Awesome Efficient LLM
1.0.0
قائمة منسقة لنماذج اللغة الكبيرة الفعالة
إذا كنت ترغب في تضمين ورقتك ، أو تحتاج إلى تحديث أي تفاصيل مثل معلومات المؤتمر أو عناوين URL للدولة ، فلا تتردد في إرسال طلب سحب. يمكنك إنشاء تنسيق Markdown المطلوب لكل ورقة عن طريق ملء المعلومات في generate_item.py وتنفيذ python generate_item.py . نحن نقدر بحرارة مساهماتك في هذه القائمة. بدلاً من ذلك ، يمكنك مراسلتي عبر البريد الإلكتروني مع الروابط إلى ورقتك ورمزك ، وسأضيف ورقتك إلى القائمة في أقرب وقت ممكن.
لكل موضوع ، قمنا برعاية قائمة من الأوراق الموصى بها التي حصلت على الكثير من نجوم جيثب أو الاستشهادات.
| العنوان والمؤلفين | مقدمة | الروابط |
|---|---|---|
sparsegpt: يمكن تقليم نماذج لغة ضخمة بدقة في طلقة واحدة إلياس فرانتار ، دان أليساره | 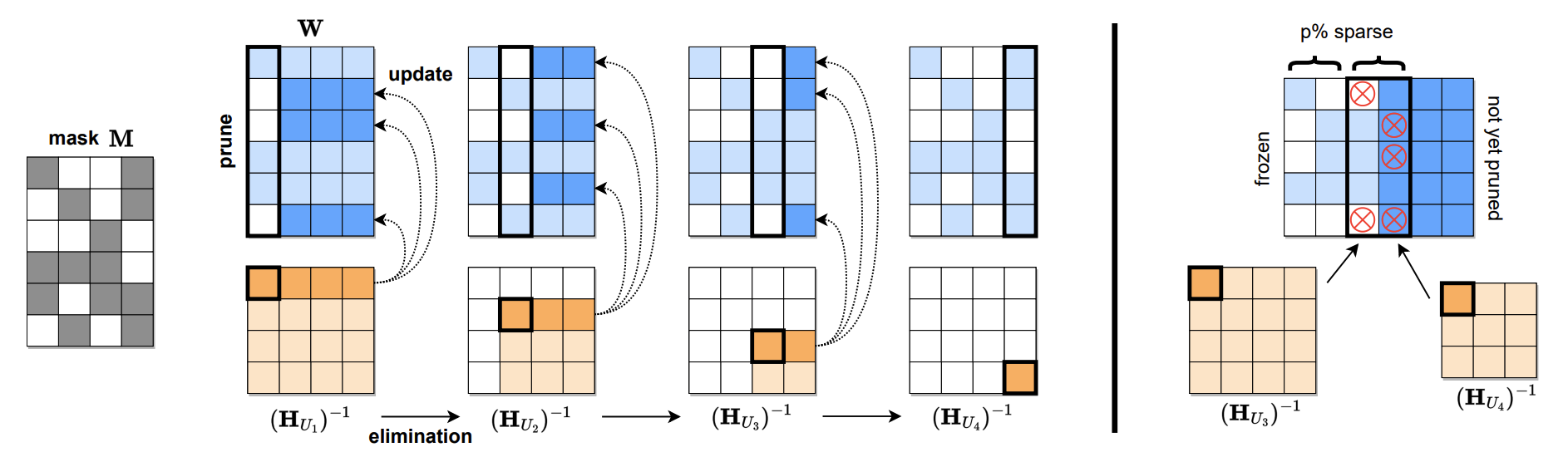 | ورقة جيثب |
LLM-Pruner: على التقليم الهيكلي لنماذج اللغة الكبيرة Xinyin MA ، Gongfan Fang ، Xinchao Wang | 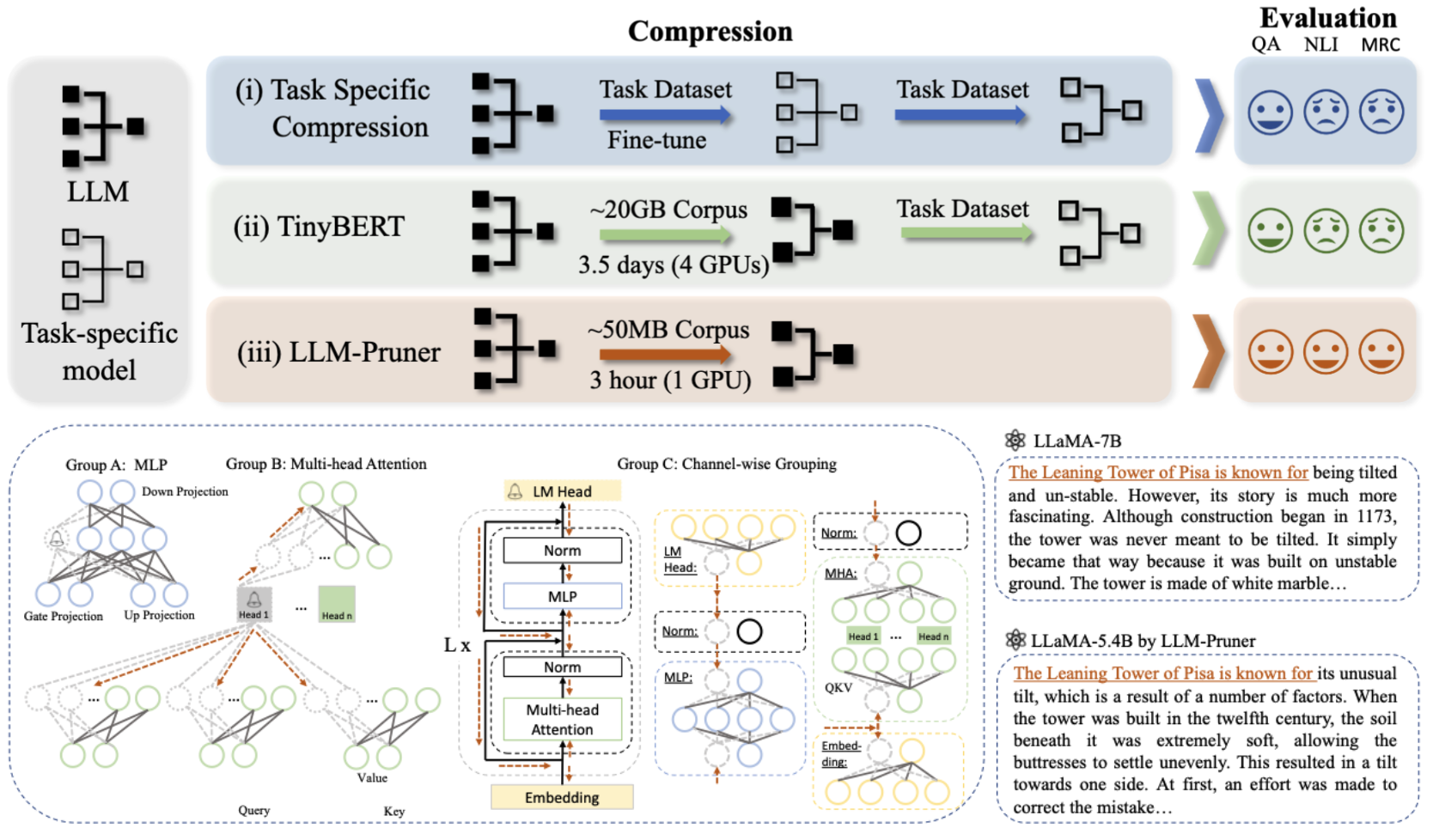 | ورقة جيثب |
نهج تقليم بسيط وفعال لنماذج اللغة الكبيرة Mingjie Sun ، Zhuang Liu ، Anna Bair ، J. Zico Kolter | 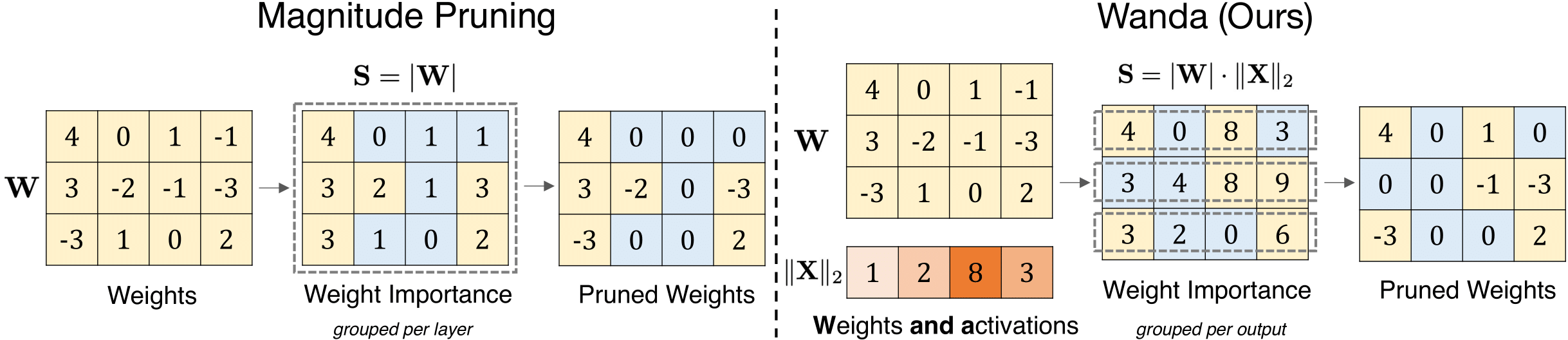 | جيثب ورق |
Llama القص: تسريع نموذج اللغة قبل التدريب عبر التقليم المنظم Mengzhou Xia ، Tianyu Gao ، Zhiyuan Zeng ، Danqi Chen | 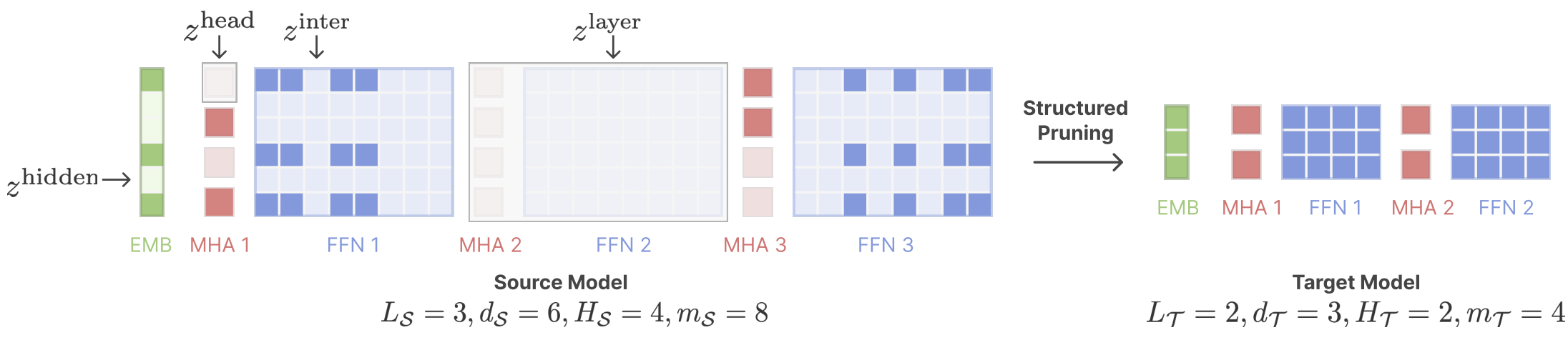 | جيثب ورق |
| استدلال LLM فعال باستخدام تقليم الإدخال الديناميكي وإدراك ذاكرة التخزين المؤقت ماركو فيديتي ، دافيد بيلي ، مارت فان بالين ، أمير جلالراد ، أندري سكيليار ، بينس ميجور ، ماركوس ناجيل ، بول واتموغ | ورق | |
| اللغز: NAS القائم على التقطير من أجل LLMS المحسّنة للاستدلال أخيد بيركوفيتش ، تومر رونين ، تالور أبراموفيتش ، نير آيلون ، ناف عساف ، محمد دابا وآخرون | ورق | |
إعادة تقييم الطبقة التقليم في LLMS: رؤى وطرق جديدة Yao Lu ، Hao Cheng ، Yujie Fang ، Zeyu Wang ، Jiaheng Wei ، Dongwei Xu ، Qi Xuan ، Xiaoniu Yang ، Zhaowei Zhu | 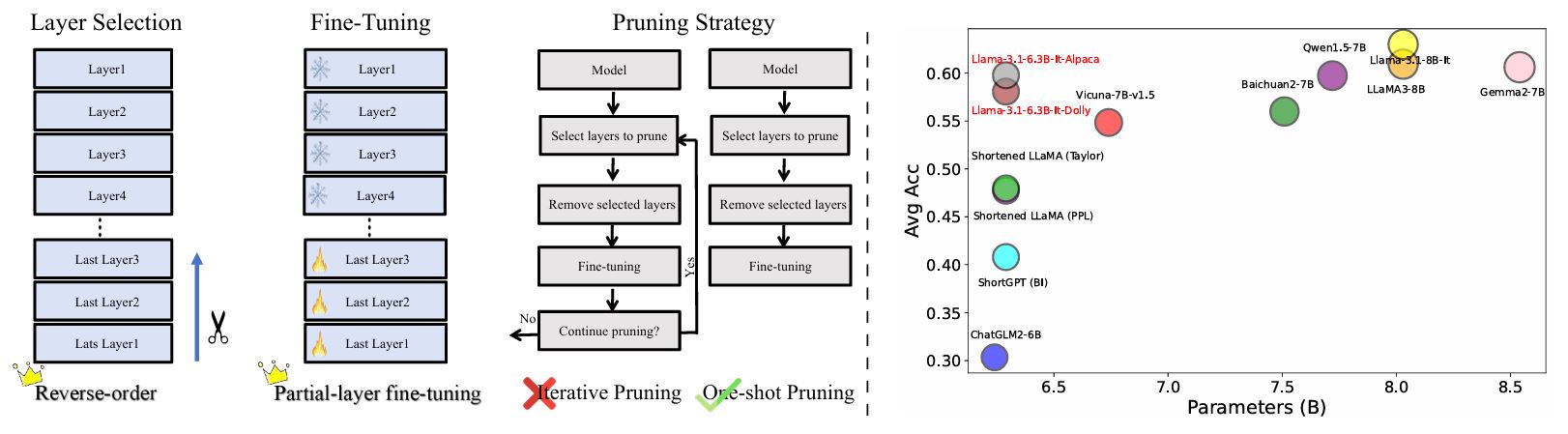 | جيثب ورق |
| أهمية الطبقة وتحليل الهلوسة في نماذج لغة كبيرة من خلال تباين التنشيط المحسن Zichen Song ، Sitan Huang ، Yuxin Wu ، Zhongfeng Kang | ورق | |
AmoeballM: بناء أي نماذج لغة كبيرة على شكل نشوب للنشر الفعال والفوري Yonggan Fu ، Zhongzhi Yu ، Junwei Li ، Jiayi Qian ، Yongan Zhang ، Xiangchi Yuan ، Dachuan Shi ، Roman Yakunin ، Yingyan Celine Lin | جيثب ورق | |
| تحجيم قانون لما بعد التدريب بعد تشذيب النموذج Xiaodong Chen ، Yuxuan Hu ، Jing Zhang ، Xiaokang Zhang ، Cuiping Li ، Hong Chen | ورق | |
DrPruning: نموذج لغة كبير فعال يشبه التحسين القوي توزيعات التوزيع Hexuan Deng ، Wenxiang Jiao ، Xuebo Liu ، Min Zhang ، Zhaopeng Tu |  | جيثب ورق |
القانون المتنافس: نحو نماذج لغوية كبيرة ذات تباين أكبر في التنشيط Yuqi Luo ، Song Chenyang ، Xu Han ، Yingfa Chen ، Chaojun Xiao ، Zhiyuan Liu ، Maosong Sun | 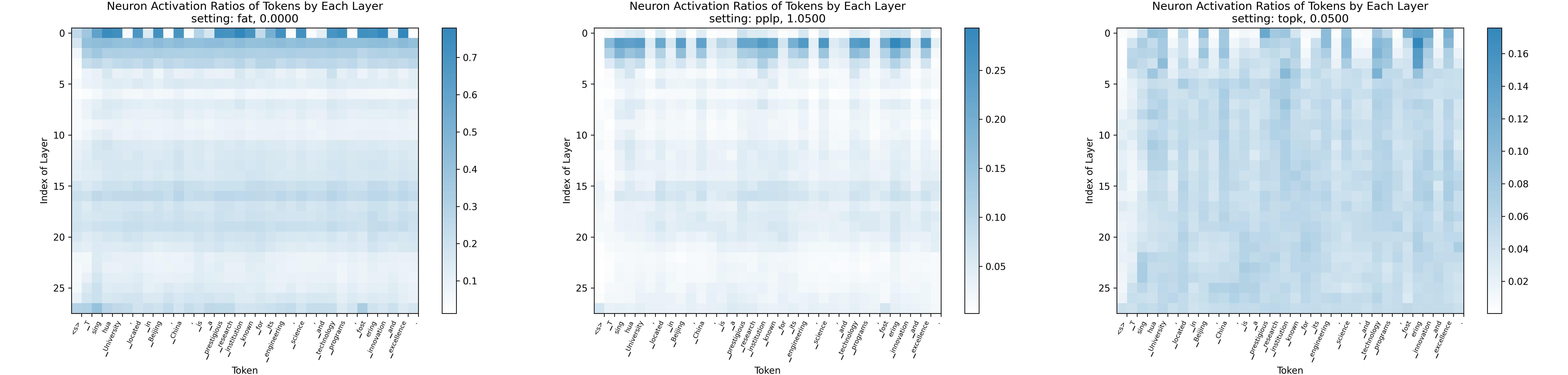 | جيثب ورق |
| AVSS: تقييم أهمية الطبقة في نماذج اللغة الكبيرة عبر تحليل تباين التنشيط Zichen Song ، Yuxin Wu ، Sitan Huang ، Zhongfeng Kang | ورق | |
| ليلاما المصممة خصيصًا: تحسين التعلم قليلًا في نماذج Llama المتقدمة بمطالبات خاصة بالمهمة دانيال أفتاب ، ستيفن ديفي | ورق | |
LLMCBENCH: قياس ضغط نموذج اللغة الكبيرة للنشر الفعال Ge Yang ، Changyi He ، Jinyang Guo ، Jianyu Wu ، Yifu Ding ، Aishan Liu ، Haotong Qin ، Pengliang Ji ، Xianglong Liu | 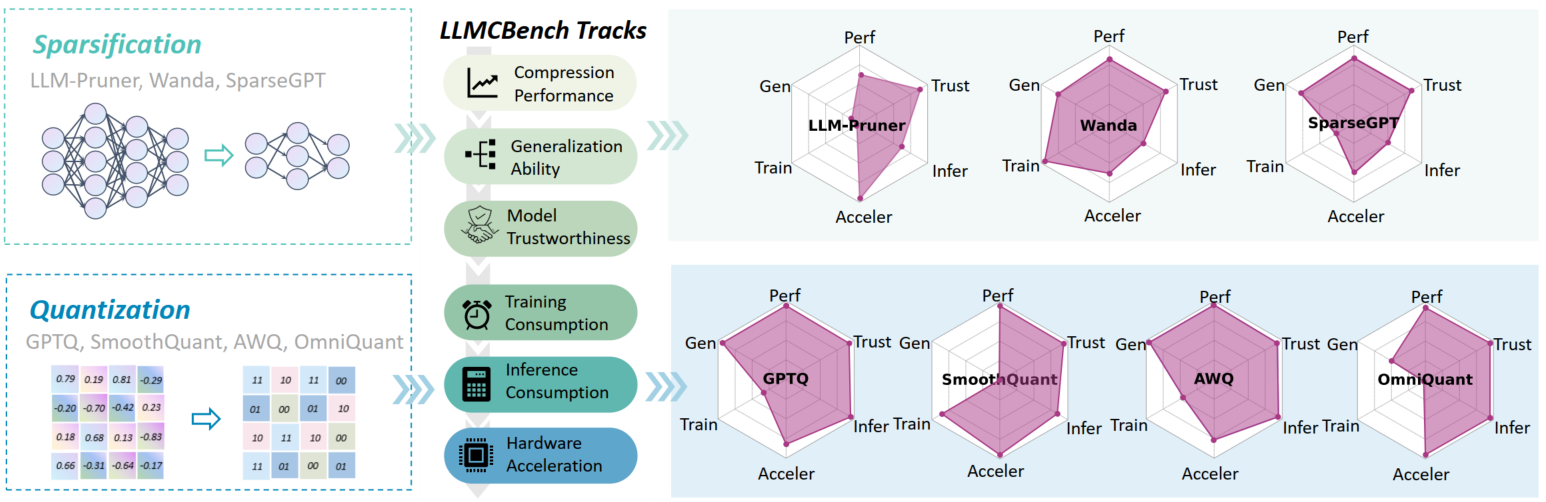 | جيثب ورق |
| أبعد من 2: 4: استكشاف V: N: M sparsity لاستنتاج المحولات الفعال على وحدات معالجة الرسومات Kang Zhao ، Tao Yuan ، Han Bao ، Zhenfeng Su ، Chang Gao ، Zhaofeng Sun ، Zichen Liang ، Liping Jing ، Jianfei Chen | ورق | |
إيفوبريس: نحو ضغط النموذج الديناميكي الأمثل عن طريق البحث التطوري أوليفر سيبرلينج ، دينيس كوزنليف ، إلدار كورتيك ، دان أليساره |  | جيثب ورق |
| FedSpallm: التقليم الفيدرالي لنماذج اللغة الكبيرة Guangji Bai ، Yijiang Li ، Zingerhan Li ، Liang Zhao ، Kibaek Kim | ورق | |
تشذيب نماذج الأساس لدقة عالية دون إعادة التدريب Pu Zhao ، Fei Sun ، Xuan Shen ، Pinrui Yu ، Zhenglun Kong ، Yanzhi Wang ، Xue Lin | جيثب ورق | |
| المعايرة الذاتية لكمية نموذج اللغة والتشذيب مايلز ويليامز ، جورج كرايسوستومو ، نيكولاوس أليتراس | ورق | |
| احذر من بيانات المعايرة لتقليم نماذج اللغة الكبيرة Yixin Ji ، Yang Xiang ، Juntao Li ، Qingrong Xia ، Ping Li ، Xinyu Duan ، Zhefeng Wang ، Min Zhang | ورق | |
ألفابرونينج: استخدام نظرية تنظيم الذات الثقيلة لتحسين التقليم من النماذج اللغوية الكبيرة Haiquan Lu ، Yefan Zhou ، Shiwei Liu ، Zhangyang Wang ، Michael W. Mahoney ، Yaoqing Yang | جيثب ورق | |
| ما وراء التقديرات الخطية: نهج التقليم الجديد لمصفوفة الانتباه Yingyu Liang ، Jiangxuan Long ، Zhenmei Shi ، Zhao Song ، Yufa Zhou | ورق | |
Disp-LLM: تقليم هيكلي مستقل عن الأبعاد لنماذج اللغة الكبيرة Shangqian Gao ، Chi-Heng Lin ، Ting Hua ، Tang Zheng ، Yilin Shen ، Hongxia Jin ، Yen-Chang Hsu | ورق | |
التقطير الذاتي لاستعادة الجودة في نماذج اللغة الكبيرة المشبعة Vithursan Thangarasa ، Ganesh Venkatesh ، Nish Sinnadurai ، Sean Lie | ورق | |
| LLM رتبة: رسم نظري للرسم البياني لتقليم نماذج اللغة الكبيرة ديفيد هوفمان ، كايلاش بودهاثوكي ، ماتيوس كلندرنر | ورق | |
