozendaal, Romain Lepert, Todor Boinovski, Mart Van Baalen, Markus Nagel, Paul Whatmough, Babak Ehteshami Bejnordi | Papel | |
Monta: Acelerando o treinamento da mistura de especialistas com a otimização paralela com consciência de rede de tráfego de rede Jingming Guo, Yan Liu, Yu Meng, Zhiwei Tao, Banglan Liu, Gang Chen, Xiang Li | Github Papel | |
MOE-I2: Compressionando a mistura de modelos de especialistas por meio de poda inter-expert e decomposição intra-expert de baixa rank Cheng Yang, Yang Sui, Jinqi Xiao, Lingyi Huang, Yu Gong, Yuanlin Duan, Wenqi Jia, Miao Yin, Yu Cheng, Bo Yuan | Github Papel | |
| Hobbit: um sistema de descarga de especialista em precisão mista para inferência Fast Moe Peng Tang, Jiacheng Liu, Xiaofeng Hou, Yifei PU, Jing Wang, Pheng-Ann Heng, Chao Li, Minyi Guo | Papel | |
| Promoagem: LLM baseada em MOE rápida portada usando cache proativo Xiaoniu Song, Zihang Zhong, Rong Chen | Papel | |
| Fluxo de Expert: ativação otimizada de especialistas e alocação de token para inferência eficiente da mistura de especialistas Xin ele, Shunkang Zhang, Yuxin Wang, Haiyan Yin, Zihao Zeng, Shaohuai Shi, Zhenheng Tang, Xiaowen Chu, Ivor Tsang, Ong Yew Soon | Papel | |
| EPS-MOE: Agendador de oleoduto especializado para inferência de MOE econômica Yulei Qian, Fengcun Li, Xiangyang JI, Xiaoyu Zhao, Jianchao Tan, Kefeng Zhang, Xunliang Cai | Papel | |
MC-MOE: Compressor de mistura para a mistura de experts LLMS ganha mais Wei Huang, Yue Liao, Jianhui Liu, Ruifei He, Haoru Tan, Shiming Zhang, Hongsheng Li, Si Liu, Xiaojuan Qi |  | Github Papel |
| Título e autores | Introdução | Links |
|---|---|---|
MOBILLAMA: Rumo ao GPT totalmente transparente preciso e leve Omkar Thawakar, Ashmal Vayani, Salman Khan, Hisham Cholakal, Rao M. Anwer, Michael Felsberg, Tim Baldwin, Eric P. Xing, Fahad Shahbaz Khan |  | Github Papel Modelo |
Megalodon: Eficiente LLM Pré -treinamento e inferência com comprimento de contexto ilimitado Xuezhe Ma, Xiaomeng Yang, Wenhan Xiong, Beidi Chen, Lili Yu, Hao Zhang, Jonathan May, Luke Zettlemoyer, Omer Levy, Chunting Zhou | 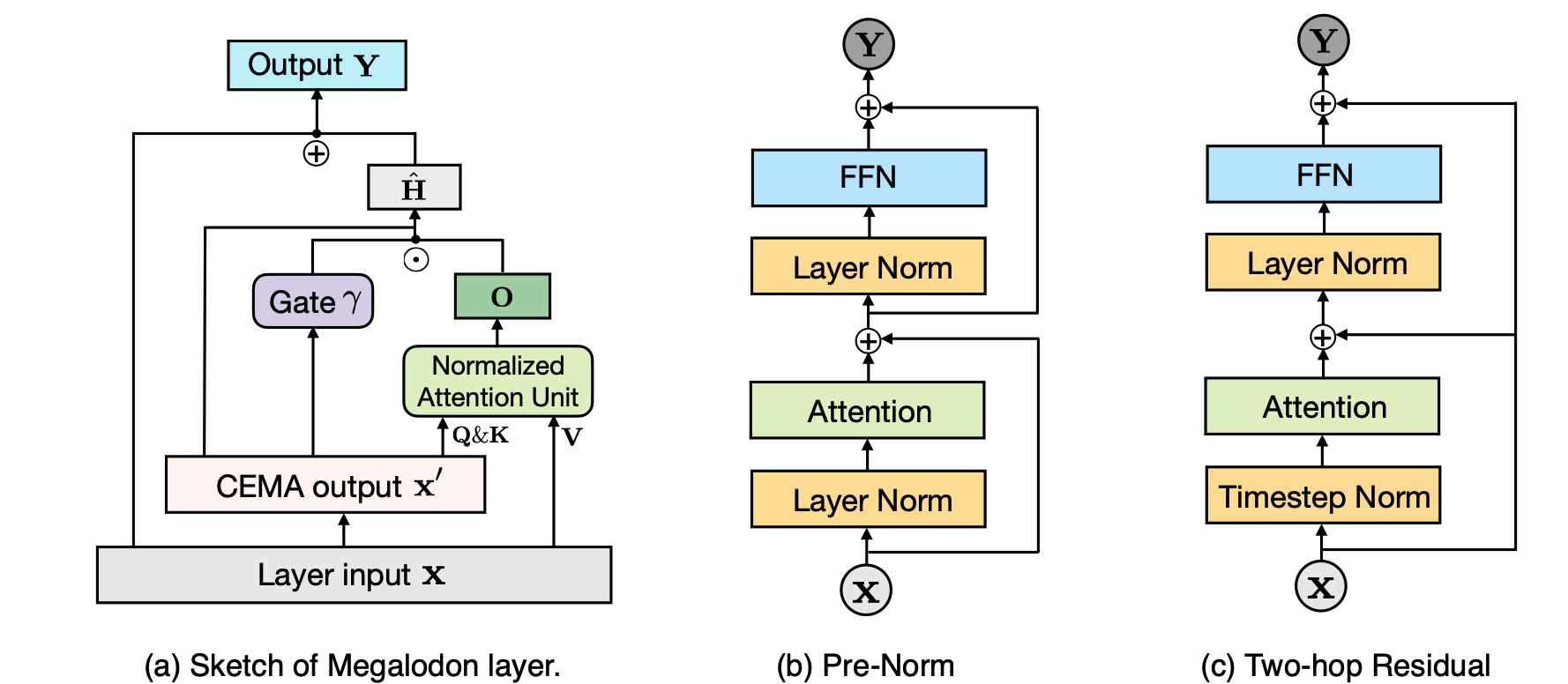 | Github Papel |
| Taipan: modelos de linguagem espacial de estado eficiente e expressivos com atenção seletiva Chien Van Nguyen, Huy Huu Nguyen, Thang M. Pham, Ruiyi Zhang, Hanieh Deilamsalehy, Puneet Mathur, Ryan A. Rossi, Trung Bui, Viet Dac Lai, Franck Dernoncourt, Thien Huuu Nguyen, | Papel | |
Seerattion: Aprendendo atenção esparsa intrínseca em seu LLMS Yizhao Gao, Zhichen Zeng, Dayou Du, Shijie Cao, Hayden Kwok-Hay So, Ting Cao, Fan Yang, Mao Yang | Github Papel | |
Compartilhamento de base: compartilhamento de parâmetros de camada cruzada para grande compactação de modelos de idiomas Jingcun Wang, Yu-Guang Chen, Ing-Chao Lin, Bing Li, Grace Li Zhang | Github Papel | |
| Rodimus*: quebrando a compensação de precisão-eficiência com atenções eficientes Zhihao ele, Hang Yu, Zi Gong, Shizhan Liu, Jianguo Li, Weiyao Lin | Papel |
| Título e autores | Introdução | Links |
|---|---|---|
| Model diz o que descartar: compactação de cache de kv adaptável para LLMS Suyu Ge, Yunan Zhang, Liyuan Liu, Minjia Zhang, Jiawei Han, Jianfeng Gao | 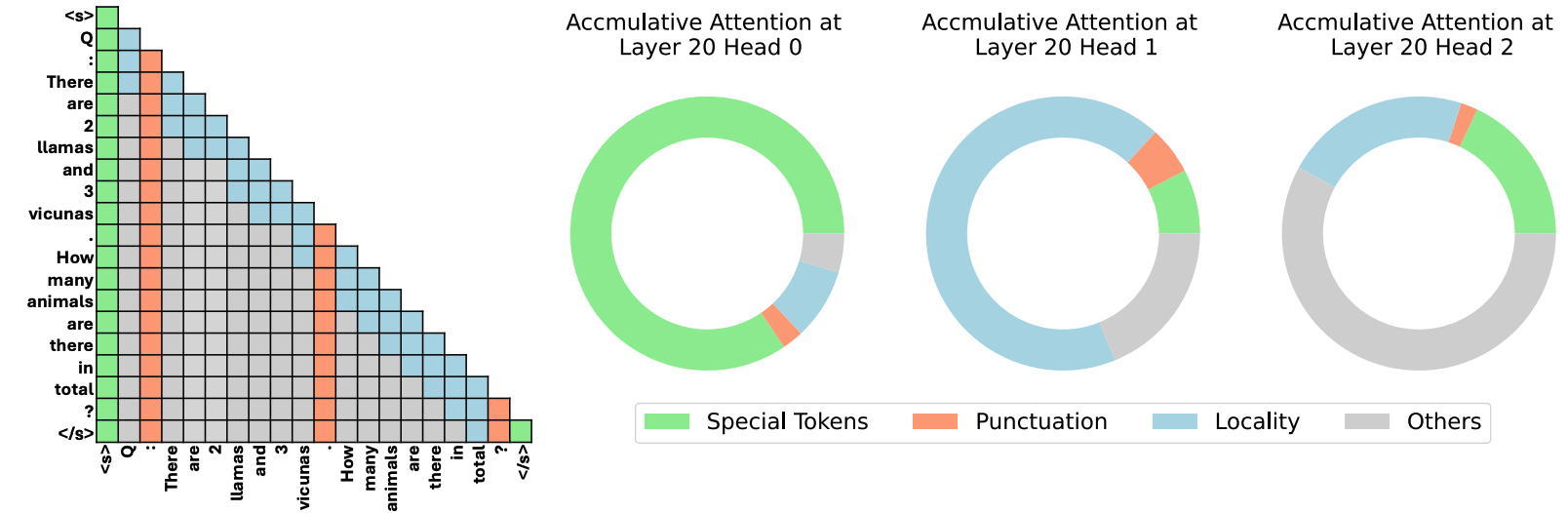 | Papel |
| ClusterKV: Manipulando o cache KV LLM em espaço semântico para compressão recallável Guangda Liu, Chengwei Li, Jieru Zhao, Chenqi Zhang, Minyi Guo | Papel | |
| Unificar compactação de cache KV para grandes modelos de linguagem com Leankv Yanqi Zhang, Yuwei Hu, Runyuan Zhao, John CS Lui, Haibo Chen | Papel | |
| Comprimindo o cache KV para inferência de longa data LLM com similaridade de atenção entre camadas Da Ma, Lu Chen, Situo Zhang, Yuxun Miao, Su Zhu, Zhi Chen, Hongshen Xu, Hanqi Li, fã Shuai, Lei Pan, Kai Yu Yu | Papel | |
| Minikv: empurrando os limites da inferência de LLM por meio de cache KV discriminativo em camada de 2 bits Akshat Sharma, Hangliang Ding, Jianping Li, Neel Dani, Minjia Zhang | Papel | |
| Tokenselect: inferência eficiente de longa inferência e extrapolação de comprimento para LLMs por meio de seleção de cache de KV no nível de token dinâmico Wei Wu, Zhuoshi Pan, Chao Wang, Liyi Chen, Yunchu Bai, Kun Fu, Zheng Wang, Hui Xiong | Papel | |