هل مجموعة بيانات C4 مثالية للتقليم؟ التحقيق في بيانات المعايرة للاختطاف LLM Abhinav Bandari ، Lu Yin ، Cheng-Yu Hsieh ، Ajay Kumar Jaiswal ، Tianlong Chen ، Li Shen ، Ranjay Krishna ، Shiwei Liu | جيثب ورق | |
| التخفيف من التحيز النسخ في التعلم داخل السياق من خلال تقليم الخلايا العصبية أمين علي ، ليور وولف ، إيفان تيتوف | 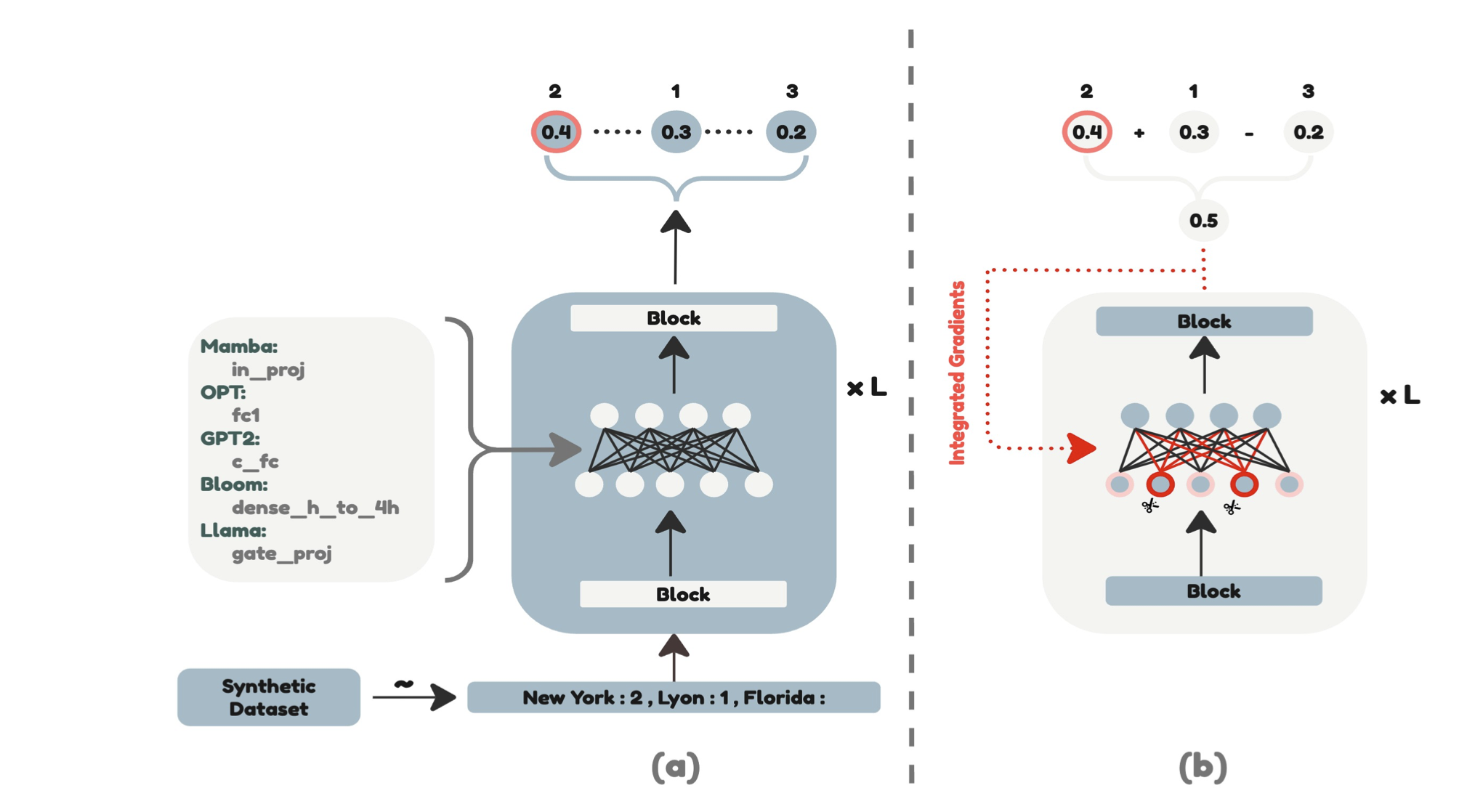 | ورق |
SQFT: التكيف النموذج منخفض التكلفة في نماذج الأساس المتناثرة منخفضة الدقة خوان بابلو مونوز ، جينجي يوان ، نيلش جاين | 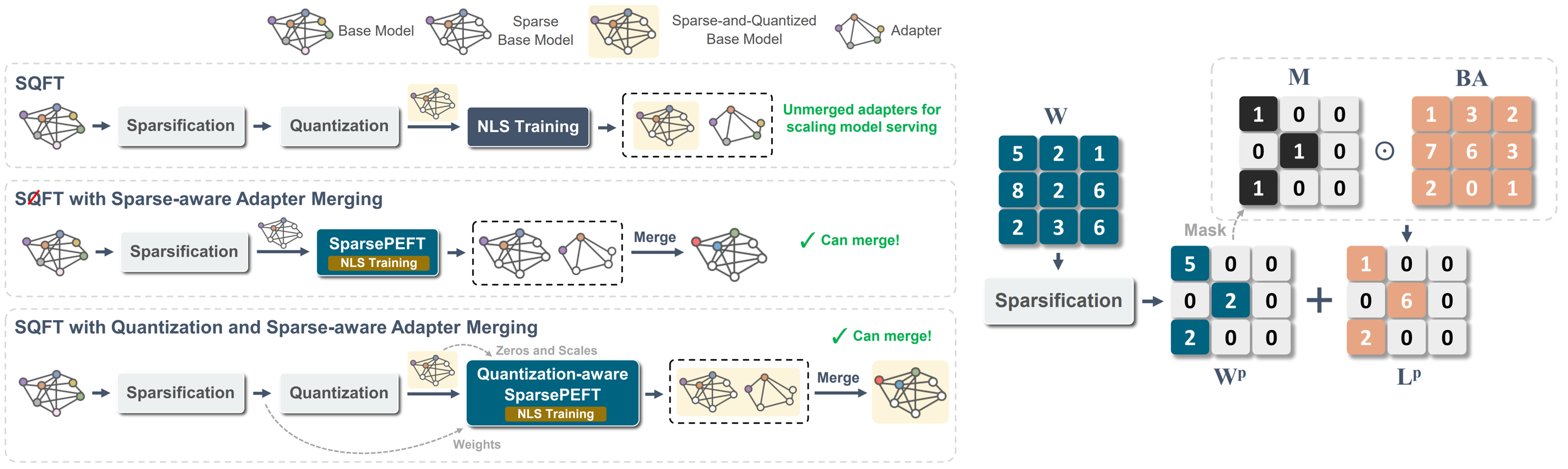 | جيثب ورق |
Maskllm: تباين شبه منظم في نماذج اللغة الكبيرة Gongfan Fang ، Hongxu Yin ، Saurav Muralidharan ، Greg Heinrich ، Jeff Pool ، Jan Kautz ، Pavlo Molchanov ، Xinchao Wang | 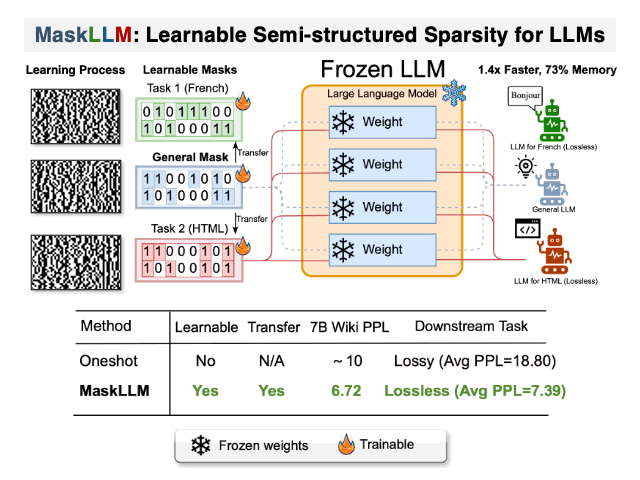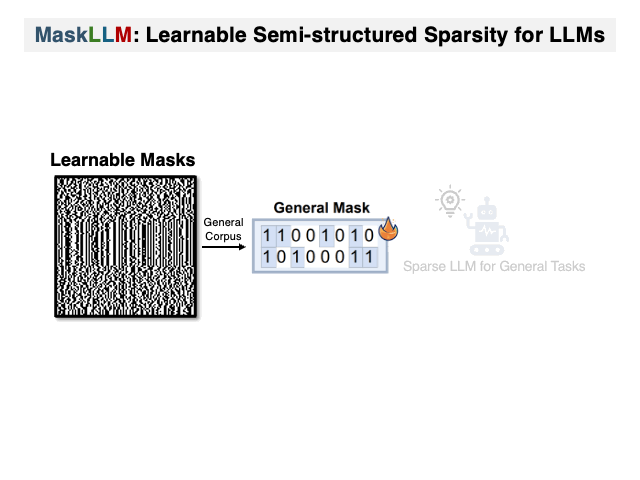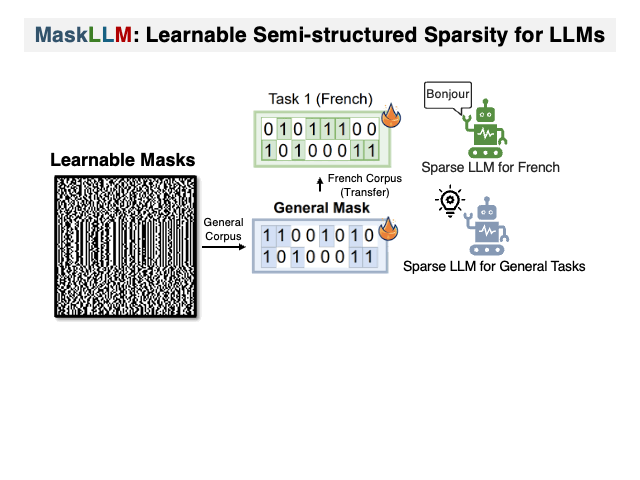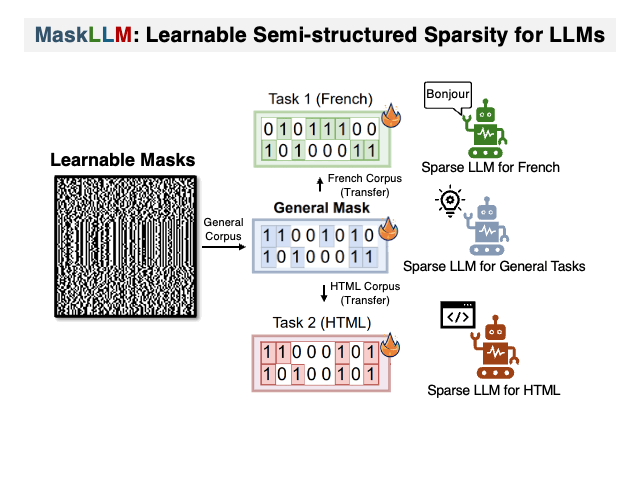 | جيثب ورق |
ابحث عن نماذج لغة كبيرة فعالة Xuan Shen ، Pu Zhao ، Yifan Gong ، Zhenglun Kong ، Zheng Zhan ، Yushu Wu ، Ming Lin ، Chao Wu ، Xue Lin ، Yanzhi Wang | ورق | |
CFSP: إطار تشذيب منظم فعال لـ LLMs مع معلومات التنشيط الخشنة Yuxin Wang ، Minghua Ma ، Zekun Wang ، Jingchang Chen ، Huiming Fan ، Liping Shan ، Qing Yang ، Dongliang Xu ، Ming Liu ، Bing Qin | جيثب ورق | |
| الشوفان: تقليم خارجي من خلال التحلل المتناثر والمنخفض في المرتبة المنخفضة ستيفن تشانغ ، فاردان بابين | ورق | |
| KVPRUNER: التقليم الهيكلي لنماذج اللغة الكبيرة الأسرع والذاكرة Bo LV ، Quan Zhou ، Xuanang Ding ، Yan Wang ، Zeming MA | ورق | |
| تقييم تأثير تقنيات الضغط على الأداء الخاص بالمهمة لنماذج اللغة الكبيرة Bishwash Khanal ، Jeffery M. Capone | ورق | |
| الصاعقة: تشذيب منظم غير منظم ل Jaeseong Lee ، Seung-Won Hwang ، Aurick Qiao ، Daniel F Campos ، Zhewei Yao ، Yuxiong He | ورق | |
PAT: تقليم يدرك نماذج اللغة الكبيرة Yijiang Liu ، Huanrui Yang ، Youxin Chen ، Rongyu Zhang ، Miao Wang ، Yuan Du ، Li Du |  | جيثب ورق |
| العنوان والمؤلفين | مقدمة | الروابط |
|---|---|---|
| تقطير المعرفة لنماذج اللغة الكبيرة Yuxian Gu ، Li Dong ، Furu Wei ، Minlie Huang |  | جيثب ورق |
| تحسين قدرات التفكير الرياضي لنماذج اللغة الصغيرة من خلال التقطير التي تعتمد على التعليقات Xunyu Zhu ، Jian Li ، Can MA ، Weiping Wang | ورق | |
التقطير السياق التوليدي Haebin Shin ، Lei Ji ، Yeyun Gong ، Sungdong Kim ، Eunbi Choi ، Minjoon SEO |  | جيثب ورق |
| التبديل: الدراسة مع المعلم من أجل تقطير المعرفة لنماذج اللغة الكبيرة Jahyun Koo ، Yerin Hwang ، Yongil Kim ، Taegwan Kang ، Hyunkyung Bae ، Kyomin Jung |  | ورق |
ما وراء التصريح التلقائي: LLMS السريع عبر التكرار الذاتي عبر الزمن جاستن ديشينوكس ، كاجلار غولسيهير | جيثب ورق | |
| التقطير قبل التدريب لنماذج اللغة الكبيرة: استكشاف مساحة التصميم Hao Peng ، Xin LV ، Yushi Bai ، Zijun Yao ، Jiajie Zhang ، Lei Hou ، Juanzi Li | ورق | |
MiniPLM: تقطير المعرفة لنماذج لغة ما قبل التدريب Yuxian Gu ، Hao Zhou ، Fandong Meng ، Jie Zhou ، Minlie Huang | 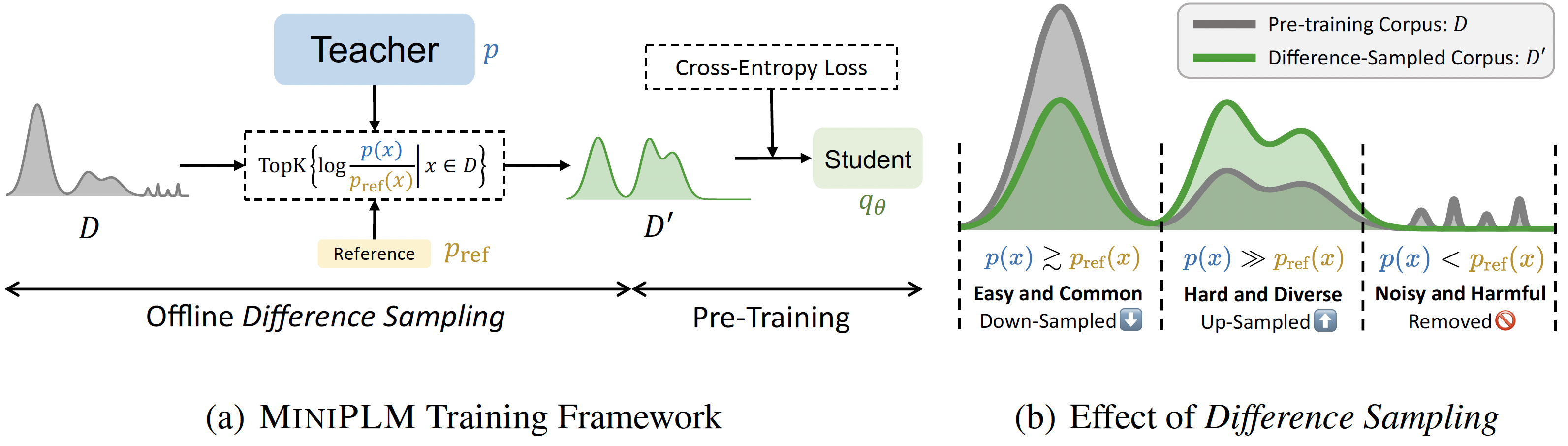 | جيثب ورق |
| تقطير المعرفة المضاربة: سد فجوة المعلم والطالب من خلال أخذ العينات المتشابكة Wenda Xu ، Rujun Han ، Zifeng Wang ، Long T. Le ، Dhruv Madeka ، Lei Li ، William Yang Wang ، Rishabh Agarwal ، Chen-Yu Lee ، Tomas Pfister | ورق | |
| التقطير التباين التطوري لمحاذاة نموذج اللغة Julian Katz-Samuels ، Zheng Li ، Hyokun Yun ، Priyanka Nigam ، Yi Xu ، Vaclav Petricek ، Bing Yin ، Trishul Chilimbi | ورق | |
| Babyllamama-2: نماذج تُعرف المقطوعة بالفرقة تتفوق باستمرار على المعلمين مع بيانات محدودة الصدر جان لوب ، إينار تيميرياسوف | ورق | |
| Echoatt: حضور ، نسخ ، ثم اضبط نماذج لغة كبيرة أكثر كفاءة حسين راجابزاده ، أريف جافاري ، أمان شارما ، بينيامين جامي ، هايوك جو كوون ، علي غودسي ، الملاكمة تشن ، مهدي رزاجوليزاده | ورق | |
Skintern: استيعاب المعرفة الرمزية لتقطير قدرات سرير أفضل في نماذج لغة صغيرة Huanxuan Liao ، Shizhu He ، Yupu Hao ، Xiang Li ، Yuanzhe Zhang ، Kang Liu ، Jun Zhao | جيثب ورق | |
LLMR: تقطير المعرفة مع مكافأة كبيرة الناجم عن نموذج اللغة Dongheng Li ، Yongchang Hao ، Lili Mou | 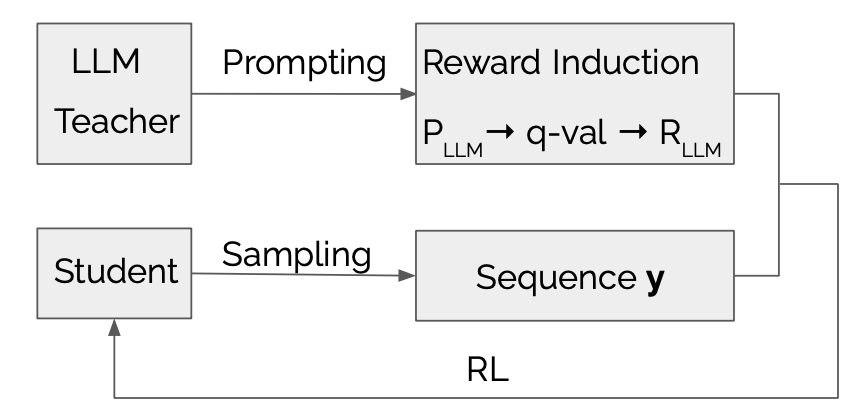 | جيثب ورق |
| استكشاف وتعزيز نقل التوزيع في تقطير المعرفة لنماذج اللغات التلقائية Jun Rao ، Xuebo Liu ، Zepeng Lin ، Liang Ding ، Jing Li ، Dacheng Tao | ورق | |
| تقطير المعرفة الفعال: تمكين نماذج اللغة الصغيرة مع رؤى نموذج المعلم Mohamad Ballout ، Ulf Krumnack ، Gunther Heidemann ، Kai-Uwe Kühnberger | ورق | |
Mamba في Llama: نماذج التقطير والتسريع Junxiong Wang ، Daniele Paliotta ، Avner May ، Alexander M. Rush ، Tri Dao | جيثب ورق |
| العنوان والمؤلفين | مقدمة | الروابط |
|---|---|---|
GPTQ: كمية دقيقة بعد التدريب للمحولات التي تم تدريبها قبل التدريب إلياس فرانتار ، صالح آشكوبوس ، تورستن هيفلر ، دان أليستاره | 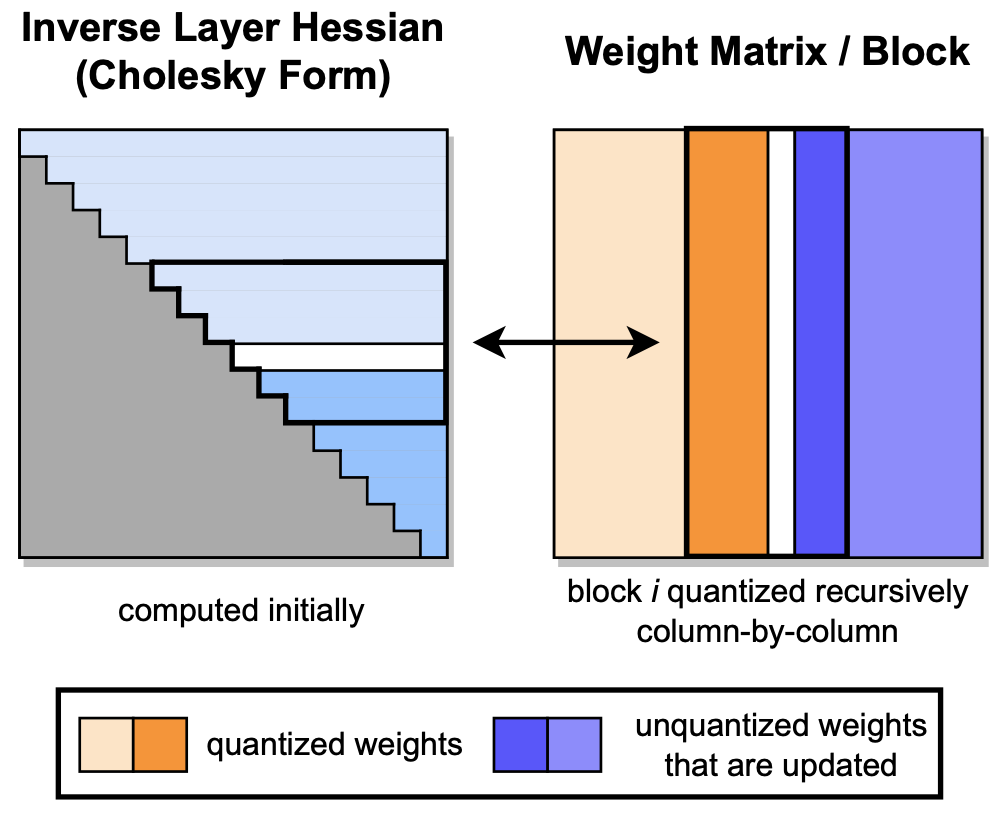 | جيثب ورق |
SmoothQuant: كمية دقيقة وفعالة بعد التدريب لنماذج اللغة الكبيرة Guangxuan Xiao ، Ji Lin ، Mickael Seznec ، Hao Wu ، Julien Demouth ، Song Han | 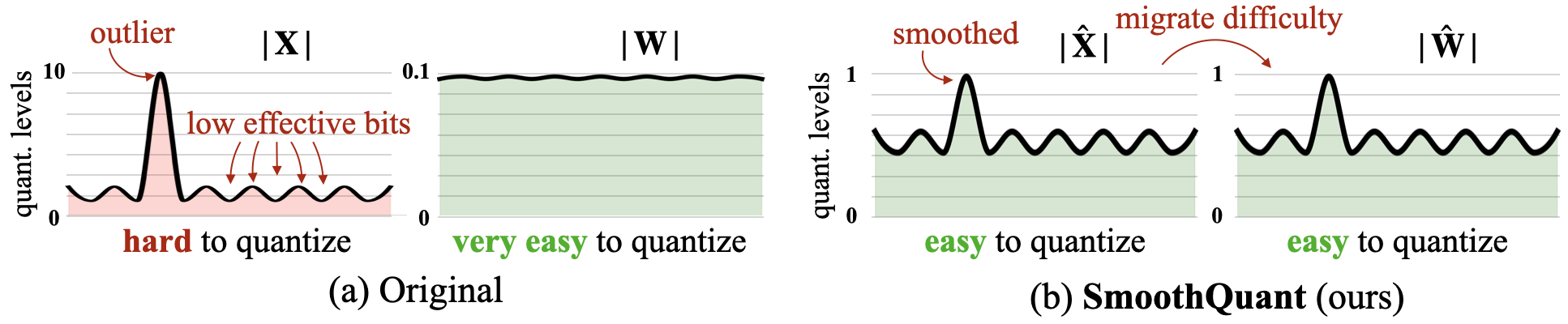 | جيثب ورق |