Nem todas as cabeças são importantes: um método de compactação de cache KV de nível de cabeça com recuperação integrada e raciocínio Yu Fu, Zefan Cai, Abedelkadir Asi, Wayne Xiong, Yue Dong, Wen Xiao | 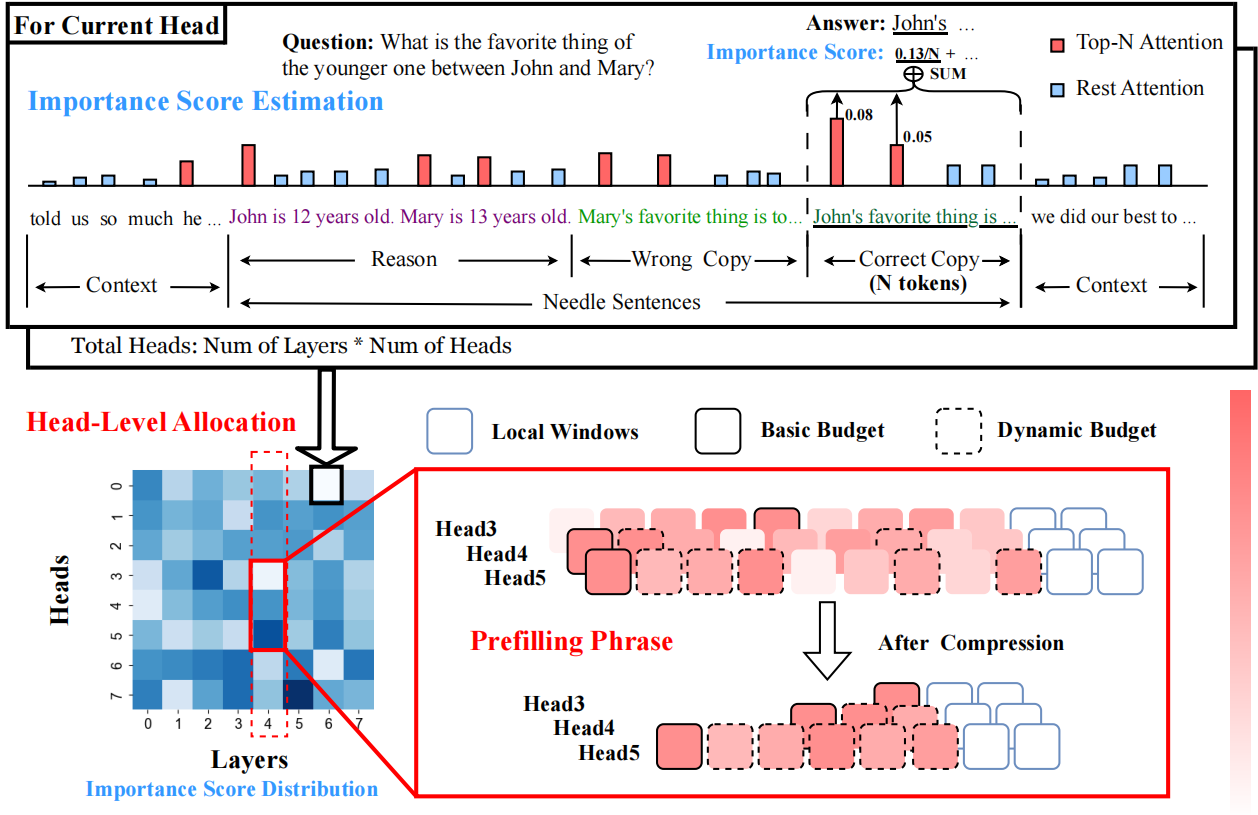 | Github Papel |
Buzz: Cache esparso de KV esparso de colméia com rebatedores pesados segmentados para inferência eficiente de LLM Junqi Zhao, Zhijin Fang, Shu Li, Shaohui Yang, Shichao Ele | Github Papel | |
Um estudo sistemático de compartilhamento de KV de camadas cruzadas para inferência eficiente de LLM Você wu, haoyi wu, kewei tu | 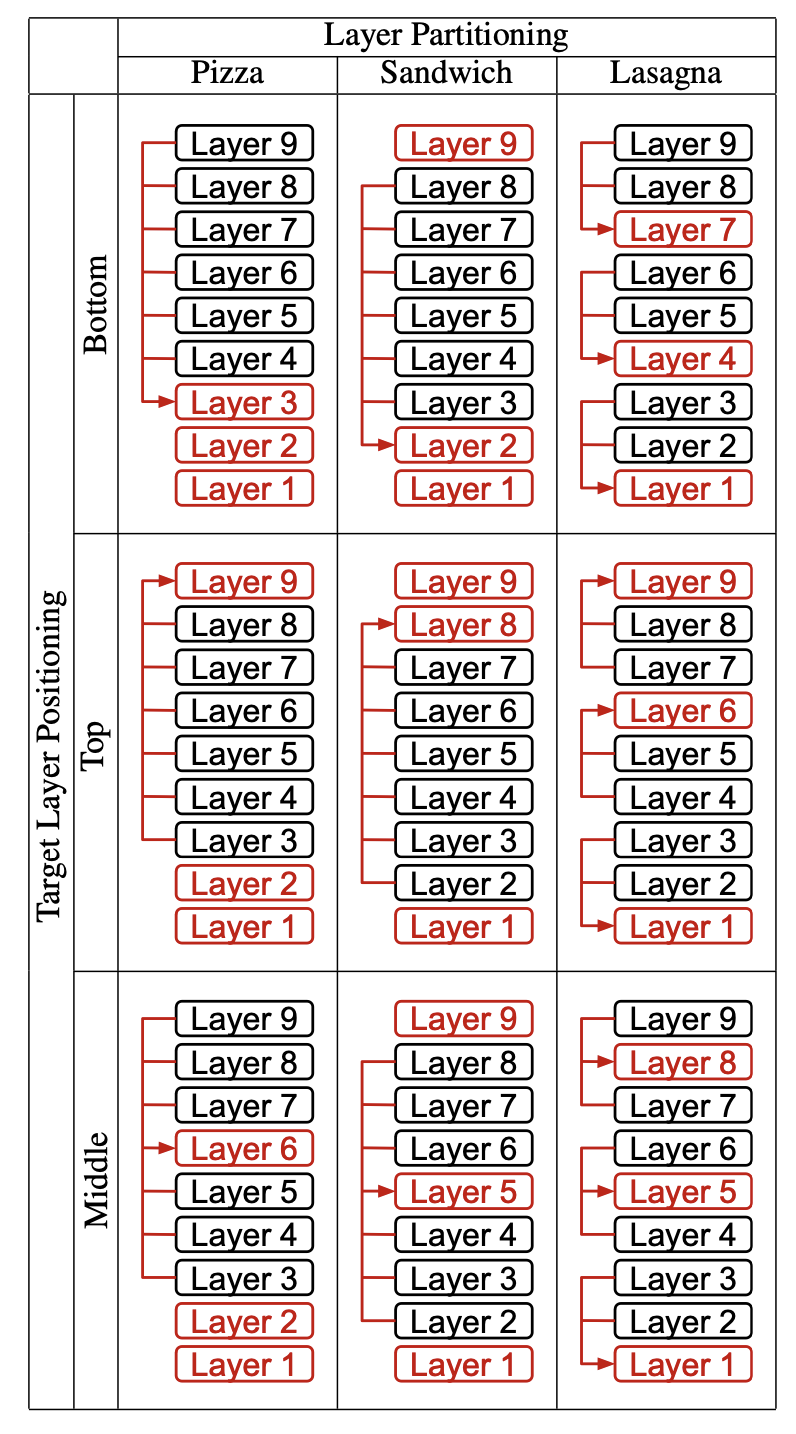 | Github Papel |
| Compressão de cache KV sem perdas para 2% Zhen Yang, Jnhan, Kan Wu, Ruobing Xie, um Wang, Xingwu Sun, Zhanhui Kang | Papel | |
| Matryoshkakv: compressão KV adaptável via projeção ortogonal treinável Bokai Lin, Zihao Zeng, Zipeng Xiao, Siqi Kou, Tianqi Hou, Xiaofeng Gao, Hao Zhang, Zhijie Deng | Papel | |
Quantização de vetores residuais para compactação de cache KV em um modelo de linguagem grande Ankur Kumar | Github Papel | |
Kvsharer: inferência eficiente por meio de compartilhamento de cache de KV diferente de camada Yifei Yang, Zouying Cao, Qiguang Chen, Libo Qin, Dongjie Yang, Hai Zhao, Zhi Chen | 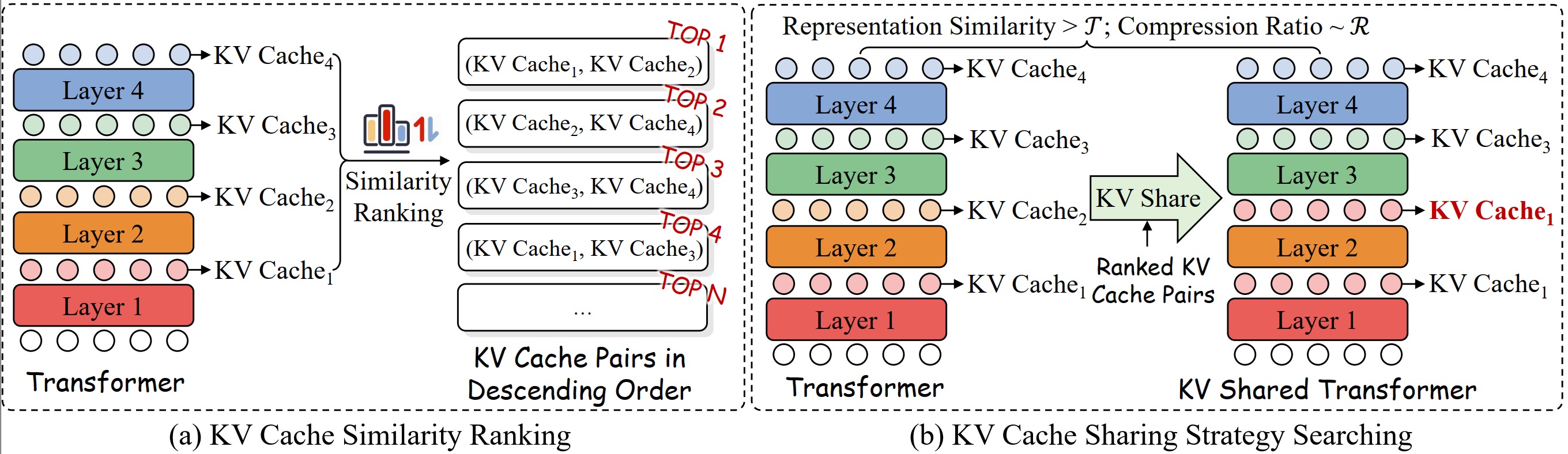 | Github Papel |
| LORC: Compressão de baixo rank para o cache LLMS KV com uma estratégia de compressão progressiva Rongzhi Zhang, Kuang Wang, Liyuan Liu, Shuohang Wang, Hao Cheng, Chao Zhang, Yelong Shen | 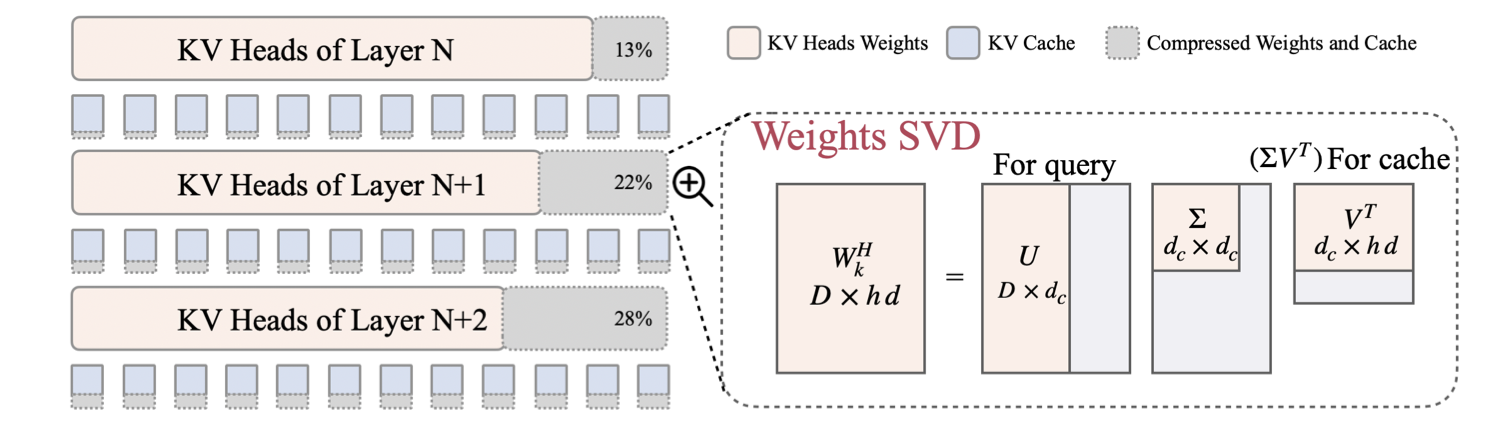 | Papel |
| Swiftkv: Inferência rápida otimizada de pré-encerramento na transformação do modelo que preserva o conhecimento Aurick Qiao, Zhewei Yao, Samyam Rajbhandari, Yuxiong Ele | Papel | |
Compressão de memória dinâmica: LLMs de retrofitamento para inferência acelerada Piotr Nawrot, Adrian łańcucki, Marcin ChoChowski, David Tarjan, Edoardo M. Ponti | 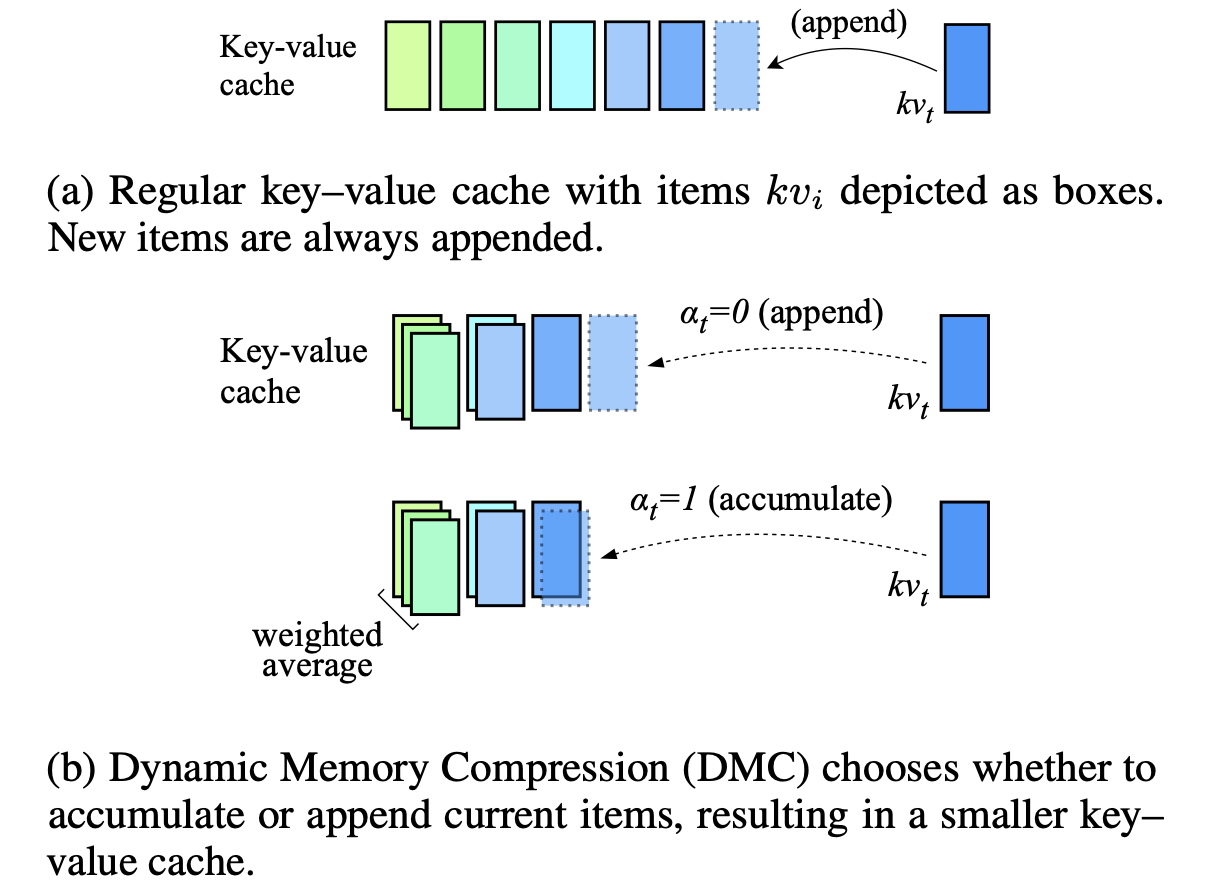 | Papel |
| KV-COMPRESS: compactação de cache kv paginada com taxas de compressão variáveis por cabeça de atenção Isaac Rehg | Papel | |
ADA-KV: otimizando o despejo de cache do KV por alocação de orçamento adaptável para inferência eficiente de LLM Yuan Feng, Junlin LV, Yukun Cao, Xike Xie, S. Kevin Zhou | 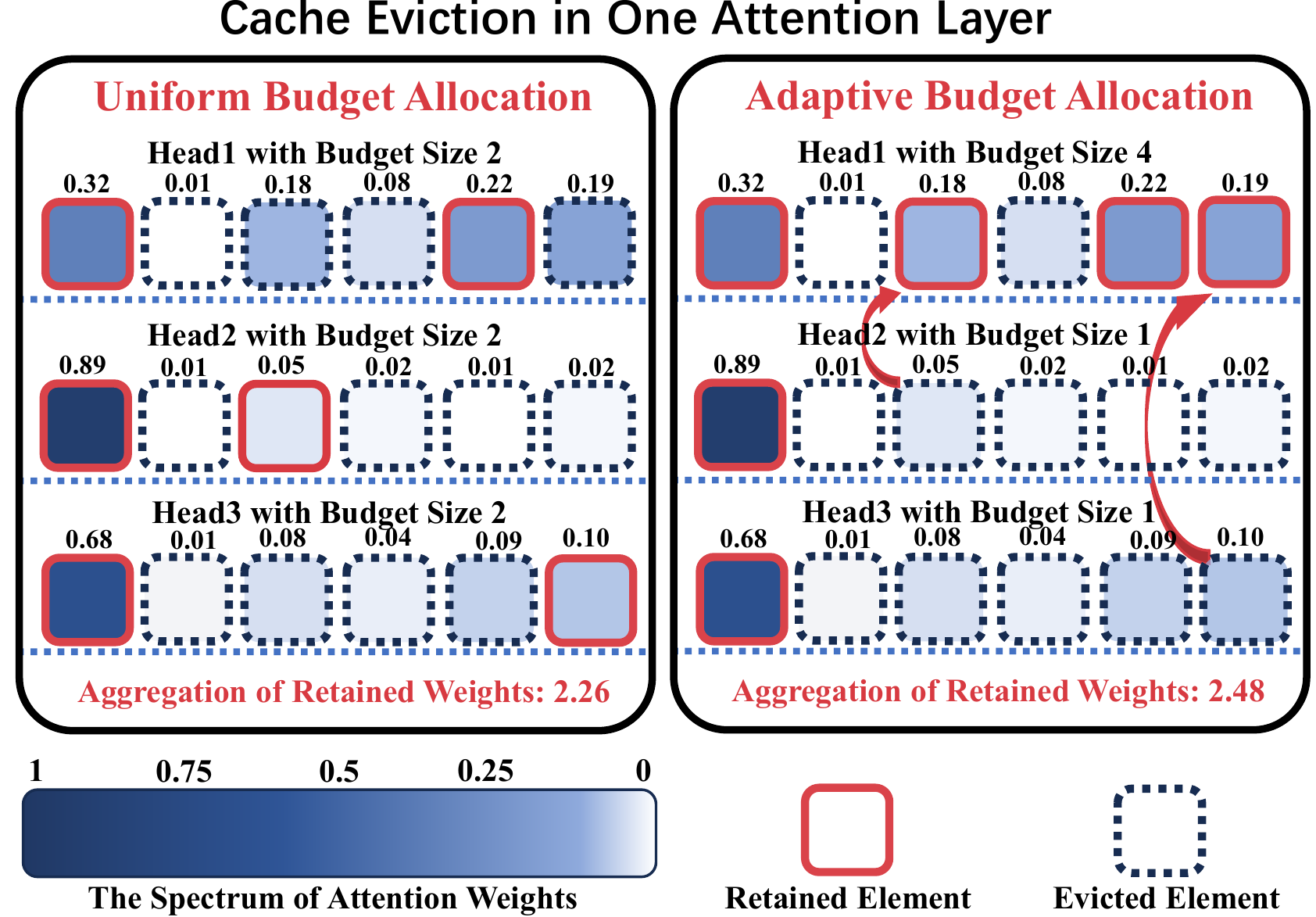 | Github Papel |
Alinhado: reduzindo o acesso à memória do cache kv com quantização alinhada por precisão Yifan Tan, Haoze Wang, Chao Yan, Yangdong Deng | Github Papel | |
| CSKV: canal com eficiência de treinamento encolhendo para cache KV em cenários de longo contexto Luning Wang, Shiyao Li, Xuefei Ning, Zhihang Yuan, Shengen Yan, Guohao Dai, Yu Wang | Papel | |
| Uma primeira olhada na inferência eficiente e segura do Device LLM contra o vazamento de KV Huan Yang, Deyu Zhang, Yudong Zhao, Yuanchun Li, Yunxin Liu | Papel |
| Título e autores | Introdução | Links |
|---|---|---|
Llmlingua: comprimindo instruções para inferência acelerada de grandes modelos de linguagem Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, Lili Qiu | 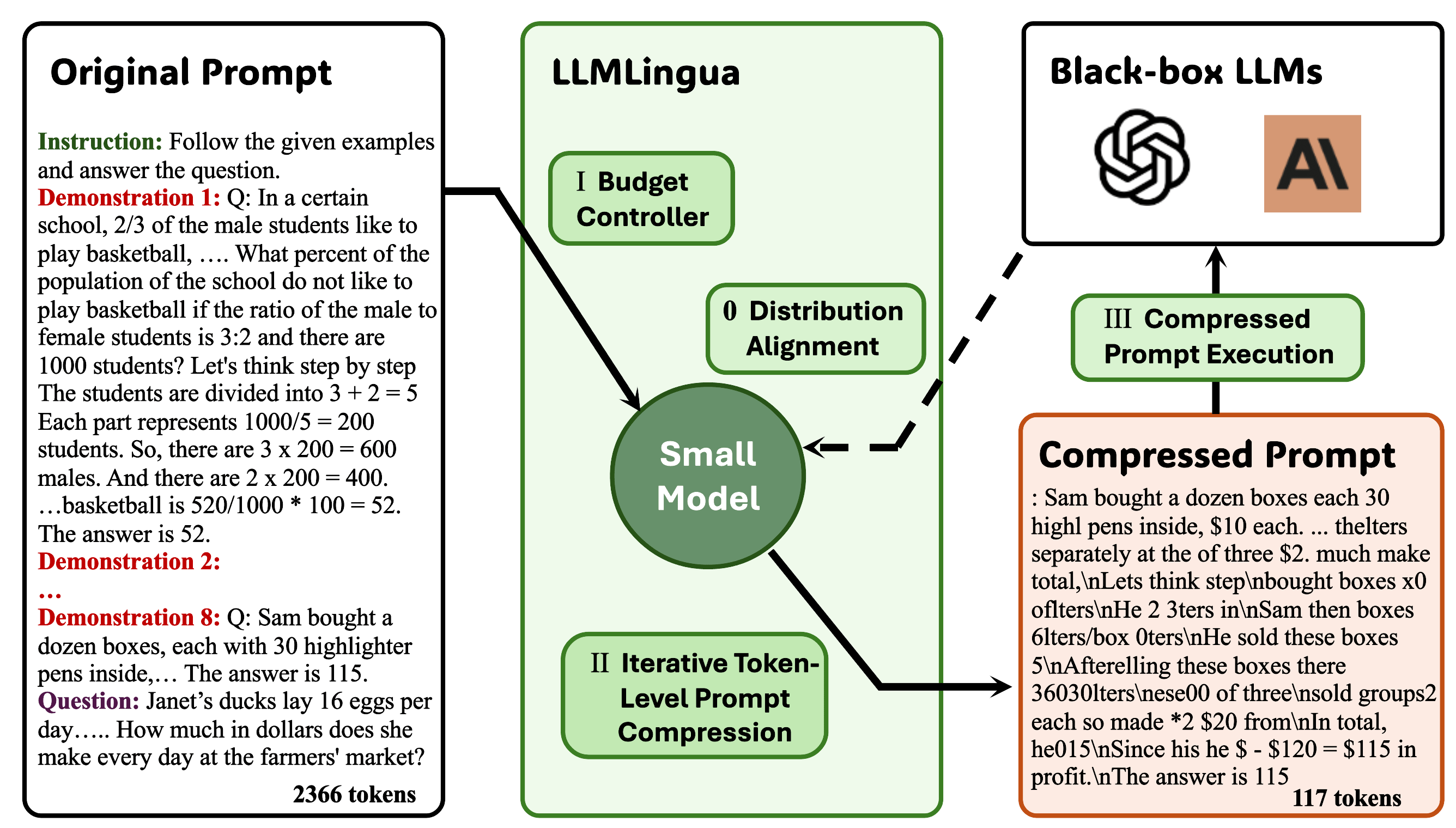 | Github Papel |
Longllmlingua: acelerando e aprimorando LLMs em cenários de contexto de longo prazo por meio de compactação imediata Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, Lili Qiu | 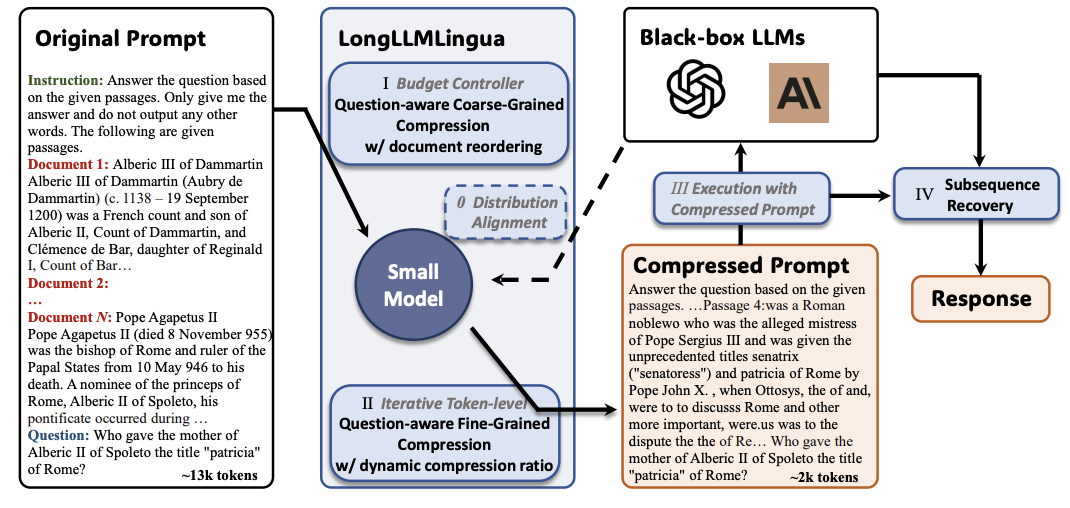 | Github Papel |
| JPO: Poder conjunta e otimização imediata para grandes serviços de modelo de linguagem acelerada Feiran você, Hongyang du, Kaibin Huang, Abbas Jamalipour | Papel | |
Destilação de contexto generativo Haebin Shin, Lei JI, Yeyun Gong, Sungdong Kim, Eunbi Choi, Minjoon SEO | | Github Papel |
Multitok: tokenização de comprimento variável para LLMs eficientes adaptados da compactação LZW Noel Elias, Homa Esfahanizadeh, Kaan Kale, Sriram Vishwanath, Muriel Medard | Github Papel | |
Seleção-P: Auto-supervisão Primeira compressão agnóstica para fidelidade e transferibilidade Tsz Ting Chung, Leyang Cui, Lemao Liu, Xinting Huang, Shuming Shi, Dit-Yan Yeung | Papel | |
Da leitura à compactação: explorando o leitor de vários documentos para compactação imediata Eunseong Choi, Sunkyung Lee, Minjin Choi, June Park, Jongwuk Lee | Papel | |
| Compressor de percepção: um método de compactação imediata sem treinamento em cenários de contexto longo Jiwei Tang, Jin Xu, Tingwei Lu, Hai Lin, Yiming Zhao, Hai-Tao Zheng | Papel | |