AWQ: كمية وزن التنشيط لضغط LLM والتسارع Ji Lin ، Jiaming Tang ، Haotian Tang ، Shang Yang ، Xingyu Dang ، Song Han | 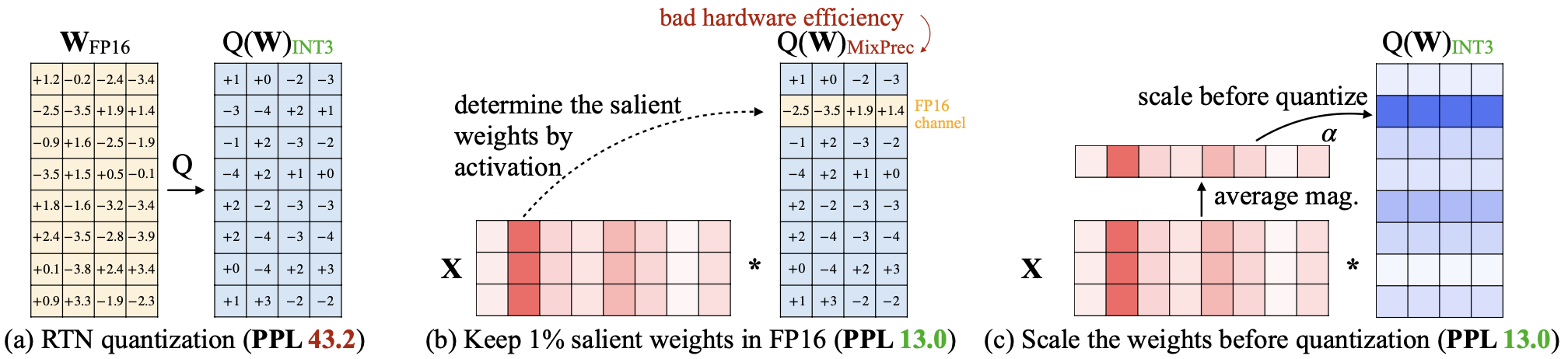 | جيثب ورق |
كلوانيك: الكميات المعايرة في كل مكان للنماذج اللغوية الكبيرة Wenqi Shao ، Mengzhao Chen ، Zhaoyang Zhang ، Peng Xu ، Lirui Zhao ، Zhiqian Li ، Kaipeng Zhang ، Peng Gao ، Yu Qiao ، Ping Luo | 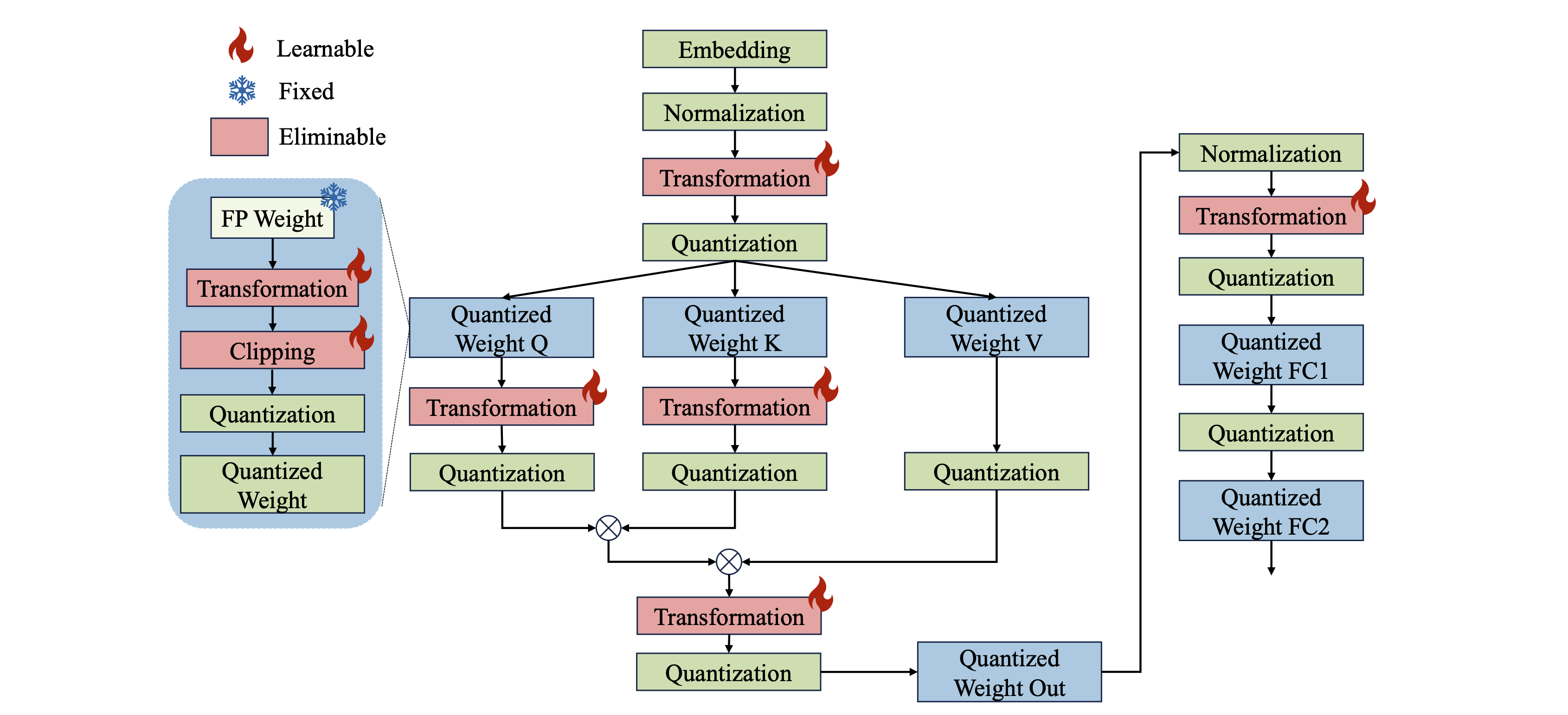 | جيثب ورق |
| skim: أي كميات من البت تدفع حدود كمية ما بعد التدريب Ronsheng Bai ، Qiang Liu ، Bo Liu | ورق | |
| CPTQUANT-تقنيات قياس كمية مختلطة بعد التدريب الجديدة لنماذج اللغة الكبيرة أميتاش ناندا ، ساري بهارجافي بالجا ، ديباشيس ساهو | ورق | |
ANDA: فتح استنتاج LLM الفعال مع تنسيق بيانات التنشيط المجمعة متغير الطول Chao Fang ، Man Shi ، Robin Geens ، Arne Symons ، Zhongfeng Wang ، Marian Verhelst | ورق | |
| MIXPE: القياس الكمي وتصميم الأجهزة المشتركة لاستنتاج LLM الفعال Yu Zhang ، Mingzi Wang ، Lancheng Zou ، Wulong Liu ، Hui-Ling Zhen ، Mingxuan Yuan ، Bei Yu | ورق | |
صورة نقطية: تسارع Bit-serial-for-datatype llm Yuzong Chen ، Ahmed F. Abouelhamayed ، Xilai Dai ، Yang Wang ، Marta Andronic ، George A. Constantinides ، Mohamed S. Abdelfattah | جيثب ورق | |
| AMXFP4: تم ترويض القيم المتطورة بتنشيط مع النقطة العائمة المجهرية غير المتماثلة لاستنتاج LLM 4 بت Janghwan Lee ، Jiwoong Park ، Jinseok Kim ، Yongjik Kim ، Jungju Oh ، Jinwook Oh ، Jungwook Choi | 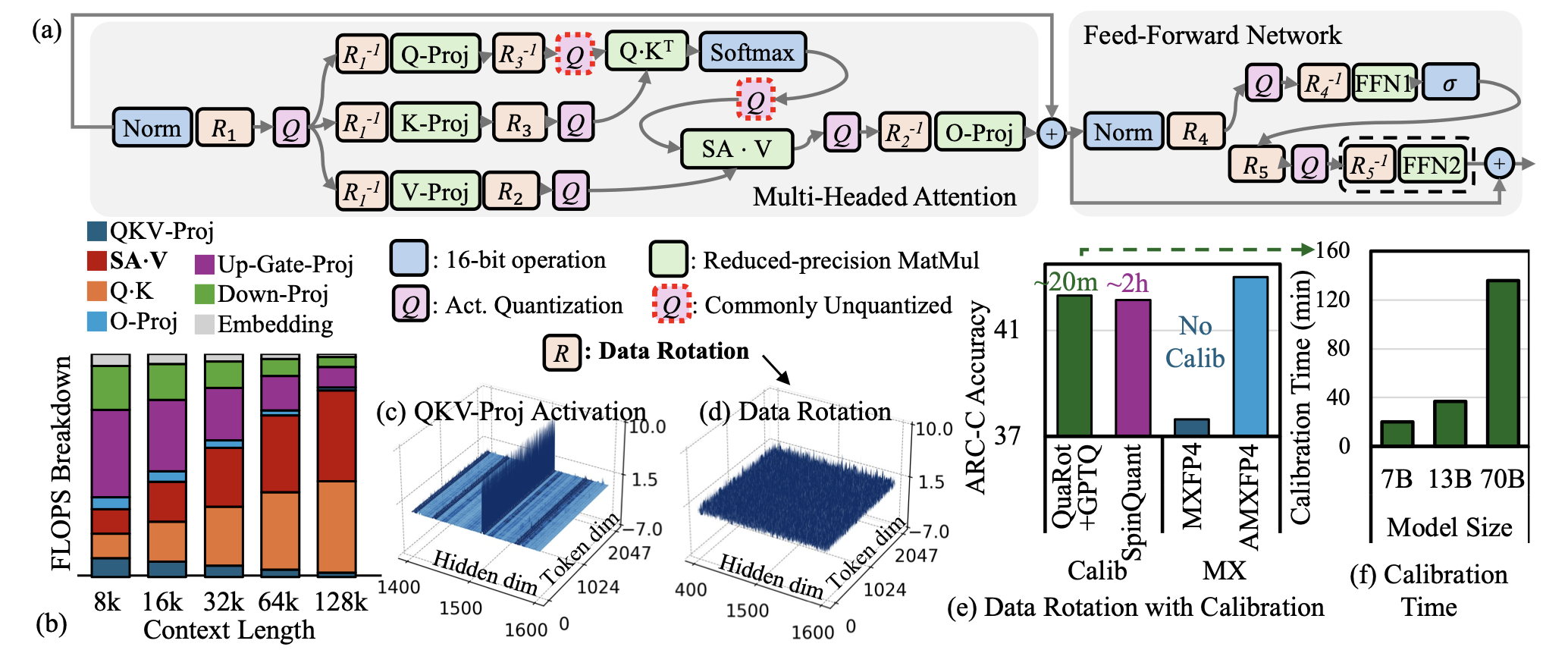 | ورق |
| ثنائية في مامبا: نحو نماذج مساحة حالة واحدة دقيقة واحدة Shengkun Tang ، Liqun MA ، Haonan Li ، Mingjie Sun ، Zhiqiang Shen | ورق | |
| "أعطني BF16 أو أعطني الموت"؟ مقايضات دقة الأداء في تقدير LLM إلدار كورتيك ، ألكساندر ماركيز ، شوبرا بانديت ، مارك كورتز ، دان أليساره | ورق | |
| GWQ: تقدير الوزن على دراية بالنماذج اللغوية الكبيرة Yihua Shao ، Siyu Liang ، Xiaolin Lin ، Zijian Ling ، Zixian Zhu et al | ورق | |
| دراسة شاملة حول تقنيات القياس الكمي لنماذج اللغة الكبيرة Jiedong Lang ، Zhehao Guo ، Shuyu Huang | ورق | |
| Bitnet A4.8: 4 بت تنشيطات LLMS 1 بت Hongyu Wang ، Shuming MA ، Furu Wei | ورق | |
Tesseraq: ultra LLM LLM بعد التدريب مع إعادة بناء الكتلة Yuhang Li ، Priyadarshini Panda | 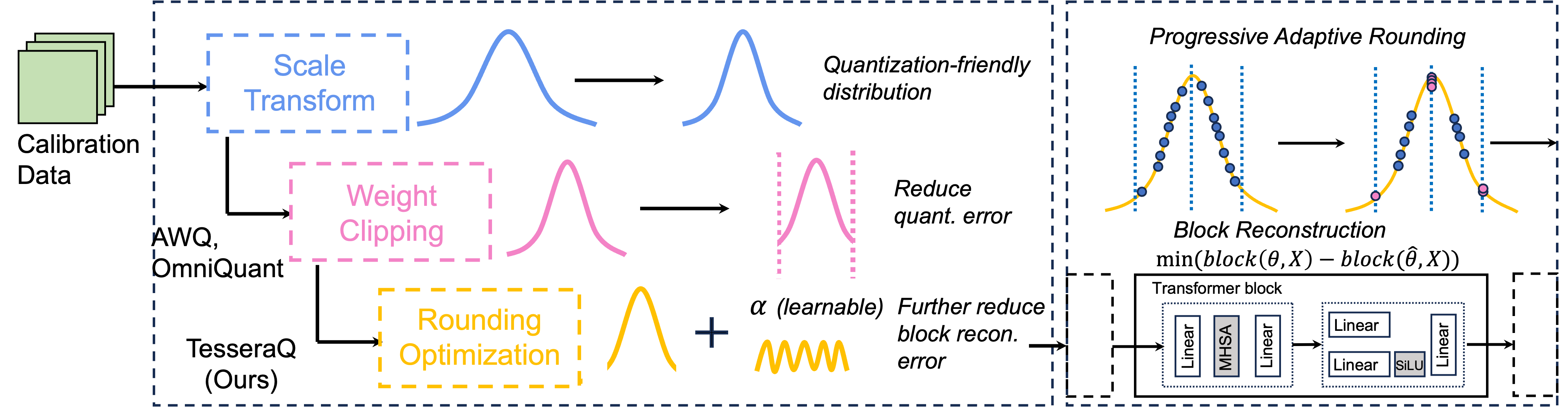 | جيثب ورق |
BitStack: التحكم في الحجم الدقيق لنماذج لغة كبيرة مضغوطة في بيئات الذاكرة المتغيرة Xinghao Wang ، Pengyu Wang ، Bo Wang ، Dong Zhang ، Yunhua Zhou ، Xipeng Qiu | 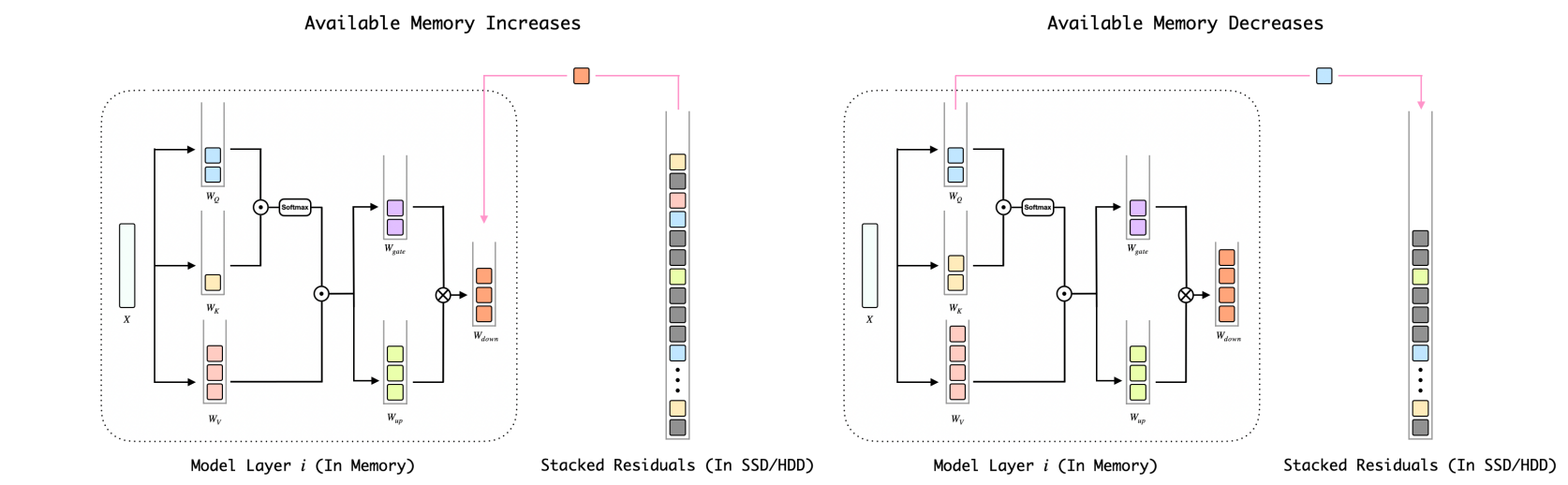 | جيثب ورق |
| تأثير استراتيجيات تسريع الاستدلال على تحيز LLMS إليزابيث كيرستن ، إيفان هابرنال ، فيدانت ناندا ، محمد بيلال زافار | ورق | |
| فهم صعوبة تحديد كمية بعد التدريب لنماذج اللغة الكبيرة Zifei Xu ، Sayeh Sharify ، Wanzin Yazar ، Tristan Webb ، Xin Wang | ورق | |
1 بت AI INFRA: الجزء 1.1 ، Bitnet B1.58 سريع وبدون خسارة Jinheng Wang ، Hansong Zhou ، Ting Song ، Shaoguang Mao ، Shuming MA ، Hongyu Wang ، Yan Xia ، Furu Wei | جيثب ورق | |
| Quailora: التهيئة الكمية الراغبة في لورا نيل لوتون ، إيشواريا بادماكومار ، جوديث جاسبرز ، جاك فيتزجيرالد ، أنوب كومار ، جريج فير ستيج ، أرام غالستيان | ورق | |
| تقييم نماذج لغة كبيرة كمية لتوليد الكود على معايير اللغة منخفضة الموارد Enkhbold Nyamsuren | ورق | |
Squeezellm: الكمية الكثيفة والقرعة Sehoon Kim ، Coleman Hooper ، Amir Gholami ، Zhen Dong ، Xiuyu Li ، Sheng Shen ، Michael W. Mahoney ، Kurt Keutzer | 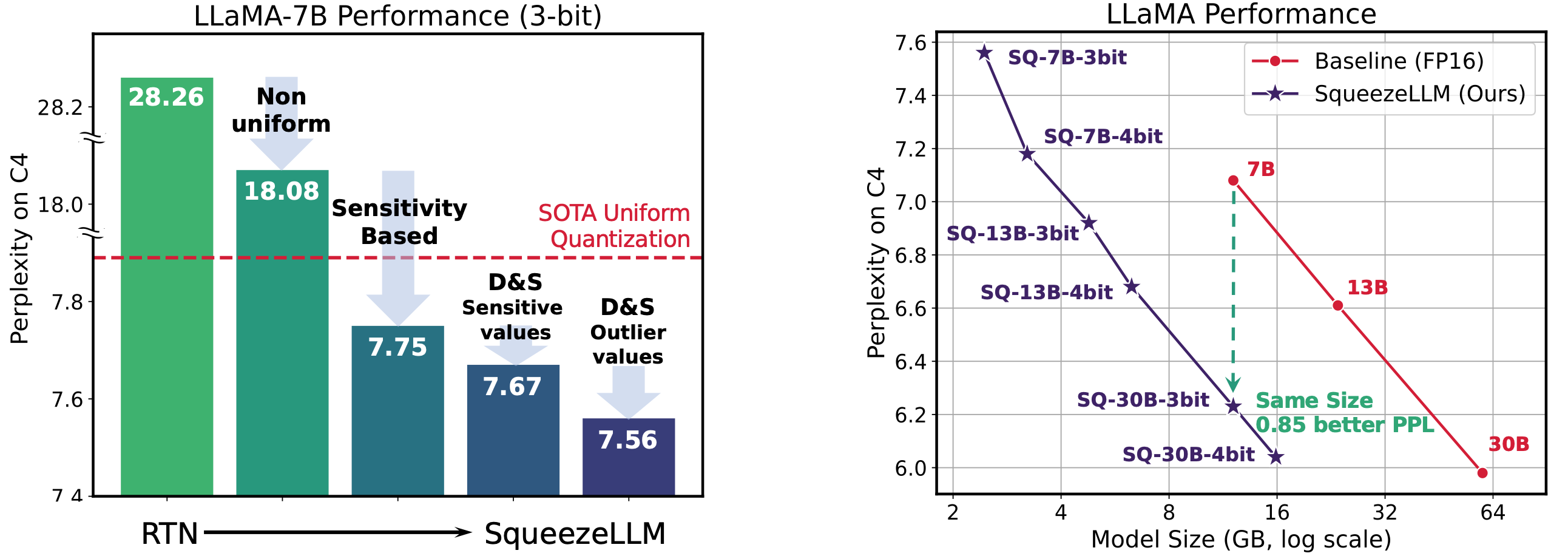 | جيثب ورق |
| كمية ناقلات الهرم ل LLMS Tycho fa van der ouderaa ، Maximilian L. Croci ، Agrin Hilmkil ، James Hensman | ورق | |
| Seedlm: ضغط أوزان LLM في بذور مولدات العشوائية الزائفة راسول شافيبور ، ديفيد هاريسون ، ماكسويل هورتون ، جيفري ماركر ، هومان بيدات ، ساتشين ميهتا ، محمد راستيغاري ، ماهيار نجبي ، سامان نادريباريزي | ورق | |
Flatquant: مسائل التسطيح لكمية LLM Yuxuan Sun ، Ruikang Liu ، Haoli Bai ، Han Bao ، Kang Zhao ، Yuening LI | جيثب ورق | |
Slim: طلقة واحدة متفرقة بالإضافة إلى تقريب منخفضة الرتبة من LLMS محمد موزفاري ، مريم مهري ديهنافي | جيثب ورق | |
| قوانين تحجيم نماذج لغة كبيرة بعد التدريب Zifei Xu ، ألكساندر لان ، وانزين يازار ، تريستان ويب ، سايه شاريفي ، شين وانغ | ورق | |
| تقريبية مستمرة لتحسين تقدير الكميات التدريبية لـ LLMS هو لي ، جيانانغ هونغ ، يوانتشو وو ، سنيهال أدبول ، زونغلين لي | ورق | |
DAQ: الكميات التي تدرك الكثافة بعد التدريب فقط لوزن LLMS Yingsong Luo ، Ling Chen | جيثب ورق | |
Quamba: وصفة كمية بعد التدريب لنماذج مساحة الحالة الانتقائية Hung-Yueh Chiang ، Chi-Chih Chang ، Natalia Frumkin ، Kai-Chiang Wu ، Diana Marculescu | جيثب ورق | |
| asymkv: تمكين كمية 1 بت من ذاكرة التخزين المؤقت KV مع تكوينات الكمية غير المتماثلة من الطبقة تشيان تاو ، وينيوان يو ، جينغن تشو | ورق | |
| تحديد كميات مختلطة القنوات لنماذج اللغة الكبيرة Zihan Chen ، Bike Xie ، Jundong Li ، Cong Shen | ورق | |
| فك التشفير التدريجي المختلط لاستنتاج LLM الفعال Hao Mark Chen ، Fuwen Tan ، Alexandros Kouris ، Royson Lee ، Hongxiang Fan ، Stylianos I. Venieris | ورق | |
exaq: كميات إطلاء على الأسس لتسريع LLMS Moran Shkolnik ، Maxim Fishman ، Brian Chmiel ، Hilla Ben-Yaacov ، Ron Banner ، Kfir Yehuda Levy | 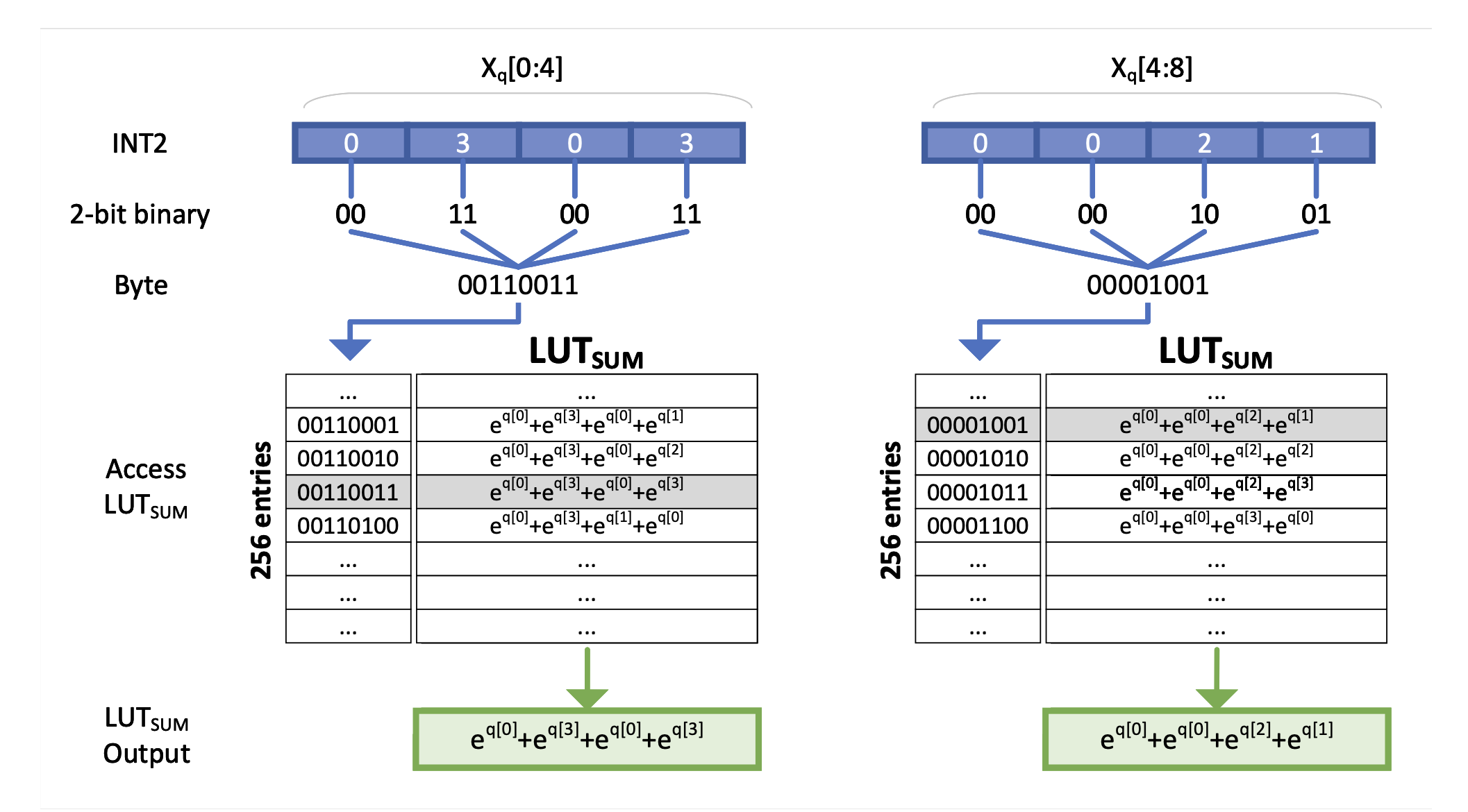 | جيثب ورق |
بادئة: الكمي الثابت يتفوق على ديناميكية من خلال القيم المتطرفة المسبقة في LLMS Mengzhao Chen ، Yi Liu ، Jiahao Wang ، Yi Bin ، Wenqi Shao ، Ping Luo | جيثب ورق | |
الضغط الشديد لنماذج اللغة الكبيرة عبر القياس الإضافي Vage Egiazarian ، Andrei Panferov ، Denis Kuznedelev ، Elias Frantar ، Artem Babenko ، Dan Alistarh | 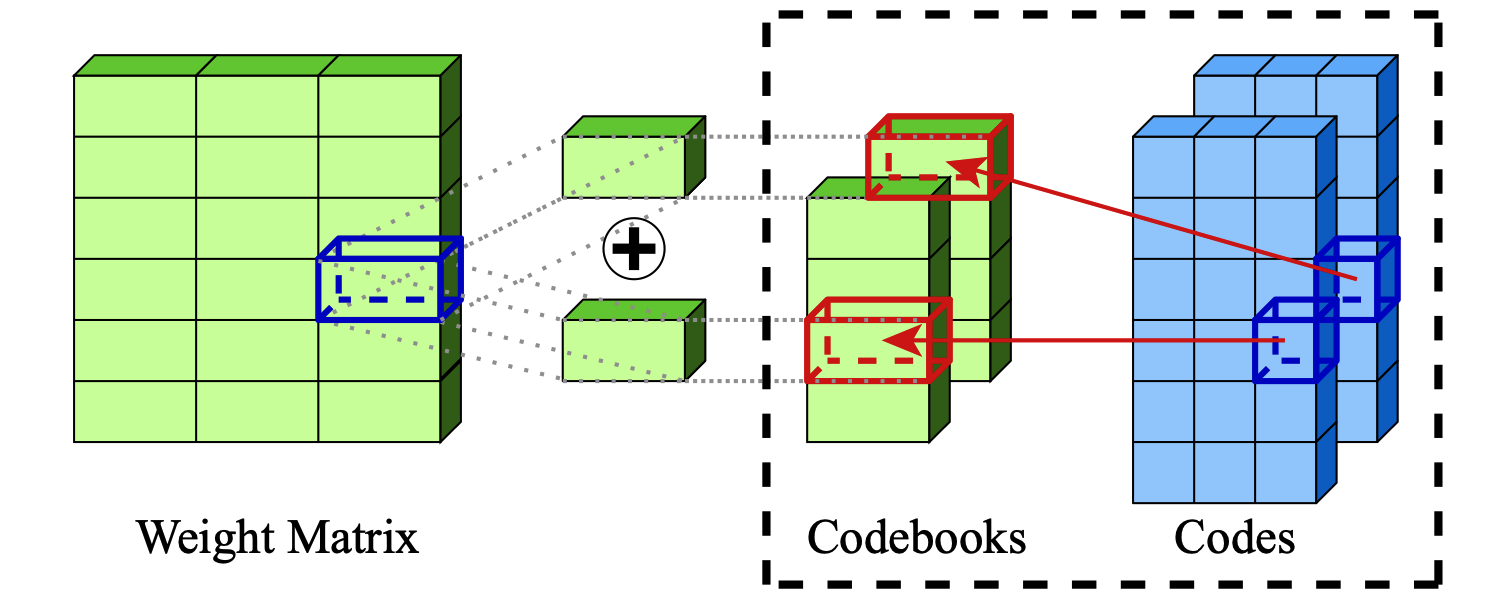 | جيثب ورق |
| قوانين تحجيم الكميات المختلطة في نماذج اللغة الكبيرة Zeyu Cao ، Cheng Zhang ، Pedro Gimenes ، Jianqiao Lu ، Jianyi Cheng ، Yiren Zhao | 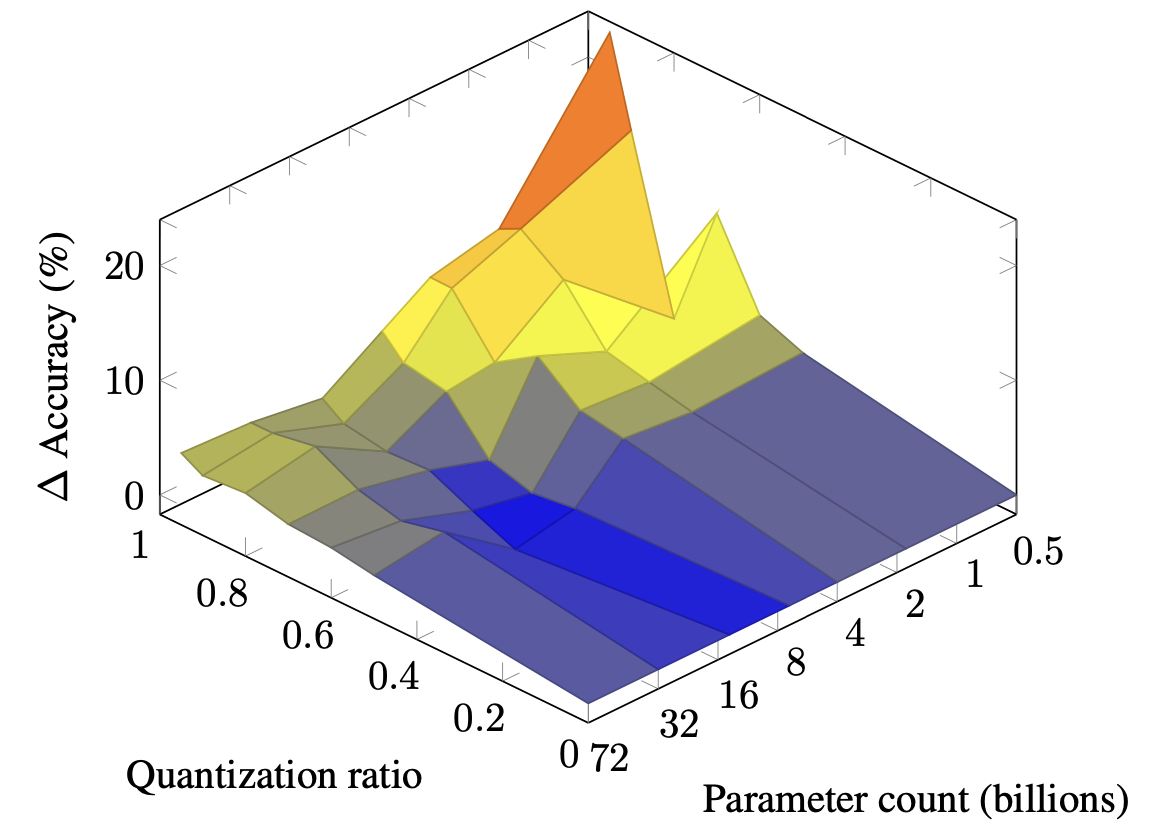 | ورق |
| Palmbench: معيار شامل لنماذج اللغة الكبيرة المضغوطة على منصات المحمول Yilong Li ، Jingyu Liu ، Hao Zhang ، M Badri Narayanan ، Utkarsh Sharma ، Shuai Zhang ، Pan Hu ، Yijing Zeng ، Jayaram Raghuram ، Suman Banerjee | 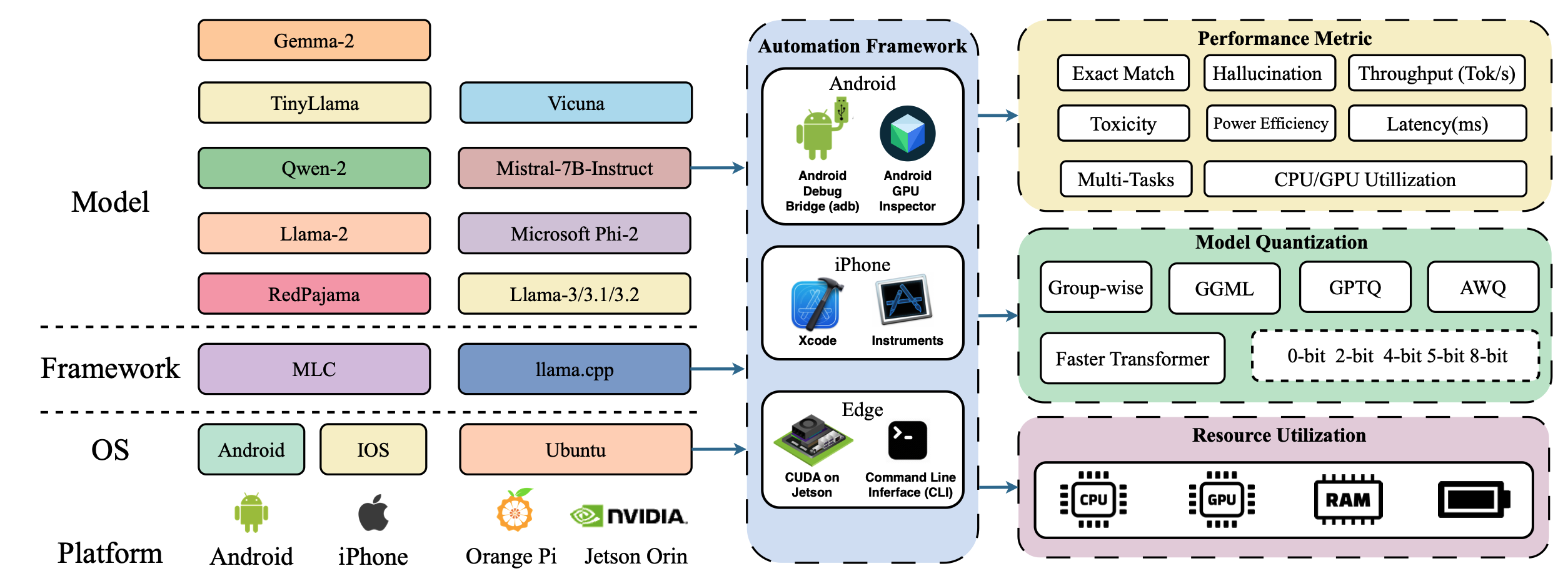 | ورق |
| Crossquant: طريقة كمية بعد التدريب مع نواة كمية أصغر لضغط نموذج اللغة الكبيرة الدقيقة Wenyuan Liu ، Xindian MA ، Peng Zhang ، Yan Wang | ورق | |
| SageAttention: اهتمام دقيق 8 بت لتسريع الاستدلال في التوصيل والتشغيل Jintao Zhang ، Jia Wei ، Pengle Zhang ، Jun Zhu ، Jianfei Chen | ورق | |
| الإضافة هي كل ما تحتاجه لنماذج اللغة الموفرة للطاقة Hongyin Luo ، Wei Sun | ورق | |
VPTQ: كميات متطورة لما بعد التدريب في ناقلات المتجهات المنخفضة بتات لنماذج اللغة الكبيرة Yifei Liu ، Jicheng Wen ، Yang Wang ، Shengyu Ye ، Li Lyna Zhang ، Ting Cao ، Cheng Li ، Mao Yang | 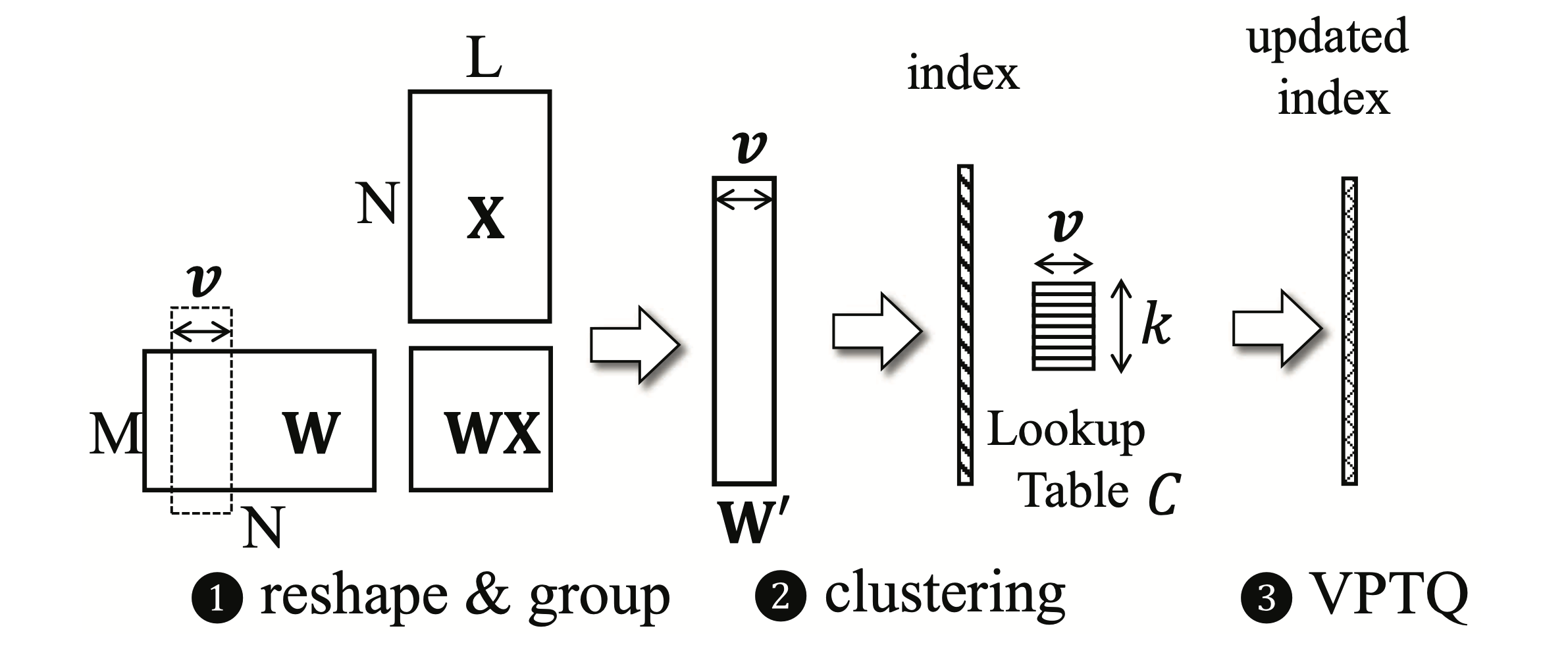 | جيثب ورق |
int-flashattention: تمكين اهتمام الفلاش لتحديد int8 Shimao Chen ، Zirui Liu ، Zhiying Wu ، Ce Zheng ، Peizhuang Cong ، Zihan Jiang ، Yuhan Wu ، Lei Su ، Tong Yang | جيثب ورق | |
| تراكم كمي ما بعد التدريب إيان كولبيرت ، فابيان جروب ، جوزيبي فرانكو ، جينجي تشانغ ، رايان ساب | ورق | |
duquant: توزيع القيم المتطرفة عبر التحول المزدوج يجعل LLMs كمية أقوى Haokun Lin ، Hoobo Xu ، Yichen Wu ، Jingzhi Cui ، Yingtao Zhang ، Linzhan Mou ، Linqi Song ، Zhenan Sun ، Ying Wei | 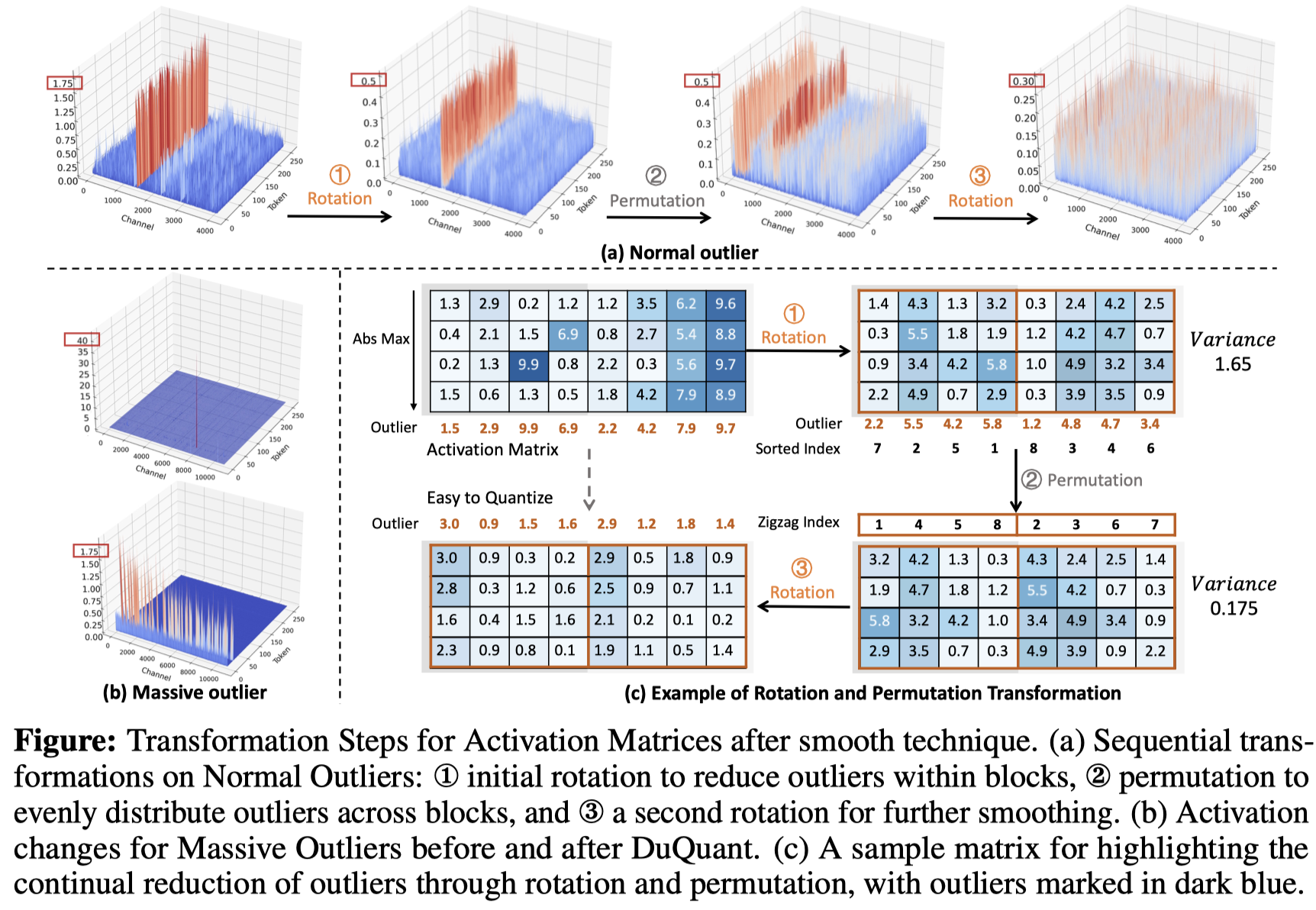 | جيثب ورق |
| تقييم شامل لنماذج اللغة الكبيرة التي تم ضبطها على التعليمات الكمية: تحليل تجريبي يصل إلى 405 ب Jemin Lee ، Sihyeong Park ، Jinse Kwon ، Jihun Oh ، Yongin Kwon | ورق | |
| تفرد LLAMA3-70B مع تقدير لكل قناة: دراسة تجريبية مينغهاي تشين | ورق |
| العنوان والمؤلفين | مقدمة | الروابط |
|---|---|---|
Deja VU: التباين السياقي في LLMs الفعالة في وقت الاستدلال Zichang Liu ، Jue Wang ، Tri Dao ، Tianyi Zhou ، Binhang Yuan ، Zhao Song ، Anshumali Shrivastava ، Ce Zhang ، Yuandong Tian ، Christopher RE ، Beidi Chen | 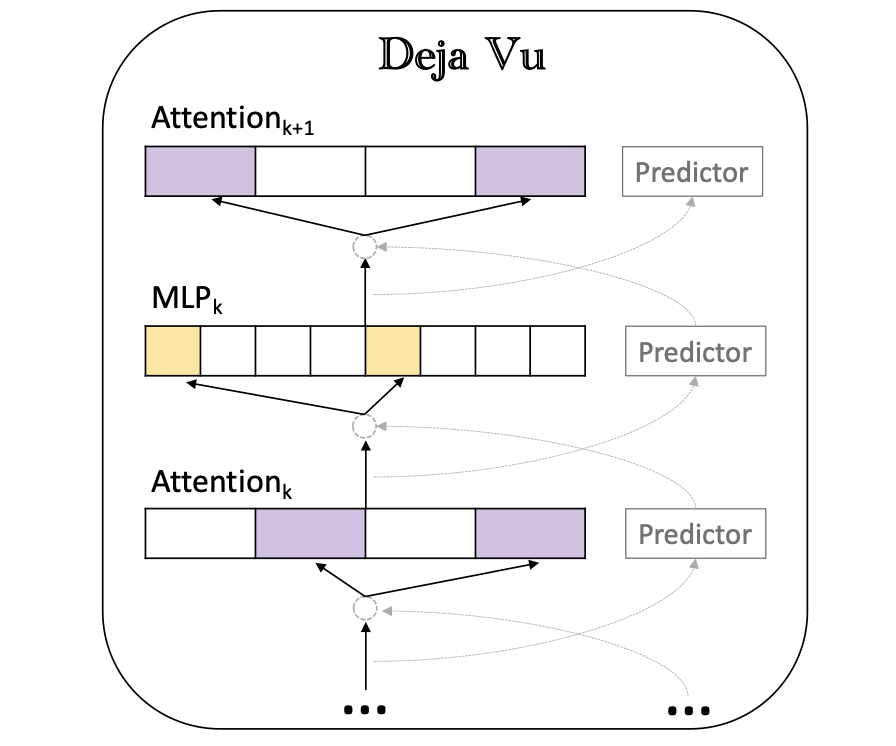 | جيثب ورق |
SPECINFER: تسريع خدمة LLM التوليدية مع الاستدلال المضاربة والتحقق من شجرة الرمز المميز Xupeng Miao ، Gabriele Oliaro ، Zhihao Zhang ، Xinhao Cheng ، Zeyu Wang ، Rae Ying Yee Wong ، Zhuoming Chen ، Daiaan Arfeen ، Reyna Abhyankar ، Zhihao Jia | 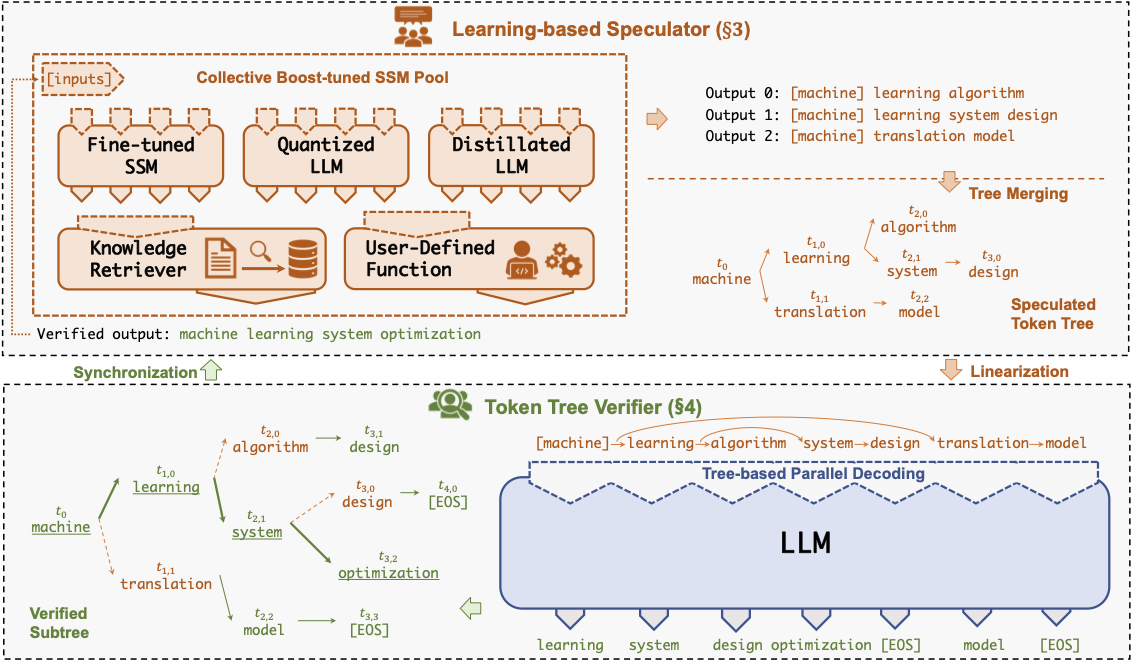 | جيثب ورق |
نماذج لغة البث الفعالة مع مغسلة الانتباه Guangxuan Xiao ، Yuandong Tian ، Beidi Chen ، Song Han ، Mike Lewis | 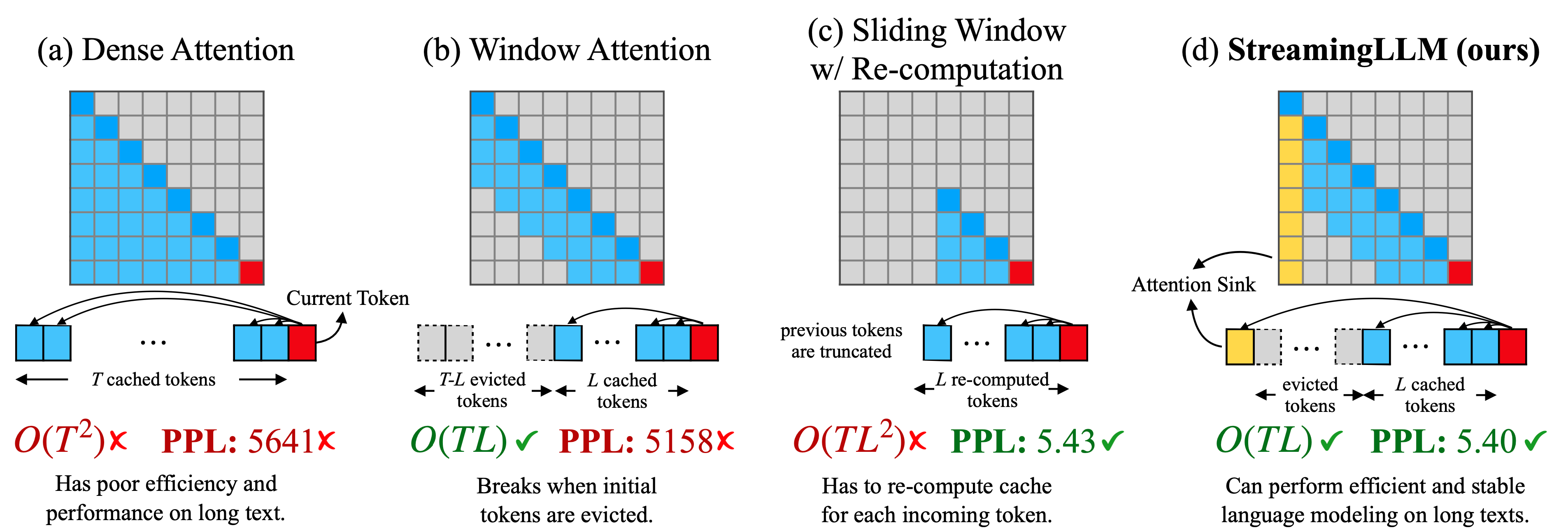 | جيثب ورق |
النسر: تسارع لا يهدأ من فك تشفير LLM عن طريق استقراء الميزة Yuhui Li و Chao Zhang و Hongyang Zhang | 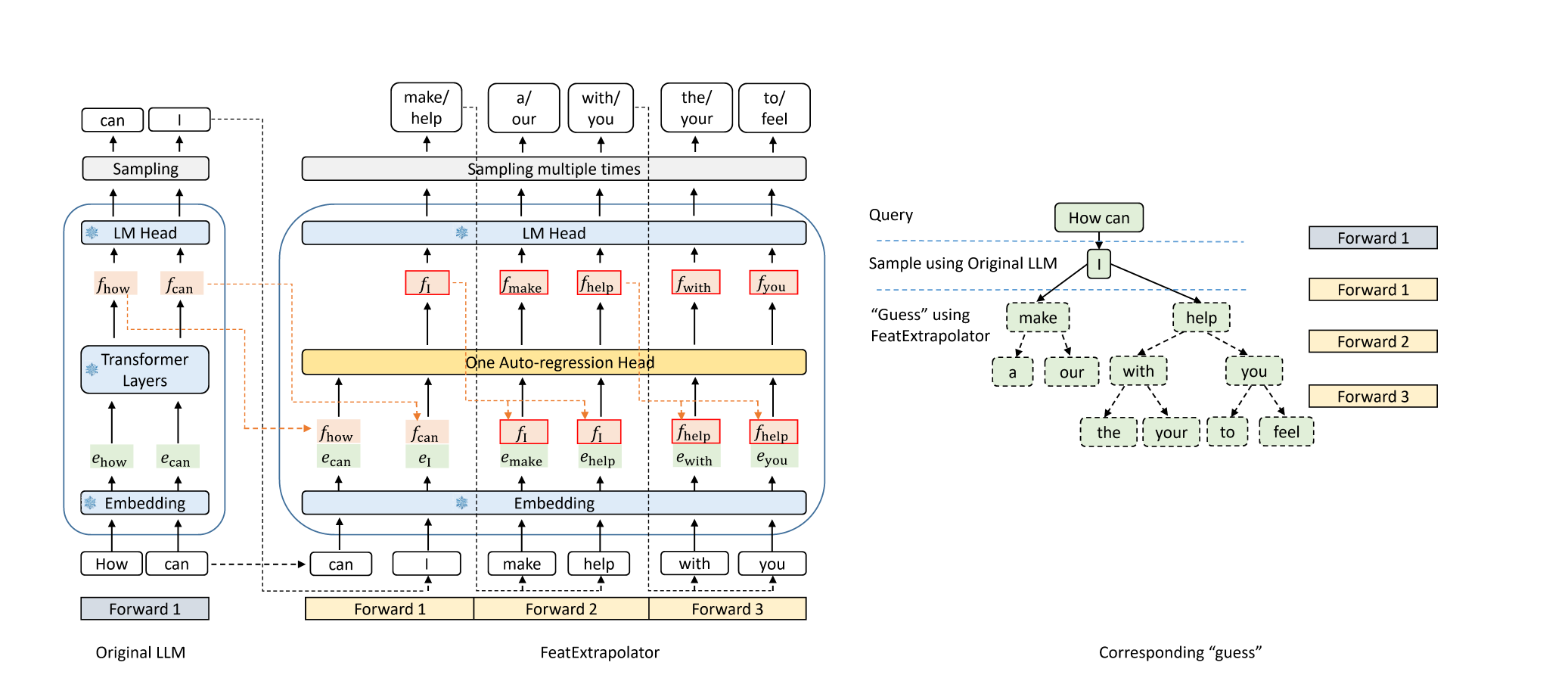 | جيثب مدونة |
ميدوسا: إطار تسريع للاستدلال البسيط LLM برؤوس فك التشفير متعددة Tianle Cai ، Yuhong Li ، Zhengyang Geng ، Hongwu Peng ، Jason D. Lee ، Deming Chen ، Tri Dao | جيثب ورق | |
| فك تشفير المضاربة مع نموذج مسودة قائم على CTC لتسريع استدلال LLM Zhuofan Wen ، Shangtong Gui ، Yang Feng | ورق | |
| PLD+: تسريع الاستدلال LLM عن طريق الاستفادة من القطع الأثرية النموذجية اللغوية Shwetha Somasundaram ، Anirudh Phukan ، Apoorv Saxena | ورق | |
fastdraft: كيفية تدريب مسودتك أورير زافرير ، إيغور مارغوليس ، دورين شتيمان ، جاي بودوخ | ورق | |
SMOA: تحسين نماذج لغة كبيرة متعددة العوامل مع مزيج متناثر من العوامل Dawei Li ، Zhen Tan ، Peijia Qian ، Yifan Li ، Kumar Satvik Chaudhary ، Lijie Hu ، Jiayi Shen | 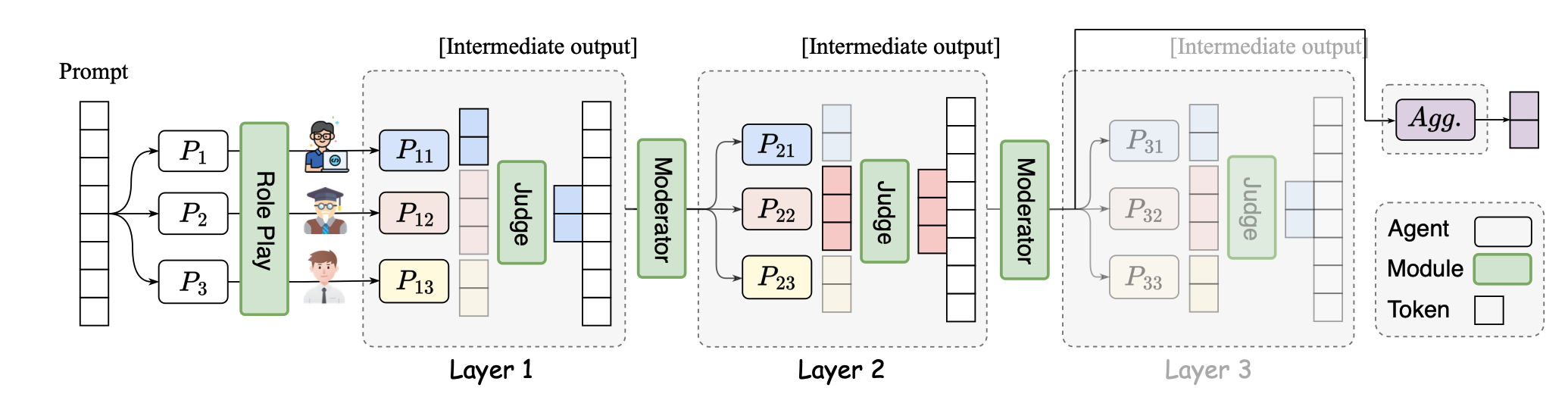 | جيثب ورق |
| N-Grammys: تسريع الاستدلال التلقائي مع المضاربة المدمجة خالية من التعلم لورانس ستيوارت ، ماثيو تراير ، سوجان كومار غونوغوندلا ، ستيفانو ساتو | ورق | |
| تسارع الاستدلال من الذكاء الاصطناعي عبر طرق التنفيذ الديناميكية Haim Barad ، Jascha Achterberg ، Tien Pei Chou ، Jean Yu | ورق | |
| FuckDecoding: نهج خالي من النماذج لتسريع استدلال نموذج اللغة الكبير غابرييل أوليارو ، تشايهاو جيا ، دانييل كامبوس ، أوريك تشياو | ورق | |
| التخطيط للاستراتيجية الديناميكية للإجابة على أسئلة فعالة مع نماذج لغة كبيرة Tanmay Parekh ، Pradyot Prakash ، Alexander Radovic ، Akshay Shekher ، Denis Savenkov | ورق | |
Magicpig: أخذ العينات LSH لتوليد LLM فعال Zhuoming Chen ، Ranajoy Sadhukhan ، Zihao Ye ، Yang Zhou ، Jianyu Zhang ، Niklas Nolte ، Yuandong Tian ، Matthijs Douze ، Leon Bottou ، Zhihao Jia ، Beidi Chen | جيثب ورق | |
| نماذج لغوية أسرع ذات تنبؤات متعددة الأعمدة باستخدام تحلل الموتر Artem Basharin ، Andrei Chertkov ، Ivan Oseledets | 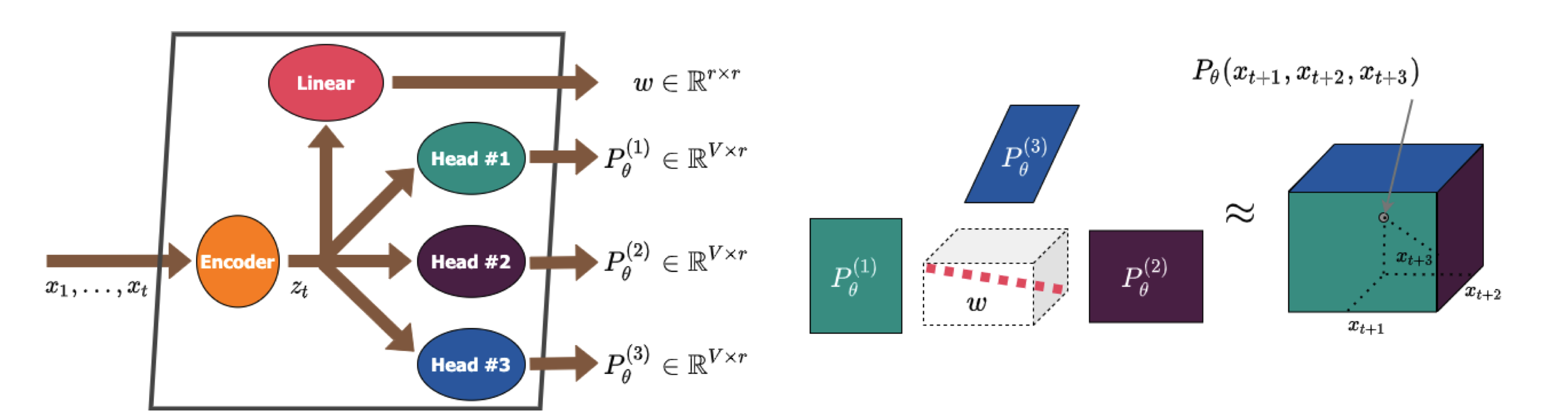 | ورق |