Finezip: empurrando os limites de grandes modelos de linguagem para compressão de texto sem perdas práticas Fazal Mittu, Yihuan BU, Akshat Gupta, Ashok Devirddy, Alp Eren Ozdarendeli, Anant Singh, Gopala Anumanchipalli | Github Papel | |
Parse de árvores guiadas de compactação PROMPRADA LLM Wenhao Mao, Chengbin Hou, Tianyu Zhang, Xinyu Lin, Ke Tang, Hairong LV | Github Papel | |
Alphazip: compressão de texto sem perda de rede neural Swathi Shree Narashiman, Nitin Chandrachoodan | Github Papel | |
| Taco-RL: Tarefa de otimização de compactação imediata com aprendizado de reforço Shivam Shandilya, Menglin Xia, Supriyo Ghosh, Huiqiang Jiang, Jue Zhang, Qianhui Wu, Victor Rühle | Papel | |
| Destilação eficiente de contexto LLM Rajesh Upadhayayaya, Zachary Smith, Chritopher Kottmyer, Manish Raj Osti | Papel | |
Aprimorando e acelerando grandes modelos de linguagem por meio de compressão contextual com reconhecimento de instrução Haowen Hou, Fei MA, Binwen Bai, Xinxin Zhu, Fei Yu | Github Papel |
| Título e autores | Introdução | Links |
|---|---|---|
Galore natural: acelerando em abundância para treinamento e ajuste fino com eficiência de memória Arijit Das | Github Papel | |
| Compacto: Ativações compactadas para treinamento LLM com eficiência de memória Yara Shamshoum, Nitzan Hodos, Yuval Sieradzki, Assaf Schuster | Papel | |
Espace: Redução da dimensionalidade das ativações para compactação de modelos Charbel Sakr, Brucek Khailany | 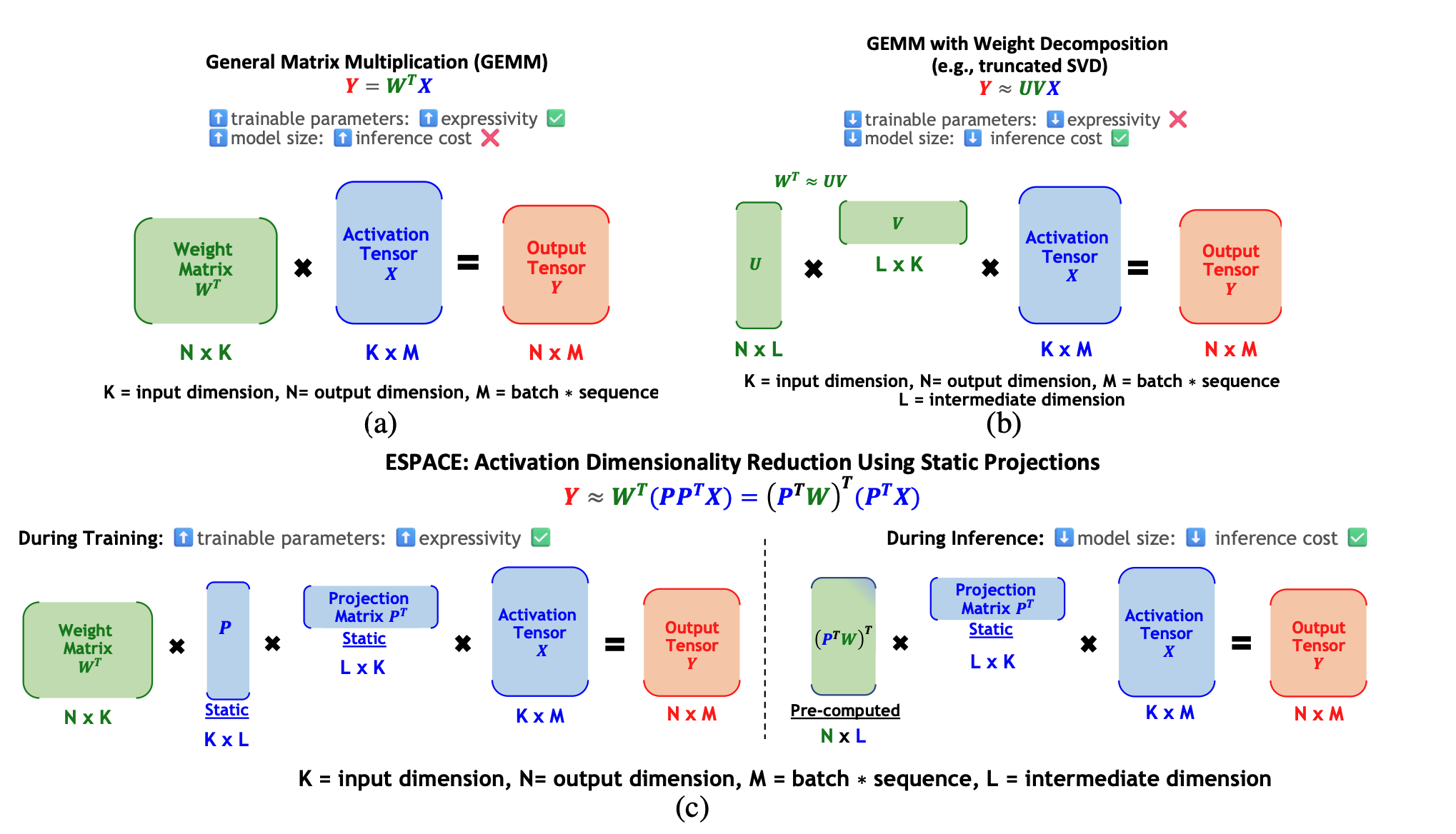 | Papel |
| Título e autores | Introdução | Links |
|---|---|---|
| FastSwitch: otimizando a eficiência de comutação de contexto em um modelo de linguagem grande e consciente de justiça Ao Shen, Zhiyao Li, Mingyu Gao | Papel | |
| CE-collm: modelos de linguagem grandes eficientes e adaptáveis por meio de colaboração na borda da nuvem Hongpeng Jin, Yanzhao WU | Papel | |
| Ripple: acelerando a inferência LLM em smartphones com gerenciamento de neurônios com consciência de correlação Tuowei Wang, Ruwen Fan, Minxing Huang, Zixu Hao, Kun Li, Ting Cao, Youyou Lu, Yaoxue Zhang, Ju Ren | Papel | |