| الاستدلال الفعال لنماذج اللغة الكبيرة المعززة رنا شاهوت ، كونغ ليانغ ، شيجي شين ، تشيانو لاو ، يونغ كوي ، مينلان يو ، مايكل ميتزينماشر | ورق | |
تقشير المفردات الديناميكية في LLMS Exit-Exit Jort Vincenti ، Karim Abdel Sadek ، Joan Velja ، Matteo Nulli ، Metod Jazbec |  | جيثب ورق |
Coreinfer: تسريع استنتاج نموذج اللغة الكبير مع التنشيط المتفرق المستوحى من الدلالات Qinsi Wang ، Saeed Vahidian ، Hancheng Ye ، Jianyang Gu ، Jianyi Zhang ، Yiran Chen | جيثب ورق | |
الثنائي: استنتاج فعال LLM LLM مع رؤوس الاسترجاع والبث Guangxuan Xiao ، Jiaming Tang ، Jingwei Zuo ، Junxian Guo ، Shang Yang ، Haotian Tang ، Yao Fu ، Song Han | 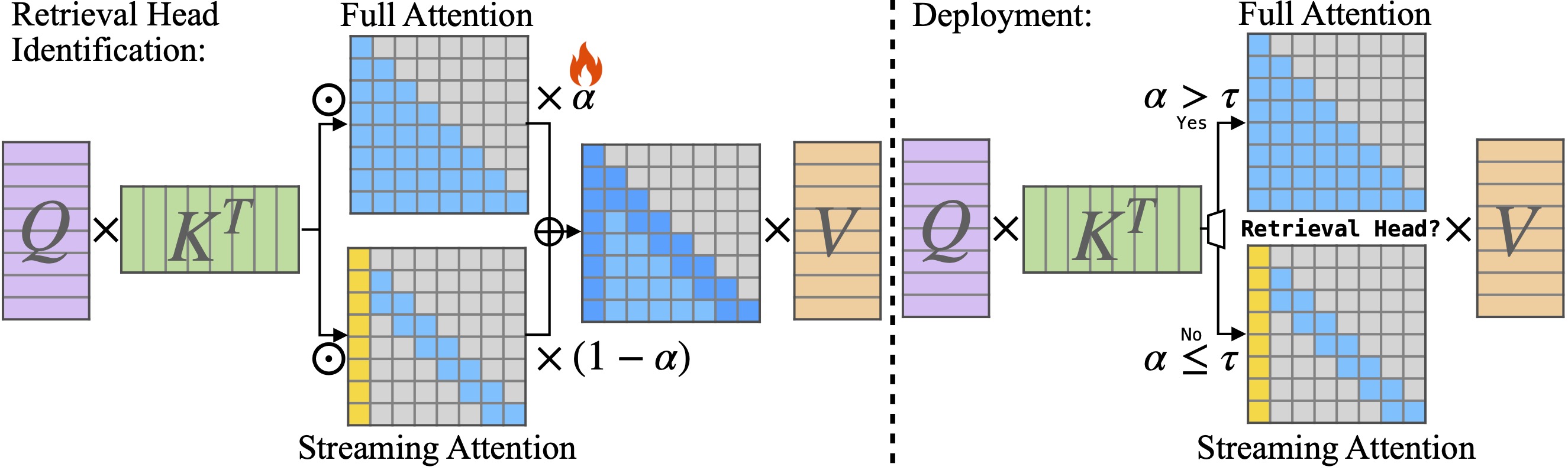 | جيثب ورق |
| Dyspec: فك تشفير المضاربة بشكل أسرع مع بنية شجرة رمزية ديناميكية Yunfan Xiong ، Ruoyu Zhang ، Yanzeng Li ، Tianhao Wu ، Lei Zou | ورق | |
| QSPEC: فك تشفير المضاربة مع مخططات القياس التكميلي Juntao Zhao ، Wenhao Lu ، Sheng Wang ، Lingpeng Kong ، Chuan Wu | ورق | |
| TidaldEcode: فك تشفير LLM سريع ودقيق مع الاهتمام المستمر المستمر Lijie Yang ، Zhihao Zhang ، Zhuofu Chen ، Zikun Li ، Zhihao Jia | ورق | |
| Parallelspec: صراخ متوازي لفك تشفير المضاربة الفعال Zilin Xiao ، Hongming Zhang ، Tao GE ، Siru Ouyang ، Vicente Ordonez ، Dong Yu | ورق | |
سويفت: فك التشفير الذاتي للذات لتسريع الاستدلال LLM Heming Xia ، Yongqi Li ، Jun Zhang ، Cunxiao Du ، Wenjie Li |  | جيثب ورق |
Turborag: تسريع جيل من أجل الاسترجاع مع ذاكرة التخزين المؤقت KV محسوبة للنص المكثف Songshuo Lu ، Hua Wang ، Yutian Rong ، Zhi Chen ، Yaohua Tang | 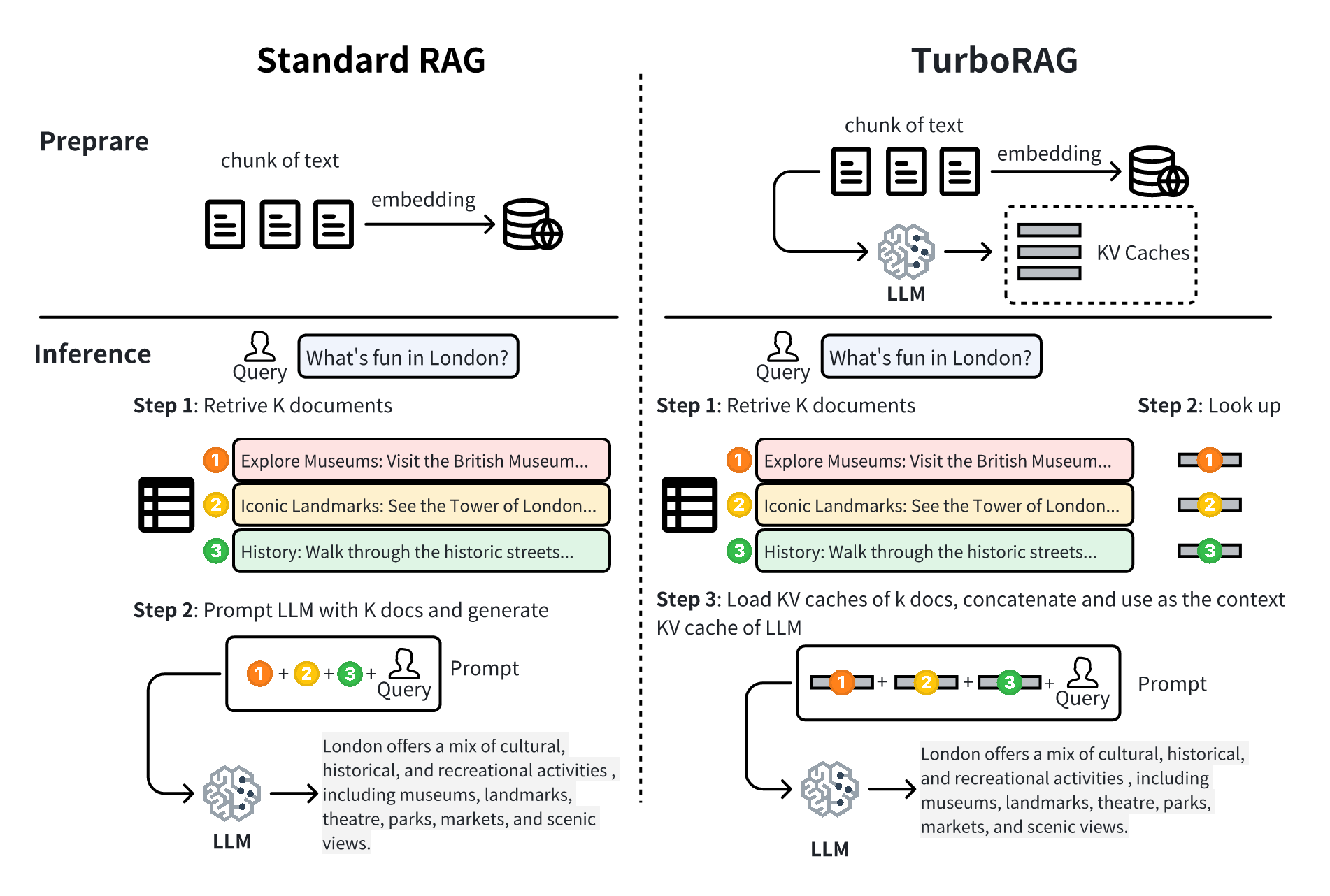 | جيثب ورق |
| قليلا يقطع شوطا طويلا: التدريب على السياق الطويل الفعال والاستدلال مع السياقات الجزئية Suyu Ge ، Xihui Lin ، Yunan Zhang ، Jiawei Han ، Hao Peng | ورق | |
| Mnemosyne: استراتيجيات التوازي لتقديم طلبات الاستدلال LLM بطول سياق متعدد ملايين الملايين amey Agrawal ، Junda Chen ، íñigo Goiri ، Ramachandran Ramjee ، Chaojie Zhang ، Alexey Tumanov ، Esha Choukse | ورق | |
اكتشاف الأحجار الكريمة في الطبقات المبكرة: تسريع LLMS LLMS مع تخفيض رمز إدخال 1000X Zhenmei Shi ، Yifei Ming ، Xuan-Phi Nguyen ، Yingyu Liang ، Shafiq Joty | جيثب ورق | |
| فك تشفير شعاع المضاربة الديناميكي لاستنتاج LLM الفعال Zongyue Qin ، Zifan He ، Neha Prakriya ، Jason Cong ، Yizhou Sun | ورق | |
critiprefill: نهج قائم على الحكم في القطاع للتسارع المسبق في LLMS Junlin LV ، Yuan Feng ، Xike Xie ، Xin Jia ، Qirong Peng ، Guiming Xie | جيثب ورق | |
| الاسترجاع: تسريع استنتاج LLM طويل السياق عبر استرجاع المتجه Di Liu ، Meng Chen ، Baotong Lu ، Huiqiang Jiang ، Zhenhua Han ، Qianxi Zhang ، Qi Chen ، Chengruidong Zhang ، Bailu Ding ، Kai Zhang ، Chen Chen ، Fan Yang ، Yuqing Yang ، Lili Qiu | ورق | |
سيريوس: تباين في السياق مع تصحيح LLMs الفعالة يانغ تشو ، تشوومنغ تشن ، تشوهوزو شو ، فيكتوريا لين ، بيدي تشن | جيثب ورق | |
Onegen: جيل موحد فعال من تمرير واحد واسترجاع لـ LLMS Jintian Zhang ، Cheng Peng ، Mengshu Sun ، Xiang Chen ، Lei Liang ، Zhiqiang Zhang ، Jun Zhou ، Huajun Chen ، Ningyu Zhang | 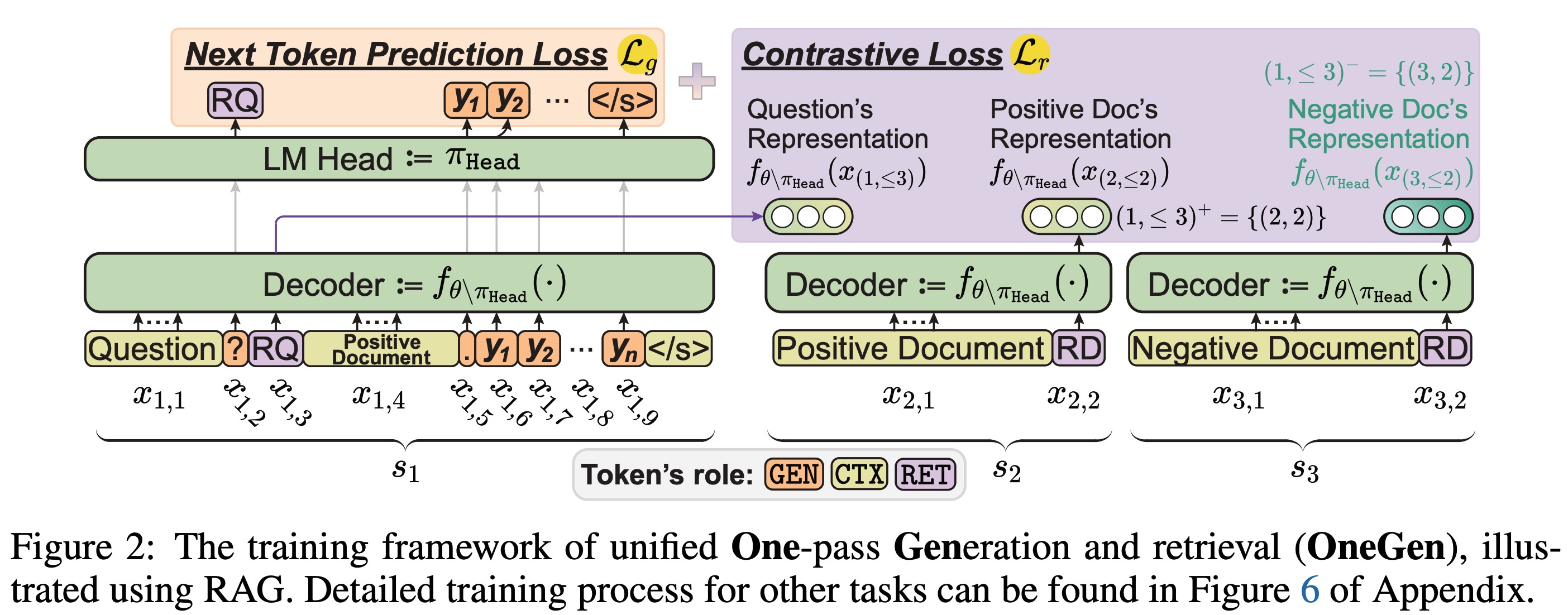 | جيثب ورق |
| التناثر المسار: بادئة تعزيز للاستدلال الفعال في LLM Jiace Zhu ، Yingtao Shen ، Jie Zhao ، Zou | ورق | |
| زيادة فك تشفير المضاربة بدون فقدان عن طريق أخذ العينات وتقطير المحاذاة الجزئي Lujun Gui ، Bin Xiao ، Lei Su ، Weipeng Chen | ورق |
| العنوان والمؤلفين | مقدمة | الروابط |
|---|---|---|
الاستدلال السريع لنماذج لغة الخبراء المزيج مع تفريغ Artyom Eliseev ، دينيس مازور |  | جيثب ورق |
تكثيف ، لا تقلم فقط: تعزيز الكفاءة والأداء في تشذيب طبقة Moe Mingyu Cao ، Gen Li ، Jie Ji ، Jiaqi Zhang ، Xiaolong MA ، Shiwei Liu ، Lu Yin | جيثب ورق | |
| مزيج من خبراء ذاكرة التخزين المؤقت لاستدلال الجهاز المحمول الفعال Andrii Skliar ، Ties Van Rozendaal ، Romain Lepert ، Todor Boinovski ، Mart Van Baalen ، Markus Nagel ، Paul Whatmough ، Babak Ehteshami Bejnordi | ورق | |
مونتا: تدريب مزيج من الخبراء مع التحسين الموازي مع TRAFFC Jingming Guo ، Yan Liu ، Yu Meng ، Zhiwei Tao ، Banglan Liu ، Gang Chen ، Xiang Li | جيثب ورق | |
MOE-I2: ضغط مزيج من نماذج الخبراء من خلال التقليم بين الخبرة والتحلل منخفضة الرتبة داخل الخبرة Cheng Yang ، Yang Sui ، Jinqi Xiao ، Lingyi Huang ، Yu Gong ، Yuanlin Duan ، Wenqi Jia ، Miao Yin ، Yu Cheng ، Bo Yuan | جيثب ورق | |
| Hobbit: نظام تفريغ خبير مختلط لاستنتاج MOE السريع Peng Tang ، Jiacheng Liu ، Xiaofeng Hou ، Yifei Pu ، Jing Wang ، Pheng-Ann Heng ، Chao Li ، Minyi Guo | ورق | |
| Promoe: LLM Fast Moe المستند إلى Moe يخدم باستخدام التخزين المؤقت الاستباقي أغنية Xiaoniu ، Zihang Zhong ، Rong Chen | ورق | |
| الخبراء: تنشيط الخبراء المحسّن وتخصيص الرمز المميز لاستدلال الخبرة الفعال شين هو ، شونكانغ تشانغ ، يوكسين وانغ ، هايان يين ، زيهاو زنغ ، شوهواي شي ، تشينينغ تانغ ، شياووين تشو ، إيفور تسانغ ، أونج يو قريباً | ورق | |
| EPS-MOE: جدولة خطوط أنابيب خبراء لاستنتاج وزارة الأملاك الموفرة من حيث التكلفة Yulei Qian ، Fengcun Li ، Xiangyang Ji ، Xiaoyu Zhao ، Jianchao Tan ، Kefeng Zhang ، Xunliang Cai | ورق | |