ALISE: Accelerating Large Language Model Serving with Speculative Scheduling Youpeng Zhao, Jun Wang | Papel | |
| EPIC: Efficient Position-Independent Context Caching for Serving Large Language Models Junhao Hu, Wenrui Huang, Haoyi Wang, Weidong Wang, Tiancheng Hu, Qin Zhang, Hao Feng, Xusheng Chen, Yizhou Shan, Tao Xie | Papel | |
SDP4Bit: Toward 4-bit Communication Quantization in Sharded Data Parallelism for LLM Training Jinda Jia, Cong Xie, Hanlin Lu, Daoce Wang, Hao Feng, Chengming Zhang, Baixi Sun, Haibin Lin, Zhi Zhang, Xin Liu, Dingwen Tao | Papel | |
| FastAttention: Extend FlashAttention2 to NPUs and Low-resource GPUs Haoran Lin, Xianzhi Yu, Kang Zhao, Lu Hou, Zongyuan Zhan et al | Papel | |
| POD-Attention: Unlocking Full Prefill-Decode Overlap for Faster LLM Inference Aditya K Kamath, Ramya Prabhu, Jayashree Mohan, Simon Peter, Ramachandran Ramjee, Ashish Panwar | Papel | |
TPI-LLM: Serving 70B-scale LLMs Efficiently on Low-resource Edge Devices Zonghang Li, Wenjiao Feng, Mohsen Guizani, Hongfang Yu | Github Papel | |
Efficient Arbitrary Precision Acceleration for Large Language Models on GPU Tensor Cores Shaobo Ma, Chao Fang, Haikuo Shao, Zhongfeng Wang | Papel | |
OPAL: Outlier-Preserved Microscaling Quantization A ccelerator for Generative Large Language Models Jahyun Koo, Dahoon Park, Sangwoo Jung, Jaeha Kung | Papel | |
| Accelerating Large Language Model Training with Hybrid GPU-based Compression Lang Xu, Quentin Anthony, Qinghua Zhou, Nawras Alnaasan, Radha R. Gulhane, Aamir Shafi, Hari Subramoni, Dhabaleswar K. Panda | Papel |
| Title & Authors | Introdução | Links |
|---|---|---|
| HELENE: Hessian Layer-wise Clipping and Gradient Annealing for Accelerating Fine-tuning LLM with Zeroth-order Optimization Huaqin Zhao, Jiaxi Li, Yi Pan, Shizhe Liang, Xiaofeng Yang, Wei Liu, Xiang Li, Fei Dou, Tianming Liu, Jin Lu | Papel | |
Robust and Efficient Fine-tuning of LLMs with Bayesian Reparameterization of Low-Rank Adaptation Ayan Sengupta, Vaibhav Seth, Arinjay Pathak, Natraj Raman, Sriram Gopalakrishnan, Tanmoy Chakraborty | Github Papel | |
MiLoRA: Efficient Mixture of Low-Rank Adaptation for Large Language Models Fine-tuning Jingfan Zhang, Yi Zhao, Dan Chen, Xing Tian, Huanran Zheng, Wei Zhu | Papel | |