MC-MOE: ضاغط الخليط لخليط الخبراء LLMS يكسب المزيد Wei Huang ، Yue Liao ، Jianhui Liu ، Ruifei He ، Haoru Tan ، Shiming Zhang ، Hongsheng Li ، Si Liu ، Xiaojuan Qi |  | جيثب ورق |
| العنوان والمؤلفين | مقدمة | الروابط |
|---|---|---|
موبيلاما: نحو GPT دقيق وخفيف الوزن تمامًا Omkar Thawakar ، Ashmal Vayani ، Salman Khan ، Hisham Cholakal ، Rao M. Anwer ، Michael Felsberg ، Tim Baldwin ، Eric P. Xing ، Fahad Shahbaz Khan |  | جيثب ورق نموذج |
Megalodon: pretring pretring و repative كفاءة مع طول سياق غير محدود Xuezhe MA ، Xiaomeng Yang ، Wenhan Xiong ، Beidi Chen ، Lili Yu ، Hao Zhang ، Jonathan May ، Luke Zettlemoyer ، Omer Levy ، Chunting Zhou | 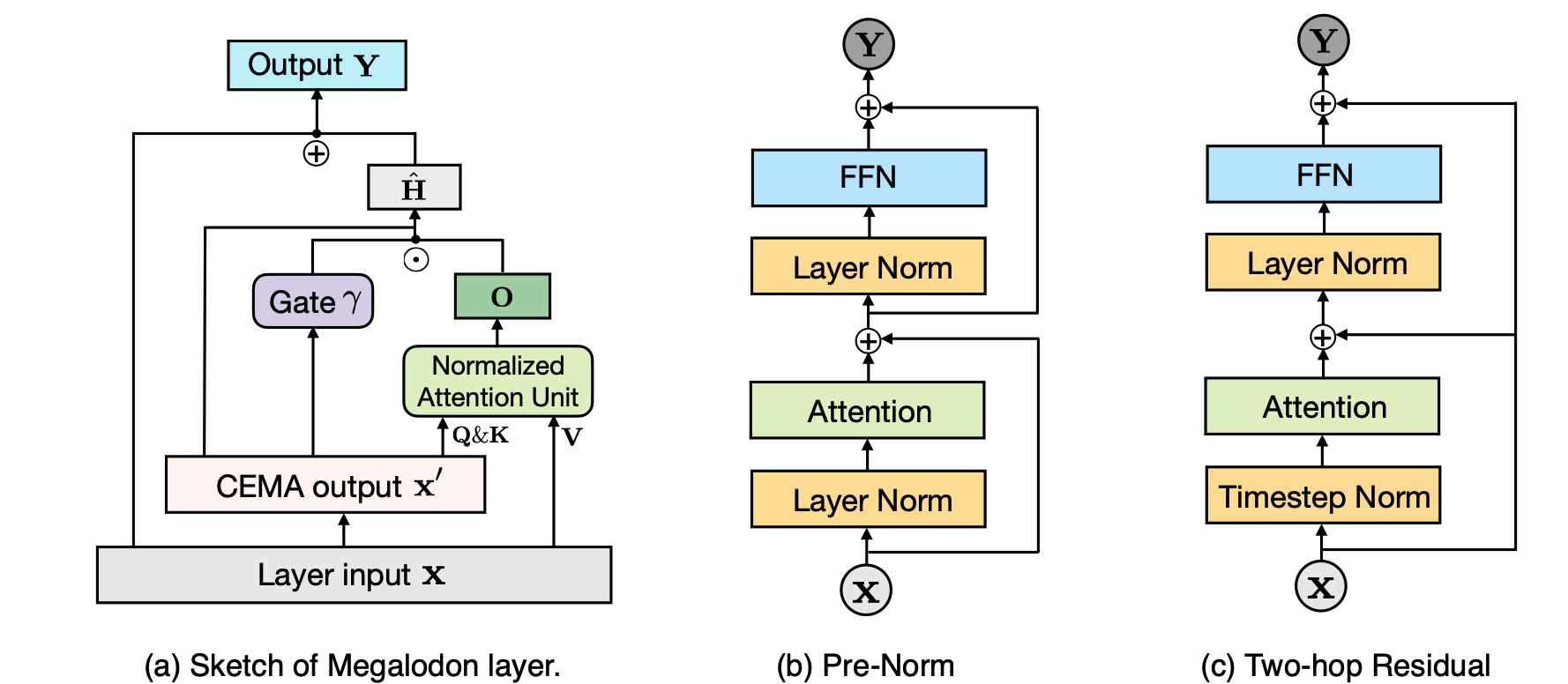 | جيثب ورق |
| تايبان: نماذج لغة الفضاء الفعالة والتعبيرية مع اهتمام انتقائي شين فان نغوين ، هوي هوو نغوين ، ثانغ م. فام ، رويي تشانغ ، هانيه ديلامساليه ، بونيت ماثور ، ريان روسي ، ترونج بوي ، فييت داك لاي ، فرانك ديرنكورت ، ثين هويو نغوين. | ورق | |
Seerattention: تعلم الاهتمام المتناثر الجوهري في LLMS الخاص بك Yizhao Gao ، Zhichen Zeng ، Dayou Du ، Shijie Cao ، Hayden Kwok-Hay So ، Ting Cao ، Fan Yang ، Mao Yang | جيثب ورق | |
مشاركة الأساس: مشاركة معلمات الطبقة المتقاطعة لضغط نموذج اللغة الكبير Jingcun Wang ، Yu-Guang Chen ، Eng-Chao Lin ، Bing Li ، La Li Zhang | جيثب ورق | |
| روديموس*: كسر مفاضلة دقة الكفاءة مع الاهتمام الفعال Zhihao He ، Hang Yu ، Zi Gong ، Shizhan Liu ، Jianguo Li ، Weiyao Lin | ورق |
| العنوان والمؤلفين | مقدمة | الروابط |
|---|---|---|
| يخبرك النموذج بما يجب تجاهله: ضغط ذاكرة التخزين المؤقت KV التكيفية لـ LLMS Suyu GE ، Yunan Zhang ، Liyuan Liu ، Minjia Zhang ، Jiawei Han ، Jianfeng Gao | 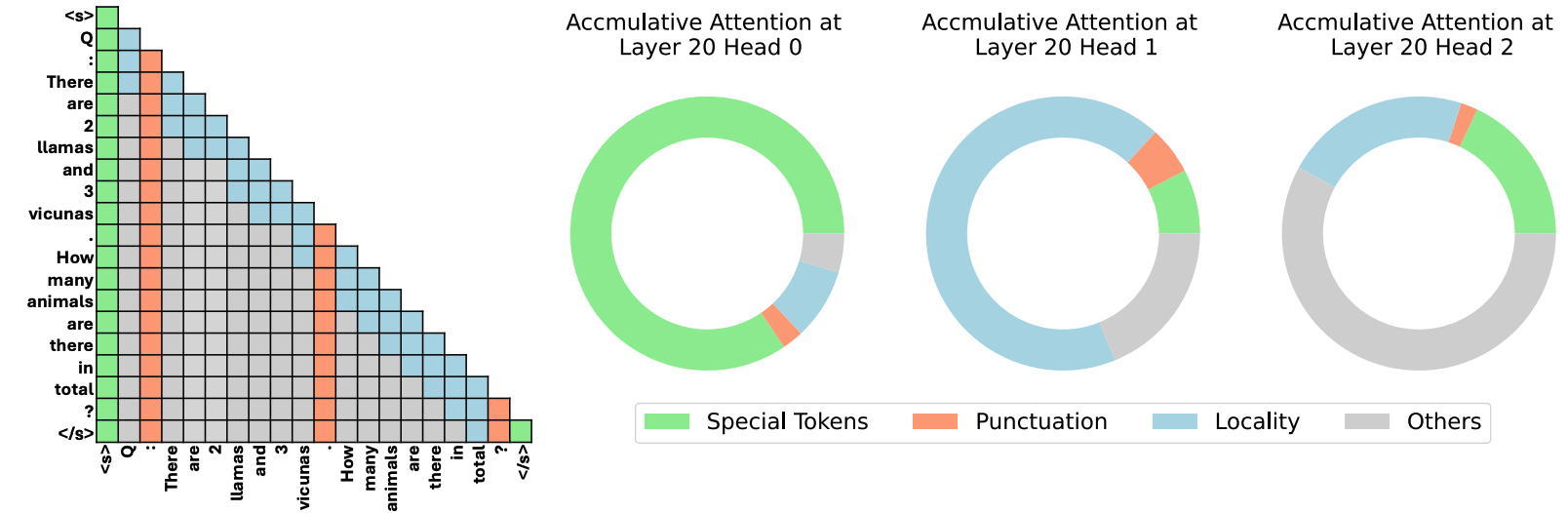 | ورق |
| ClusterKV: معالجة ذاكرة التخزين المؤقت LLM KV في الفضاء الدلالي لضغط قابلة للاستدعاء Guangda Liu ، Chengwei Li ، Jieru Zhao ، Chenqi Zhang ، Minyi Guo | ورق | |
| توحيد ضغط ذاكرة التخزين المؤقت KV لنماذج اللغة الكبيرة مع Leankv Yanqi Zhang ، Yuwei Hu ، Runyuan Zhao ، John CS Lui ، Haibo Chen | ورق | |
| ضغط ذاكرة التخزين المؤقت KV لاستنتاج LLM طويل السياق مع تشابه انتباه الطبقة Da Ma ، Lu Chen ، Situo Zhang ، Yuxun Miao ، Su Zhu ، Zhi Chen ، Hongshen Xu ، Hanqi Li ، Shuai Fan ، Lei Pan ، Kai Yu | ورق | |
| Minikv: دفع حدود استنتاج LLM عبر ذاكرة التخزين المؤقت KV ذات الطبقة 2 بت أكشات شارما ، هانغليانغ دينغ ، جيانغ لي ، نيل داني ، مينجيا تشانغ | ورق | |
| الرموز المتصلة: استنتاج سياق طويل فعال واستقراء طول لـ LLMS عبر اختيار ذاكرة التخزين المؤقت على مستوى الرمز المميز الديناميكي Wei Wu ، Zhuoshi Pan ، Chao Wang ، Liyi Chen ، Yunchu Bai ، Kun Fu ، Zheng Wang ، Hui Xiong | ورق | |
لا يهم جميع الرؤوس: طريقة ضغط ذاكرة التخزين المؤقت على مستوى الرأس KV مع استرجاع وتفكير متكامل Yu Fu ، Zefan Cai ، Abedelkadir Asi ، Wayne Xiong ، Yue Dong ، Wen Xiao | 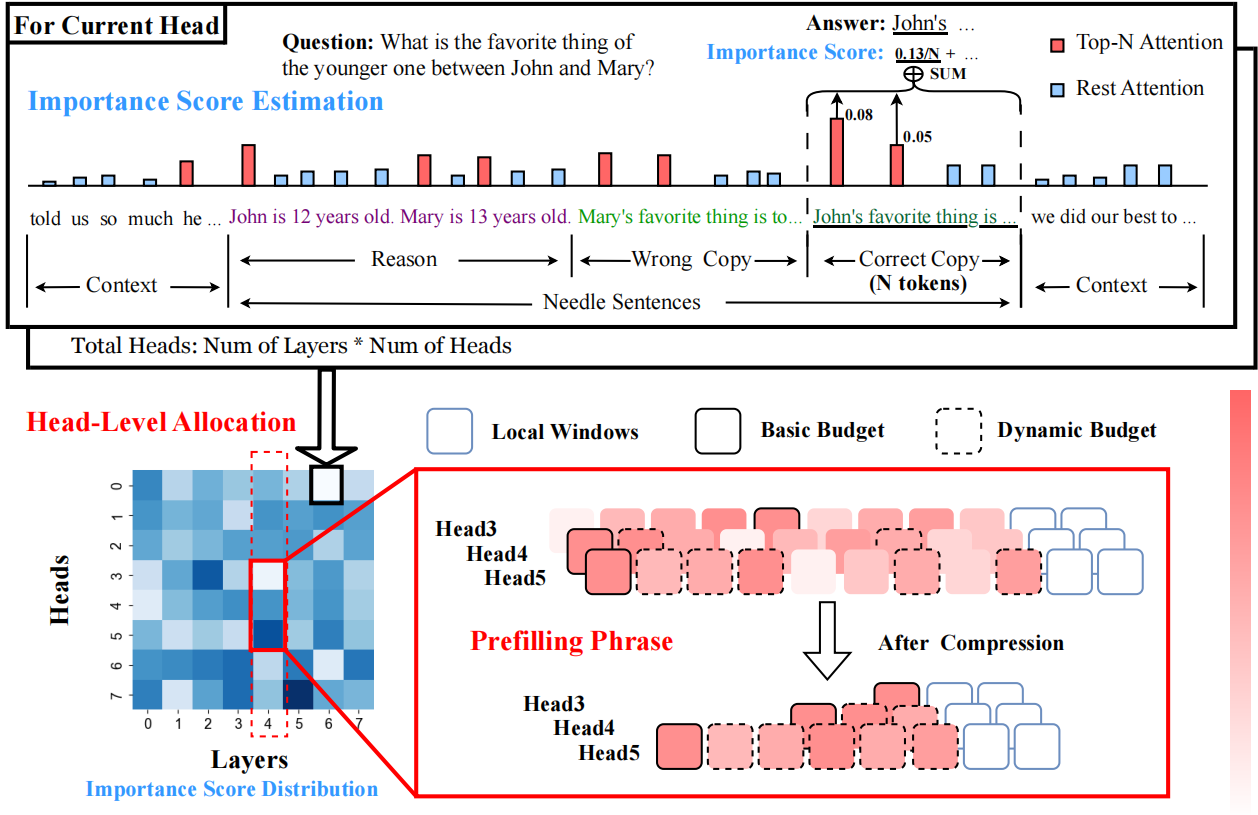 | جيثب ورق |
Buzz: ذاكرة التخزين المؤقت المتفرقة من Beehive منظمة Junqi Zhao ، Zhijin Fang ، Shu Li ، Shaohui Yang ، Shicha He | جيثب ورق | |
دراسة منهجية لمشاركة KV للطبقة المتقاطعة لاستنتاج LLM الفعال أنت wu ، haoyi wu ، kewei tu | 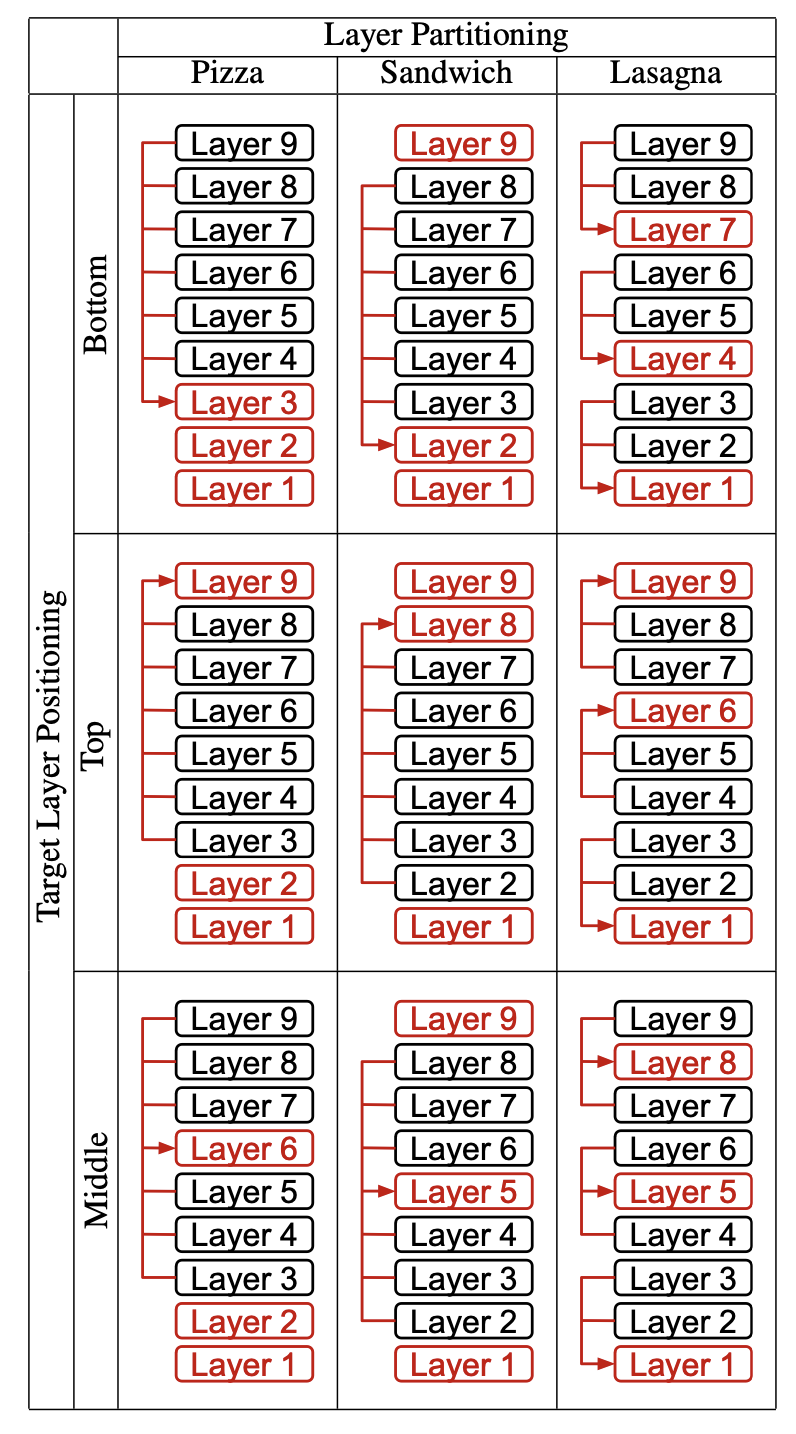 | جيثب ورق |
| ضغط ذاكرة التخزين المؤقت KV بدون خسارة إلى 2 ٪ Zhen Yang ، Jnhan ، Kan Wu ، Ruobing Xie ، An Wang ، Xingwu Sun ، Zhanhui Kang | ورق | |
| Matryoshkakv: ضغط KV التكيفي عن طريق الإسقاط المتعامد القابل للتدريب Bokai Lin ، Zihao Zeng ، Zipeng Xiao ، Siqi Kou ، Tianqi Hou ، Xiaofeng Gao ، Hao Zhang ، Zhijie Deng | ورق | |
كمية المتجه المتبقية لضغط ذاكرة التخزين المؤقت KV في نموذج اللغة الكبيرة أنكور كومار | جيثب ورق | |
kvsharer: الاستدلال الفعال عبر مشاركة ذاكرة التخزين المؤقت KV متباينة الطبقة Yifei Yang ، Zouying Cao ، Qiguang Chen ، Libo Qin ، Dongjie Yang ، Hai Zhao ، Zhi Chen | 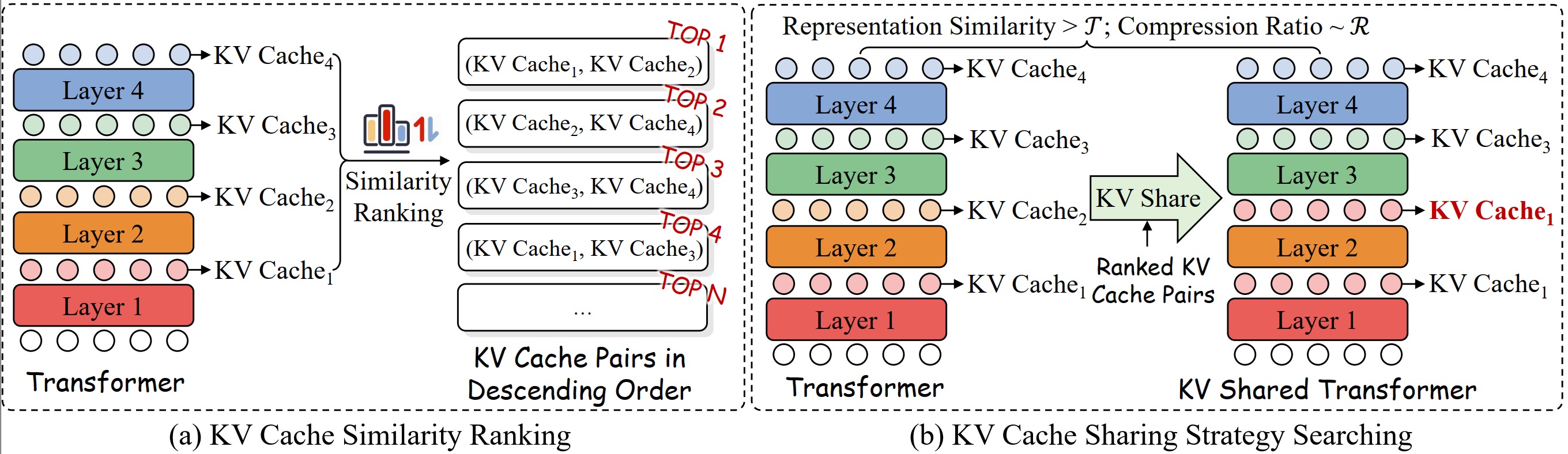 | جيثب ورق |
| LORC: ضغط منخفض الرتبة لذاكرة التخزين المؤقت LLMS KV مع استراتيجية الضغط التدريجي Rongzhi Zhang ، Kuang Wang ، Liyuan Liu ، Shuohang Wang ، Hao Cheng ، Chao Zhang ، Yelong Shen | 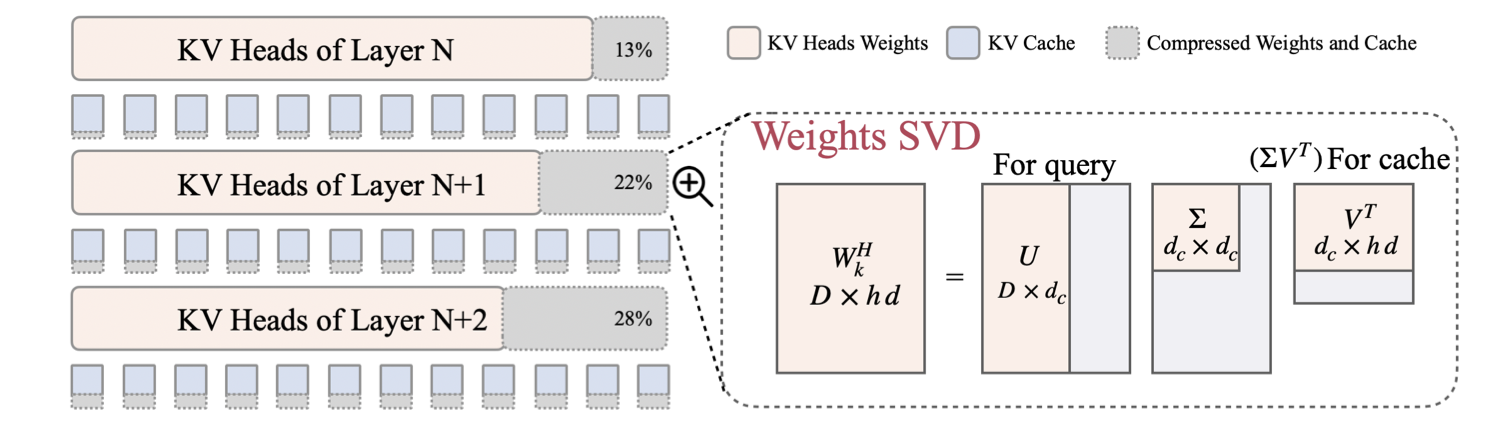 | ورق |
| SWIFTKV: الاستدلال السريع المحسّن مسبقًا مع تحول نموذج الحفاظ على المعرفة Aurick Qiao ، Zhewei Yao ، Samyam Rajbhandari ، Yuxiong He | ورق | |
ضغط الذاكرة الديناميكي: التعديل التحديثي LLMs للاستدلال المتسارع Piotr Nawrot ، Adrian łańcucki ، Marcin Chochowski ، David Tarjan ، Edoardo M. Ponti | 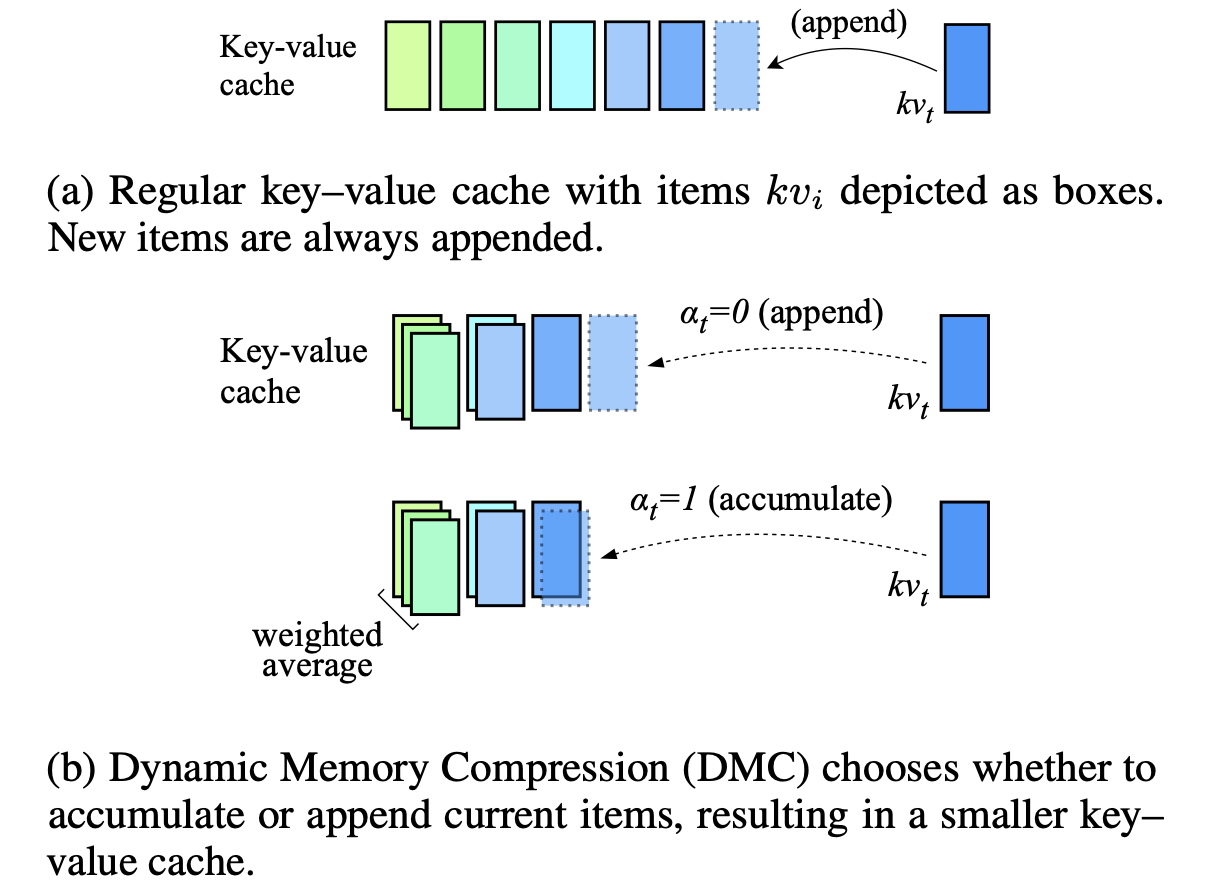 | ورق |
| KV-COSSING: ضغط كيلو فايم باجس مع معدلات ضغط متغيرة لكل رأس اهتمام إسحاق ريج | ورق | |
ADA-KV: تحسين إخلاء ذاكرة التخزين المؤقت KV عن طريق تخصيص الميزانية التكيفية لاستنتاج LLM الفعال Yuan Feng ، Junlin LV ، Yukun Cao ، Xike Xie ، S. Kevin Zhou | 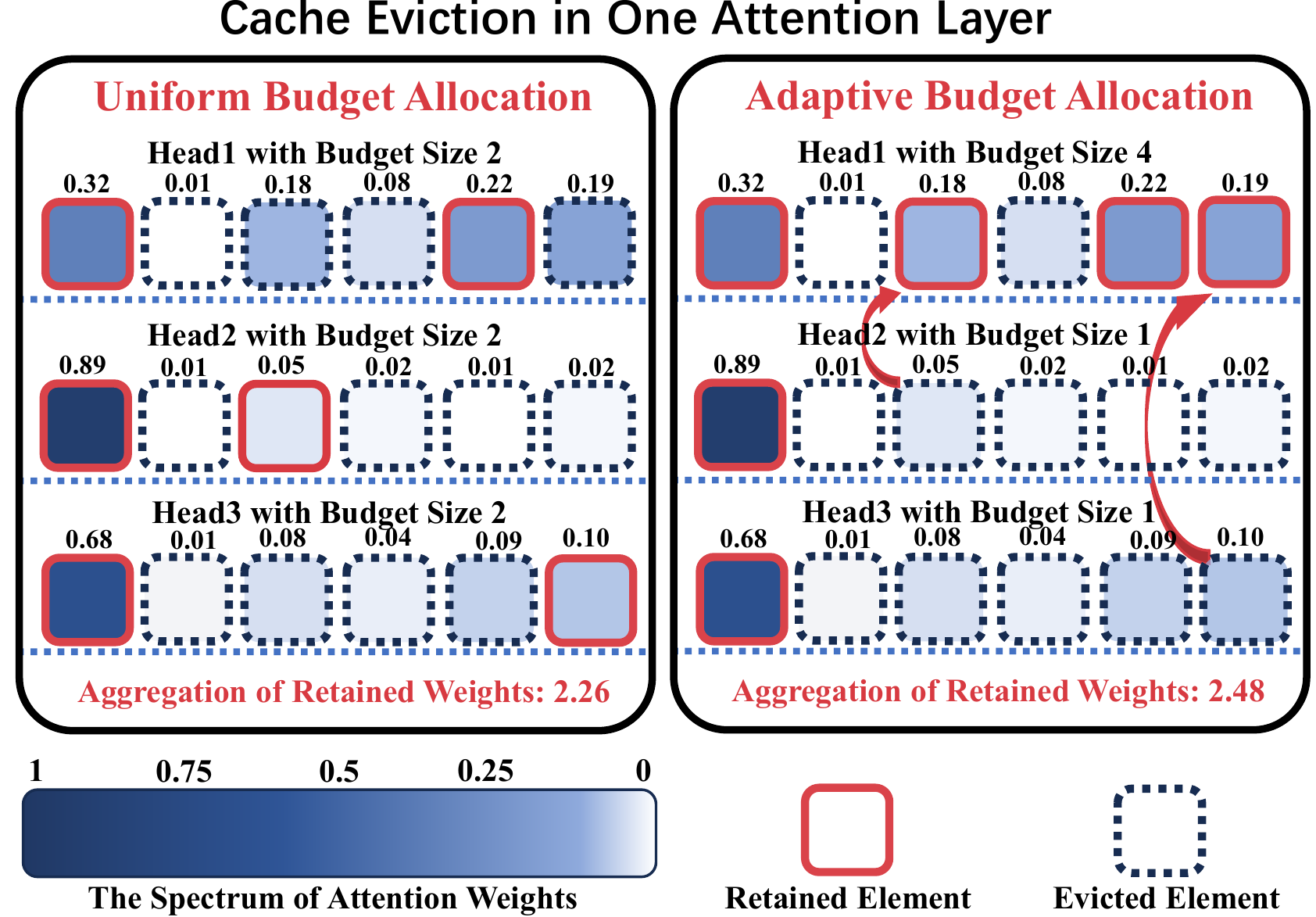 | جيثب ورق |
محاذاة: تقليل وصول الذاكرة من خدم KV مع القياس الدقيق المحاذاة ييفان تان ، هاوزي وانغ ، تشاو يان ، يانغدونغ دنغ | جيثب ورق | |
| CSKV: تقلص قناة فعالة للتدريب لذاكرة التخزين المؤقت KV في سيناريوهات السياق الطويل Luning Wang ، Shiyao Li ، Xuefei Ning ، Zhihang Yuan ، Shengen Yan ، Guohao Dai ، Yu Wang | ورق | |
| نظرة أولى على استنتاج LLM الفعال والآمن على الجهاز ضد تسرب KV Huan Yang ، Deyu Zhang ، Yudong Zhao ، Yuanchun Li ، Yunxin Liu | ورق |
| العنوان والمؤلفين | مقدمة | الروابط |
|---|---|---|
llmlingua: ضغط المطالبات للاستدلال المتسارع لنماذج اللغة الكبيرة Huiqiang Jiang ، Qianhui Wu ، Chin-Yew Lin ، Yuqing Yang ، Lili Qiu | 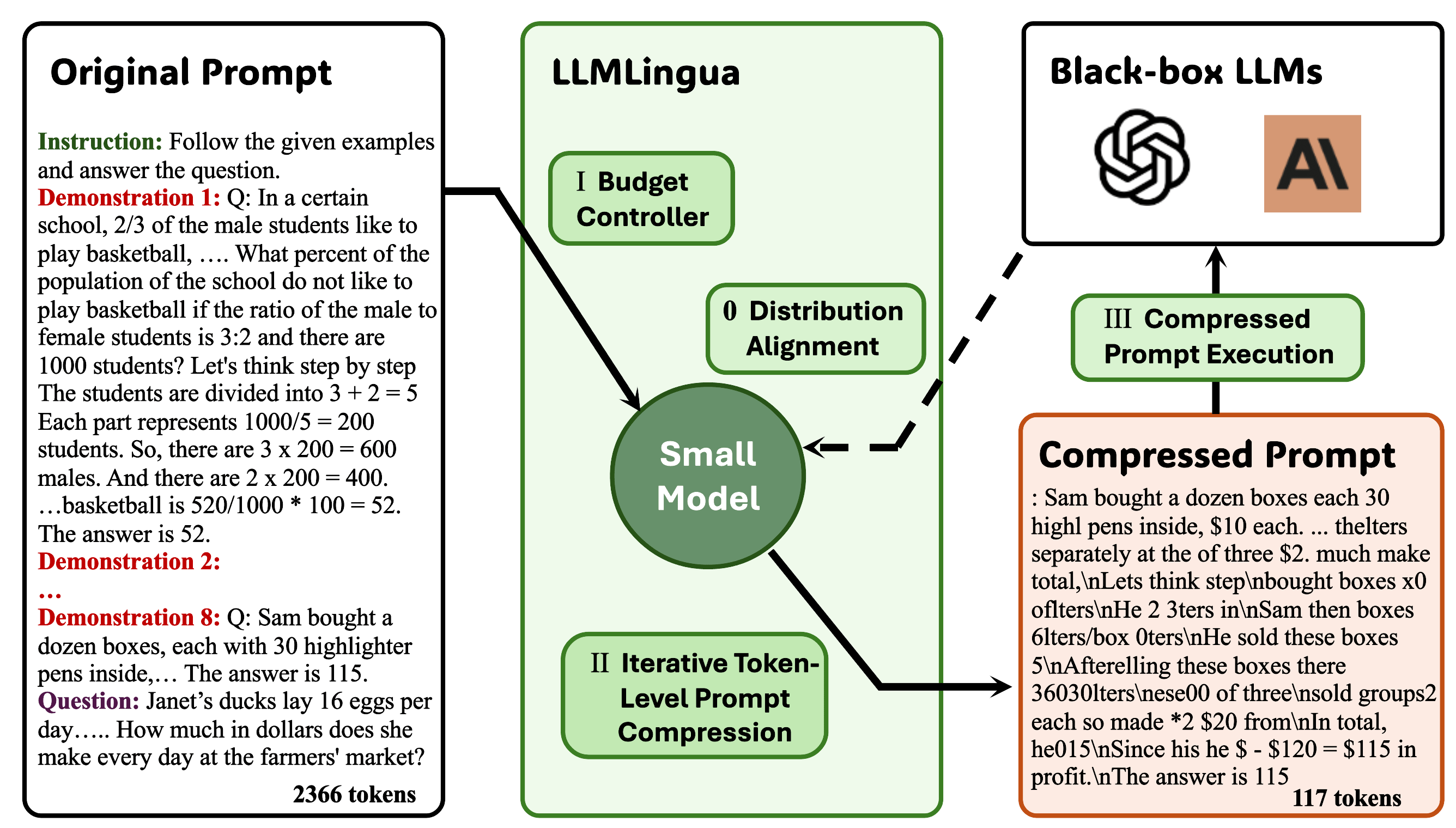 | جيثب ورق |
Longllmlingua: تسريع وتعزيز LLMs في سيناريوهات السياق الطويل عن طريق الضغط الفوري Huiqiang Jiang ، Qianhui Wu ، Xufang Luo ، Dongsheng Li ، Chin-Yew Lin ، Yuqing Yang ، Lili Qiu | 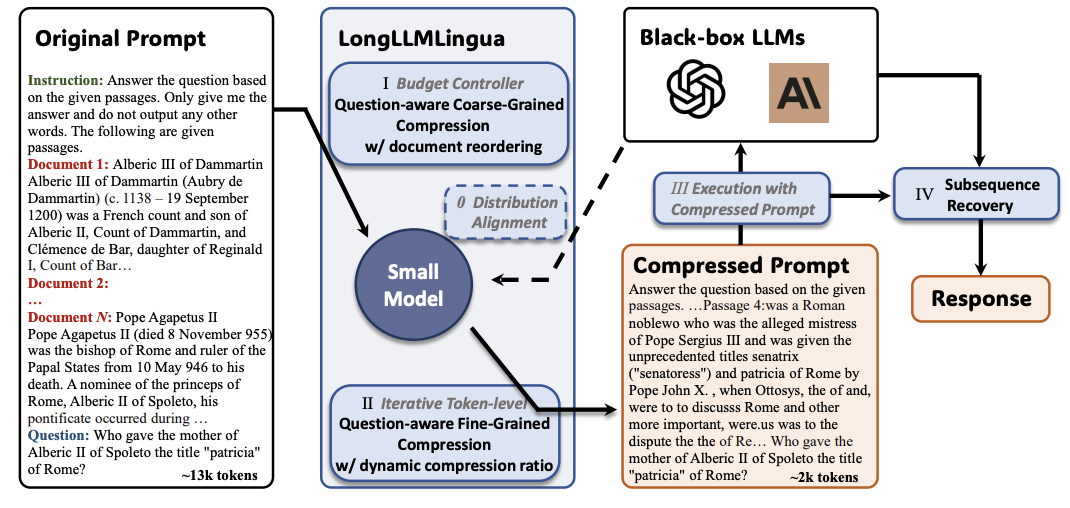 | جيثب ورق |
| JPPO: القوة المشتركة والتحسين السريع لخدمات نموذج اللغة الكبيرة المتسارعة Feiran You ، Hongyang du ، Kaibin Huang ، Abbas Jamalipour | ورق | |
التقطير السياق التوليدي Haebin Shin ، Lei Ji ، Yeyun Gong ، Sungdong Kim ، Eunbi Choi ، Minjoon SEO | | جيثب ورق |
Multitok: رمزية متغيرة الطول ل LLMs الفعالة مقتبسة من ضغط LZW نويل إلياس ، هوما إسباهانيزاده ، كان كال ، سريرام فيشواناث ، مورييل ميدارد | جيثب ورق | |
الاختيار-P: ضغط فوري من المهام الخاضعة للإشراف ذاتيا على الإخلاص وقابلية النقل Tsz Ting Chung ، Leyang Cui ، Lemao Liu ، Xinting Huang ، Shuming Shi ، Dit-Yan Yeung | ورق | |
من القراءة إلى الضغط: استكشاف القارئ متعدد الوثيقة لضغط موجه Eunseong Choi ، Sunkyung Lee ، Minjin Choi ، June Park ، Jongwuk Lee | ورق | |
| ضاغط الإدراك: طريقة ضغط موجه خالية من التدريب في سيناريوهات السياق الطويل Jiwei Tang ، Jin Xu ، Tingwei Lu ، Hai Lin ، Yiming Zhao ، Hai-Tao Zheng | ورق | |
Finezip: دفع حدود نماذج اللغة الكبيرة لضغط النص العملي بدون فقدان Fazal Mittu ، Yihuan Bu ، Akshat Gupta ، Ashok Direddy ، Alp Eren Ozdarendeli ، Anant Singh ، Gopala Anumanchipalli | جيثب ورق | |
تحليل الأشجار الموجهة LLM الضغط السريع Wenhao Mao ، Chengbin Hou ، Tianyu Zhang ، Xinyu Lin ، Ke Tang ، Hairong LV | جيثب ورق | |
ألفازيب: ضغط نص لا خسره الشبكة العصبية Swathi Shree Narashiman ، Nitin Chandrachoodan | جيثب ورق | |
| TACO-RL: تحسين الضغط على المهمات المهمية مع التعلم التعزيز شيفام شاندليا ، مينغلين شيا ، سوبريو غوش ، هويكيانغ جيانغ ، جوي تشانغ ، تشيانهوي وو ، فيكتور روهيل | ورق | |
| تقطير سياق LLM فعال Rajesh Upadhayayaya ، Zachary Smith ، Chritopher Kottmyer ، Manish Raj Osti | ورق | |
تعزيز وتسريع نماذج اللغة الكبيرة من خلال ضغط السياق على دراية بالتعليمات Haowen Hou ، Fei MA ، Binwen Bai ، Xinxin Zhu ، Fei Yu | جيثب ورق |
| العنوان والمؤلفين | مقدمة | الروابط |
|---|---|---|
الوالور الطبيعي: تسريع وفرة لتدريب LLM الموفرة للذاكرة والضبط آريجيت داس | جيثب ورق | |
| مضغوط: تنشيطات مضغوطة لتدريب LLM الموفرة للذاكرة Yara Shamshoum ، Nitzan Hodos ، Yuval Sieradzki ، عساف شوستر | ورق | |
ESPACE: تخفيض الأبعاد في تنشيط ضغط النموذج Charbel Sakr, Brucek Khailany | 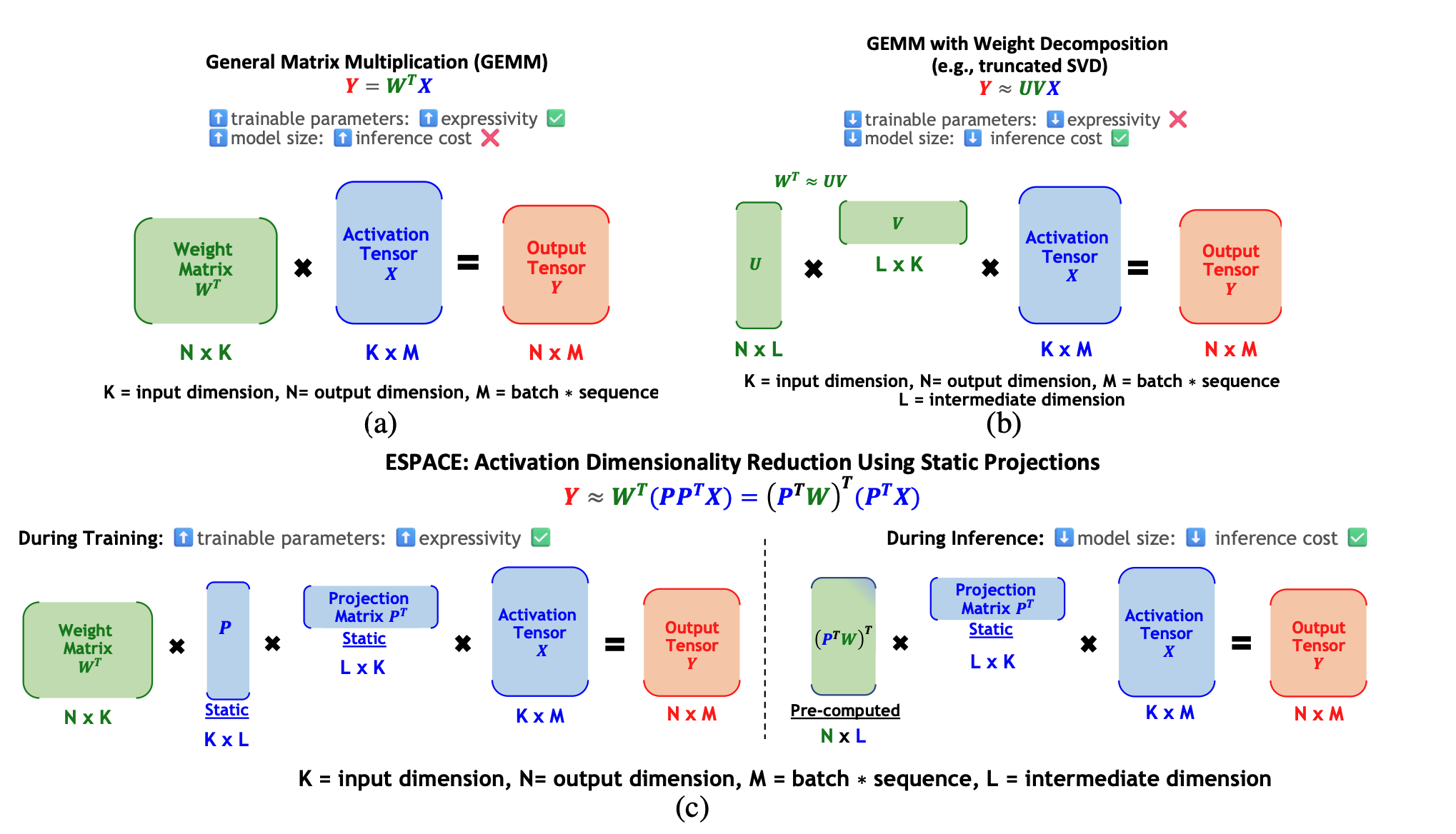 | ورق |
| Title & Authors | مقدمة | الروابط |
|---|---|---|
| FastSwitch: Optimizing Context Switching Efficiency in Fairness-aware Large Language Model Serving Ao Shen, Zhiyao Li, Mingyu Gao | ورق | |
| CE-CoLLM: Efficient and Adaptive Large Language Models Through Cloud-Edge Collaboration Hongpeng Jin, Yanzhao Wu | ورق | |
| Ripple: Accelerating LLM Inference on Smartphones with Correlation-Aware Neuron Management Tuowei Wang, Ruwen Fan, Minxing Huang, Zixu Hao, Kun Li, Ting Cao, Youyou Lu, Yaoxue Zhang, Ju Ren | ورق | |
ALISE: Accelerating Large Language Model Serving with Speculative Scheduling Youpeng Zhao, Jun Wang | ورق | |
| EPIC: Efficient Position-Independent Context Caching for Serving Large Language Models Junhao Hu, Wenrui Huang, Haoyi Wang, Weidong Wang, Tiancheng Hu, Qin Zhang, Hao Feng, Xusheng Chen, Yizhou Shan, Tao Xie | ورق | |
SDP4Bit: Toward 4-bit Communication Quantization in Sharded Data Parallelism for LLM Training Jinda Jia, Cong Xie, Hanlin Lu, Daoce Wang, Hao Feng, Chengming Zhang, Baixi Sun, Haibin Lin, Zhi Zhang, Xin Liu, Dingwen Tao | ورق | |
| FastAttention: Extend FlashAttention2 to NPUs and Low-resource GPUs Haoran Lin, Xianzhi Yu, Kang Zhao, Lu Hou, Zongyuan Zhan et al | ورق | |
| POD-Attention: Unlocking Full Prefill-Decode Overlap for Faster LLM Inference Aditya K Kamath, Ramya Prabhu, Jayashree Mohan, Simon Peter, Ramachandran Ramjee, Ashish Panwar | ورق | |
TPI-LLM: Serving 70B-scale LLMs Efficiently on Low-resource Edge Devices Zonghang Li, Wenjiao Feng, Mohsen Guizani, Hongfang Yu | Github ورق | |
Efficient Arbitrary Precision Acceleration for Large Language Models on GPU Tensor Cores Shaobo Ma, Chao Fang, Haikuo Shao, Zhongfeng Wang | ورق | |
OPAL: Outlier-Preserved Microscaling Quantization A ccelerator for Generative Large Language Models Jahyun Koo, Dahoon Park, Sangwoo Jung, Jaeha Kung | ورق | |
| Accelerating Large Language Model Training with Hybrid GPU-based Compression Lang Xu, Quentin Anthony, Qinghua Zhou, Nawras Alnaasan, Radha R. Gulhane, Aamir Shafi, Hari Subramoni, Dhabaleswar K. Panda | ورق |