RoCoFT: Efficient Finetuning of Large Language Models with Row-Column Updates Md Kowsher, Tara Esmaeilbeig, Chun-Nam Yu, Mojtaba Soltanalian, Niloofar Yousefi | 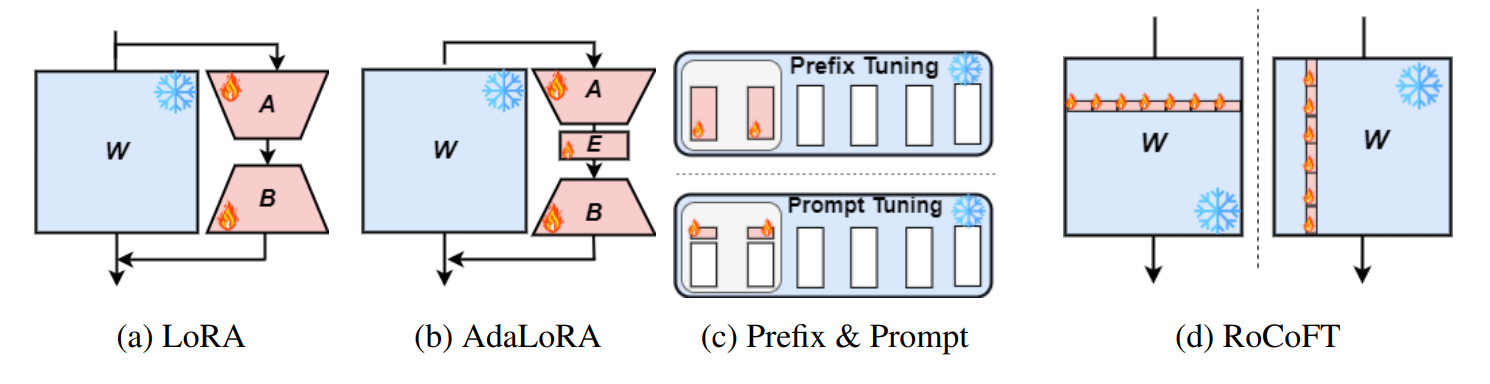 | Github Papel |
Layer-wise Importance Matters: Less Memory for Better Performance in Parameter-efficient Fine-tuning of Large Language Models Kai Yao, Penlei Gao, Lichun Li, Yuan Zhao, Xiaofeng Wang, Wei Wang, Jianke Zhu | Github Papel | |
Parameter-Efficient Fine-Tuning of Large Language Models using Semantic Knowledge Tuning Nusrat Jahan Prottasha, Asif Mahmud, Md. Shohanur Islam Sobuj, Prakash Bhat, Md Kowsher, Niloofar Yousefi, Ozlem Ozmen Garibay | Papel | |
QEFT: Quantization for Efficient Fine-Tuning of LLMs Changhun Lee, Jun-gyu Jin, Younghyun Cho, Eunhyeok Park | Github Papel | |
BIPEFT: Budget-Guided Iterative Search for Parameter Efficient Fine-Tuning of Large Pretrained Language Models Aofei Chang, Jiaqi Wang, Han Liu, Parminder Bhatia, Cao Xiao, Ting Wang, Fenglong Ma | Github Papel | |
SparseGrad: A Selective Method for Efficient Fine-tuning of MLP Layers Viktoriia Chekalina, Anna Rudenko, Gleb Mezentsev, Alexander Mikhalev, Alexander Panchenko, Ivan Oseledets | Github Papel | |
| SpaLLM: Unified Compressive Adaptation of Large Language Models with Sketching Tianyi Zhang, Junda Su, Oscar Wu, Zhaozhuo Xu, Anshumali Shrivastava | Papel | |
Bone: Block Affine Transformation as Parameter Efficient Fine-tuning Methods for Large Language Models Jiale Kang | Github Papel | |
| Enabling Resource-Efficient On-Device Fine-Tuning of LLMs Using Only Inference Engines Lei Gao, Amir Ziashahabi, Yue Niu, Salman Avestimehr, Murali Annavaram | 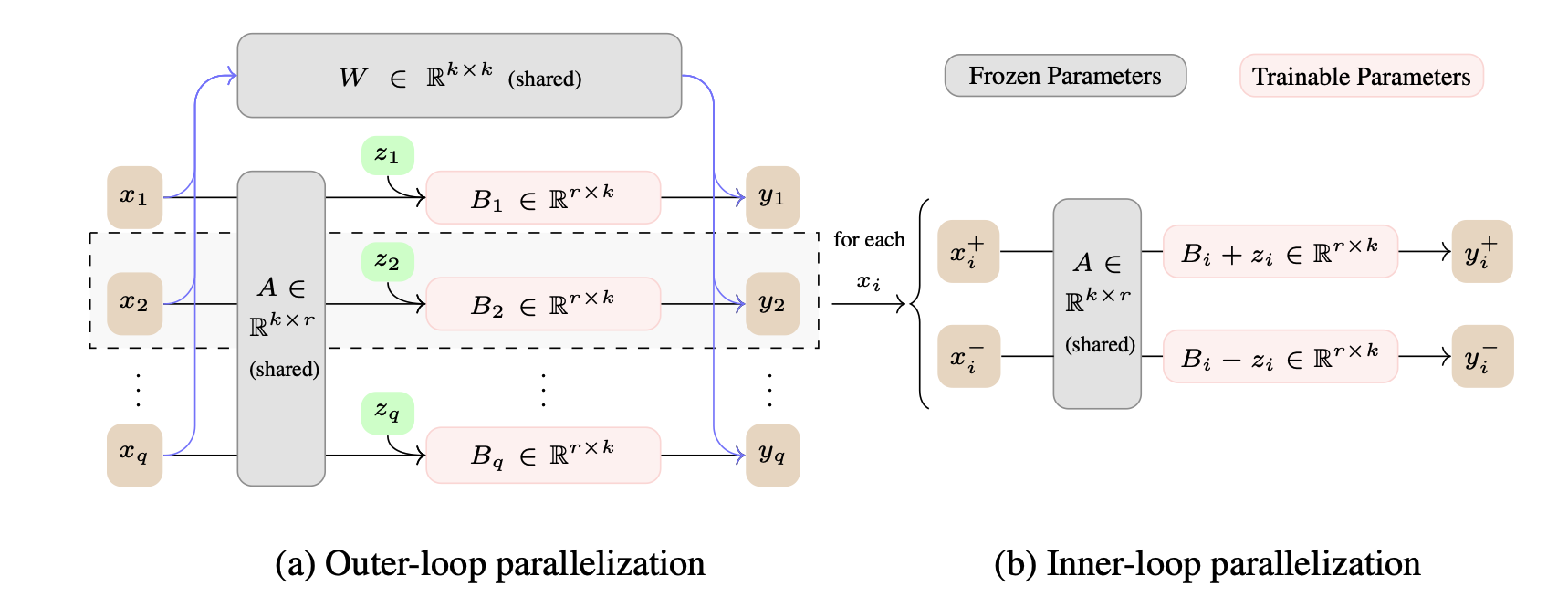 | Papel |
| Title & Authors | Introdução | Links |
|---|---|---|
| AutoMixQ: Self-Adjusting Quantization for High Performance Memory-Efficient Fine-Tuning Changhai Zhou, Shiyang Zhang, Yuhua Zhou, Zekai Liu, Shichao Weng | 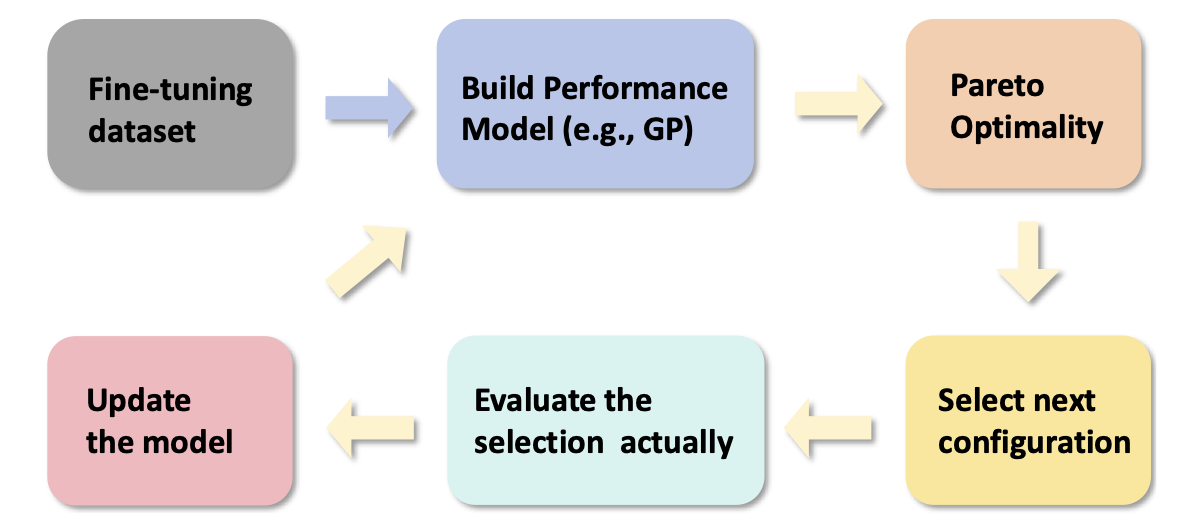 | Papel |
Scalable Efficient Training of Large Language Models with Low-dimensional Projected Attention Xingtai Lv, Ning Ding, Kaiyan Zhang, Ermo Hua, Ganqu Cui, Bowen Zhou | Github Papel | |
| Less is More: Extreme Gradient Boost Rank-1 Adaption for Efficient Finetuning of LLMs Yifei Zhang, Hao Zhu, Aiwei Liu, Han Yu, Piotr Koniusz, Irwin King | Papel | |
COAT: Compressing Optimizer states and Activation for Memory-Efficient FP8 Training Haocheng Xi, Han Cai, Ligeng Zhu, Yao Lu, Kurt Keutzer, Jianfei Chen, Song Han | 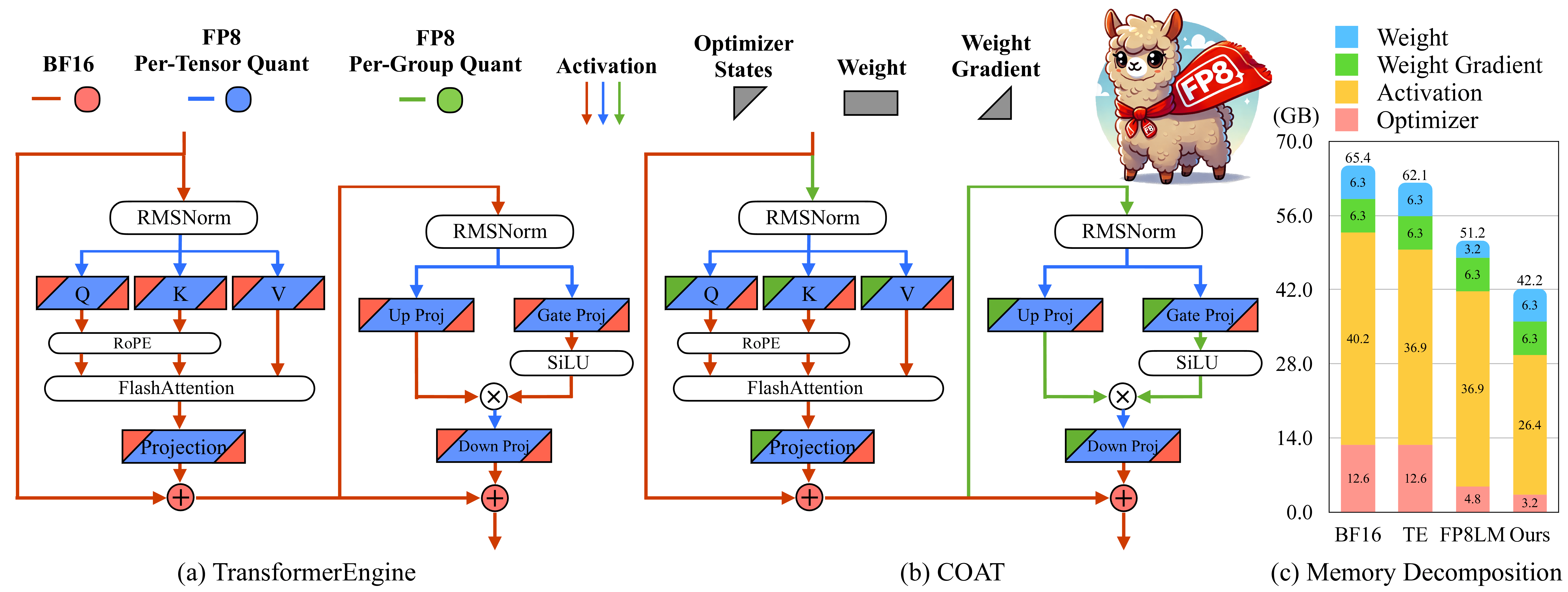 | Github Papel |
BitPipe: Bidirectional Interleaved Pipeline Parallelism for Accelerating Large Models Training Houming Wu, Ling Chen, Wenjie Yu |  | Github Papel |
| Title & Authors | Introdução | Links |
|---|---|---|
| Closer Look at Efficient Inference Methods: A Survey of Speculative Decoding Hyun Ryu, Eric Kim | Papel | |
LLM-Inference-Bench: Inference Benchmarking of Large Language Models on AI Accelerators Krishna Teja Chitty-Venkata, Siddhisanket Raskar, Bharat Kale, Farah Ferdaus et al | Github Papel | |
Prompt Compression for Large Language Models: A Survey Zongqian Li, Yinhong Liu, Yixuan Su, Nigel Collier | Github Papel | |
| Large Language Model Inference Acceleration: A Comprehensive Hardware Perspective Jinhao Li, Jiaming Xu, Shan Huang, Yonghua Chen, Wen Li, Jun Liu, Yaoxiu Lian, Jiayi Pan, Li Ding, Hao Zhou, Guohao Dai | Papel | |
| A Survey of Low-bit Large Language Models: Basics, Systems, and Algorithms Ruihao Gong, Yifu Ding, Zining Wang, Chengtao Lv, Xingyu Zheng, Jinyang Du, Haotong Qin, Jinyang Guo, Michele Magno, Xianglong Liu | Papel | |
Contextual Compression in Retrieval-Augmented Generation for Large Language Models: A Survey Sourav Verma | 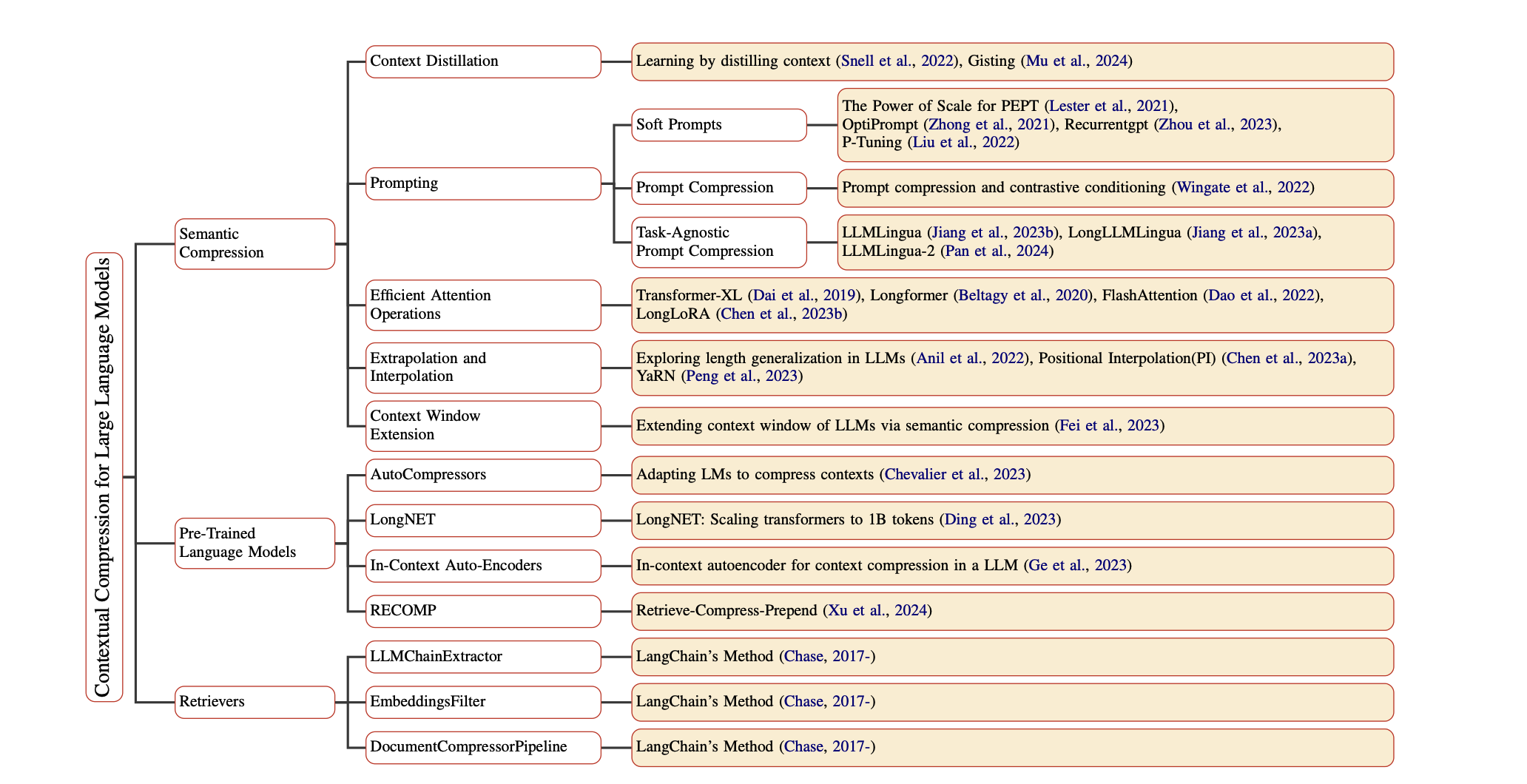 | Github Papel |
| Art and Science of Quantizing Large-Scale Models: A Comprehensive Overview Yanshu Wang, Tong Yang, Xiyan Liang, Guoan Wang, Hanning Lu, Xu Zhe, Yaoming Li, Li Weitao | Papel | |
| Hardware Acceleration of LLMs: A comprehensive survey and comparison Nikoletta Koilia, Christoforos Kachris | Papel | |
| A Survey on Symbolic Knowledge Distillation of Large Language Models Kamal Acharya, Alvaro Velasquez, Houbing Herbert Song | Papel |