| Title & Authors | مقدمة | الروابط |
|---|---|---|
| HELENE: Hessian Layer-wise Clipping and Gradient Annealing for Accelerating Fine-tuning LLM with Zeroth-order Optimization Huaqin Zhao, Jiaxi Li, Yi Pan, Shizhe Liang, Xiaofeng Yang, Wei Liu, Xiang Li, Fei Dou, Tianming Liu, Jin Lu | ورق | |
Robust and Efficient Fine-tuning of LLMs with Bayesian Reparameterization of Low-Rank Adaptation Ayan Sengupta, Vaibhav Seth, Arinjay Pathak, Natraj Raman, Sriram Gopalakrishnan, Tanmoy Chakraborty | Github ورق | |
MiLoRA: Efficient Mixture of Low-Rank Adaptation for Large Language Models Fine-tuning Jingfan Zhang, Yi Zhao, Dan Chen, Xing Tian, Huanran Zheng, Wei Zhu | ورق | |
RoCoFT: Efficient Finetuning of Large Language Models with Row-Column Updates Md Kowsher, Tara Esmaeilbeig, Chun-Nam Yu, Mojtaba Soltanalian, Niloofar Yousefi | 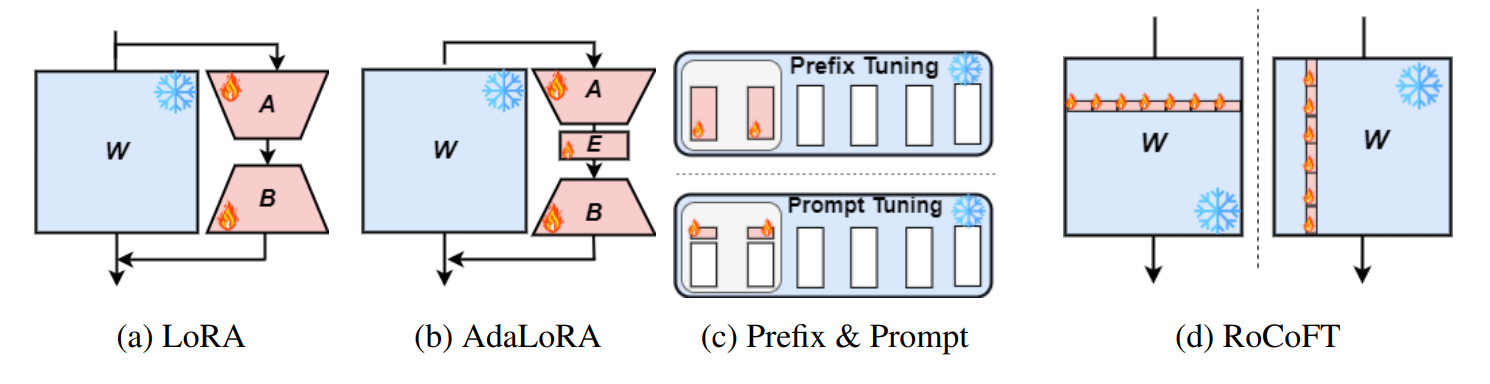 | Github ورق |
Layer-wise Importance Matters: Less Memory for Better Performance in Parameter-efficient Fine-tuning of Large Language Models Kai Yao, Penlei Gao, Lichun Li, Yuan Zhao, Xiaofeng Wang, Wei Wang, Jianke Zhu | Github ورق | |
Parameter-Efficient Fine-Tuning of Large Language Models using Semantic Knowledge Tuning Nusrat Jahan Prottasha, Asif Mahmud, Md. Shohanur Islam Sobuj, Prakash Bhat, Md Kowsher, Niloofar Yousefi, Ozlem Ozmen Garibay | ورق | |
QEFT: Quantization for Efficient Fine-Tuning of LLMs Changhun Lee, Jun-gyu Jin, Younghyun Cho, Eunhyeok Park | Github ورق | |
BIPEFT: Budget-Guided Iterative Search for Parameter Efficient Fine-Tuning of Large Pretrained Language Models Aofei Chang, Jiaqi Wang, Han Liu, Parminder Bhatia, Cao Xiao, Ting Wang, Fenglong Ma | Github ورق | |
SparseGrad: A Selective Method for Efficient Fine-tuning of MLP Layers Viktoriia Chekalina, Anna Rudenko, Gleb Mezentsev, Alexander Mikhalev, Alexander Panchenko, Ivan Oseledets | Github ورق | |
| SpaLLM: Unified Compressive Adaptation of Large Language Models with Sketching Tianyi Zhang, Junda Su, Oscar Wu, Zhaozhuo Xu, Anshumali Shrivastava | ورق | |
Bone: Block Affine Transformation as Parameter Efficient Fine-tuning Methods for Large Language Models Jiale Kang | Github ورق | |
| Enabling Resource-Efficient On-Device Fine-Tuning of LLMs Using Only Inference Engines Lei Gao, Amir Ziashahabi, Yue Niu, Salman Avestimehr, Murali Annavaram | 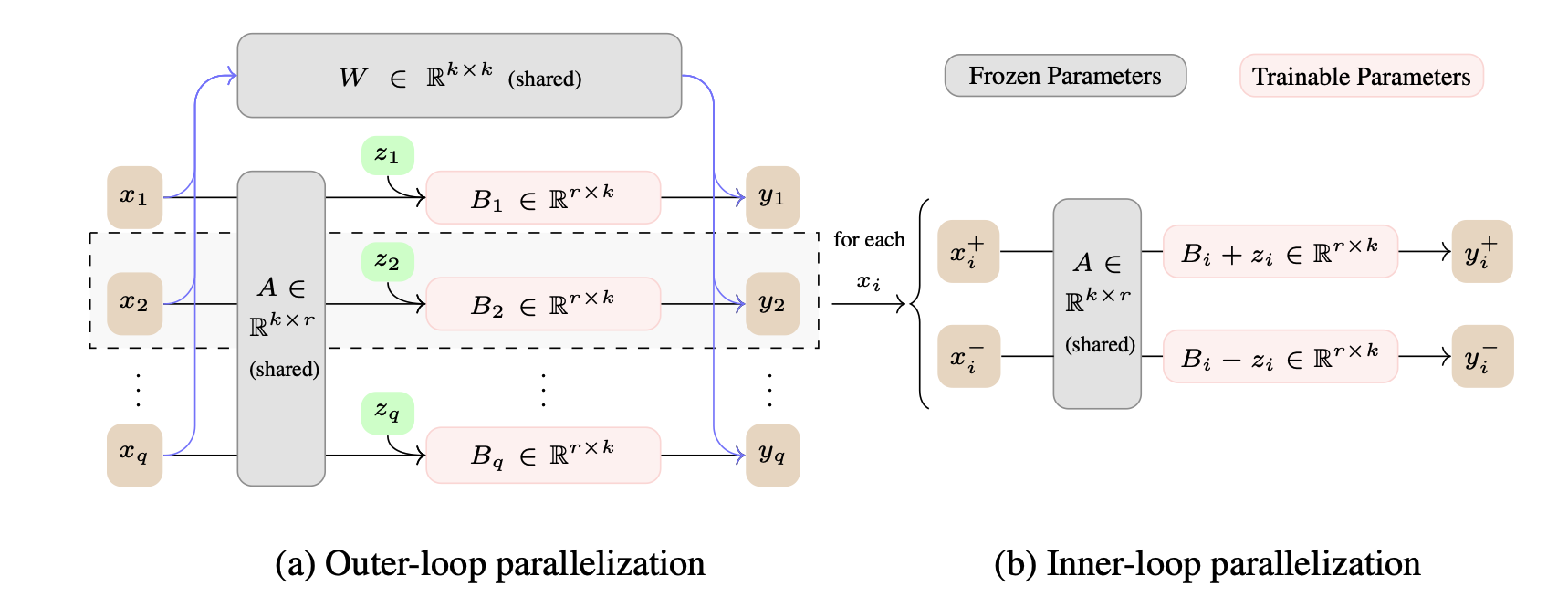 | ورق |
| Title & Authors | مقدمة | الروابط |
|---|---|---|
| AutoMixQ: Self-Adjusting Quantization for High Performance Memory-Efficient Fine-Tuning Changhai Zhou, Shiyang Zhang, Yuhua Zhou, Zekai Liu, Shichao Weng | 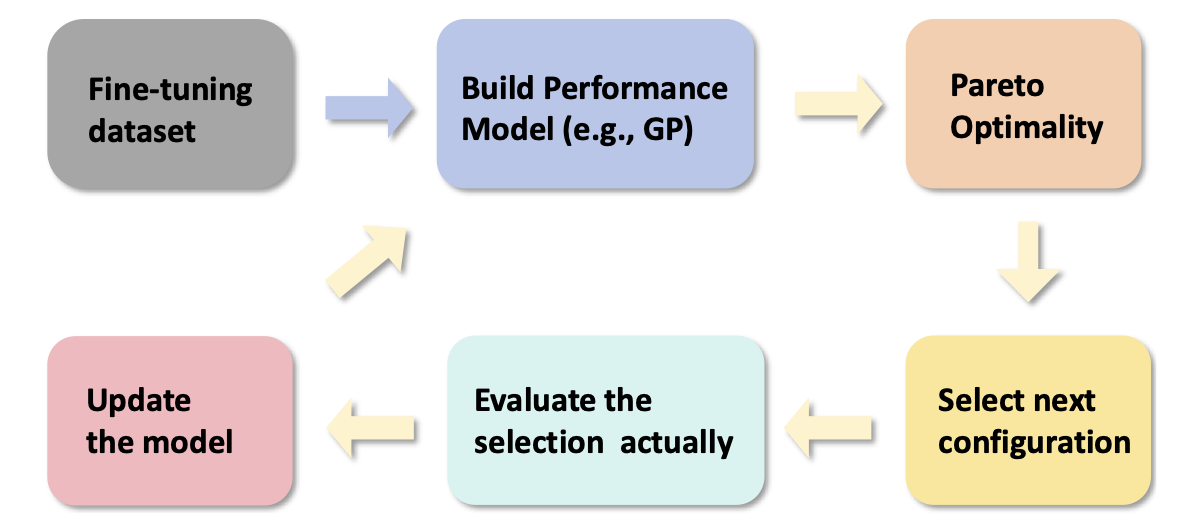 | ورق |
Scalable Efficient Training of Large Language Models with Low-dimensional Projected Attention Xingtai Lv, Ning Ding, Kaiyan Zhang, Ermo Hua, Ganqu Cui, Bowen Zhou | Github ورق | |
| Less is More: Extreme Gradient Boost Rank-1 Adaption for Efficient Finetuning of LLMs Yifei Zhang, Hao Zhu, Aiwei Liu, Han Yu, Piotr Koniusz, Irwin King | ورق | |
COAT: Compressing Optimizer states and Activation for Memory-Efficient FP8 Training Haocheng Xi, Han Cai, Ligeng Zhu, Yao Lu, Kurt Keutzer, Jianfei Chen, Song Han | 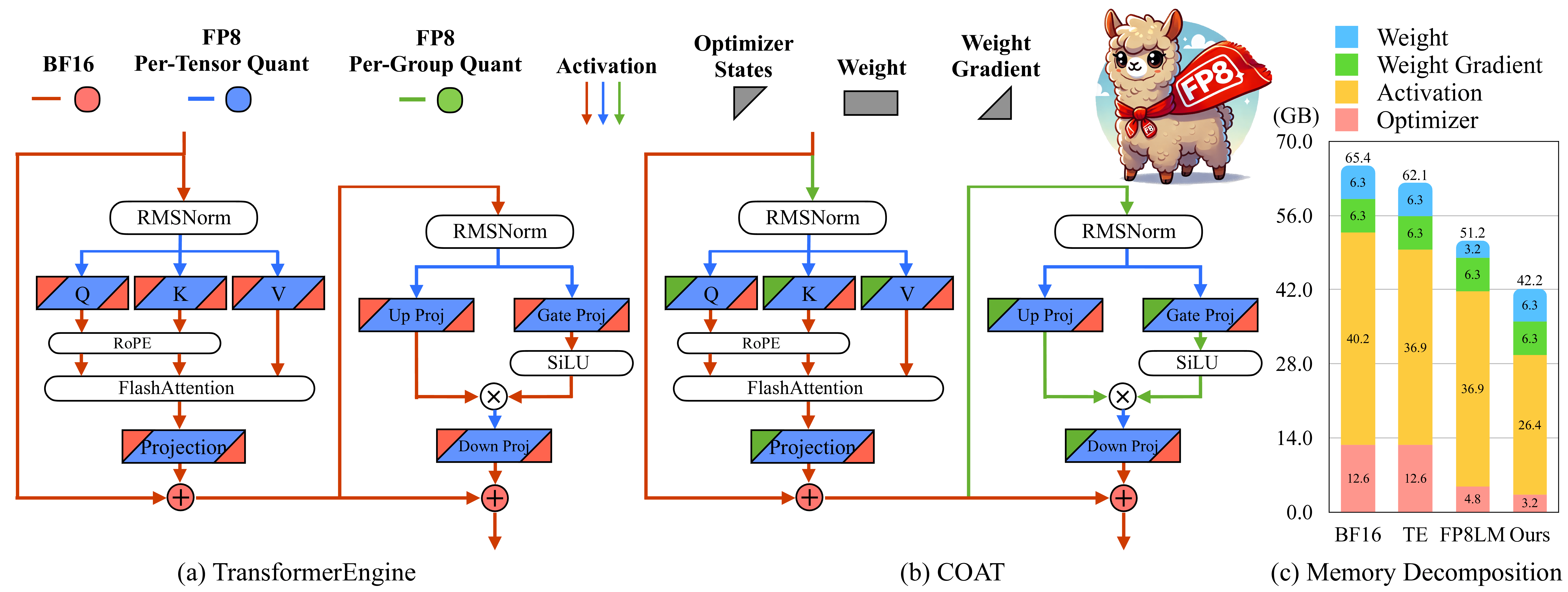 | Github ورق |
BitPipe: Bidirectional Interleaved Pipeline Parallelism for Accelerating Large Models Training Houming Wu, Ling Chen, Wenjie Yu |  | Github ورق |
| Title & Authors | مقدمة | الروابط |
|---|---|---|
| Closer Look at Efficient Inference Methods: A Survey of Speculative Decoding Hyun Ryu, Eric Kim | ورق | |
LLM-Inference-Bench: Inference Benchmarking of Large Language Models on AI Accelerators Krishna Teja Chitty-Venkata, Siddhisanket Raskar, Bharat Kale, Farah Ferdaus et al | Github ورق | |
Prompt Compression for Large Language Models: A Survey Zongqian Li, Yinhong Liu, Yixuan Su, Nigel Collier | Github ورق | |
| Large Language Model Inference Acceleration: A Comprehensive Hardware Perspective Jinhao Li, Jiaming Xu, Shan Huang, Yonghua Chen, Wen Li, Jun Liu, Yaoxiu Lian, Jiayi Pan, Li Ding, Hao Zhou, Guohao Dai | ورق | |
| A Survey of Low-bit Large Language Models: Basics, Systems, and Algorithms Ruihao Gong, Yifu Ding, Zining Wang, Chengtao Lv, Xingyu Zheng, Jinyang Du, Haotong Qin, Jinyang Guo, Michele Magno, Xianglong Liu | ورق | |
Contextual Compression in Retrieval-Augmented Generation for Large Language Models: A Survey Sourav Verma | 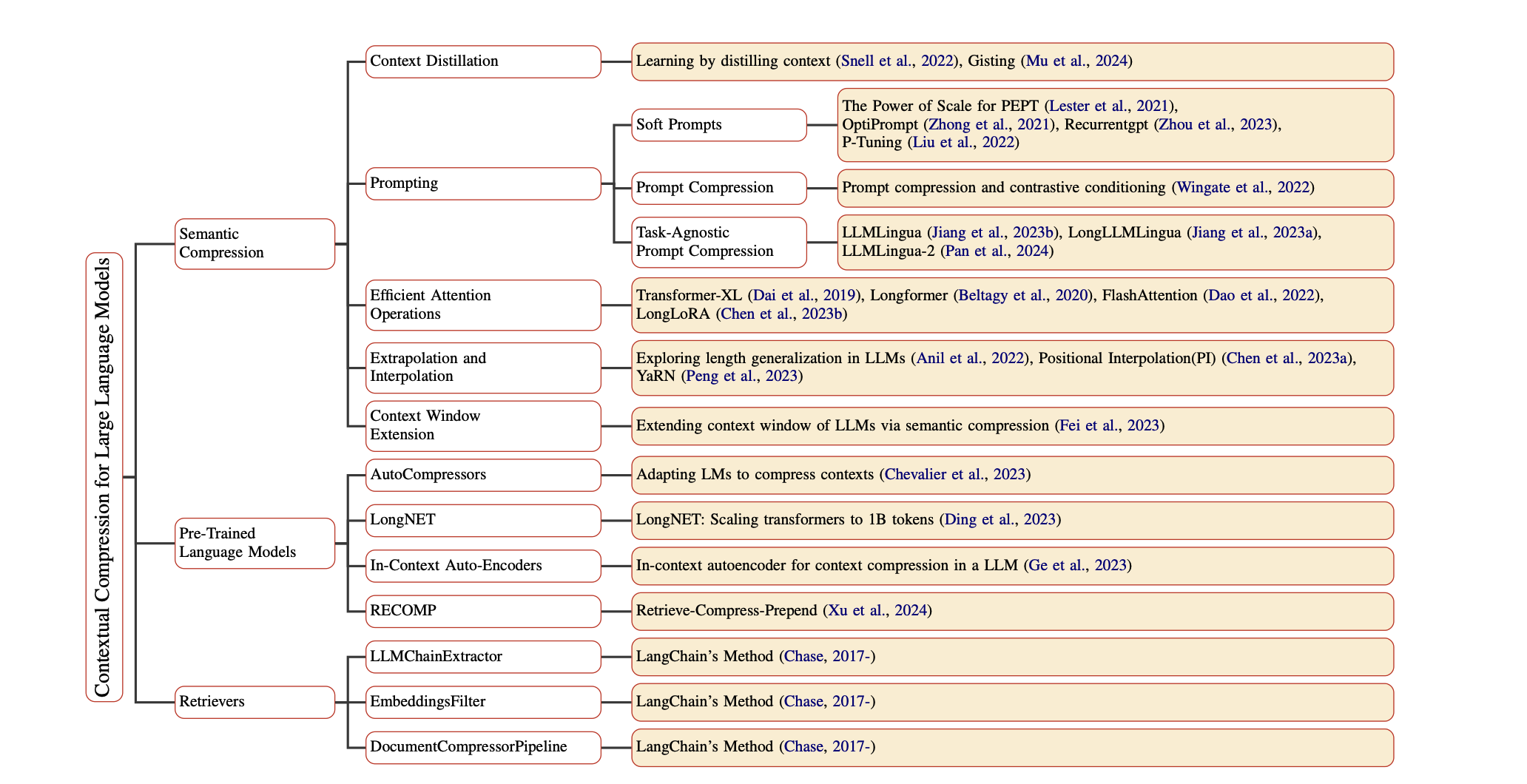 | Github ورق |
| Art and Science of Quantizing Large-Scale Models: A Comprehensive Overview Yanshu Wang, Tong Yang, Xiyan Liang, Guoan Wang, Hanning Lu, Xu Zhe, Yaoming Li, Li Weitao | ورق | |
| Hardware Acceleration of LLMs: A comprehensive survey and comparison Nikoletta Koilia, Christoforos Kachris | ورق | |
| A Survey on Symbolic Knowledge Distillation of Large Language Models Kamal Acharya, Alvaro Velasquez, Houbing Herbert Song | ورق |


